AgentIF-OneDay: 一般ユーザーの日常タスクをこなす汎用AIエージェント向けの新ベンチマーク
AgentIF-OneDayは、AIエージェントが一般ユーザーの日常生活、仕事、学習における多様なタスクをどの程度遂行できるかを評価するための新しいベンチマークであり、104の複雑なタスクと767の評価ポイントによって構成されています。
TL;DR(結論)
AgentIF-OneDayは、AIエージェントが一般ユーザーの日常生活、仕事、学習における多様なタスクをどの程度遂行できるかを評価するための新しいベンチマークであり、104の複雑なタスクと767の評価ポイントによって構成されています。 このフレームワークは、明示的な手順の実行、添付ファイルからの暗黙的な指示の推論、および対話を通じた成果物の継続的な修正という3つの主要な側面からエージェントの能力を測定し、単なる対話を超えた実用的なファイル出力能力を重視しています。 検証の結果、Gemini-3-Proを用いた自動評価パイプラインは人間による採点と80.1%という高い一致率を示しており、現在の主要なAI製品が日常的なワークフローにおいてどの程度の信頼性を持っているかを客観的に示す指標となります。
なぜこの問題か
現在、大規模言語モデル(LLM)を搭載したAIエージェントは、コーディングや深い調査、複雑な問題解決といった特定の専門領域において目覚ましい進歩を遂げています。しかし、こうした技術的な進展がある一方で、一般ユーザーが日常生活の中でAIの高度な能力を実感できる機会は依然として限られているという課題があります。既存の評価指標の多くは、タスクの難易度を上げることに主眼を置いており、幅広い層のユーザーが必要とする仕事、生活、学習といった活動の多様性を十分にカバーできていないのが現状です。 現在の評価フレームワークは、個別のモデルやチャットボット、あるいは基礎モデルの孤立したエージェント能力に焦点を当てがちです。一方で、システム全体を対象とした評価は特定の垂直領域に限定される傾向があります。汎用的なエージェント製品が急速に進化し、ユーザーの期待も動的に変化している中で、現実世界のシナリオに即した多様なタスクを評価できる基準が求められています。特に、ソフトウェア開発や執筆といった特定の用途だけでなく、意思決定のサポートや知識集約型のタスクなど、経済的価値を生む実務的な能力を測定する必要があります。…
核心:何を提案したのか
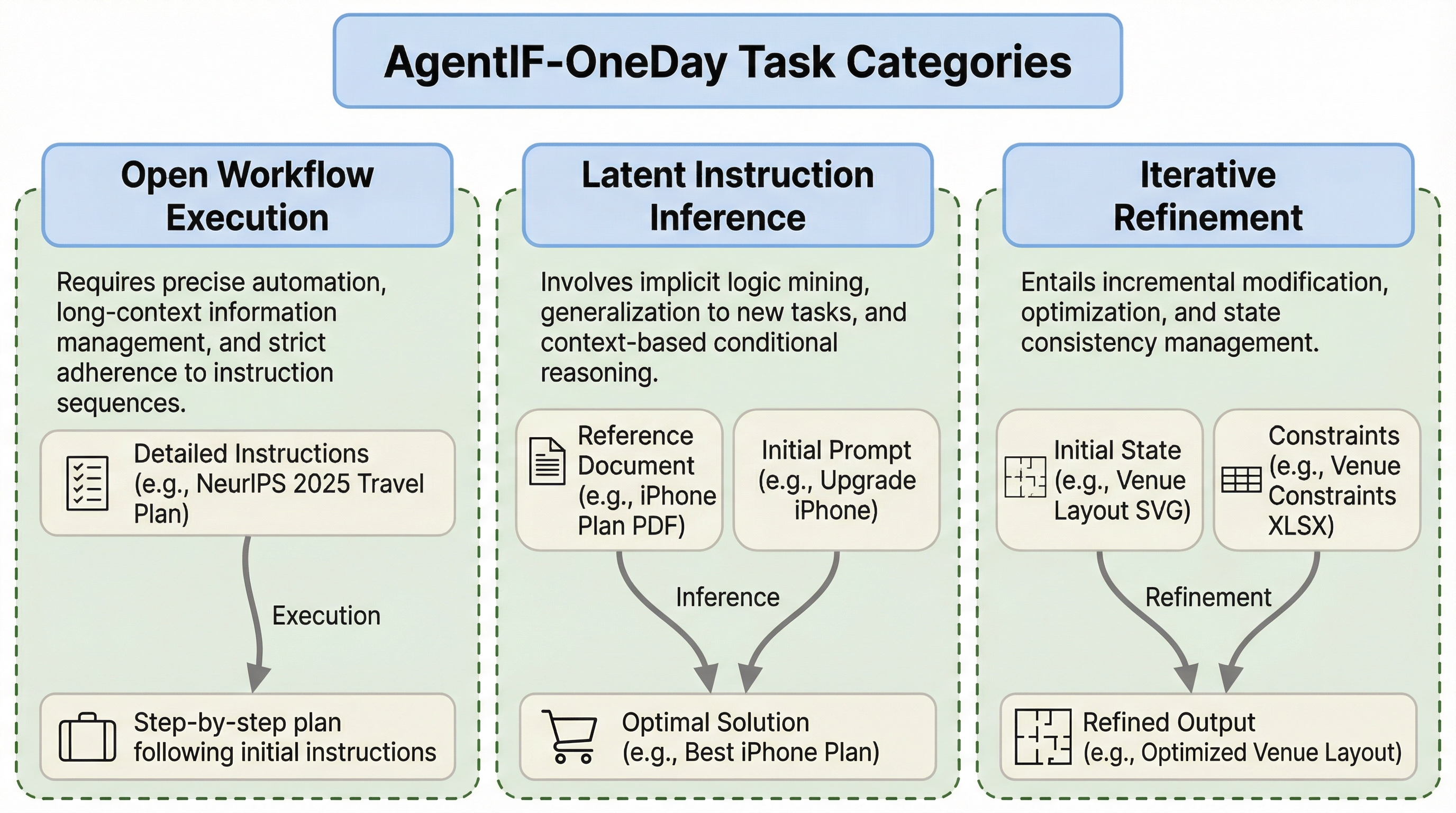
本研究では、一般ユーザーが自然言語の指示を用いて多様な日常タスクを完了できるかを判定することを目的とした「AgentIF-OneDay」を提案しました。このベンチマークは、単に会話で問題を解決するだけでなく、様々な種類の添付ファイルを理解し、具体的なファイルベースの成果物を提供することを要求します。評価の柱として、「オープンなワークフローの実行(Open Workflow Execution)」、「潜在的な指示の推論(Latent Instruction Inference)」、「反復的な洗練(Iterative Refinement)」という、ユーザー中心の3つのカテゴリを定義しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related