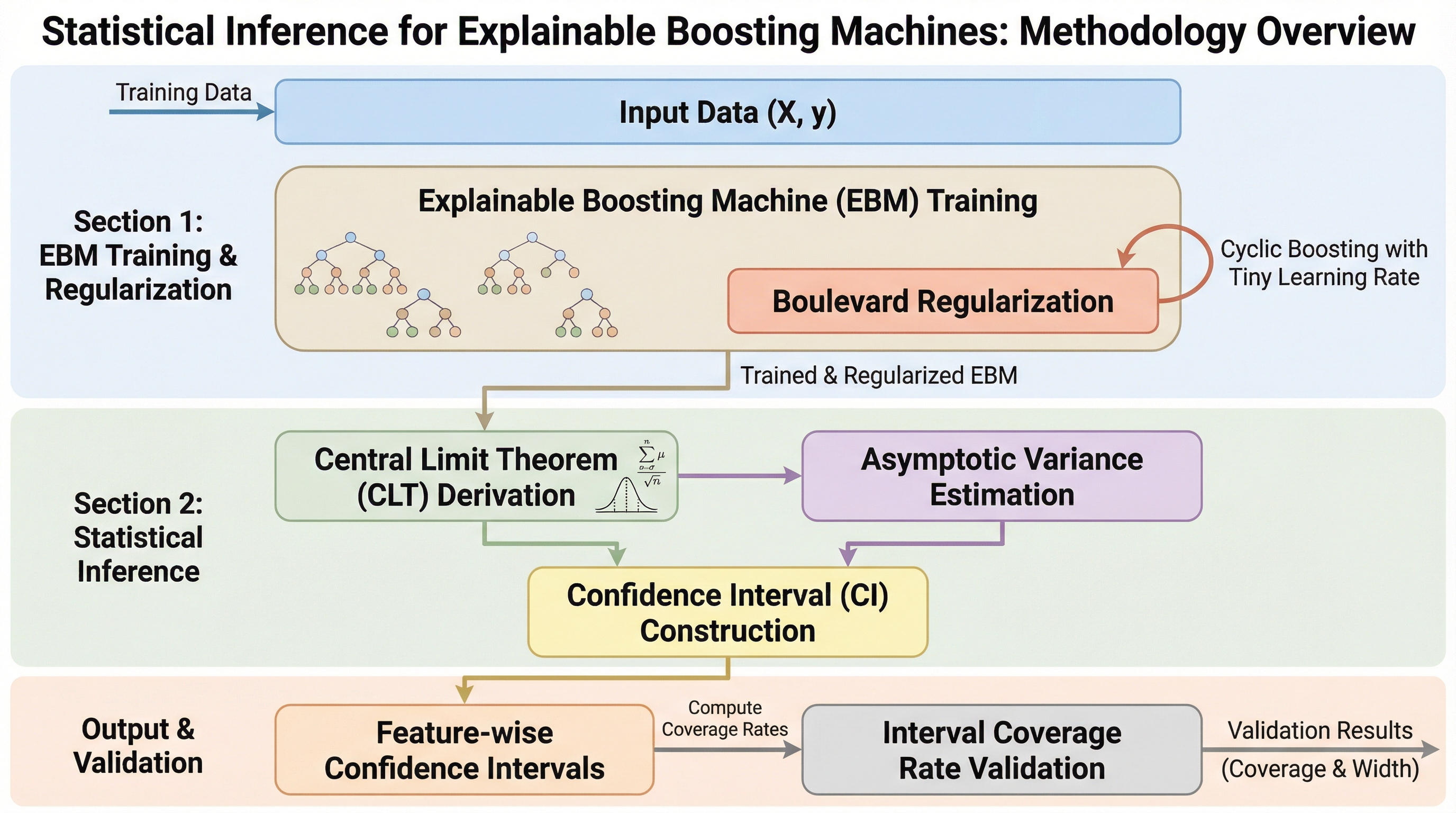
説明可能なブースティングマシンのための統計的推論
本研究は、解釈性の高い「グラスボックス」モデルである説明可能なブースティングマシン(EBM)に、移動平均を用いたブールバード正則化を導入することで、学習プロセスを特徴量ごとのカーネルリッジ回帰へと収束させる理論的枠組みを構築しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、解釈性の高い「グラスボックス」モデルである説明可能なブースティングマシン(EBM)に、移動平均を用いたブールバード正則化を導入することで、学習プロセスを特徴量ごとのカーネルリッジ回帰へと収束させる理論的枠組みを構築しました。
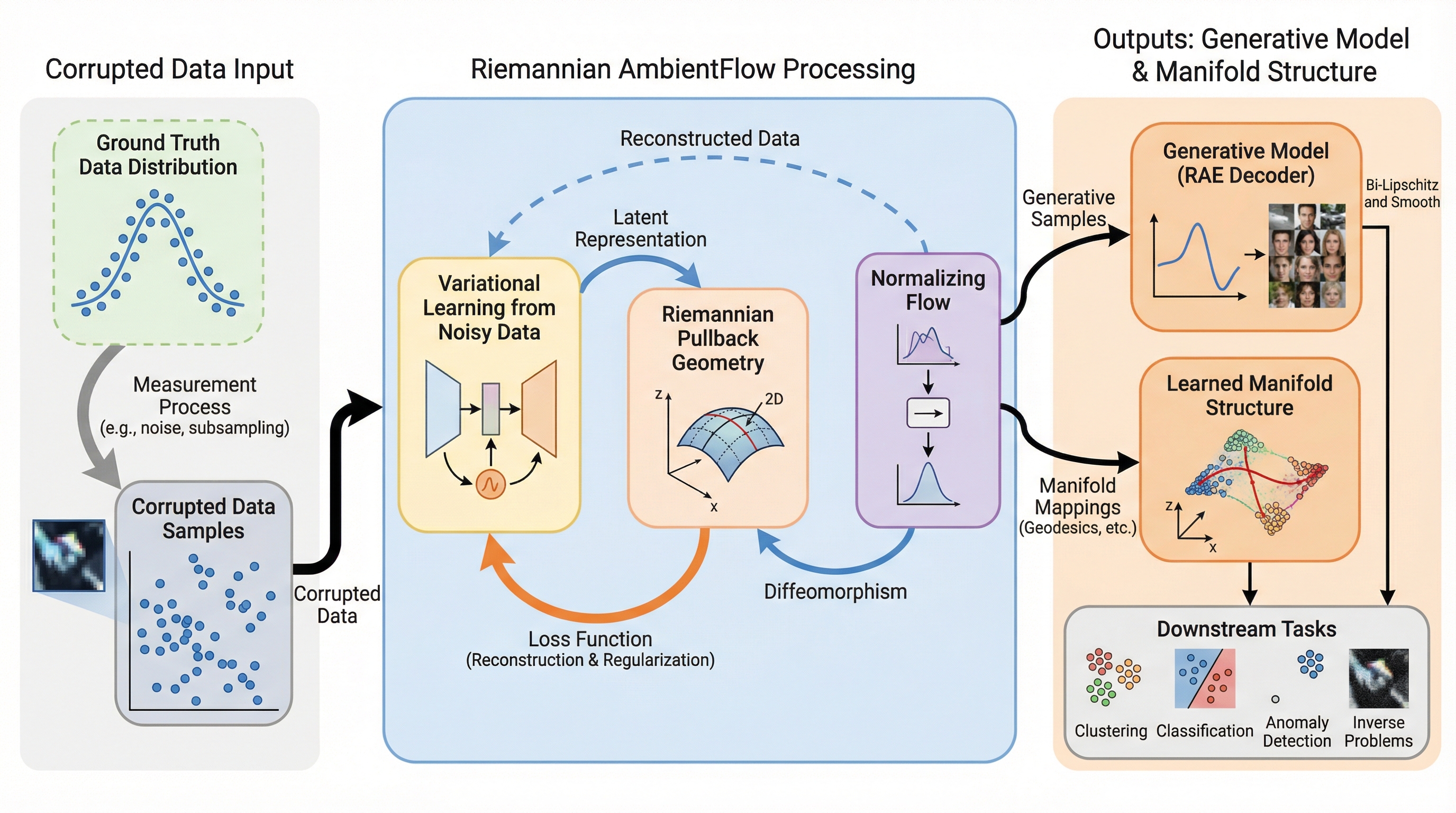
本研究は、ノイズや線形な汚染を含む観測データのみから、データの背後にある非線形な多様体構造と確率的生成モデルを同時に学習する新しい枠組み「Riemannian AmbientFlow」を提案しました。
Reflectは、大規模言語モデルを自然言語の原則(憲法)に適合させるための、追加学習や人間による注釈を一切必要としない推論時フレームワークである。 初期回答の生成、自己評価、自己批判、最終修正という4段階のプロセスをインコンテキストで実行することで、モデルの判断を透明化し、複雑な価値観への適合性を大幅に向上させる。
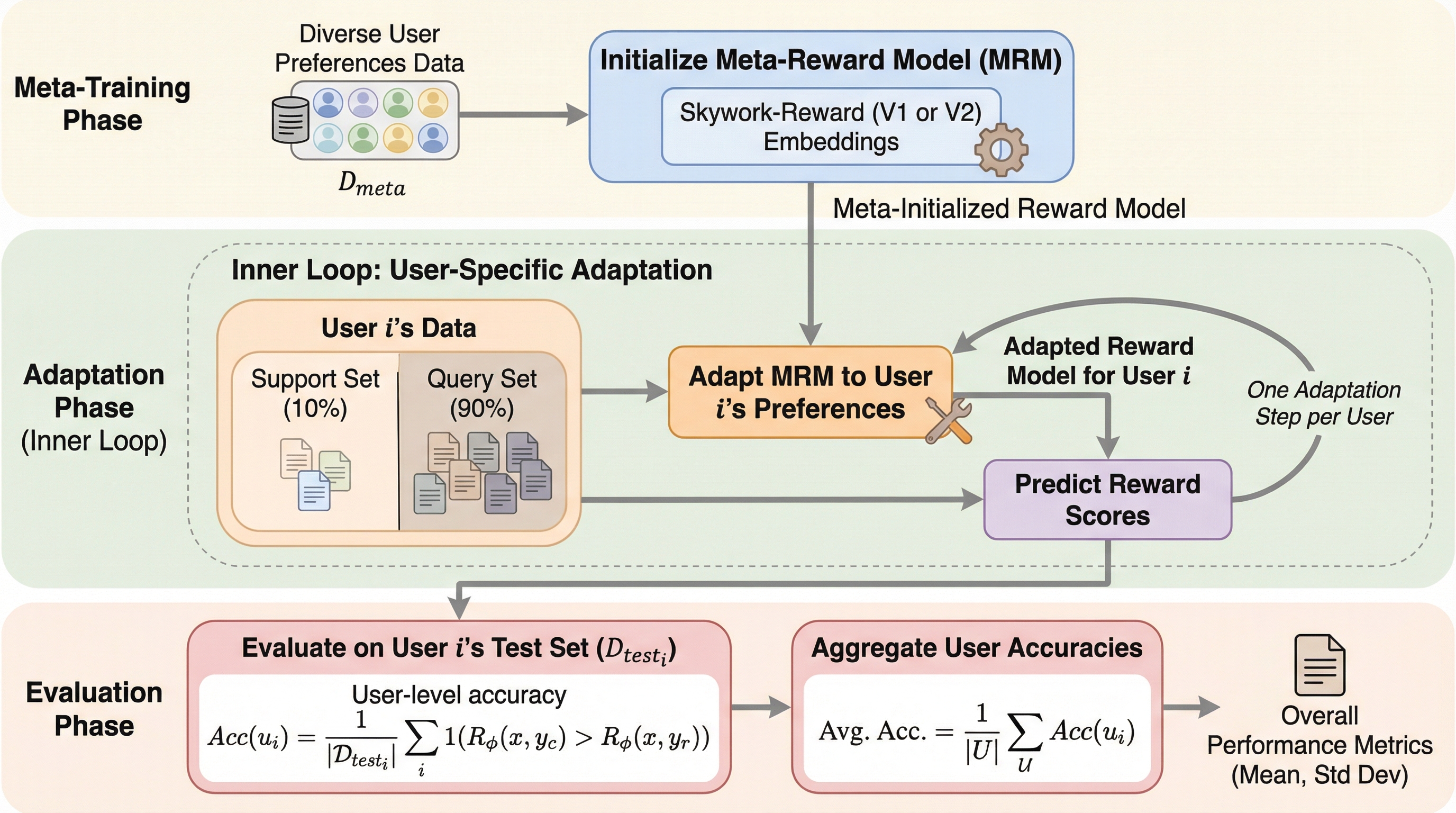
大規模言語モデル(LLM)を個々のユーザーの多様な好みに適応させるため、メタ学習の枠組みを用いた新しい報酬モデリング手法「Meta Reward Modeling(MRM)」が提案されました。この手法は、少数のフィードバックから未知のユーザーの意図を迅速に学習する「学習のプロセス」そのものを最適化することで、従来の個別化手法が抱えていたデータの希少性や過学習、未知のユーザーへの対応といった課題を根本から解決します。さらに、学習が困難なユーザーを優先的に扱う「Robust Personalization Objective(RPO)」を導入することで、特異な価値観を持つユーザーに対しても一貫して高い精度と堅牢なパフォーマンスを保証し、公平で精緻なパーソナライズを実現しました。
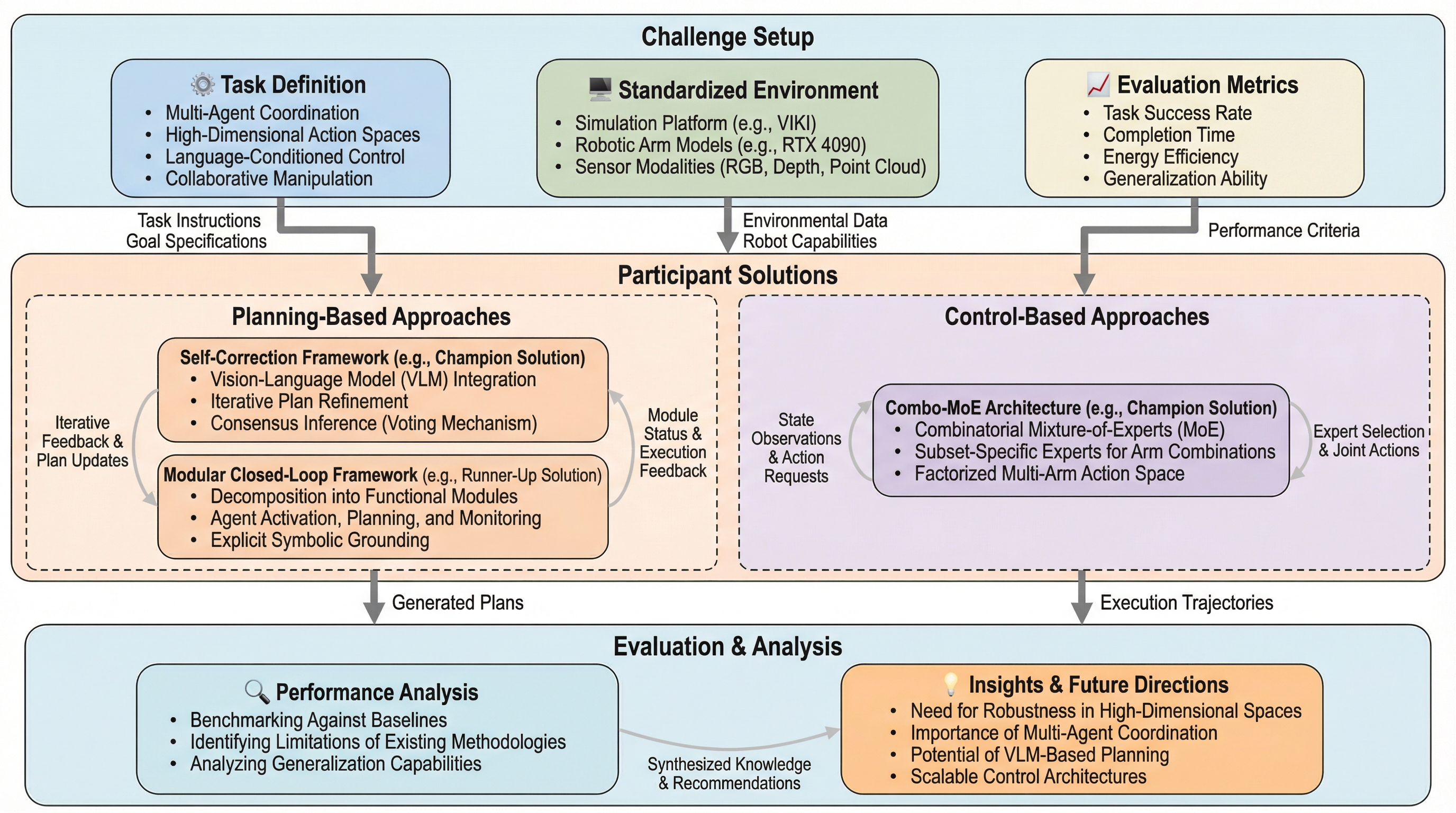
複雑なタスクを解決するため、複数のロボットが協力するマルチエージェント・ロボットシステム(MARS)チャレンジが提案された。この競技会は、視覚言語モデル(VLM)を用いた高レベルな「プランニング」と、物理シミュレーション環境での低レベルな「制御」の2つのトラックで構成されている。
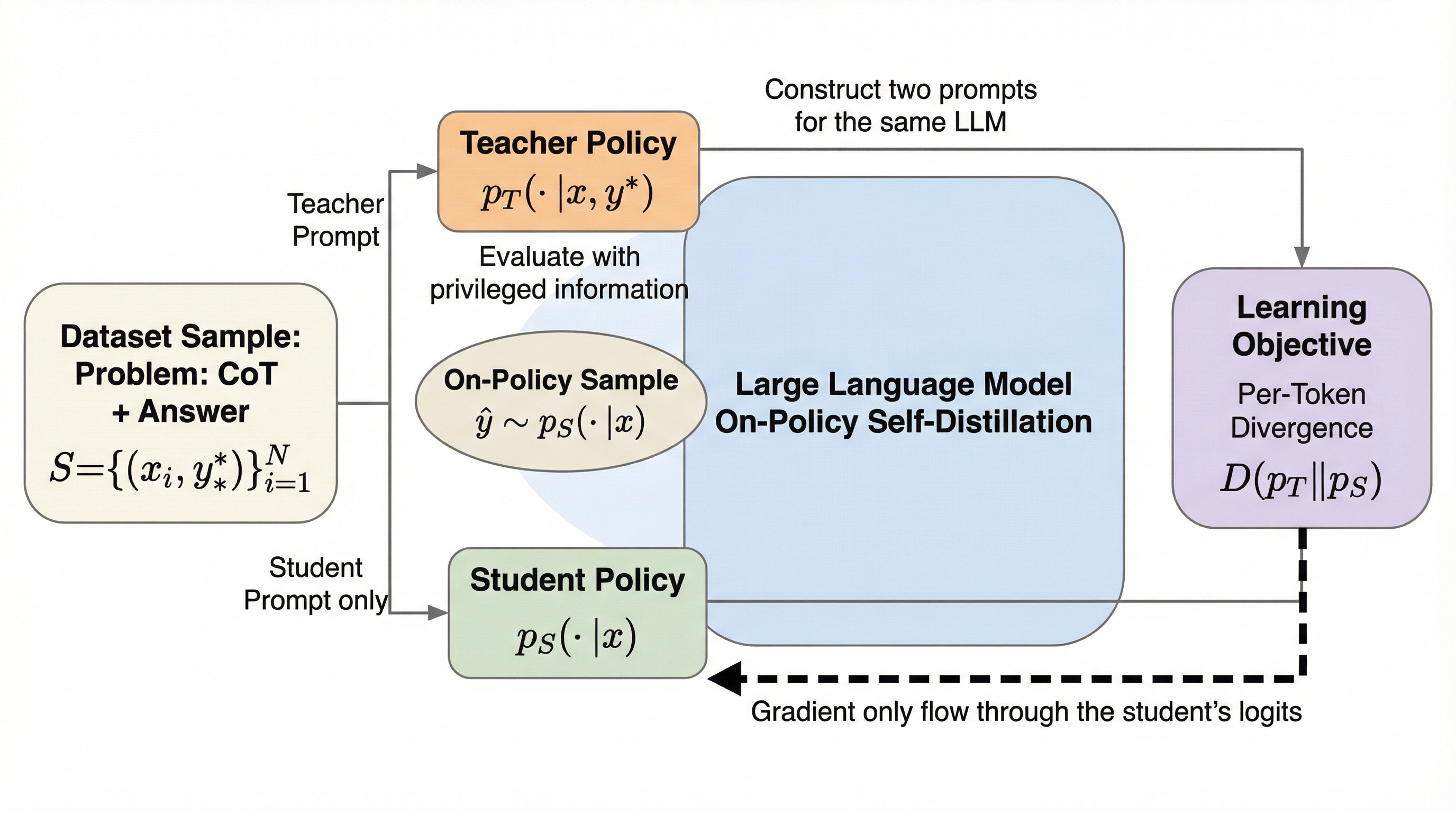
大規模言語モデルの推論能力を向上させるため、外部の教師モデルを必要とせず、単一のモデルが特権情報を活用して自分自身を教育する「オンポリシー自己蒸留(OPSD)」という新しい学習枠組みが提案されました。
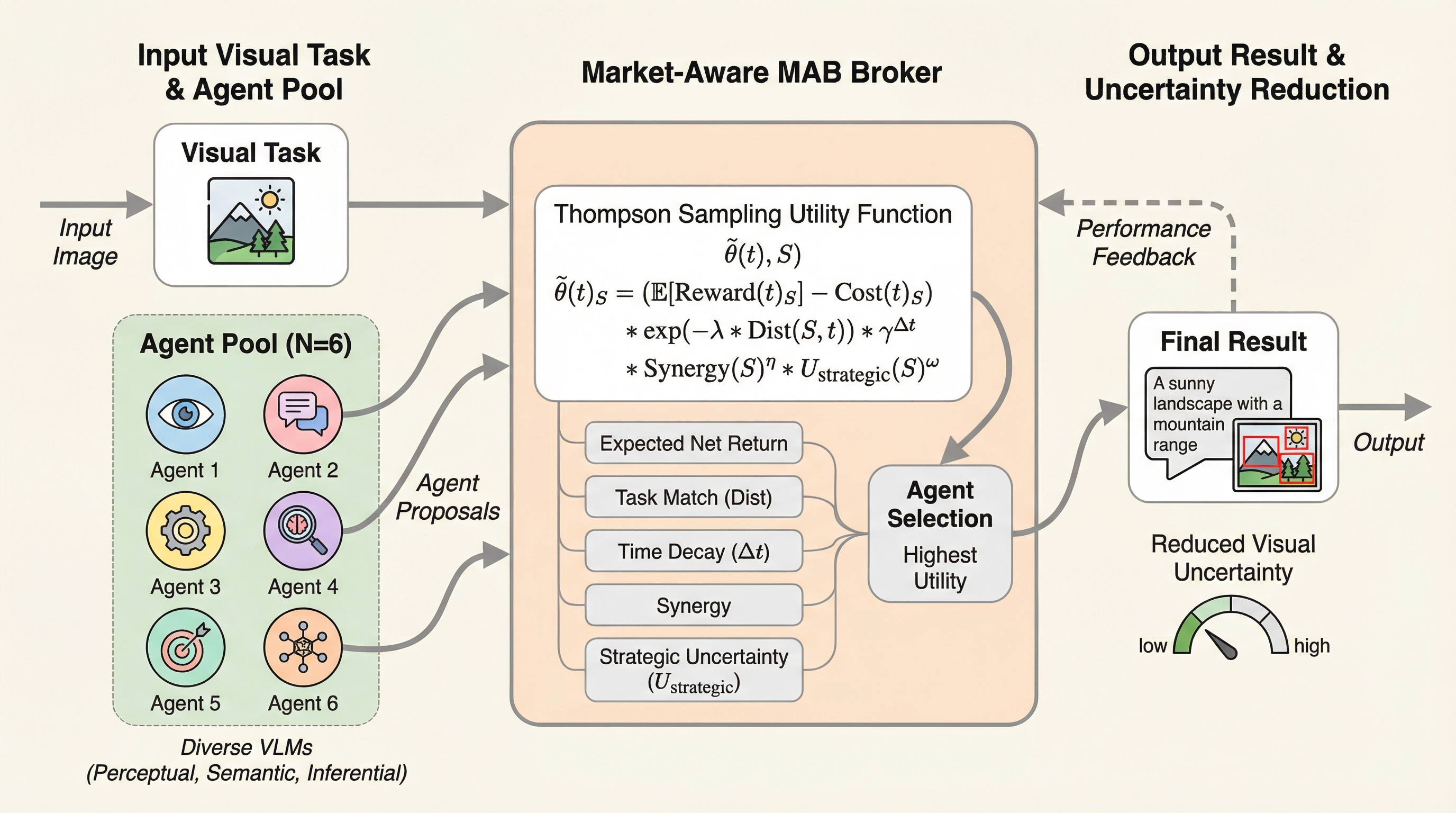
視覚言語モデル(VLM)を用いたマルチエージェントシステムにおいて、情報の非対称性と調整コストの増大という経済的課題を解決するため、不確実性を「取引可能な資産」と定義する分散型市場フレームワーク「Agora」が提案されました。
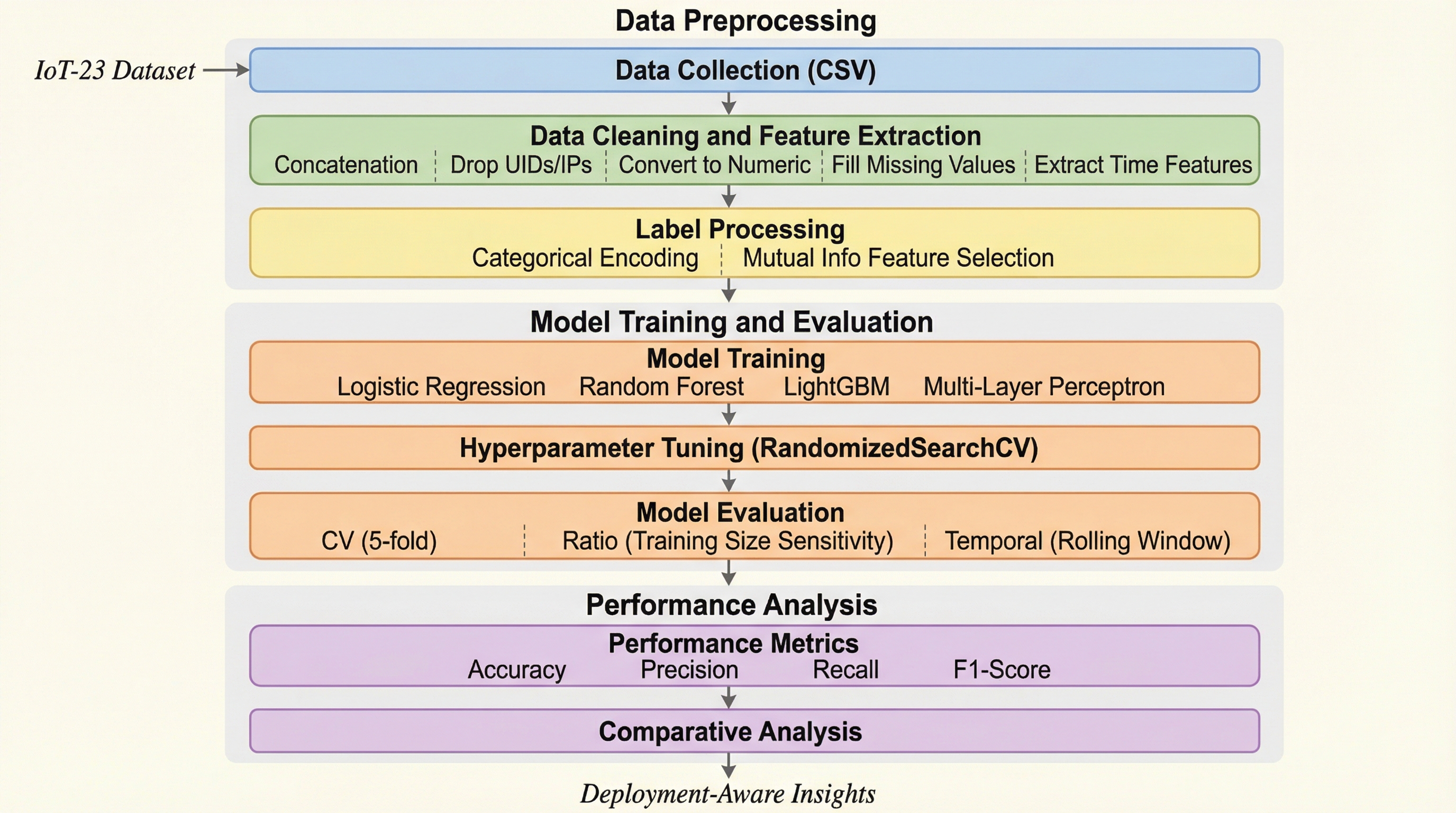
スマートシティや産業インフラで急増するIoTデバイスを保護するため、IoT-23データセットを用いてロジスティック回帰、ランダムフォレスト、LightGBM、多層パーセプトロンの4モデルを、バイナリおよびマルチクラス分類の観点から詳細に評価した。
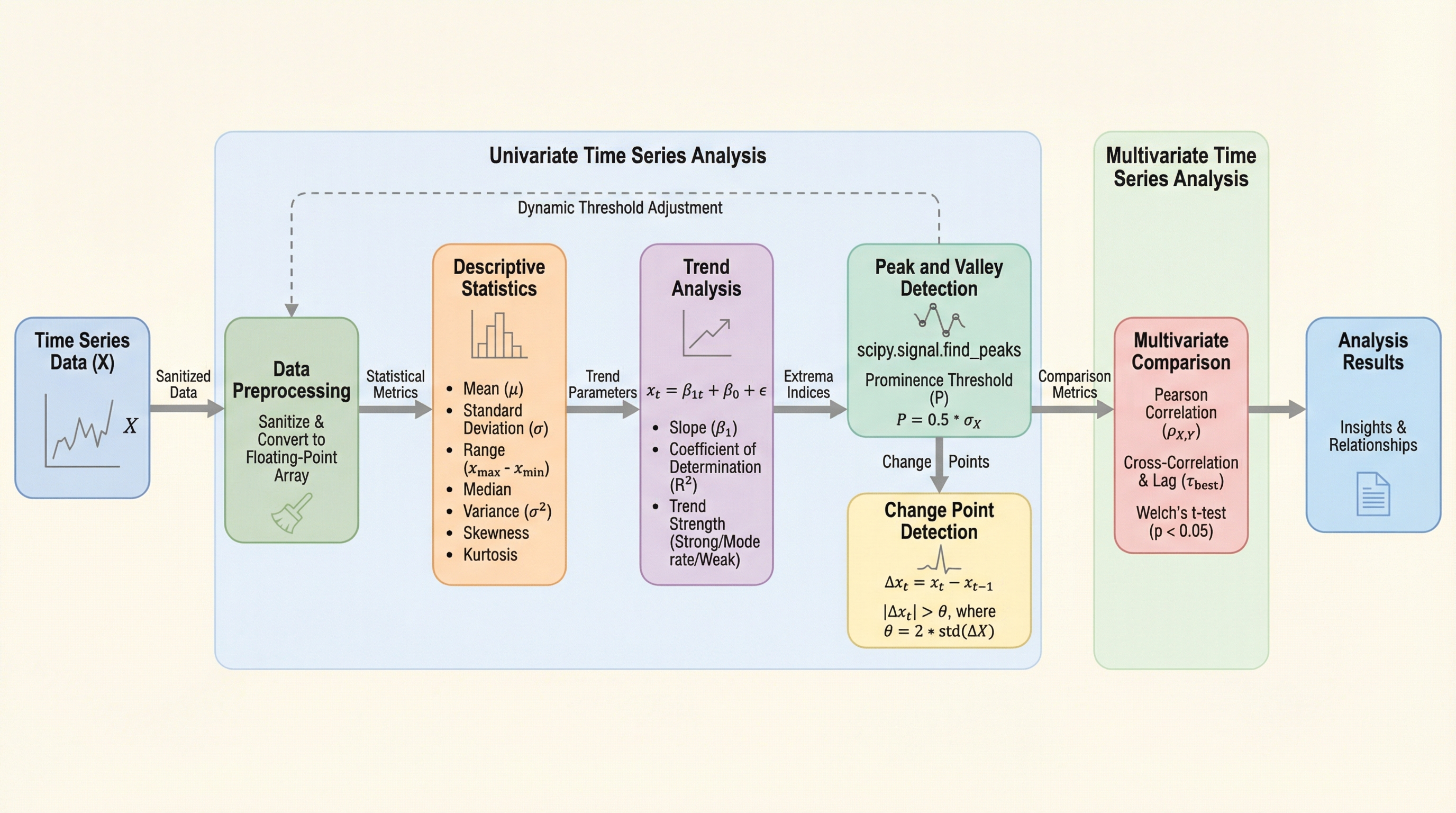
時系列データは現実世界の意思決定において不可欠ですが、従来の評価手法は単純な数値予測に偏り、文脈や因果関係を考慮した高度な推論能力を測定できていませんでした。本研究が提案する「TSRBench」は、14のドメインから収集された4125個の問題を含み、認識、推論、予測、意思決定の4つの次元と15のタスクを通じて、汎用モデルの時系列処理能力を多角的に評価する初の包括的なマルチモーダルベンチマークです。30以上の主要モデルを検証した結果、モデル規模の拡大は認識や論理推論には有効であるものの予測精度には必ずしも直結せず、また現在のマルチモーダルモデルはテキストと視覚情報の統合において相乗効果を生み出せていないという重要な課題が明らかになりました。
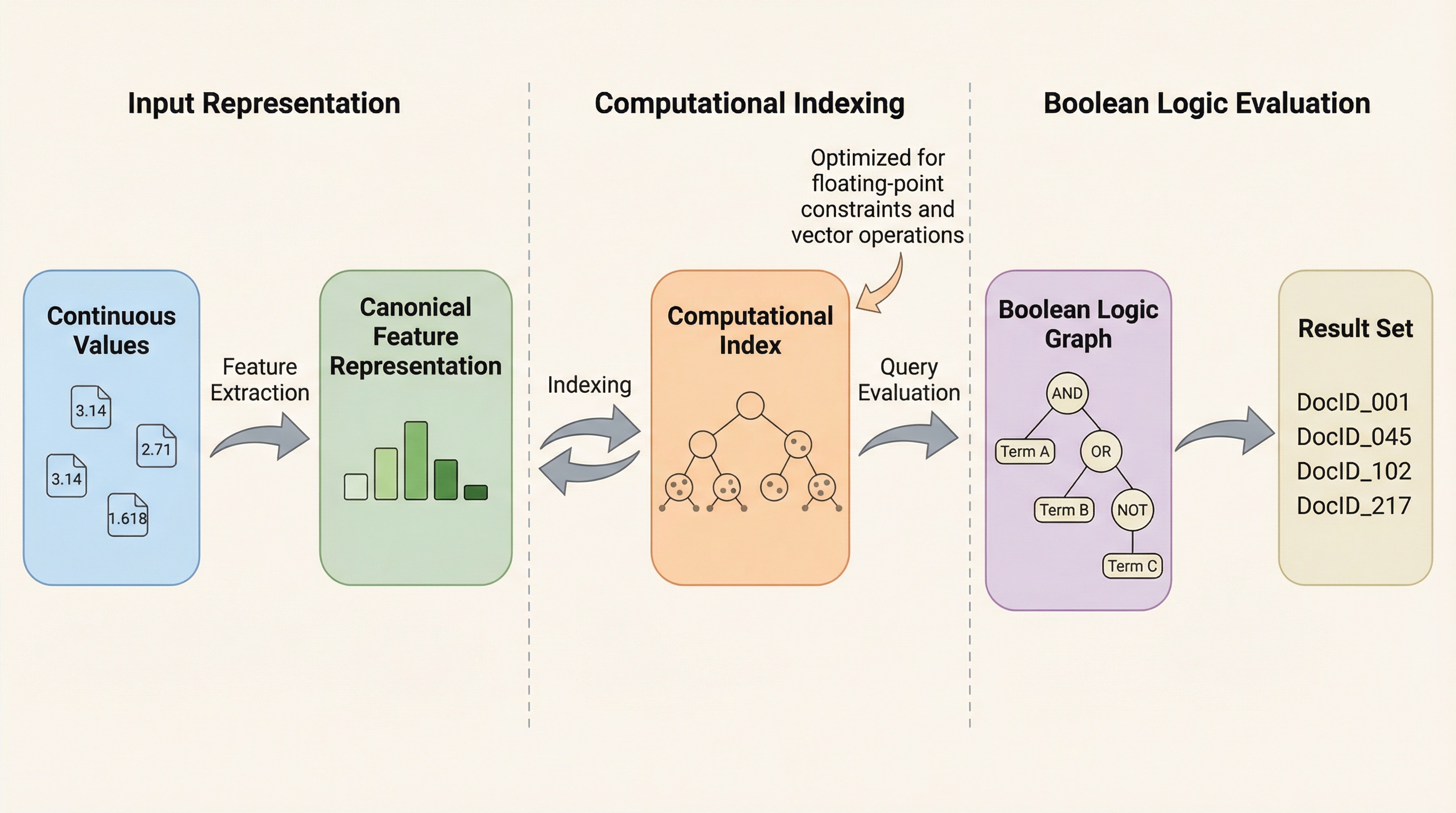
現代の情報検索は、単純なキーワード検索から大規模言語モデル(LLM)や自律型エージェントが要求する複雑な記号論理的推論へと移行していますが、既存の検索エンジンは複雑な論理構造を効率的に処理できないという深刻な課題を抱えています。