大規模言語モデルの堅牢性を高める「対話的パイプライン」
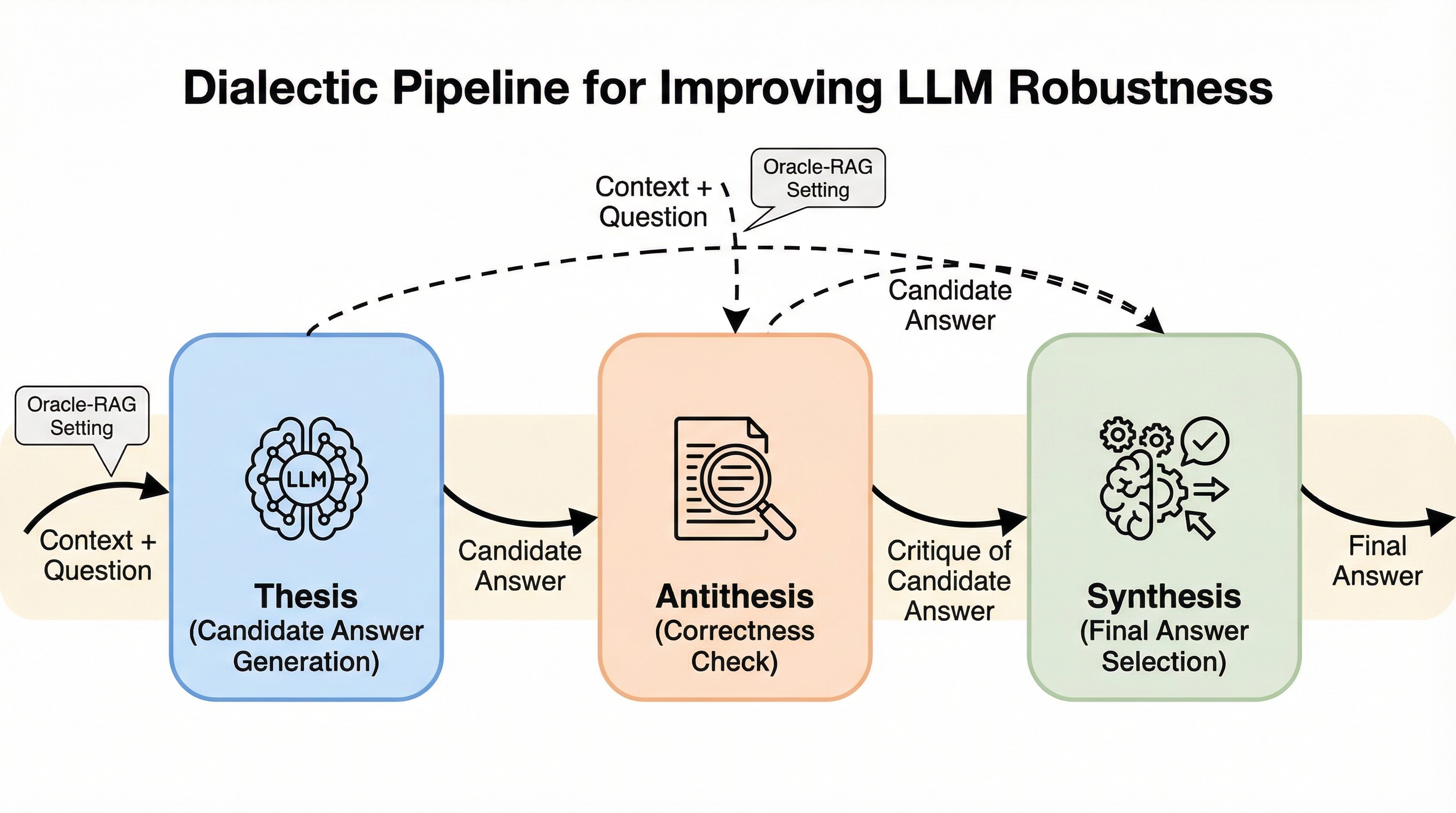
大規模言語モデル(LLM)の課題であるハルシネーションを抑制するため、ヘーゲル哲学の弁証法に着想を得た「対話的パイプライン(Dialectic Pipeline)」が提案されました。この手法は、モデルが「正(Thesis)」「反(Antithesis)」「合(Synthesis)」という3つの段階を経て自己対話を行うことで、初期の回答を批判的に検討し、最終的な結論を洗練させる仕組みです。 検証の結果、複数の知識源を統合する複雑なマルチホップ質問応答タスクにおいて、標準的な回答手法や既存の「思考の連鎖(Chain-of-Thought)」を大幅に上回る精度と信頼性を達成しました。また、外部知識を活用するRAG環境において、情報の要約や勾配ベースのフィルタリングを組み合わせることで、モデルの規模や種類を問わず回答の質がさらに向上することが確認されました。 本研究は、追加学習や特定のドメインへの特化を必要とせず、プロンプトの構造を工夫するだけでモデルの汎用性を維持したまま堅牢性を高められることを示しています。特に、推論能力と内容抽出能力の両方が求められる多段階の質問応答において、自己修正プロセスが極めて有効であることを実証し、実用的なフレームワークを提供しています。
TL;DR(結論)
大規模言語モデル(LLM)の課題であるハルシネーションを抑制するため、ヘーゲル哲学の弁証法に着想を得た「対話的パイプライン(Dialectic Pipeline)」が提案されました。この手法は、モデルが「正(Thesis)」「反(Antithesis)」「合(Synthesis)」という3つの段階を経て自己対話を行うことで、初期の回答を批判的に検討し、最終的な結論を洗練させる仕組みです。 検証の結果、複数の知識源を統合する複雑なマルチホップ質問応答タスクにおいて、標準的な回答手法や既存の「思考の連鎖(Chain-of-Thought)」を大幅に上回る精度と信頼性を達成しました。また、外部知識を活用するRAG環境において、情報の要約や勾配ベースのフィルタリングを組み合わせることで、モデルの規模や種類を問わず回答の質がさらに向上することが確認されました。 本研究は、追加学習や特定のドメインへの特化を必要とせず、プロンプトの構造を工夫するだけでモデルの汎用性を維持したまま堅牢性を高められることを示しています。特に、推論能力と内容抽出能力の両方が求められる多段階の質問応答において、自己修正プロセスが極めて有効であることを実証し、実用的なフレームワークを提供しています。
なぜこの問題か
大規模言語モデル(LLM)は、2017年のトランスフォーマー(Transformer)の登場以来、自然言語処理の分野に革命をもたらしましたが、依然として「ハルシネーション」という深刻な問題に直面しています。これはモデルが事実に基づかない、あるいは誤解を招く情報を生成してしまう現象であり、不完全な学習データやノイズ、偏った情報、あるいは不適切なプロンプト指示などが原因で発生します。この問題を解決するために、特定のドメインデータを用いたファインチューニングや、回答の正誤を判定する専用の検証モデル(Verifier)を構築する手法が取られてきましたが、これらには膨大な計算資源が必要であり、多くのユーザーアプリケーションにとって現実的ではありません。また、特定の分野に特化させることで、モデルが本来持っている広範な知識や汎用的な能力が制限されてしまうという欠点もあります。 特に、複数の情報源を適切に統合して回答を導き出す「マルチホップ(Multi-hop)」形式の質問応答は、単なる情報の抽出だけでなく高度な推論能力を必要とするため、標準的な手法では正解を得ることが困難です。…
核心:何を提案したのか
本研究では、LLMの回答品質を向上させるための新しいフレームワークとして「対話的パイプライン(Dialectic Pipeline)」を提案しています。この手法の最大の特徴は、ヘーゲル哲学の弁証法に着想を得た「自己対話」のプロセスを導入している点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related