推測デコーディング用ドラフトモデル学習では平坦なトークンがより価値を持つ
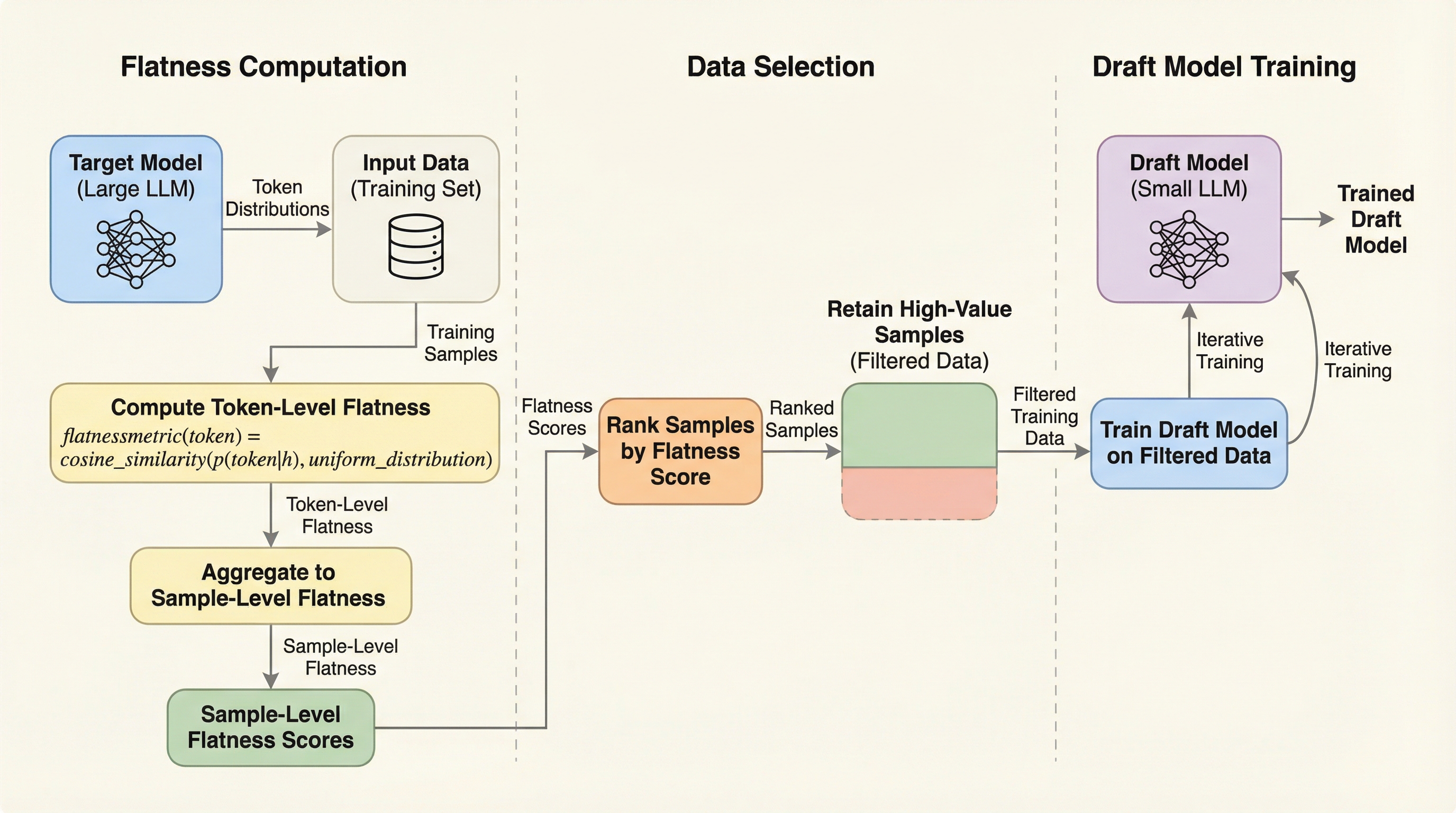
大規模言語モデル(LLM)の推論を高速化する推測デコーディング(SD)において、ドラフトモデルの学習効率を劇的に向上させるデータ中心のアプローチが提案されました。研究チームは、ターゲットモデルの予測分布が「平坦(一様分布に近い)」であるトークンほど、学習による承認率の向上が大きいという理論的・経験的な事実を明らかにしました。 この知見に基づき、予測分布の平坦さを測定する新指標「flatness」と、それを利用して価値の高いサンプルを抽出する手法「SFDD」を開発し、従来のデータ選択手法を大幅に上回る性能を確認しました。実験では、全データの50%のみを使用した場合でも、フルデータセットを用いた場合と比較して推論速度の低下を4%以内に抑えつつ、学習時間を2倍以上短縮することに成功しました。 本研究は、単に損失関数を変更するのではなく、どのデータが学習にとって真に価値があるのかという視点から、推測デコーディングの学習プロセスを最適化できることを示しました。これにより、膨大な計算リソースを必要とするドラフトモデルの構築コストを大幅に削減し、実用的な推論加速を実現する道筋を提示しています。
TL;DR(結論)
大規模言語モデル(LLM)の推論を高速化する推測デコーディング(SD)において、ドラフトモデルの学習効率を劇的に向上させるデータ中心のアプローチが提案されました。研究チームは、ターゲットモデルの予測分布が「平坦(一様分布に近い)」であるトークンほど、学習による承認率の向上が大きいという理論的・経験的な事実を明らかにしました。 この知見に基づき、予測分布の平坦さを測定する新指標「flatness」と、それを利用して価値の高いサンプルを抽出する手法「SFDD」を開発し、従来のデータ選択手法を大幅に上回る性能を確認しました。実験では、全データの50%のみを使用した場合でも、フルデータセットを用いた場合と比較して推論速度の低下を4%以内に抑えつつ、学習時間を2倍以上短縮することに成功しました。 本研究は、単に損失関数を変更するのではなく、どのデータが学習にとって真に価値があるのかという視点から、推測デコーディングの学習プロセスを最適化できることを示しました。これにより、膨大な計算リソースを必要とするドラフトモデルの構築コストを大幅に削減し、実用的な推論加速を実現する道筋を提示しています。
なぜこの問題か
現代の大規模言語モデル(LLM)は、生成、理解、対話といった多様なタスクで優れた成果を上げていますが、その推論プロセスには自己回帰的デコーディングに起因する大きな課題があります。各トークンを順番に生成する必要があるため、並列化が困難で、結果として高いレイテンシと低いスループットを招いています。この問題を解決するための有力な手法が「推測デコーディング(SD)」です。SDでは、軽量なドラフトモデルが複数の候補トークンを素早く生成し、それを巨大なターゲットモデルが並列に検証することで、1回の前方計算で複数のトークンを確定させ、推論を加速させます。 SDの手法は、追加学習を行わない「学習不要(train-free)」型と、ドラフトモデルをターゲットモデルに適合させる「学習ベース(train-based)」型に大別されます。学習不要な手法は導入が容易ですが、ドラフトモデルとターゲットモデルの整合性が低いため、トークンの承認率が低くなりやすく、頻繁なロールバックが発生するという欠点があります。一方で、学習ベースの手法はドラフトモデルをターゲットモデルの出力分布に合わせるように微調整するため、より高い承認率と安定した加速を実現できます。…
核心:何を提案したのか
本研究では、SDの学習においてすべてのトークンが等しく貢献するわけではないという仮説に基づき、データ選択の新しい基準を提案しました。具体的には、ターゲットモデルが出力する予測分布の「平坦さ(flatness)」に着目しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related