MeanCache: Flow Matching推論を加速するための、瞬時速度から平均速度へ
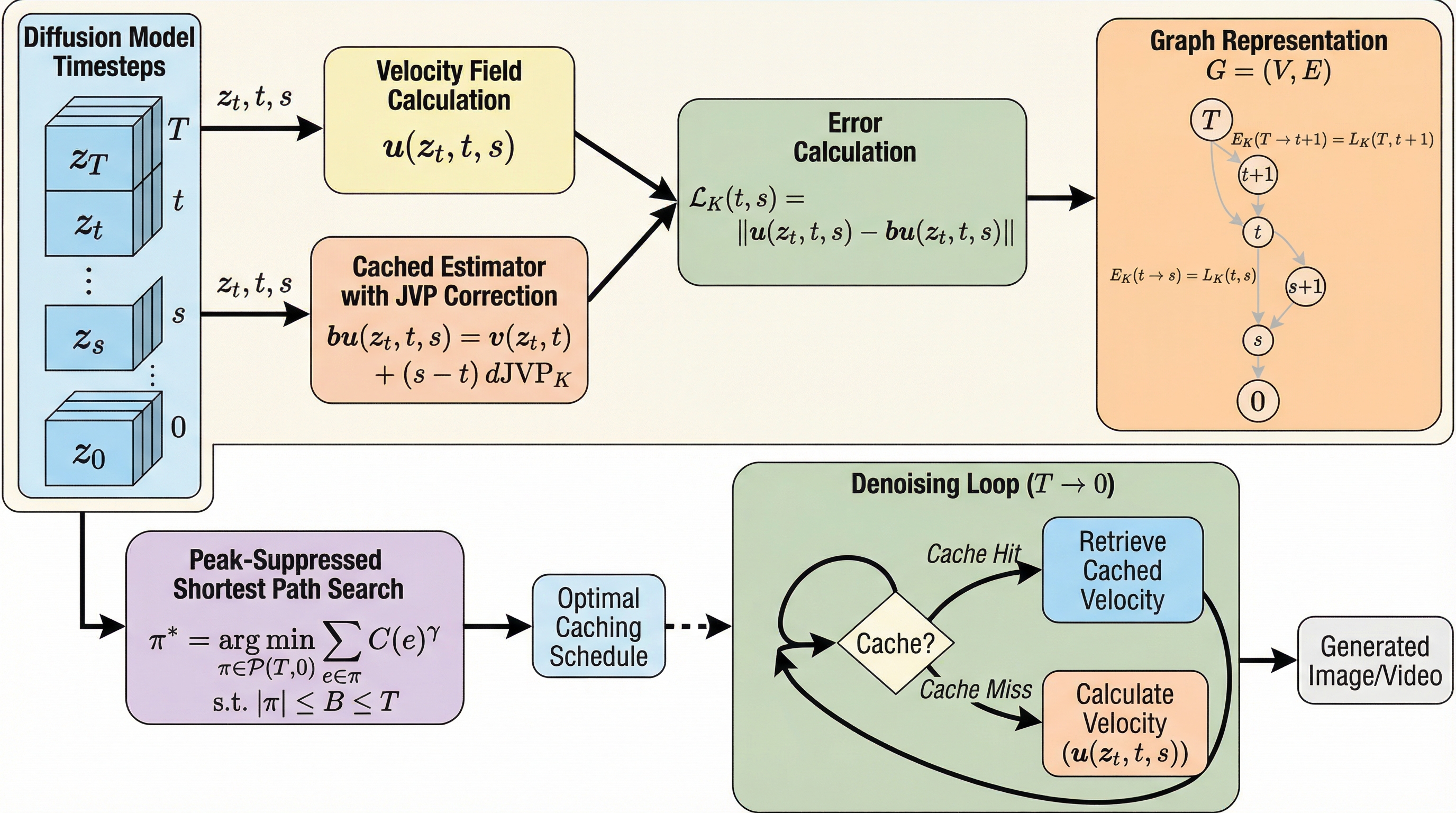
Flow Matchingを用いた生成モデルにおいて、従来のキャッシュ手法が依存していた「瞬間速度」の情報は変動が激しく、高い加速率では軌道の逸脱や誤差の蓄積を招くという課題がありました。本研究が提案する「MeanCache」は、瞬間速度を「区間平均速度」へと変換し、キャッシュされたヤコビアン・ベクトル積(JVP)を用いて軌道を補正することで、学習不要かつ軽量な形で生成品質を維持しながら推論を大幅に高速化します。FLUX.1やHunyuanVideoなどの商用規模モデルを用いた検証では、最大で4.56倍の高速化を達成し、既存の最先端手法と比較しても高い画像・動画品質と構造的一貫性を保持できることが実証されました。