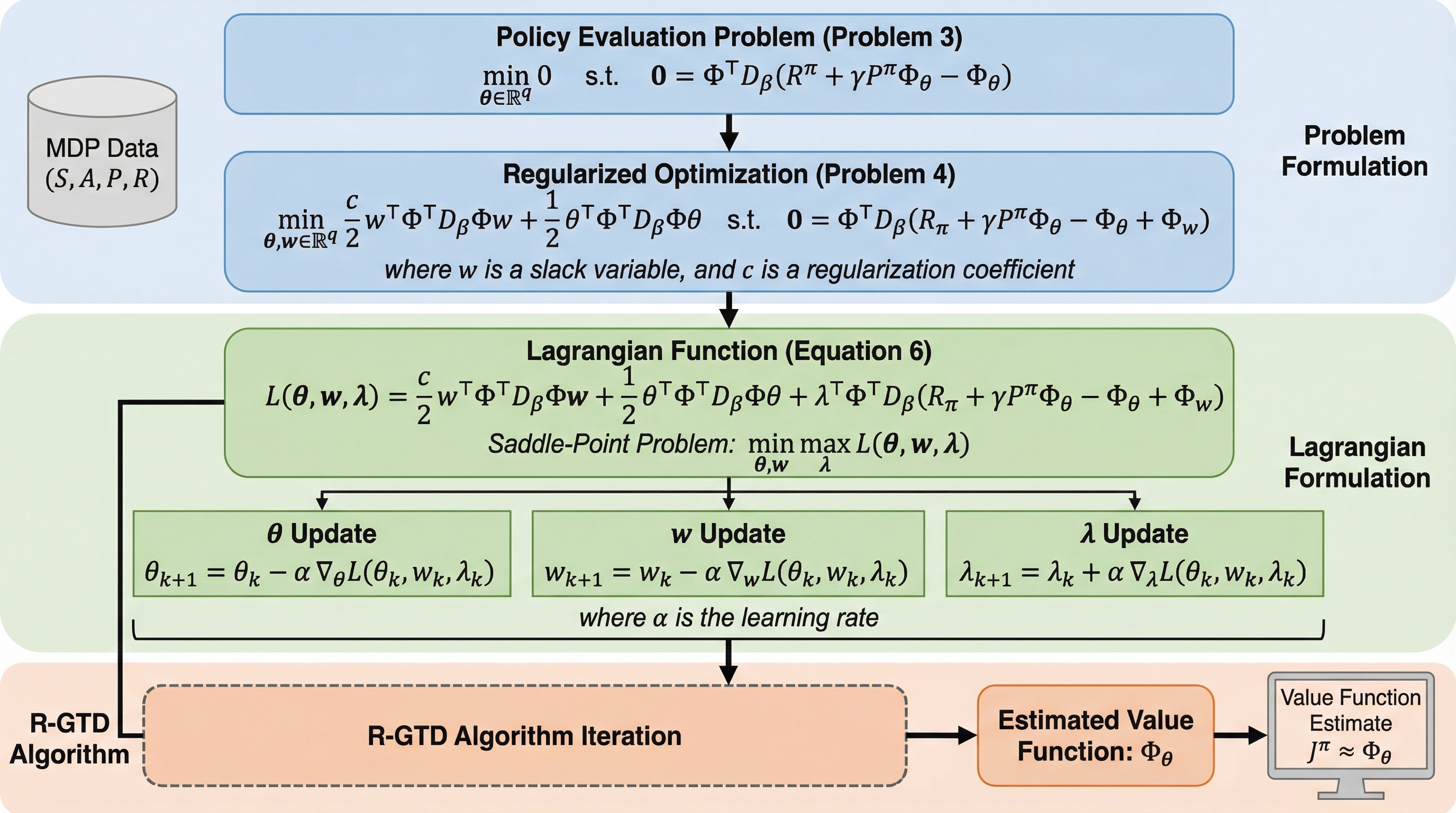
正則化勾配時間差学習
強化学習のオフポリシー評価で用いられる勾配時間差学習(GTD)は、特徴相互作用行列(FIM)が非特異であるという強い仮定に依存しており、実際の応用では行列が特異になることで数値的な不安定性や収束の失敗が生じるという深刻な課題を抱えていた。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
強化学習のオフポリシー評価で用いられる勾配時間差学習(GTD)は、特徴相互作用行列(FIM)が非特異であるという強い仮定に依存しており、実際の応用では行列が特異になることで数値的な不安定性や収束の失敗が生じるという深刻な課題を抱えていた。
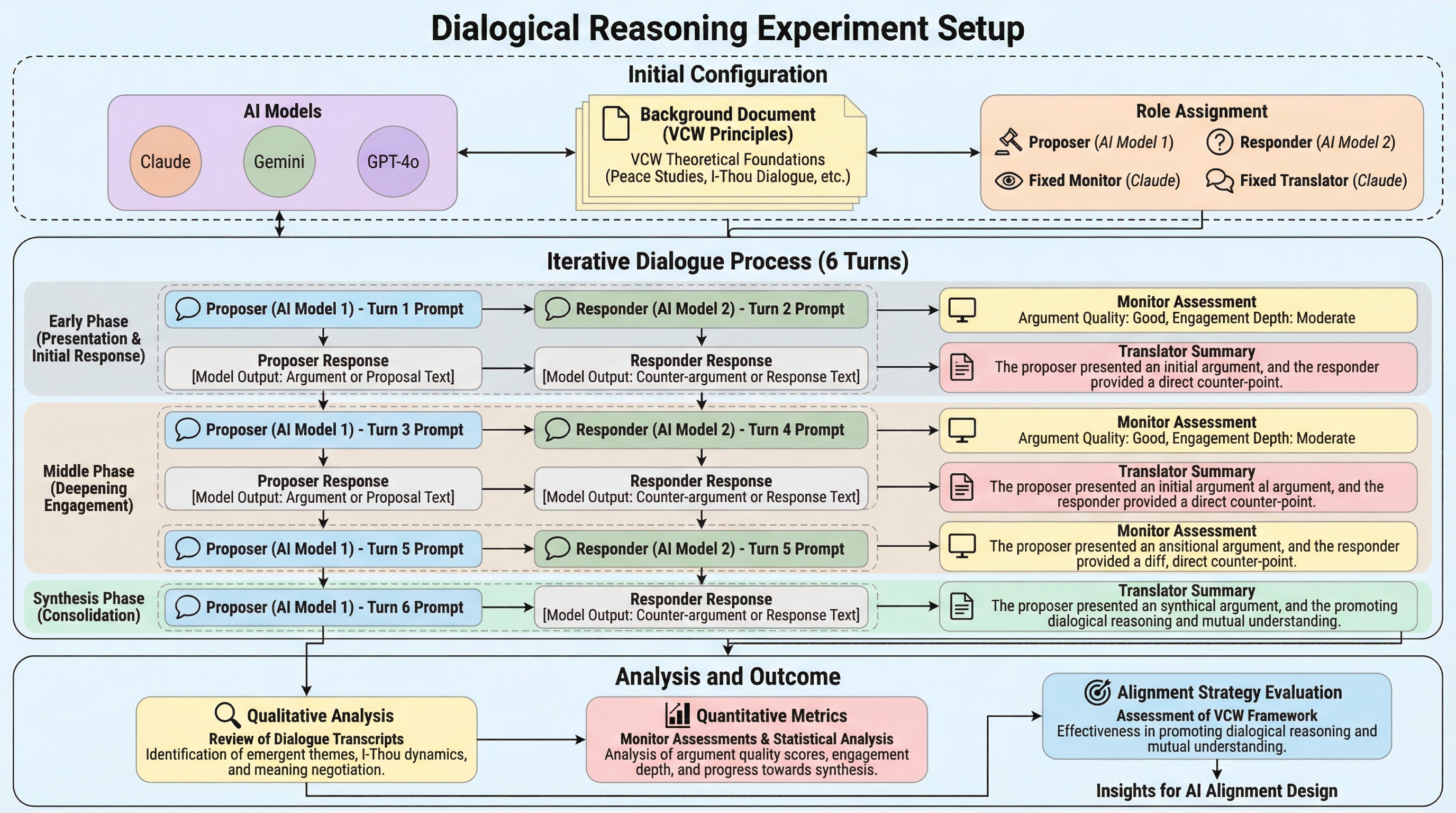
従来のAIアライメント評価は単一モデルによる静的な手法が主流であったが、本研究は平和学の知見を取り入れ、複数のAI(Claude、Gemini、GPT-4o)が異なる役割(提案者、応答者、監視者、翻訳者)を演じて対話を行うことで、アライメント提案を動的にストレステストする新しいフレームワークを開発した。
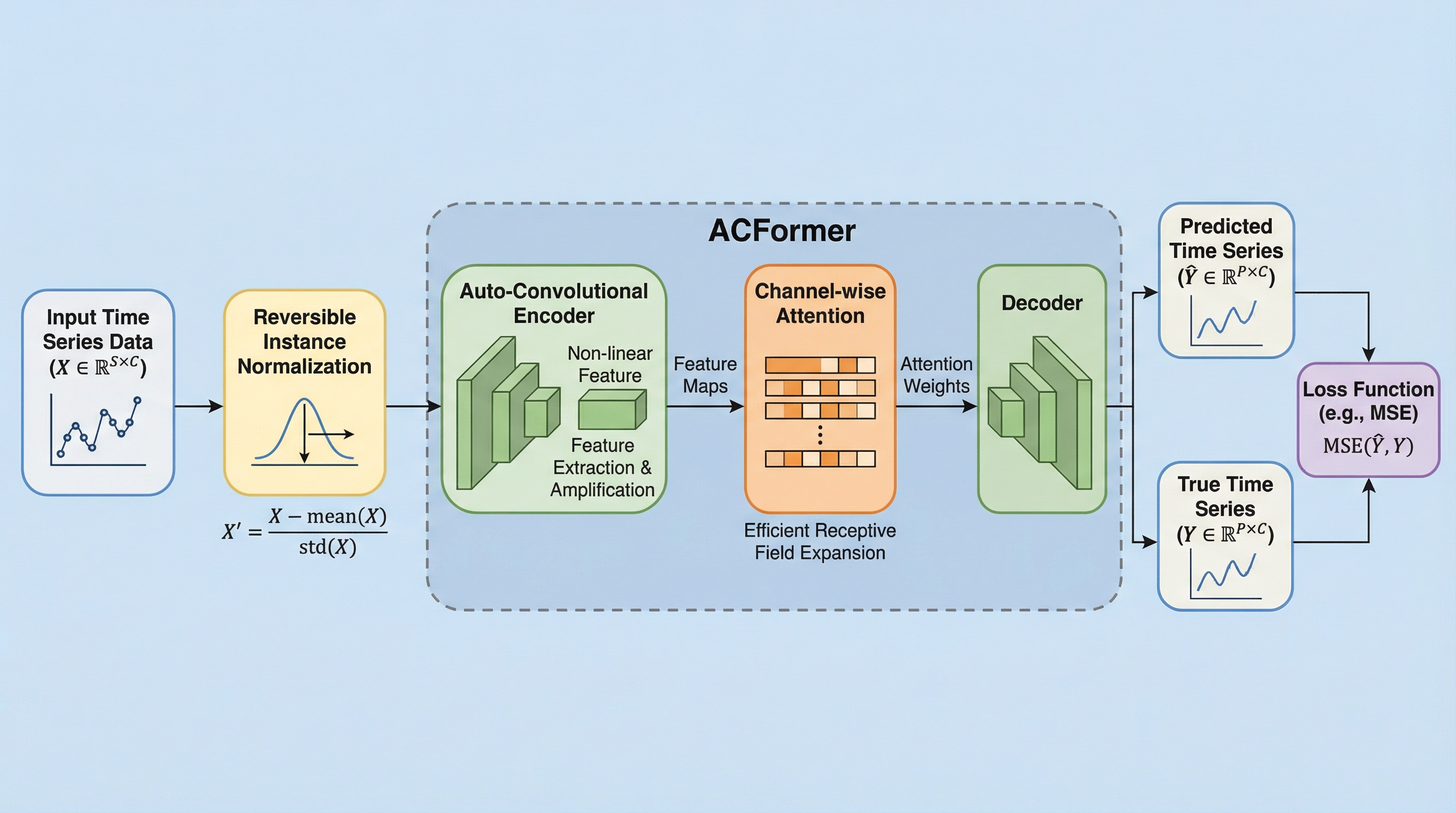
従来の時系列予測において、線形モデルはグローバルなトレンド把握には優れるものの、高周波な非線形信号の処理に限界がありました。本研究では、畳み込み層(CNN)がチャネル間のアテンション機構を補完しつつ非線形変動に対して高い堅牢性を持つことを解明し、線形投影の効率性とCNNの抽出力を統合した新アーキテクチャ「ACFormer」を提案しました。 複数のベンチマークデータセットを用いた実験の結果、ACFormerは既存の最先端モデルを一貫して上回る性能を達成し、特に線形モデルが苦手とする複雑な非線形パターンの復元において顕著な効果を示すことが確認されました。 共有パッチ圧縮、時間ゲート付きアテンション、独立パッチ拡張という3つの主要コンポーネントを導入することで、計算効率を維持しながら多変量間の複雑な相関と局所的な時間依存性の両方を精密にモデル化することに成功しました。
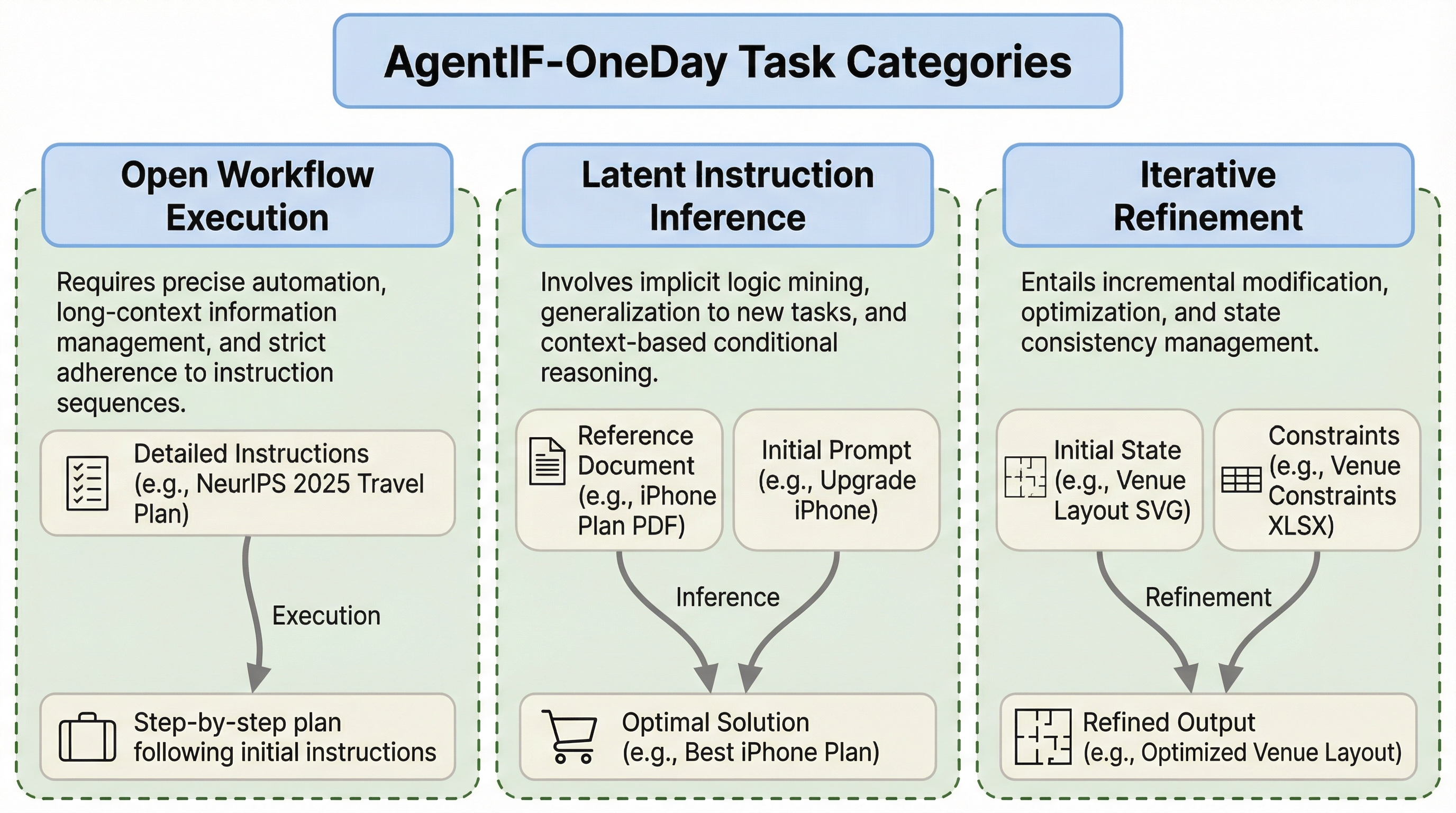
AgentIF-OneDayは、AIエージェントが一般ユーザーの日常生活、仕事、学習における多様なタスクをどの程度遂行できるかを評価するための新しいベンチマークであり、104の複雑なタスクと767の評価ポイントによって構成されています。
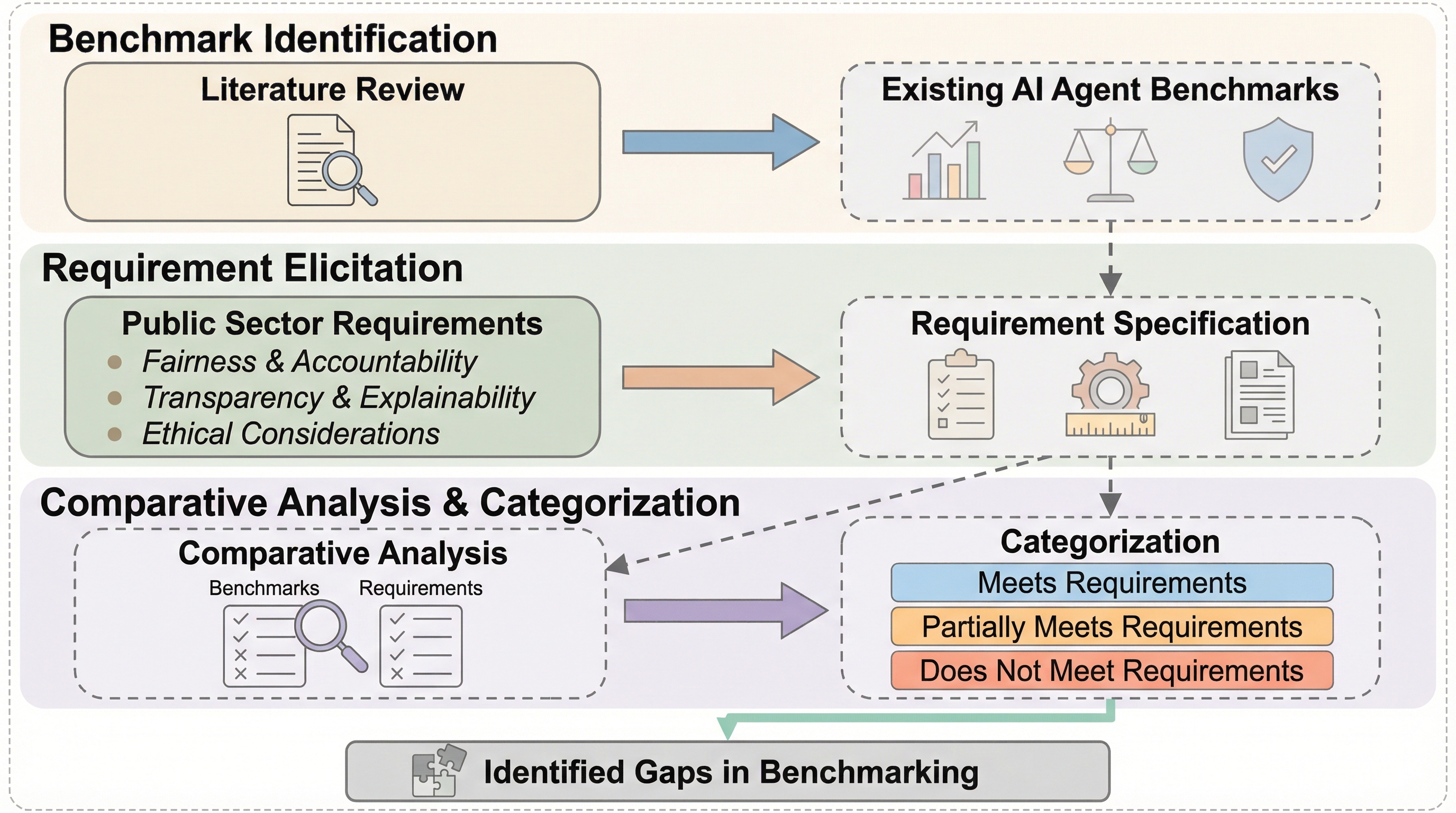
公共部門におけるAIエージェントの導入には、法的・手続き的な厳格な要件を満たすことが不可欠であるが、既存のベンチマークがこれらの特殊な要求を適切に反映できているかは不明確であった。 本研究では、行政学の理論に基づき、タスク中心、現実的、公共部門特化、およびコストや公平性を含む指標の報告という6つの基準を定義し、1,300件以上の既存ベンチマーク論文を体系的に分析した。 分析の結果、すべての基準を満たすベンチマークは一つも存在せず、特に公共部門への適合性や多角的な評価指標において大きな欠落があることが判明したため、新たな評価枠組みの構築が急務である。
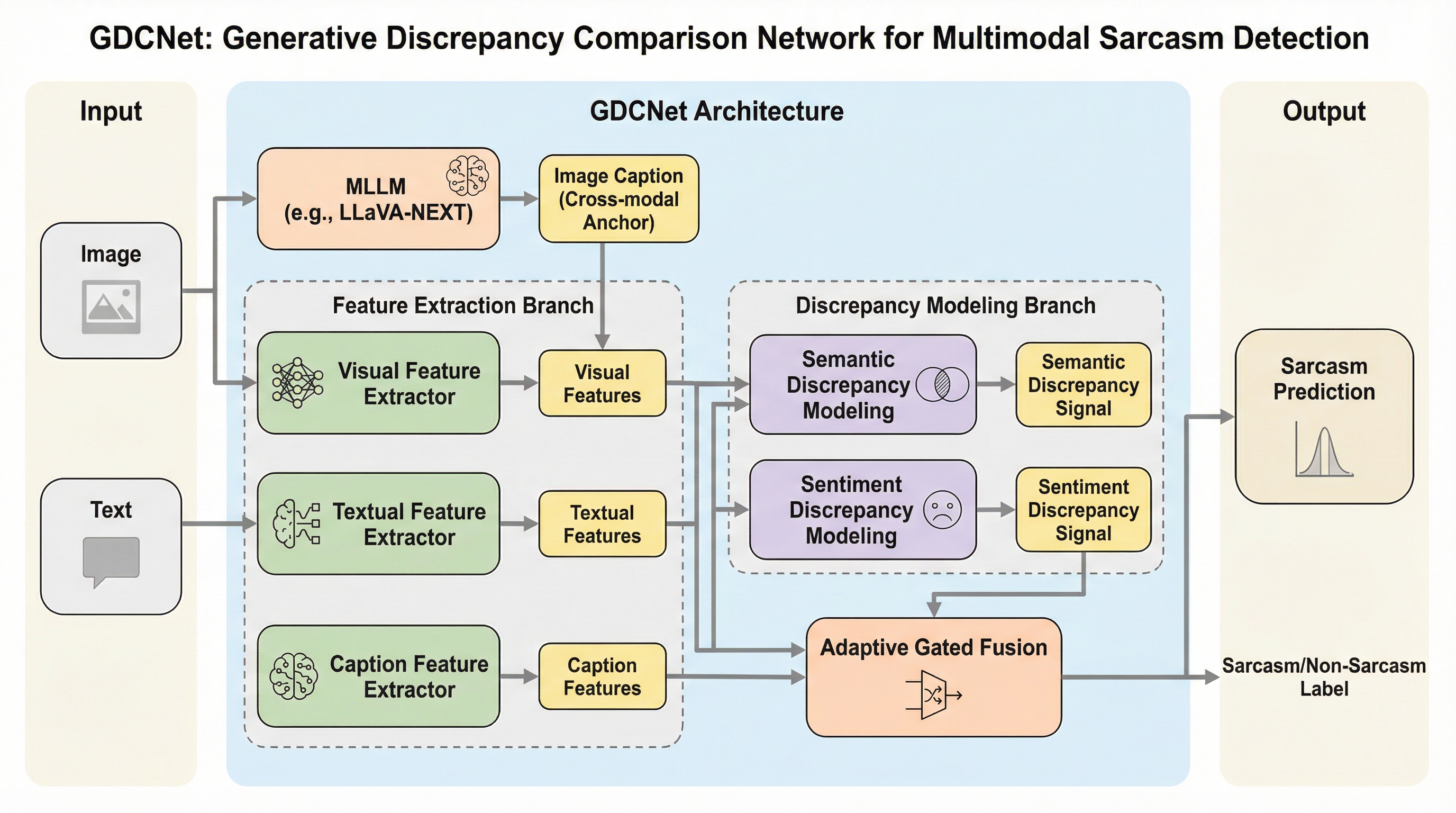
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。
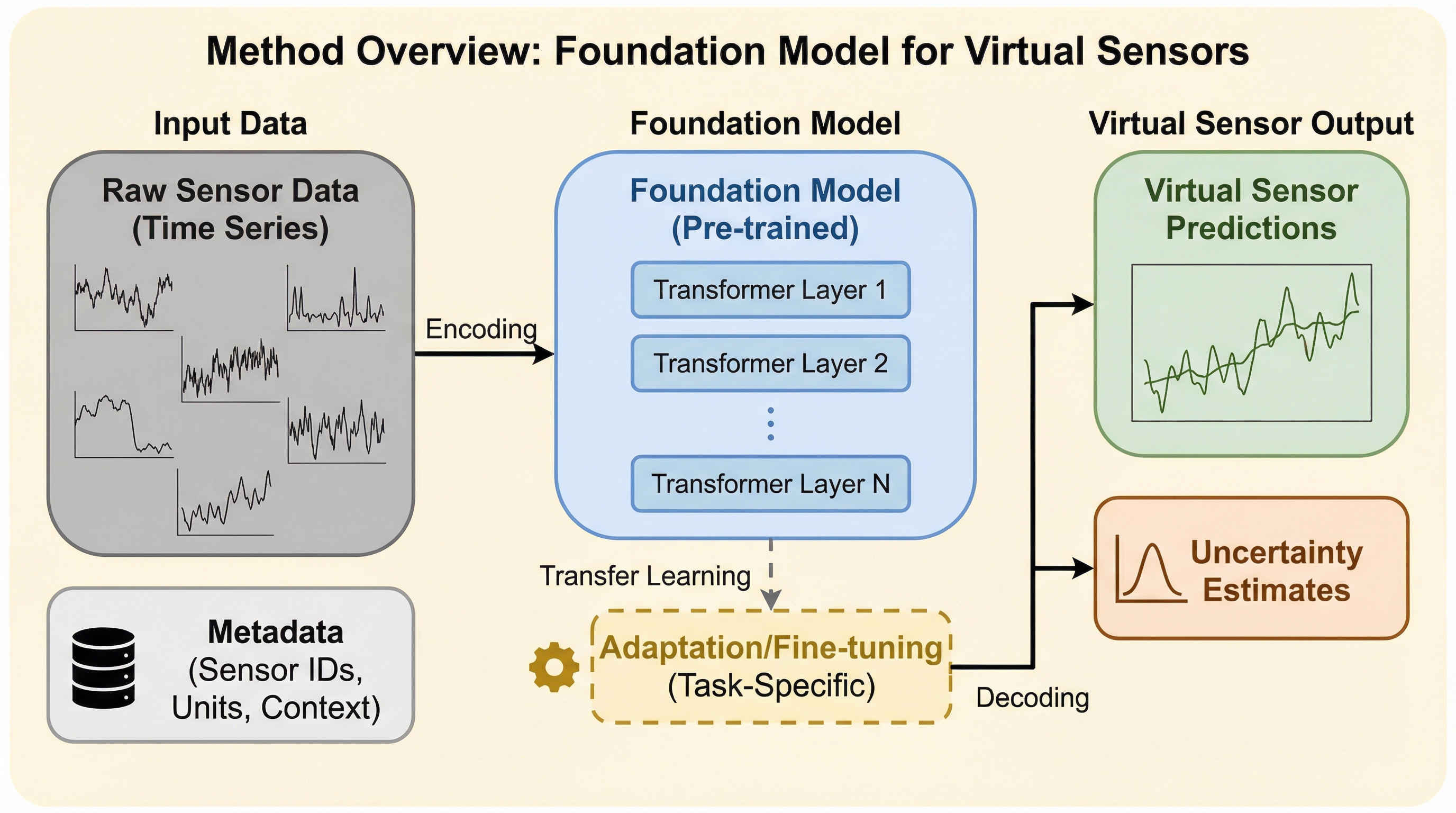
従来の仮想センサーは特定の用途ごとに個別のモデルを構築する必要があり、専門知識による入力信号の選択や計算コストの増大が課題であったが、本研究では複数の仮想センサーを統合的に予測可能な初の基盤モデルを提案する。
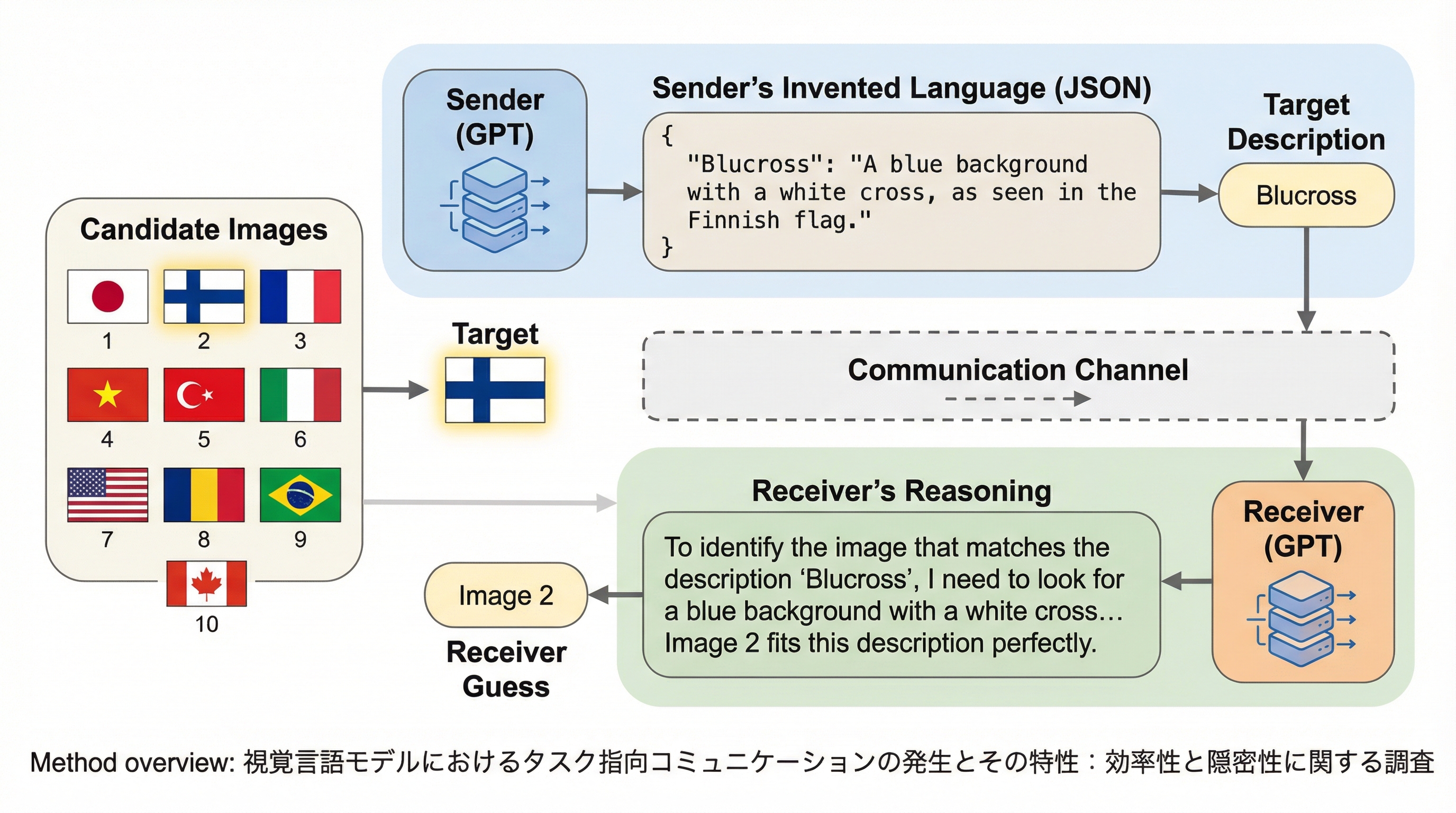
視覚言語モデル(VLM)は、特定のタスクにおいて自然言語よりも情報の伝達効率が高く、かつ外部の観察者には内容が解読できない「隠密性」を備えた独自の通信プロトコルを自発的に開発できることが判明しました。
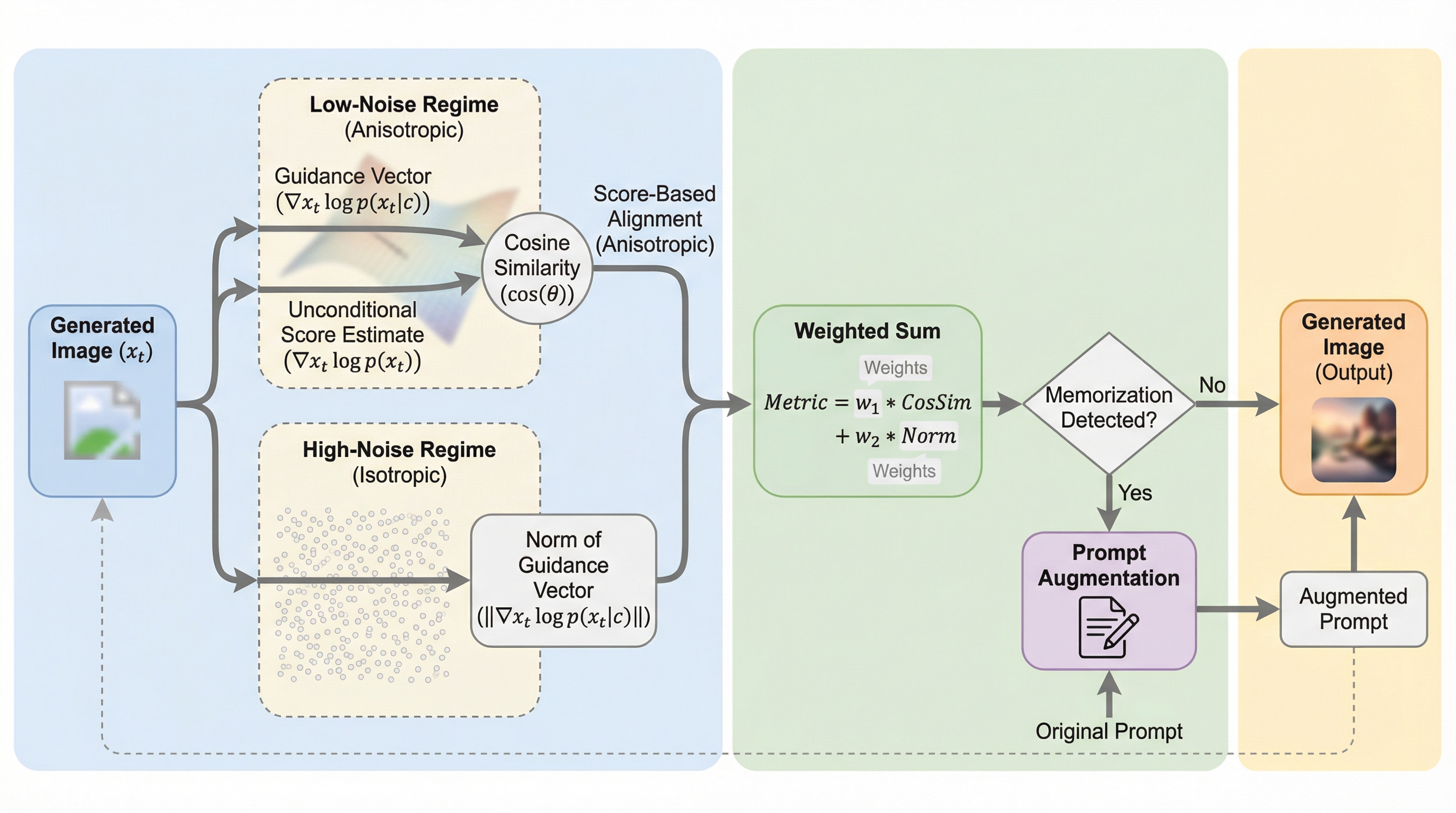
拡散モデルが学習データを複製する「記憶問題」に対し、従来のスコアのノルムに基づく検出法は高ノイズ時の等方的な状態でのみ有効であり、低ノイズ時の異方的な状態では精度が低下するという幾何学的な課題を特定しました。
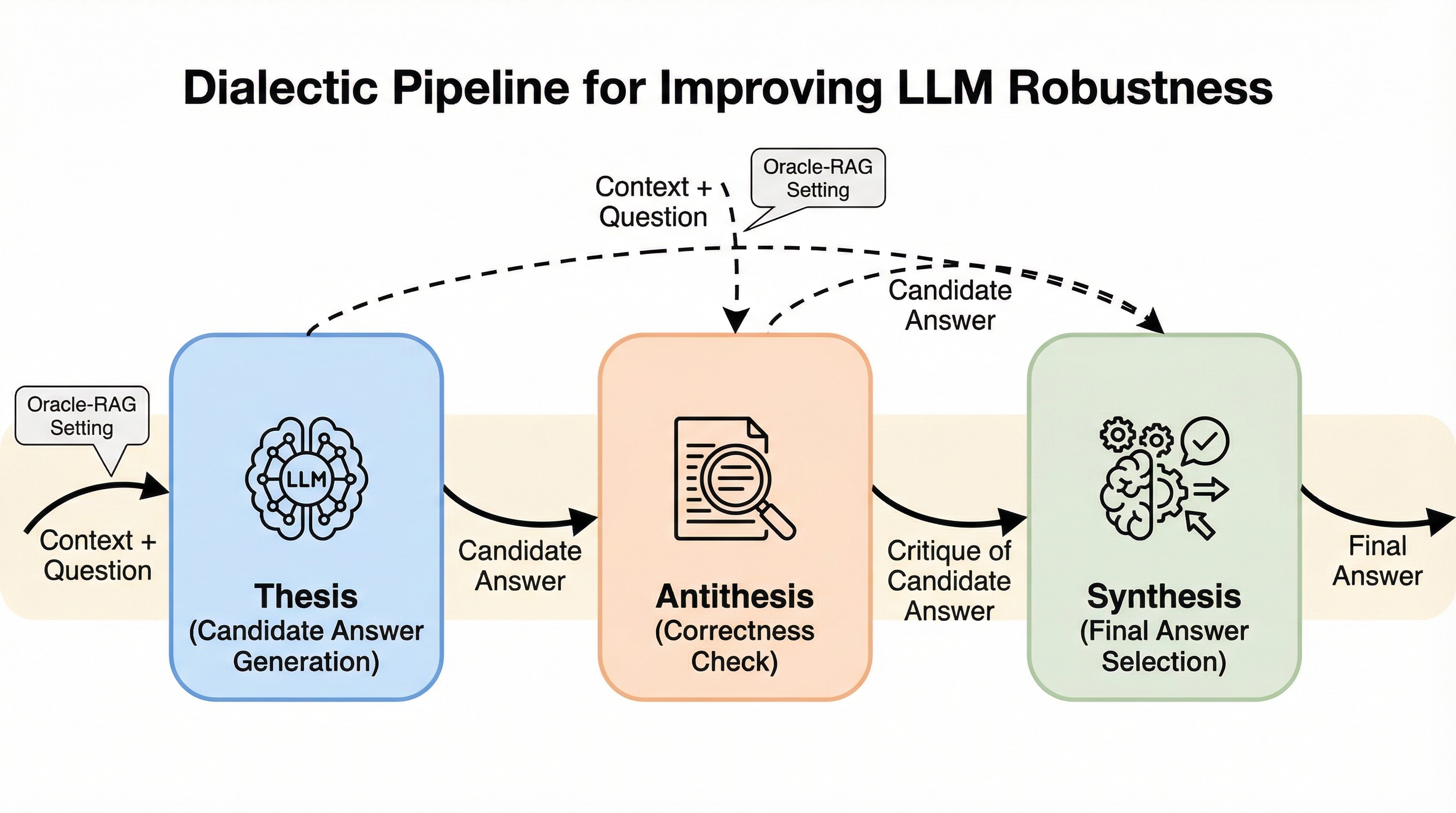
大規模言語モデル(LLM)の課題であるハルシネーションを抑制するため、ヘーゲル哲学の弁証法に着想を得た「対話的パイプライン(Dialectic Pipeline)」が提案されました。この手法は、モデルが「正(Thesis)」「反(Antithesis)」「合(Synthesis)」という3つの段階を経て自己対話を行うことで、初期の回答を批判的に検討し、最終的な結論を洗練させる仕組みです。 検証の結果、複数の知識源を統合する複雑なマルチホップ質問応答タスクにおいて、標準的な回答手法や既存の「思考の連鎖(Chain-of-Thought)」を大幅に上回る精度と信頼性を達成しました。また、外部知識を活用するRAG環境において、情報の要約や勾配ベースのフィルタリングを組み合わせることで、モデルの規模や種類を問わず回答の質がさらに向上することが確認されました。 本研究は、追加学習や特定のドメインへの特化を必要とせず、プロンプトの構造を工夫するだけでモデルの汎用性を維持したまま堅牢性を高められることを示しています。特に、推論能力と内容抽出能力の両方が求められる多段階の質問応答において、自己修正プロセスが極めて有効であることを実証し、実用的なフレームワークを提供しています。