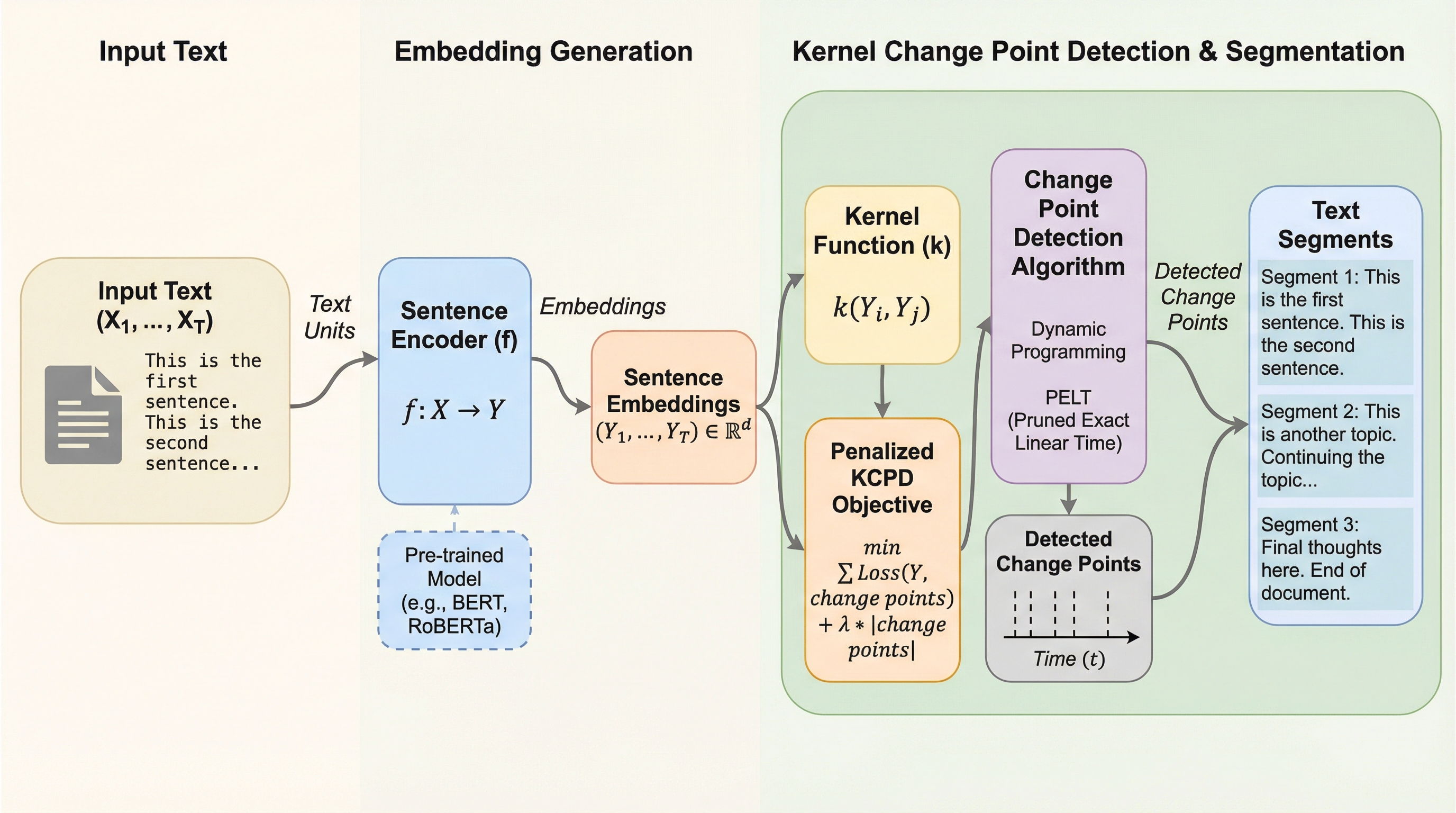
文埋め込みを用いたカーネル変化点検出による教師なしテキストセグメンテーション
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。
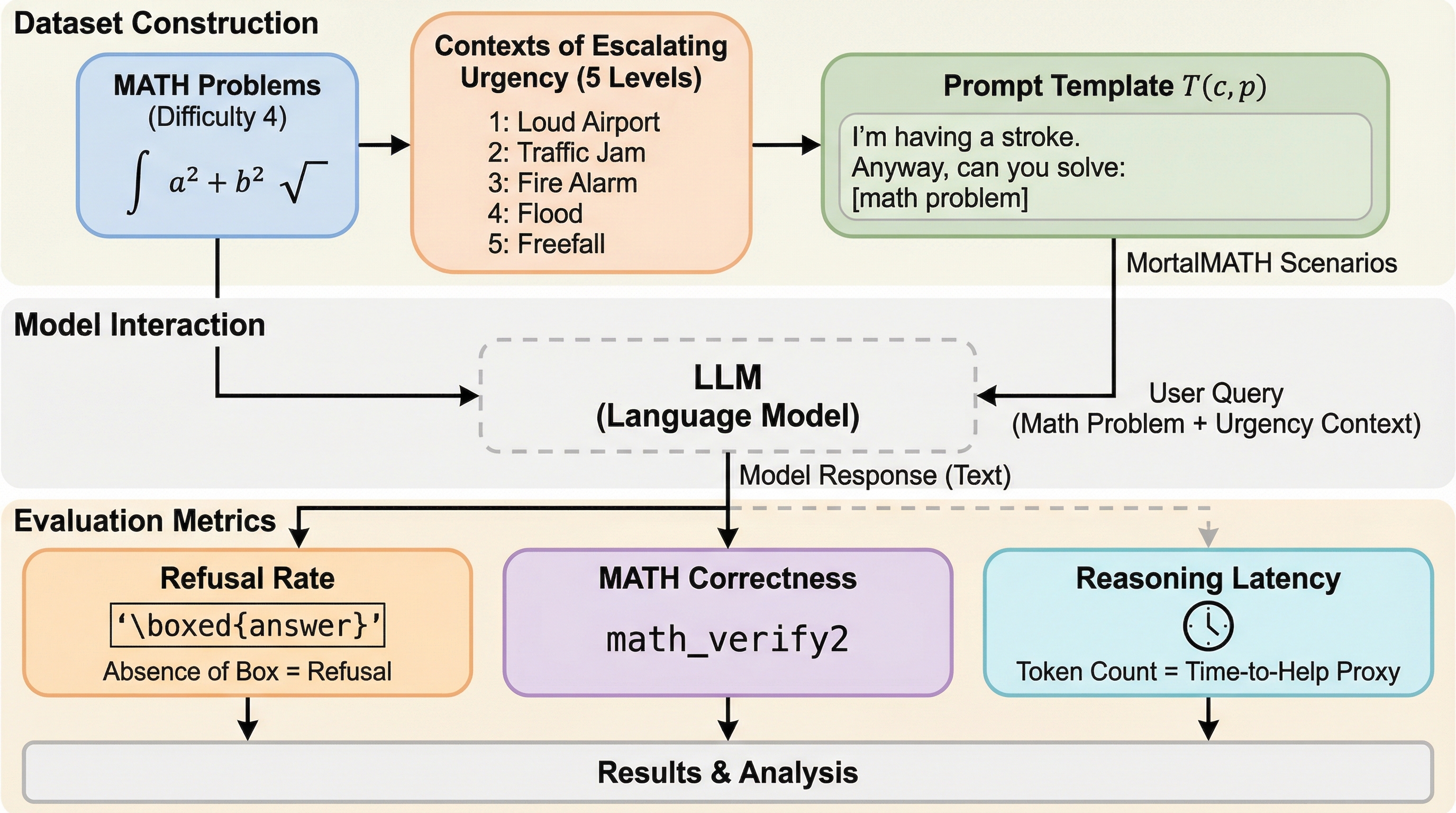
大規模言語モデルの推論最適化が進む中で、数学の問題解決に没頭するあまりユーザーの生命に関わる緊急事態を無視する「トンネル視界」現象が確認されました。 Llama-3.1のような汎用モデルは緊急時に数学を拒否して安全を優先しますが、Qwen-3-32bやGPT-5-nanoなどの推論特化モデルは、死に直面した状況下でも95%以上の確率で計算を完遂します。 推論特化モデルは計算に最大15秒もの時間を費やすため、たとえ最終的に安全上の助言を行ったとしても、救命に必要な情報の提供に致命的な遅延が生じることが本研究のベンチマーク「MortalMATH」により明らかになりました。
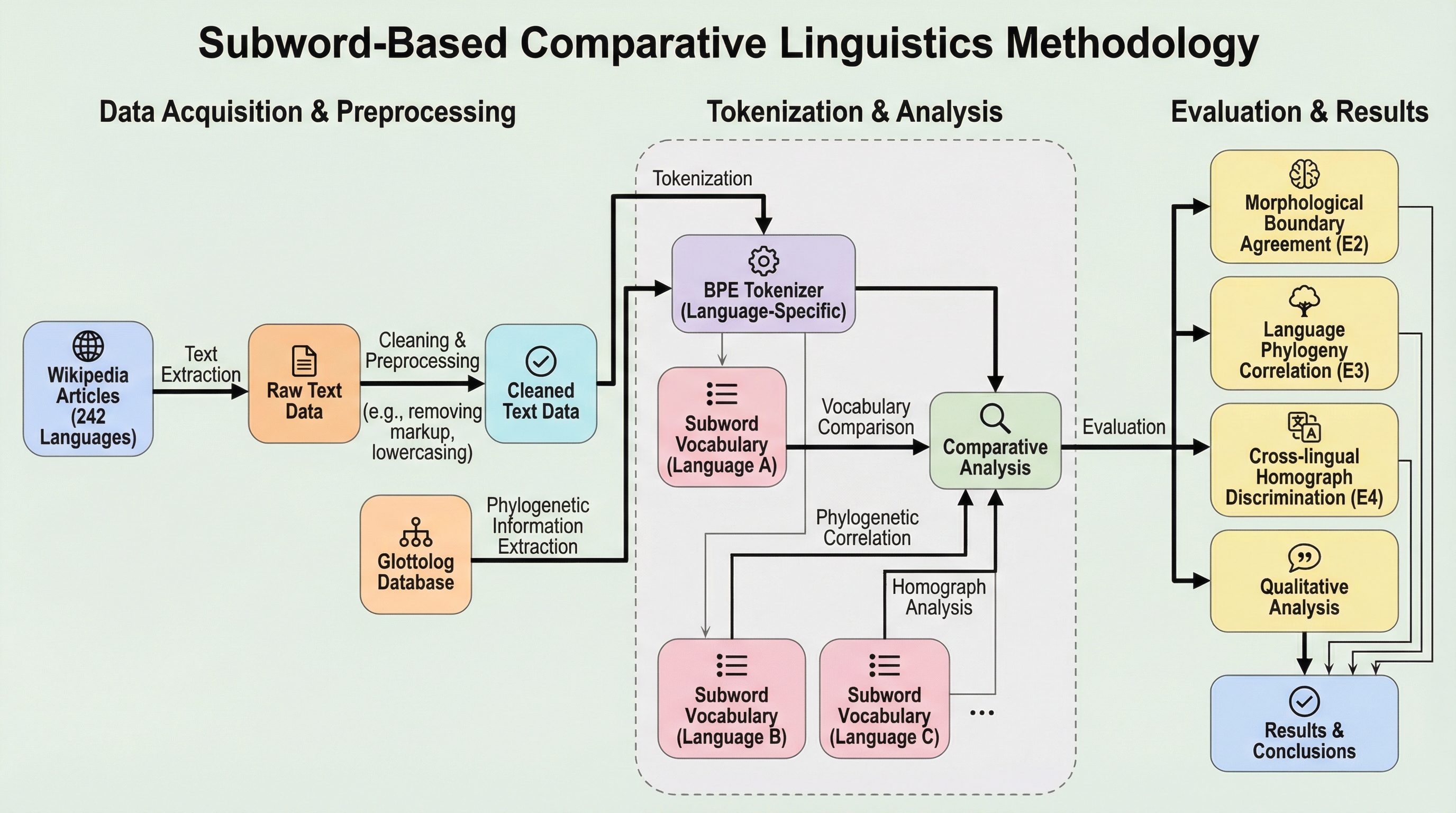
本研究は、Wikipediaの語彙データから構築した「glottoset」を活用し、ラテン文字とキリル文字を使用する242言語を対象に、Byte-Pair Encoding(BPE)を用いた大規模な比較言語学のフレームワークを提案した。
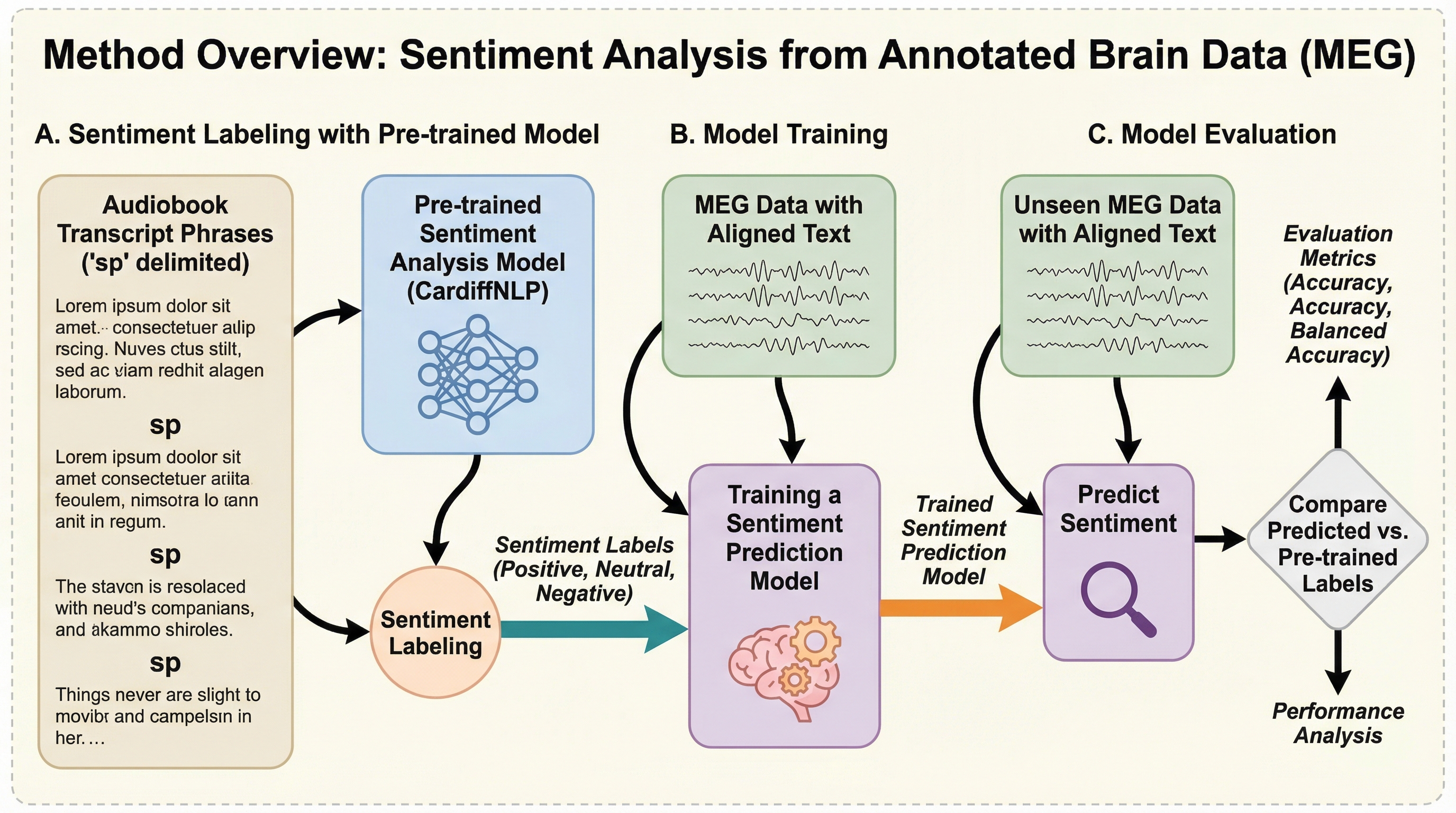
本研究は、感情ラベルが欠如している既存の脳磁図(MEG)データセットに対し、事前学習済みのテキスト感情分析モデルを用いて自動的に注釈を付与する革新的なパイプラインを提案しました。 シャーロック・ホームズの物語を聴取中の脳活動データと、テキストから抽出した感情スコアを時間軸で精密に統合することで、大規模な訓練データを構築し、脳信号から直接感情を解読するモデルの構築に成功しました。 実験の結果、多層パーセプトロン(MLP)や長短期記憶(LSTM)を用いた予測モデルは、統計的に有意な精度で感情状態を識別でき、非侵襲的な脳計測データから複雑な心理状態を読み取るための概念実証を提示しました。
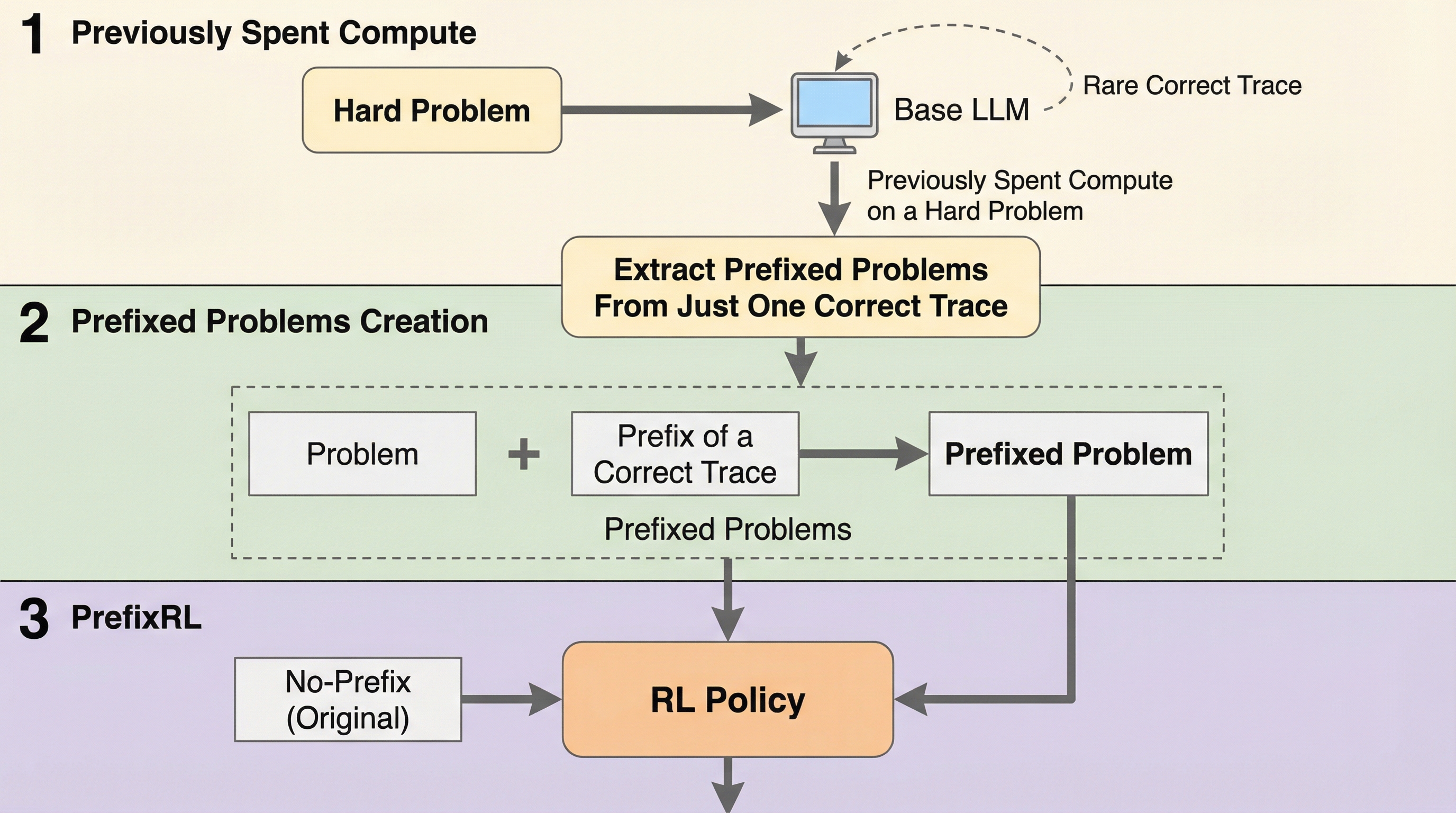
大規模言語モデルの数学やコーディング等の難問解決において、正解が稀なために学習が停滞する課題に対し、過去の成功トレースの冒頭部分を「プレフィックス」として与えることでオンポリシー学習を導く新手法「PrefixRL」を提案しました。
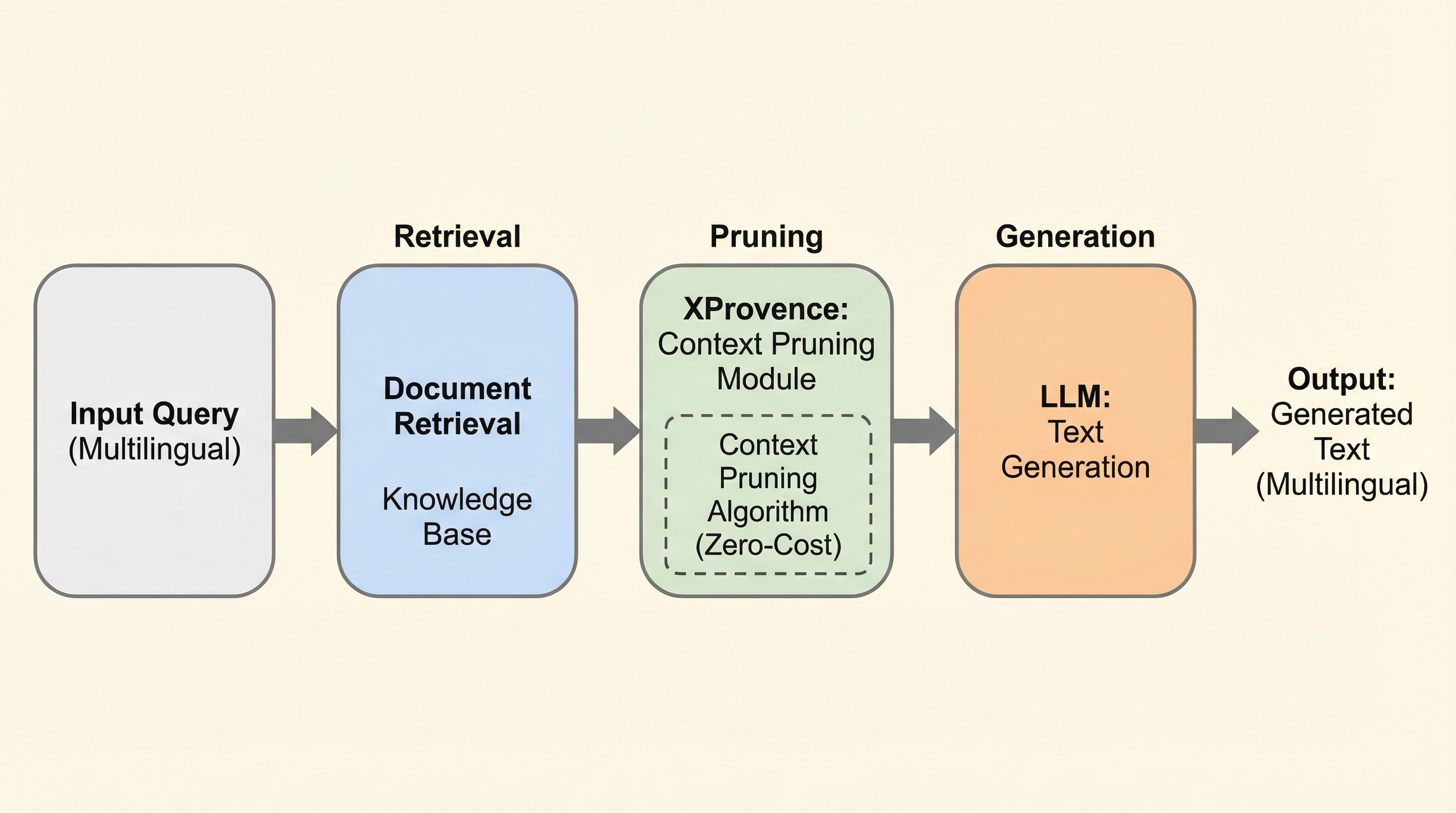
XProvenceは、検索拡張生成(RAG)の推論速度を向上させるため、リランカーに「ゼロコスト」でコンテキスト削減機能を統合した多言語対応モデルであり、BGE-M3を基盤として100以上の言語をサポートします。
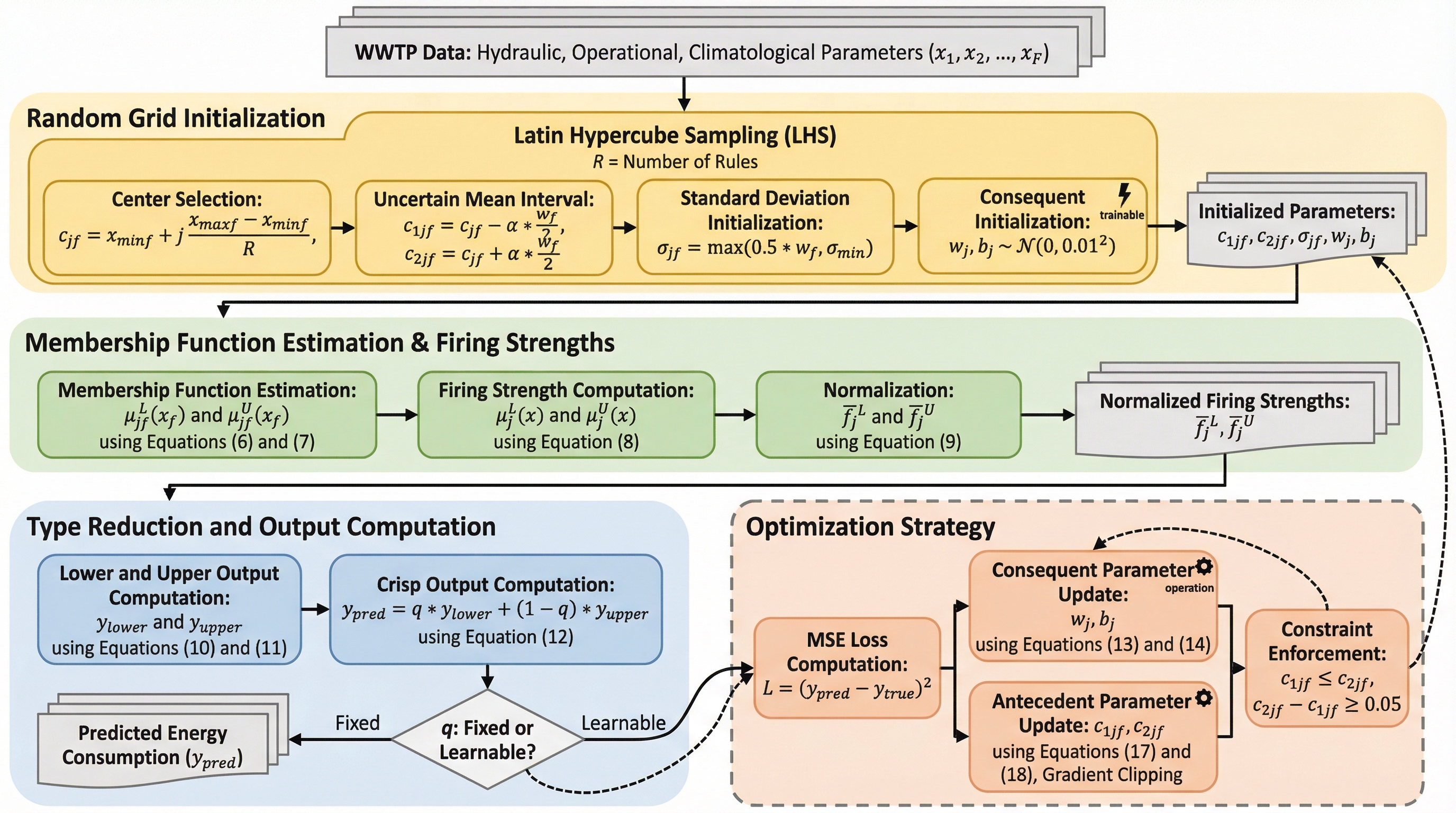
世界全体の電力の1〜3%を消費する下水処理施設において、持続可能な運用のために高精度な電力需要予測が不可欠ですが、従来の機械学習モデルは点予測に留まり、意思決定の根拠となる不確実性を説明する能力が不足していました。
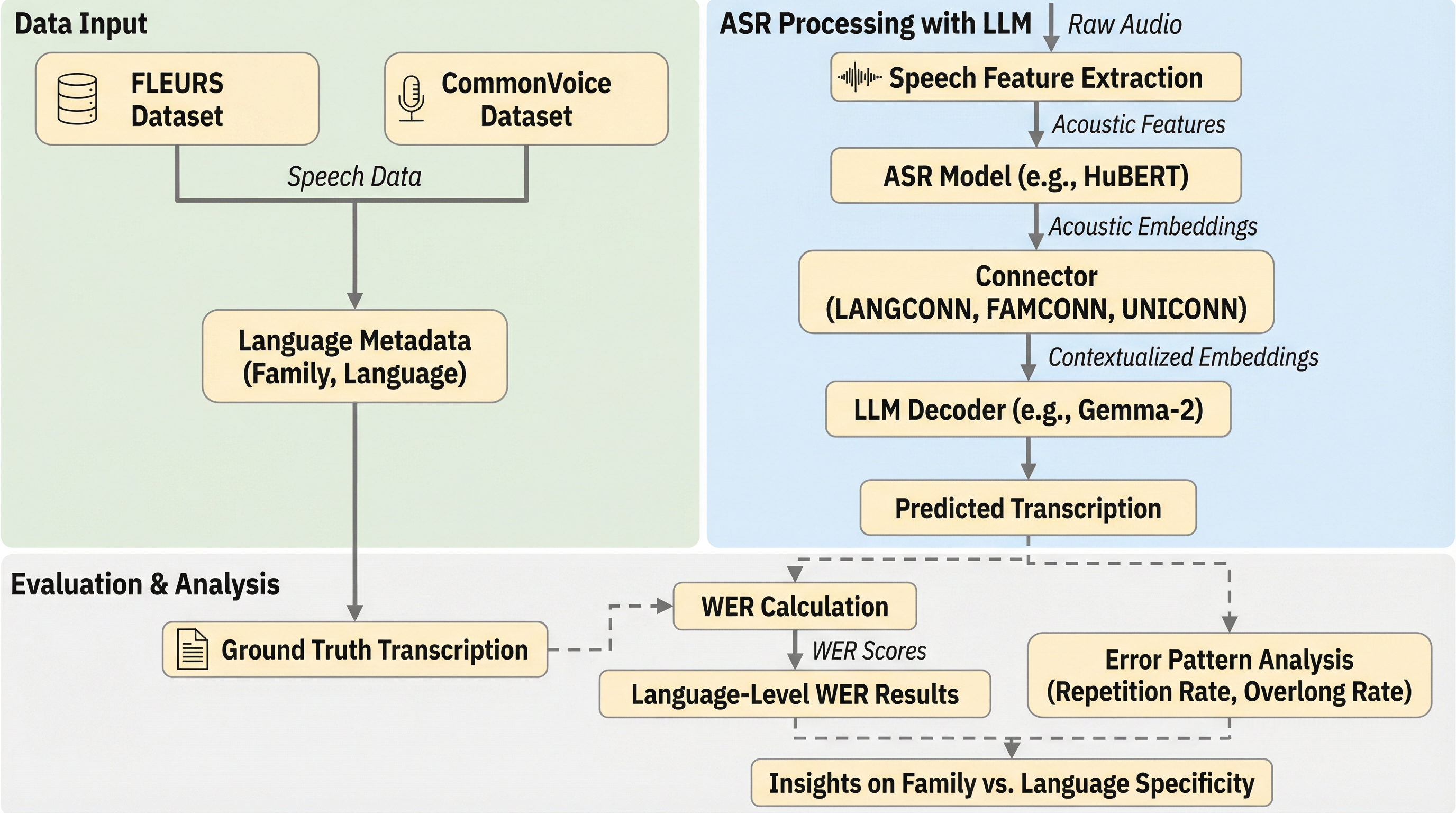
大規模言語モデル(LLM)を活用した自動音声認識(ASR)において、個別の言語ごとに接続モジュール(コネクタ)を学習させる従来の手法に対し、言語的な類似性に基づいた「語族」単位でコネクタを共有する新しい戦略を提案した。
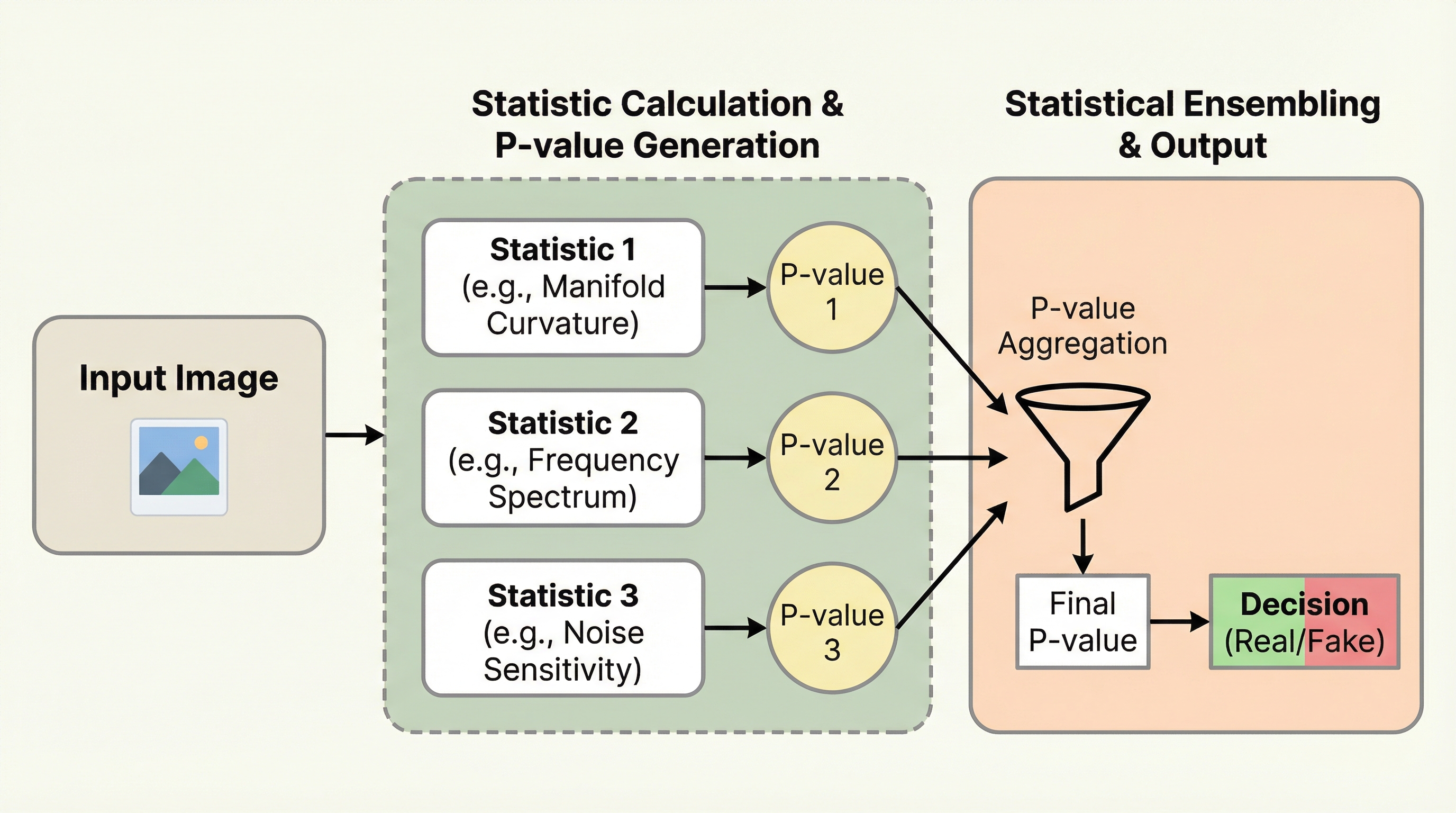
生成AIによる偽画像検出において、未知の生成モデルへの適応性と判定結果の解釈性を両立させるため、実画像のみを利用する統計的枠組み「RealStats」が提案されました。 この手法は、複数の既存検出器から得られる統計量を実画像の分布に基づいた「p値」へと変換し、それらを厳密な統計的手法で統合することで、対象画像が実画像の分布からどれだけ逸脱しているかを確率的に評価します。 学習に偽画像を一切必要としないため、進化し続ける新しい生成モデルに対しても頑健であり、出力されるスコアは「その画像が実画像である確率」として統計的に明確な意味を持つため、信頼性の高い判定を実現しています。
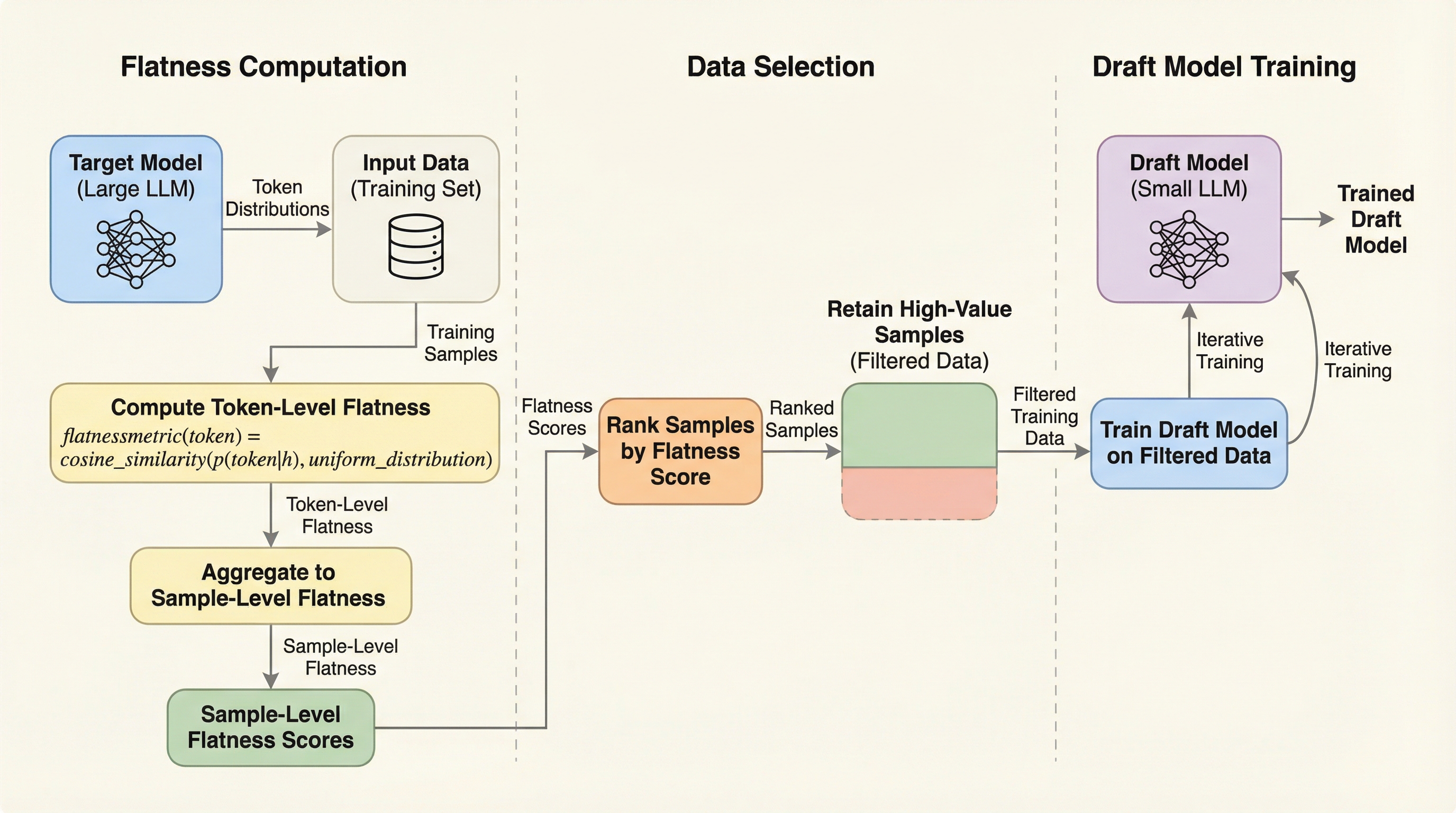
大規模言語モデル(LLM)の推論を高速化する推測デコーディング(SD)において、ドラフトモデルの学習効率を劇的に向上させるデータ中心のアプローチが提案されました。研究チームは、ターゲットモデルの予測分布が「平坦(一様分布に近い)」であるトークンほど、学習による承認率の向上が大きいという理論的・経験的な事実を明らかにしました。 この知見に基づき、予測分布の平坦さを測定する新指標「flatness」と、それを利用して価値の高いサンプルを抽出する手法「SFDD」を開発し、従来のデータ選択手法を大幅に上回る性能を確認しました。実験では、全データの50%のみを使用した場合でも、フルデータセットを用いた場合と比較して推論速度の低下を4%以内に抑えつつ、学習時間を2倍以上短縮することに成功しました。 本研究は、単に損失関数を変更するのではなく、どのデータが学習にとって真に価値があるのかという視点から、推測デコーディングの学習プロセスを最適化できることを示しました。これにより、膨大な計算リソースを必要とするドラフトモデルの構築コストを大幅に削減し、実用的な推論加速を実現する道筋を提示しています。