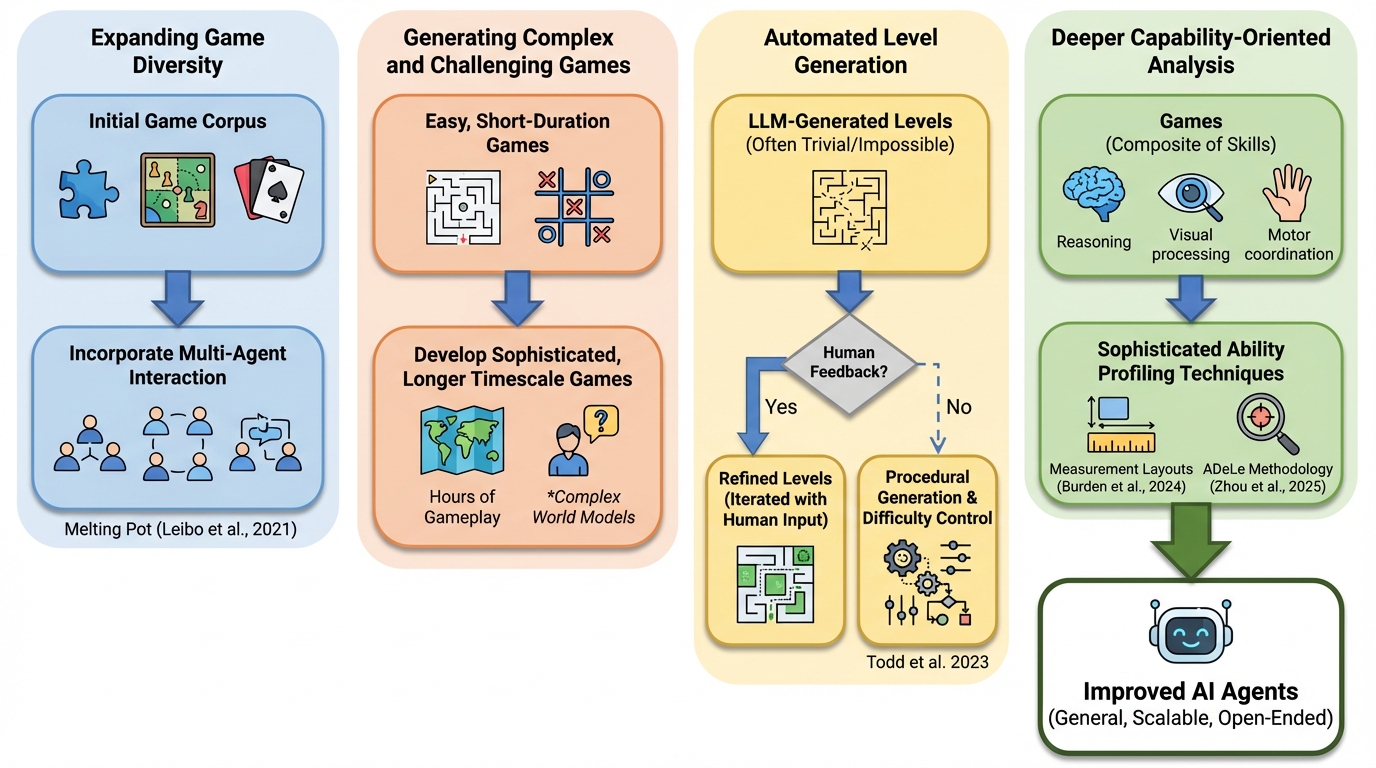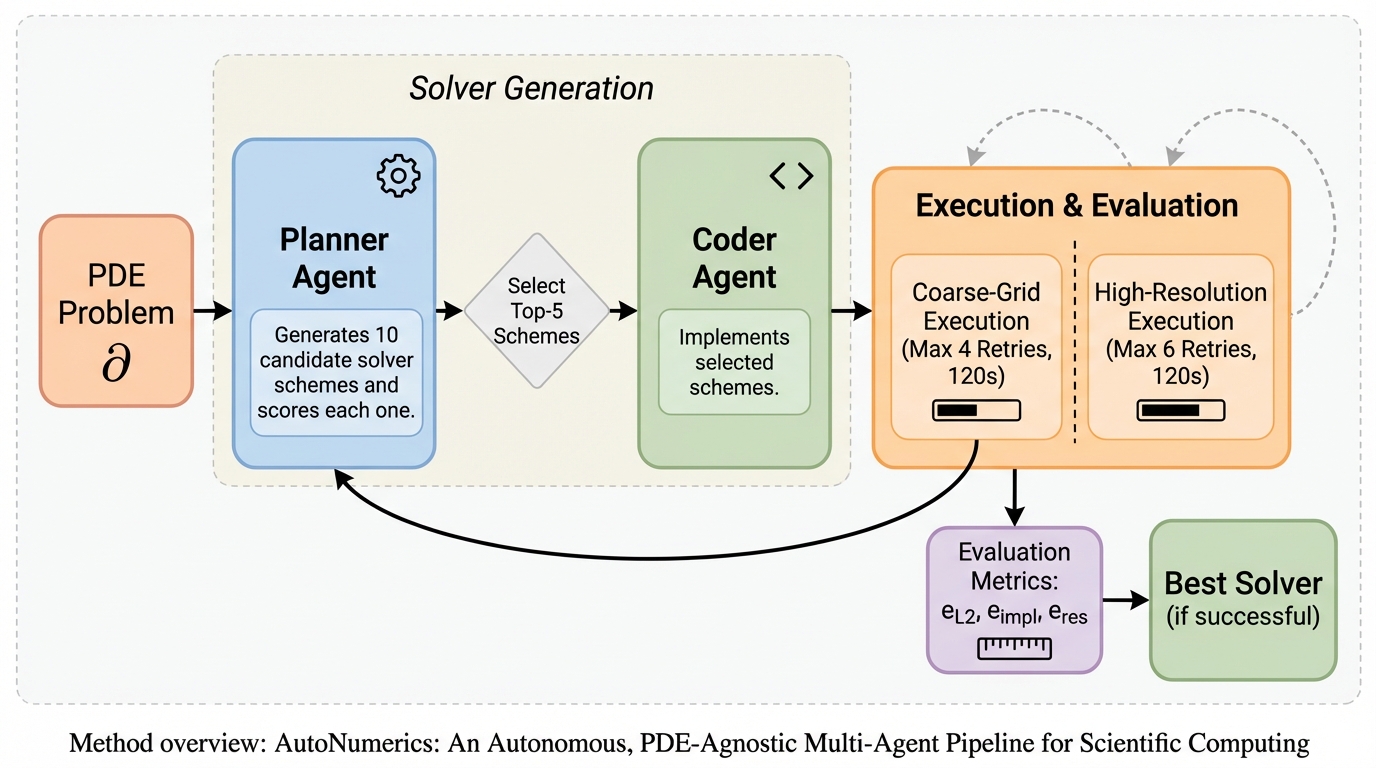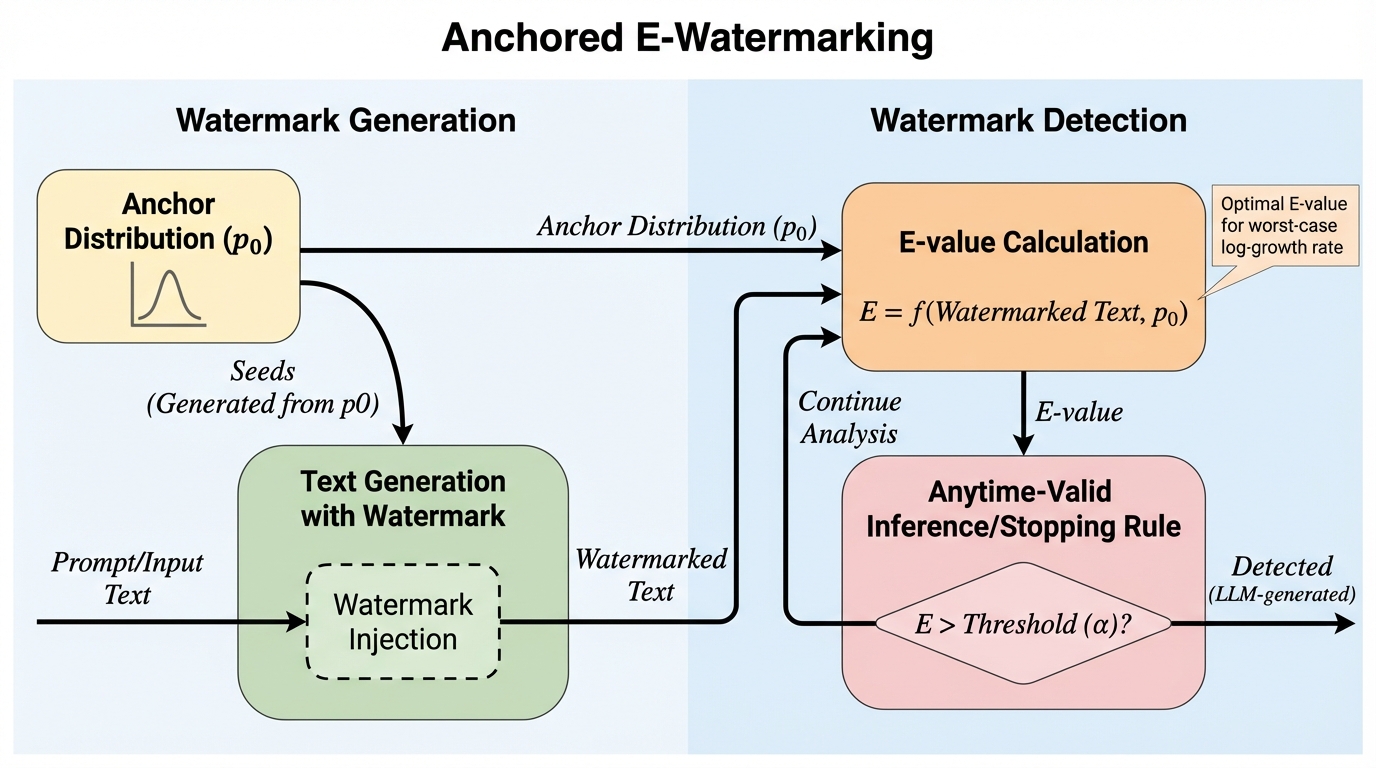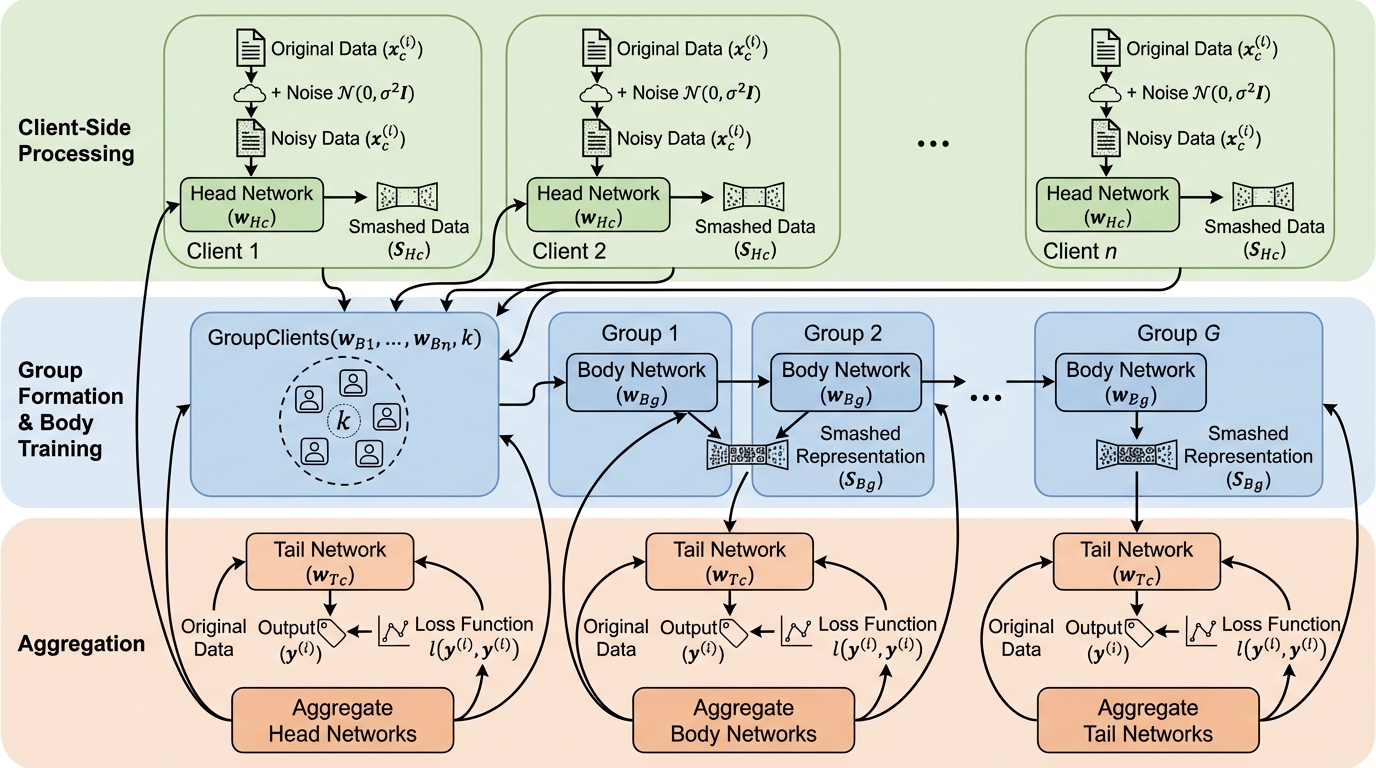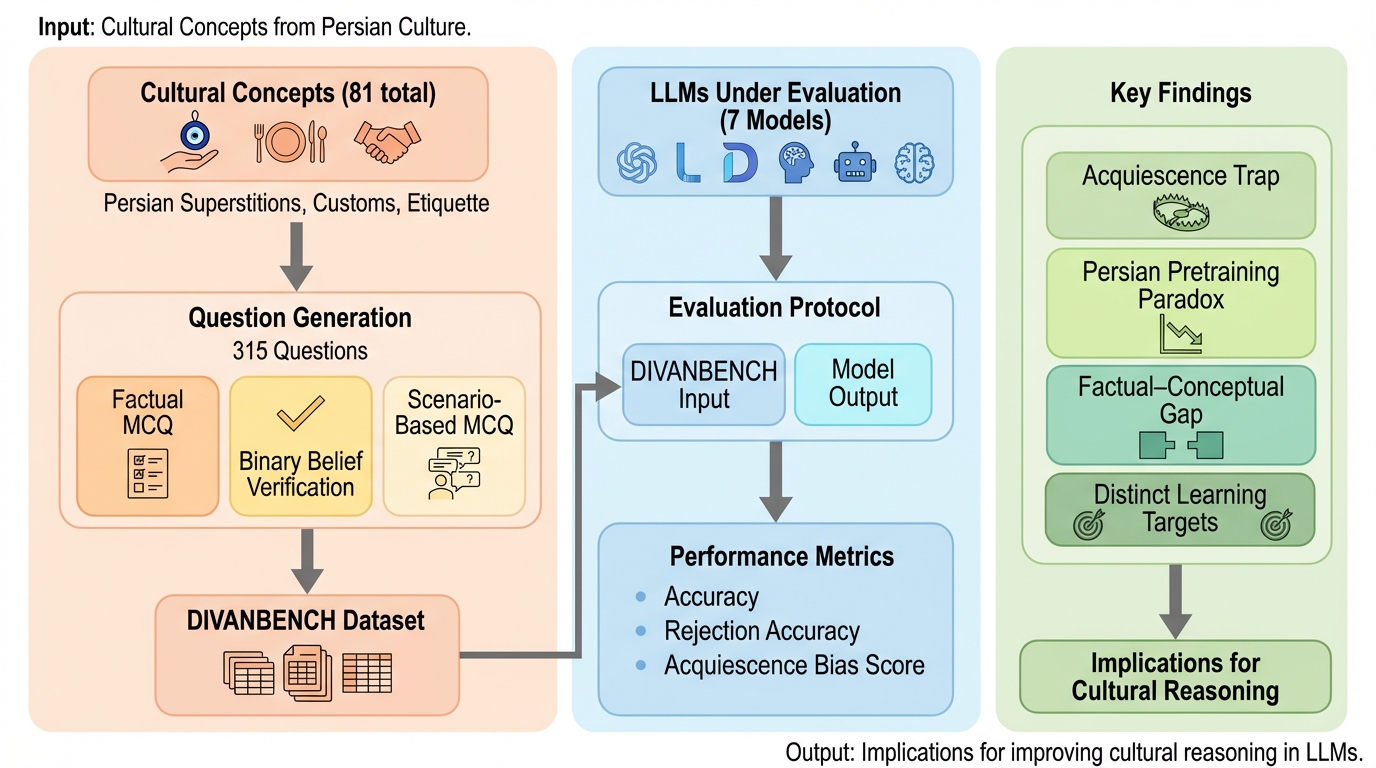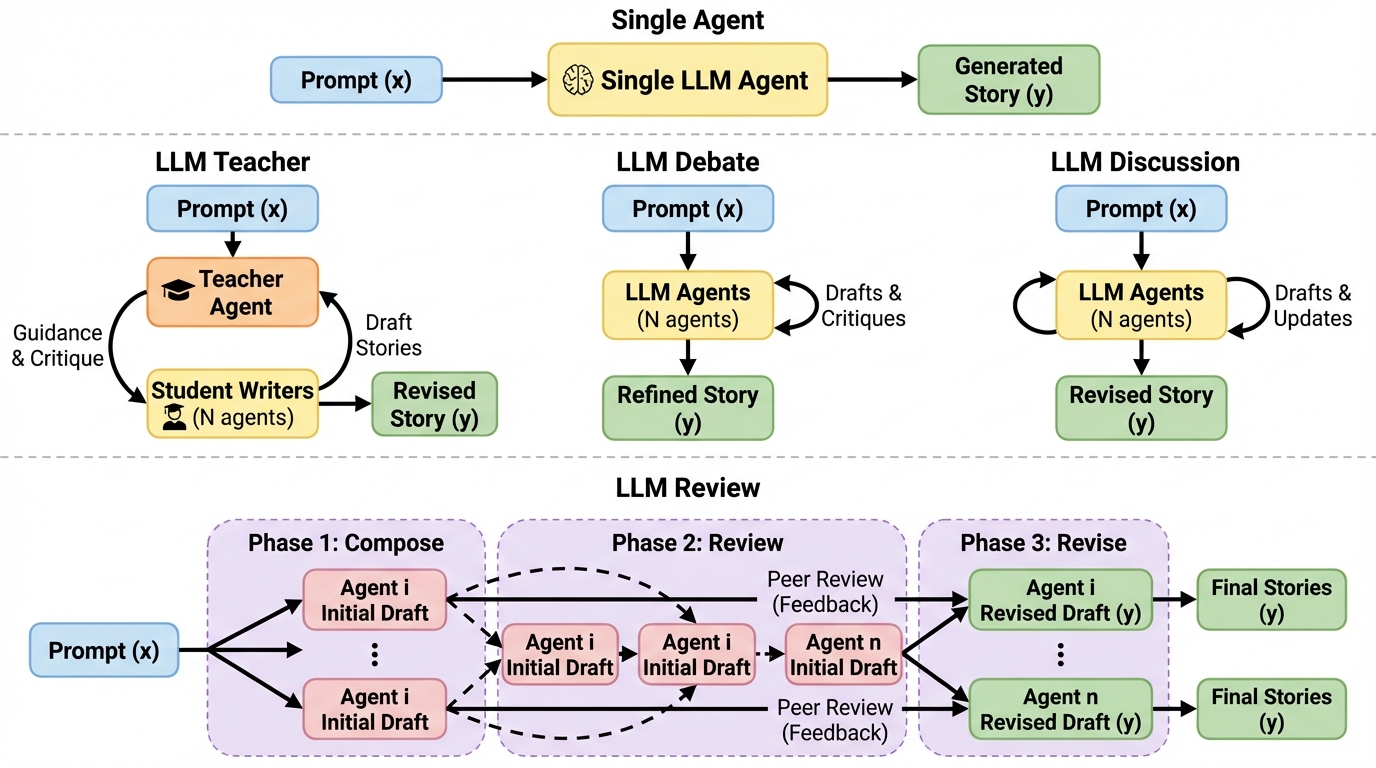
LLM Review:ブラインド・ピアレビュー型フィードバックで創作の均質化を避けるマルチエージェント枠組み。
創作では相互作用を増やすほど良くなるとは限らず、エージェント同士が互いの出力に引っ張られて内容が似通う「均質化」が起き得るため、情報の流れそのものを設計対象として扱う必要があります。 / LLM Reviewは、複数エージェントがまず独立に初稿を書き、その後に他者の初稿へ狙いを定めた批評だけを返しつつ、改稿では他者の改稿結果を見せない「ブラインド・ピアレビュー」型の反復を行います。 / サイエンスフィクション短編用データセットSciFi-100と、採点モデルによる評価・人手注釈・規則ベース新規性指標を組み合わせた検証で、提案枠組みが複数のマルチエージェント基準法より一貫して良い結果を示し、相互作用の構造がモデル規模を一部代替し得ることが示唆されます。