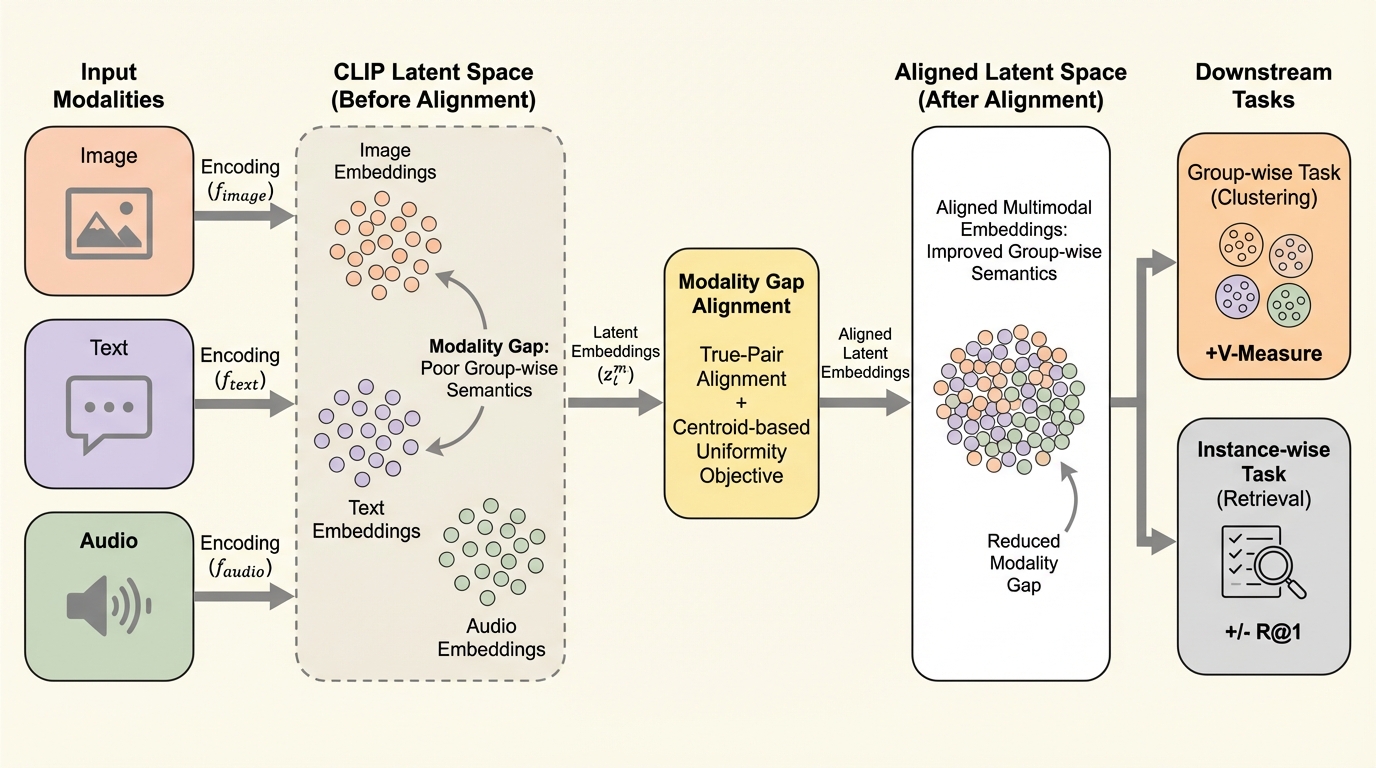
モダリティ・ギャップの解消はグループ単位の意味を整合させる
マルチモーダル学習の標準手法であるCLIPにおいて、異なるデータ形式(画像やテキスト等)が潜在空間内で分離してしまう「モダリティ・ギャップ」が、クラスタリングなどのグループ単位のタスク性能を著しく低下させていることを解明した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
マルチモーダル学習の標準手法であるCLIPにおいて、異なるデータ形式(画像やテキスト等)が潜在空間内で分離してしまう「モダリティ・ギャップ」が、クラスタリングなどのグループ単位のタスク性能を著しく低下させていることを解明した。
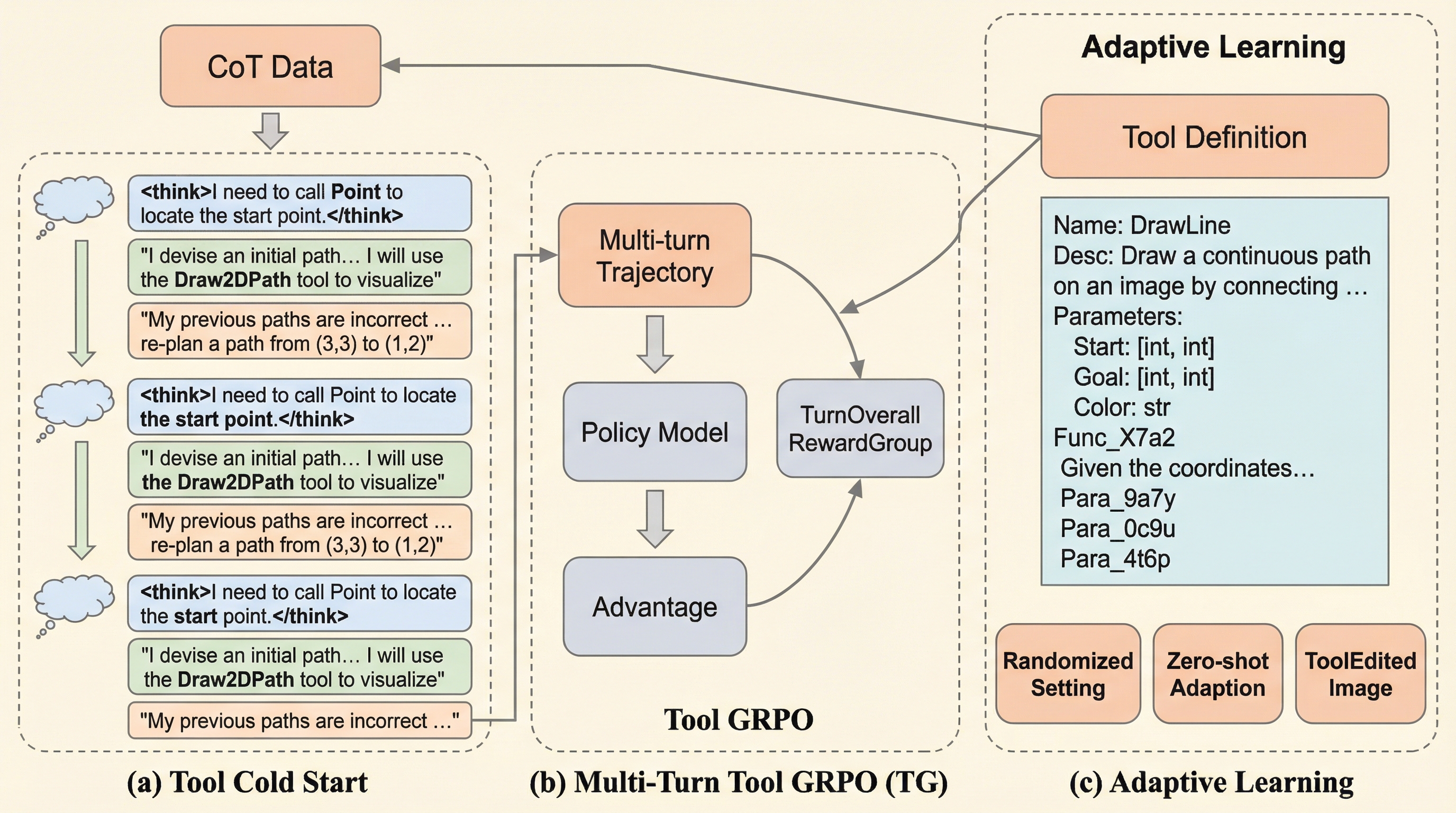
AdaReasonerは、マルチモーダル大規模言語モデル(MLLM)において、ツール利用を特定のタスクの手順としてではなく、文脈に応じて「いつ、何を、どう使うか」を判断する汎用的な推論スキルとして習得させる新しいモデルファミリーである。
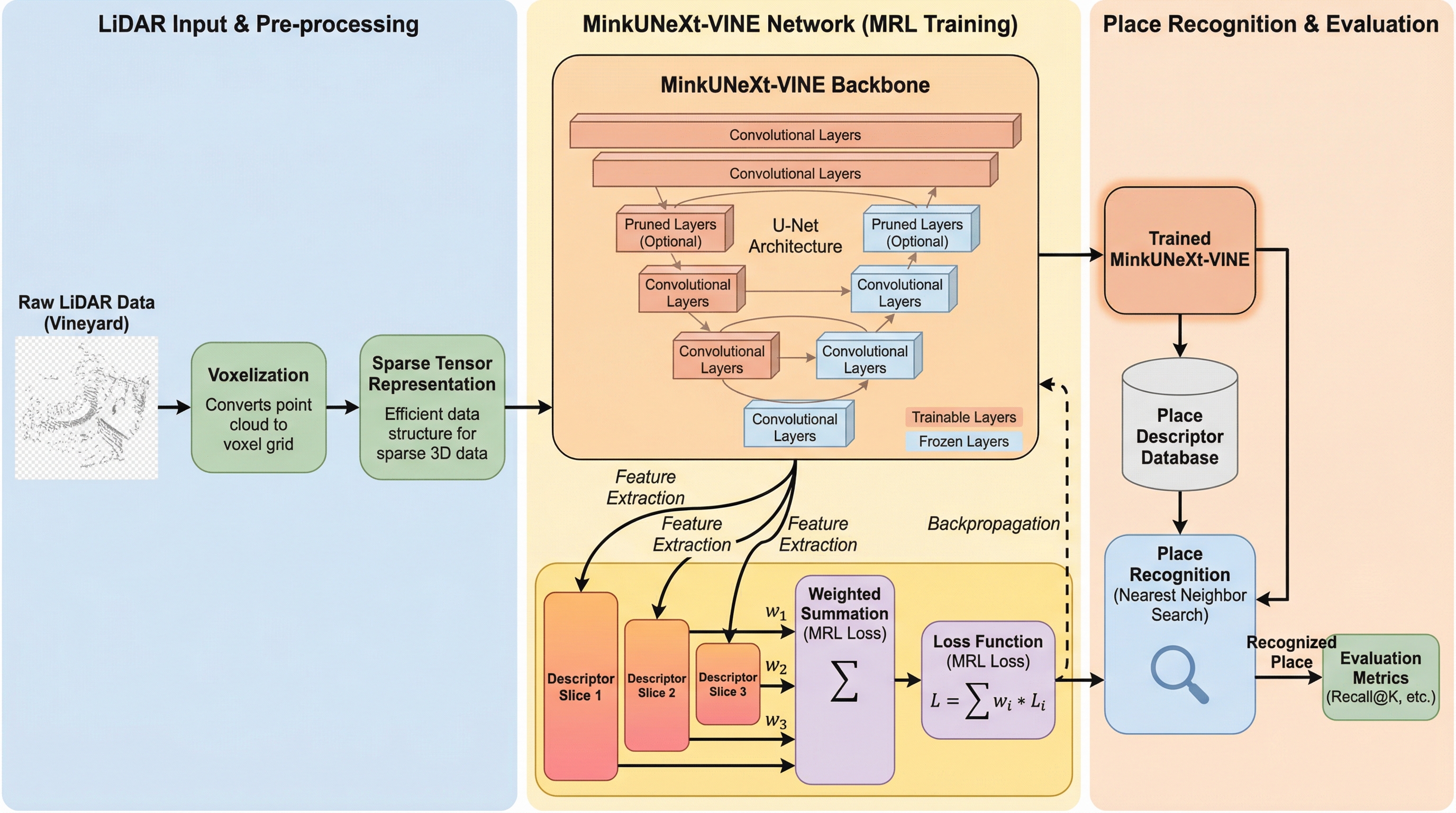
ブドウ園のような非構造的で特徴的な目印が乏しい農業環境において、ロボットが正確に自己位置を特定するための軽量な深層学習手法「MinkUNeXt-VINE」が提案されました。 既存のネットワーク構造を剪定して計算負荷を下げつつ、マトリョーシカ表現学習(MRL)を導入することで、低次元から高次元まで柔軟かつ頑健な記述子を生成し、リアルタイムでの高い処理効率を実現しています。 複数のブドウ園で収集された長期的なデータセットを用いた検証により、季節による外観の変化や低コスト・低解像度なLiDAR入力に対しても、従来の最先端手法を上回る優れた認識精度と汎用性が実証されました。
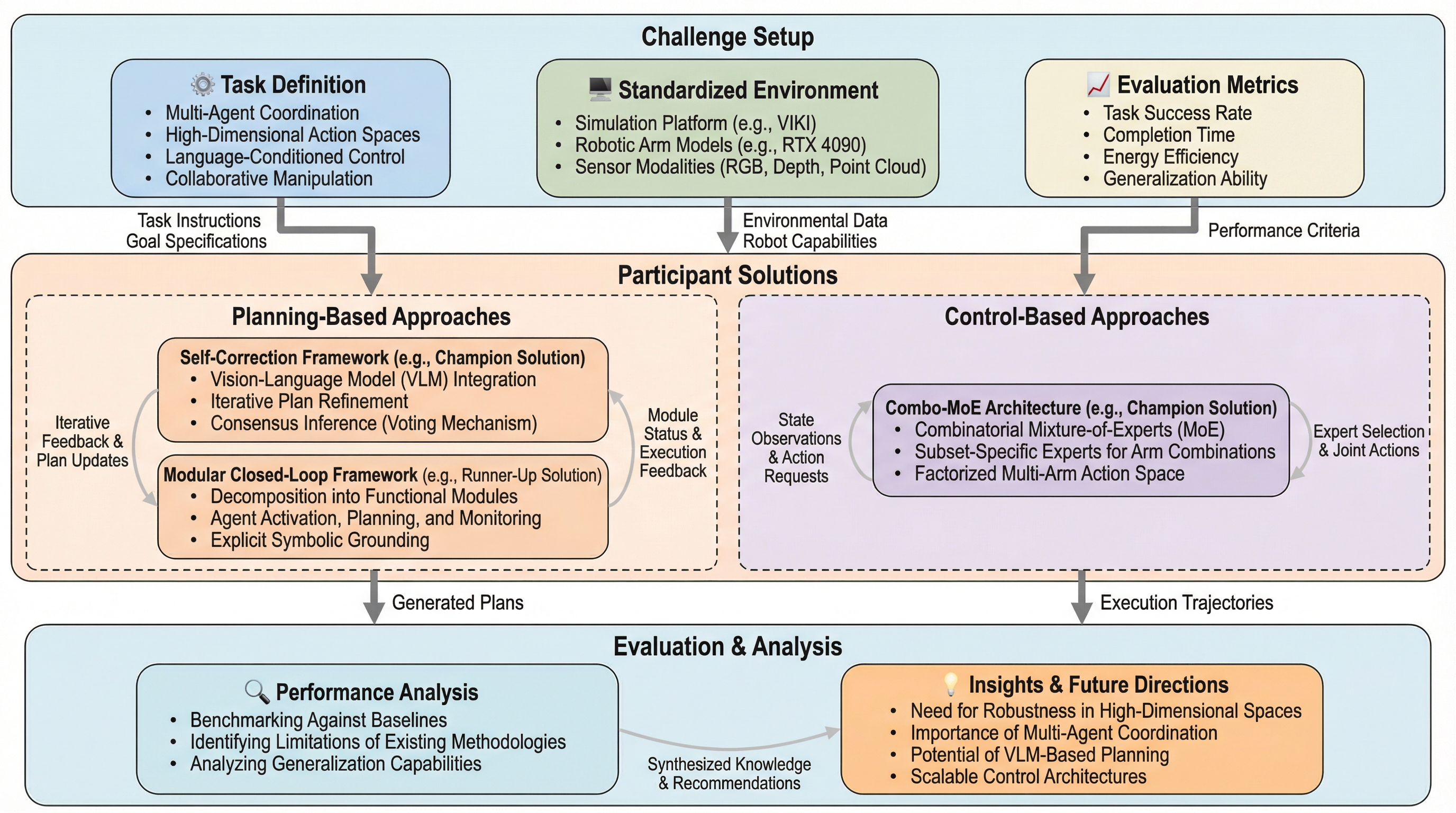
複雑なタスクを解決するため、複数のロボットが協力するマルチエージェント・ロボットシステム(MARS)チャレンジが提案された。この競技会は、視覚言語モデル(VLM)を用いた高レベルな「プランニング」と、物理シミュレーション環境での低レベルな「制御」の2つのトラックで構成されている。
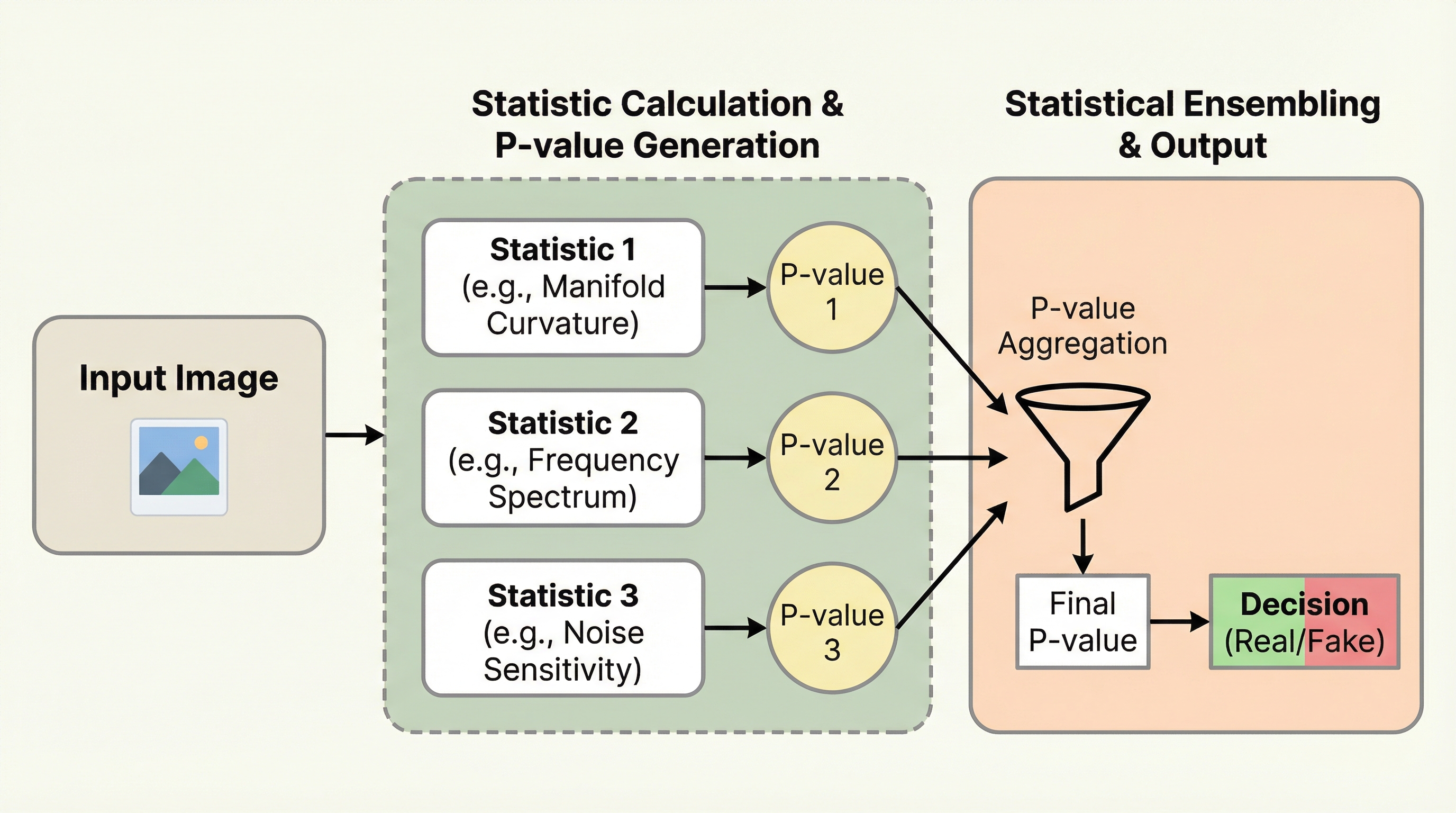
生成AIによる偽画像検出において、未知の生成モデルへの適応性と判定結果の解釈性を両立させるため、実画像のみを利用する統計的枠組み「RealStats」が提案されました。 この手法は、複数の既存検出器から得られる統計量を実画像の分布に基づいた「p値」へと変換し、それらを厳密な統計的手法で統合することで、対象画像が実画像の分布からどれだけ逸脱しているかを確率的に評価します。 学習に偽画像を一切必要としないため、進化し続ける新しい生成モデルに対しても頑健であり、出力されるスコアは「その画像が実画像である確率」として統計的に明確な意味を持つため、信頼性の高い判定を実現しています。
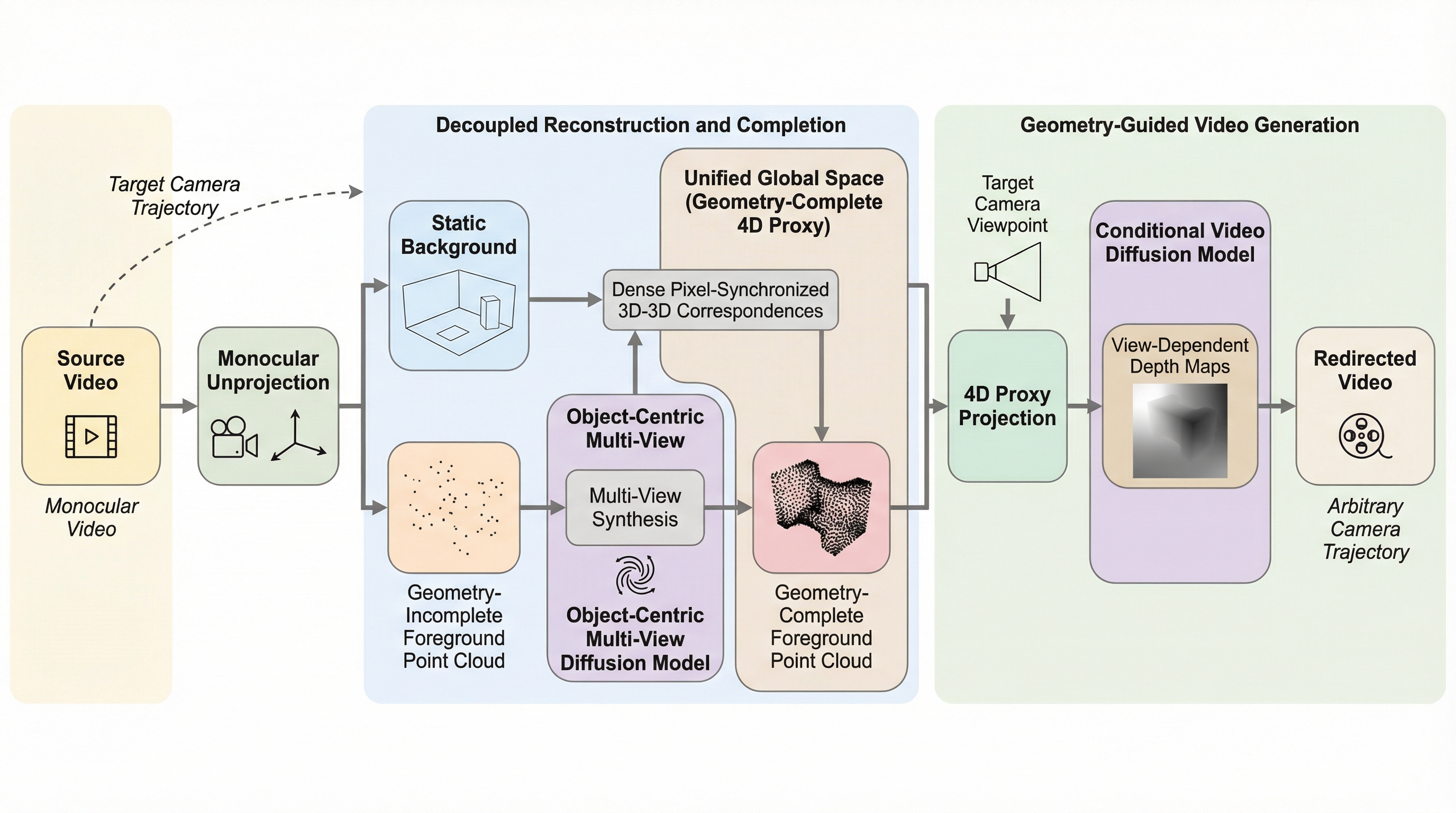
単眼動画から任意のカメラ軌道に沿った映像を生成するカメラリダイレクションにおいて、従来の「暗黙的制御」や「明示的ワーピング」では困難だった広角な視点変更と幾何学的な整合性の両立を、追加学習なしで実現する新フレームワーク「FreeOrbit4D」を提案しました。
PixSearchは、画像の特定領域に基づいた検索と推論を統合した、エンドツーエンドのセグメンテーション機能を持つ大規模マルチモーダルモデルであり、従来のシステムが抱えていた検索のタイミングや方法を自律的に判断できないという課題を解決する。
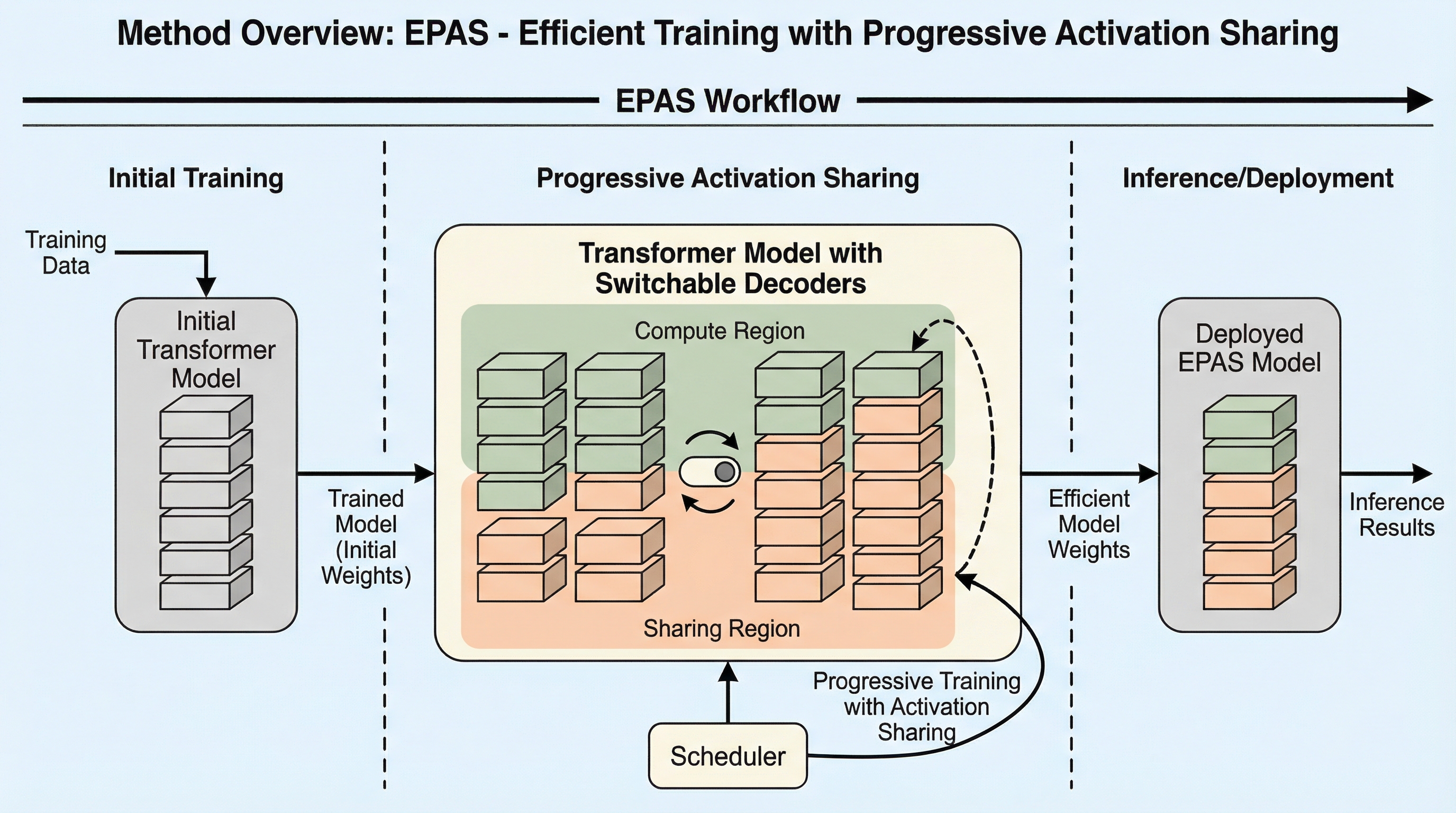
EPAS(Efficient training with Progressive Activation Sharing)は、Transformerモデルの深層における計算の冗長性を利用し、学習中に活性化(QKまたはKV)の共有領域を段階的に拡大させることで、学習と推論の両方の効率を飛躍的に向上させる新しい学習フレームワークである。 スイッチ切り替え可能なデコーダー層を導入し、学習の進行に合わせて深い層から浅い層へと共有範囲を広げる決定論的なスケジューリングを行うことで、モデルの精度を維持しながら学習スループットを最大11.1%、推論スループットを最大29.2%向上させることに成功した。 LLaMAモデルを用いた検証では、複雑な知識蒸留を必要とせずに既存の事前学習済みモデルを効率的な共有モデルへと変換可能であり、計算リソースや遅延の制約に応じて推論時の共有構成を柔軟に変更できるMany-in-oneモデルとしての実用的な特性を実証した。
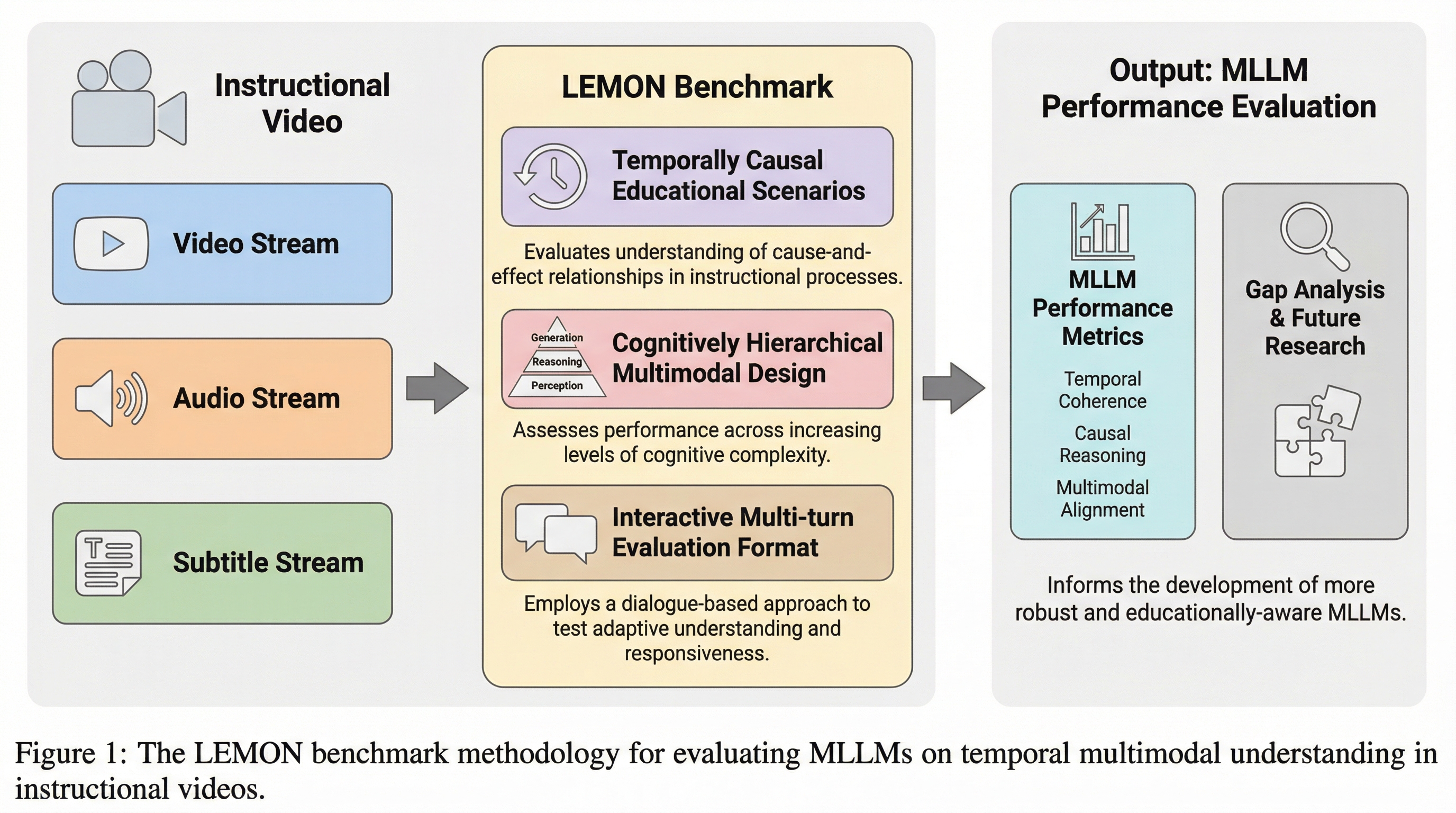
教育ビデオにおける時間的なマルチモーダル理解を精密に評価するため、数学や人工知能などのSTEM分野の講義を対象とした新しいベンチマーク「LEMON」が提案されました。このデータセットは、5つの学問分野と29のコースから収集された2,277のビデオセグメントと、4,181の高品質な問題ペアで構成されており、視覚、音声、テキストの3つのモダリティが密接に連携した高度な推論を要求します。実験の結果、GPT-5やQwen3-Omniといった最新のマルチモーダル大規模言語モデルであっても、時間的な推論や教育的な意図の予測において大きな課題があることが明らかになり、実世界での複雑なコンテンツ理解能力には依然として大きな乖離があることが示されました。
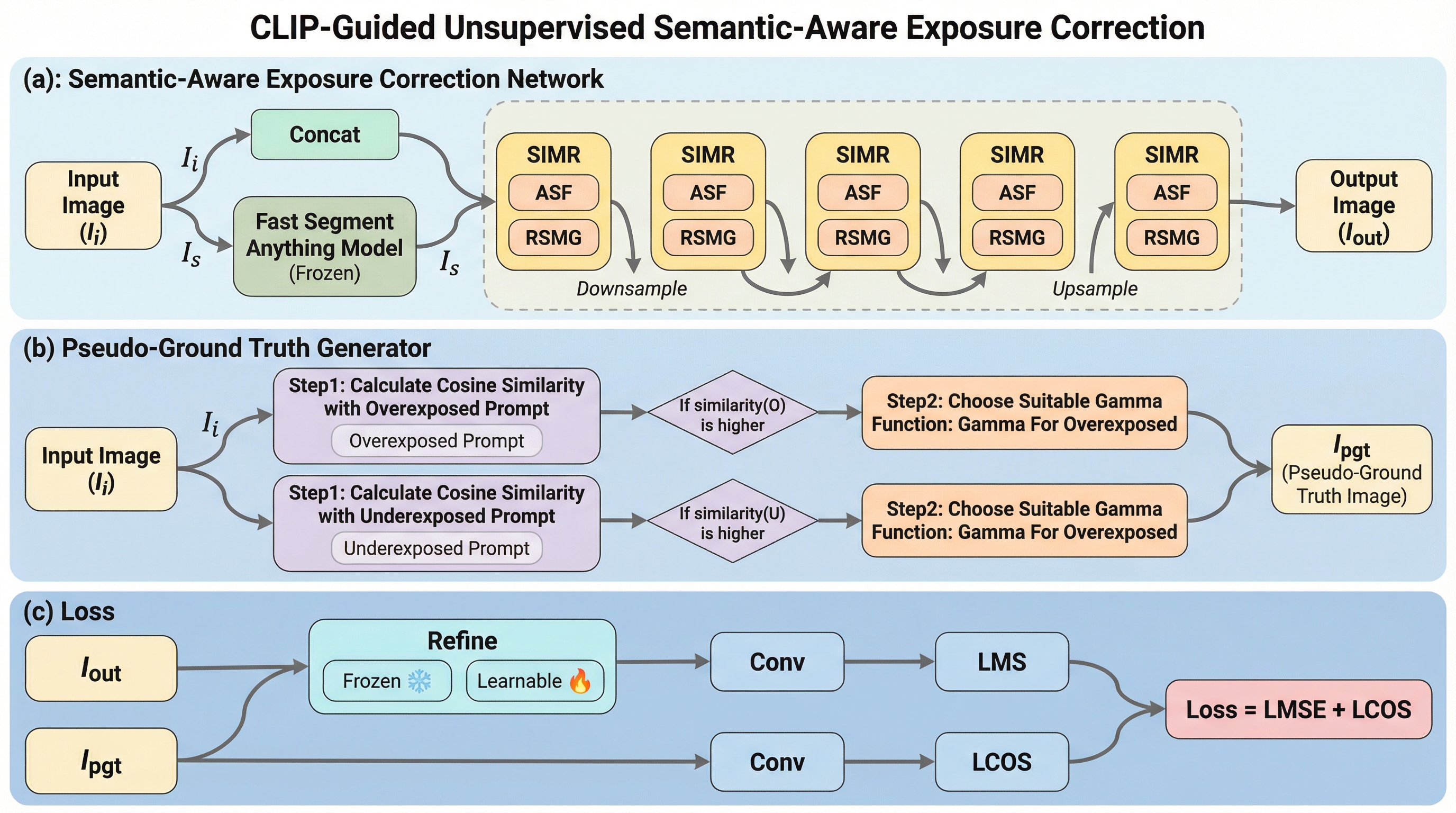
不適切な露出による詳細の消失や色被りを解決するため、Fast Segment Anything Modelから得られる物体レベルの意味情報を活用し、領域ごとの精密な補正を行う新しい教師なし学習フレームワークが提案されました。