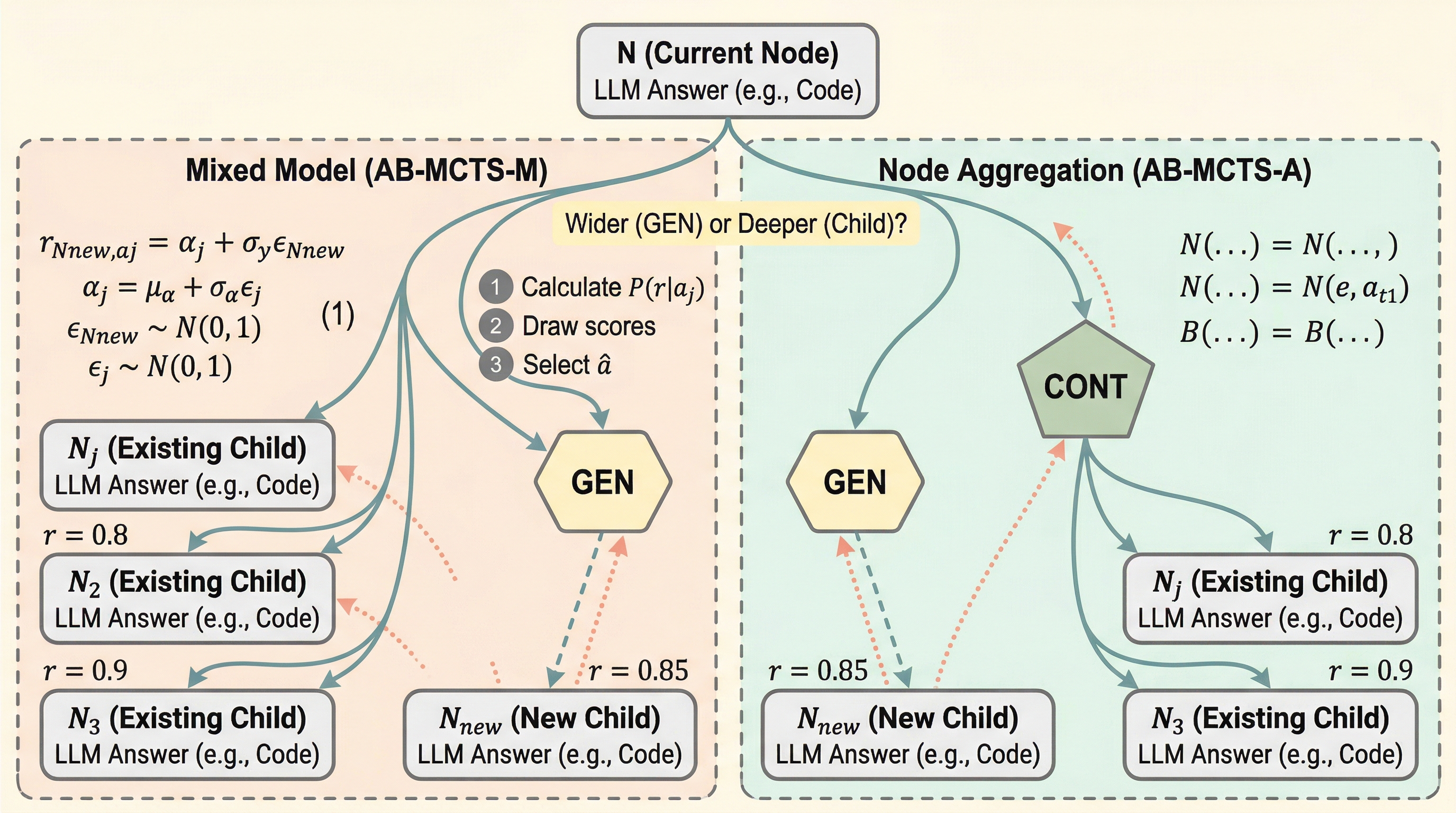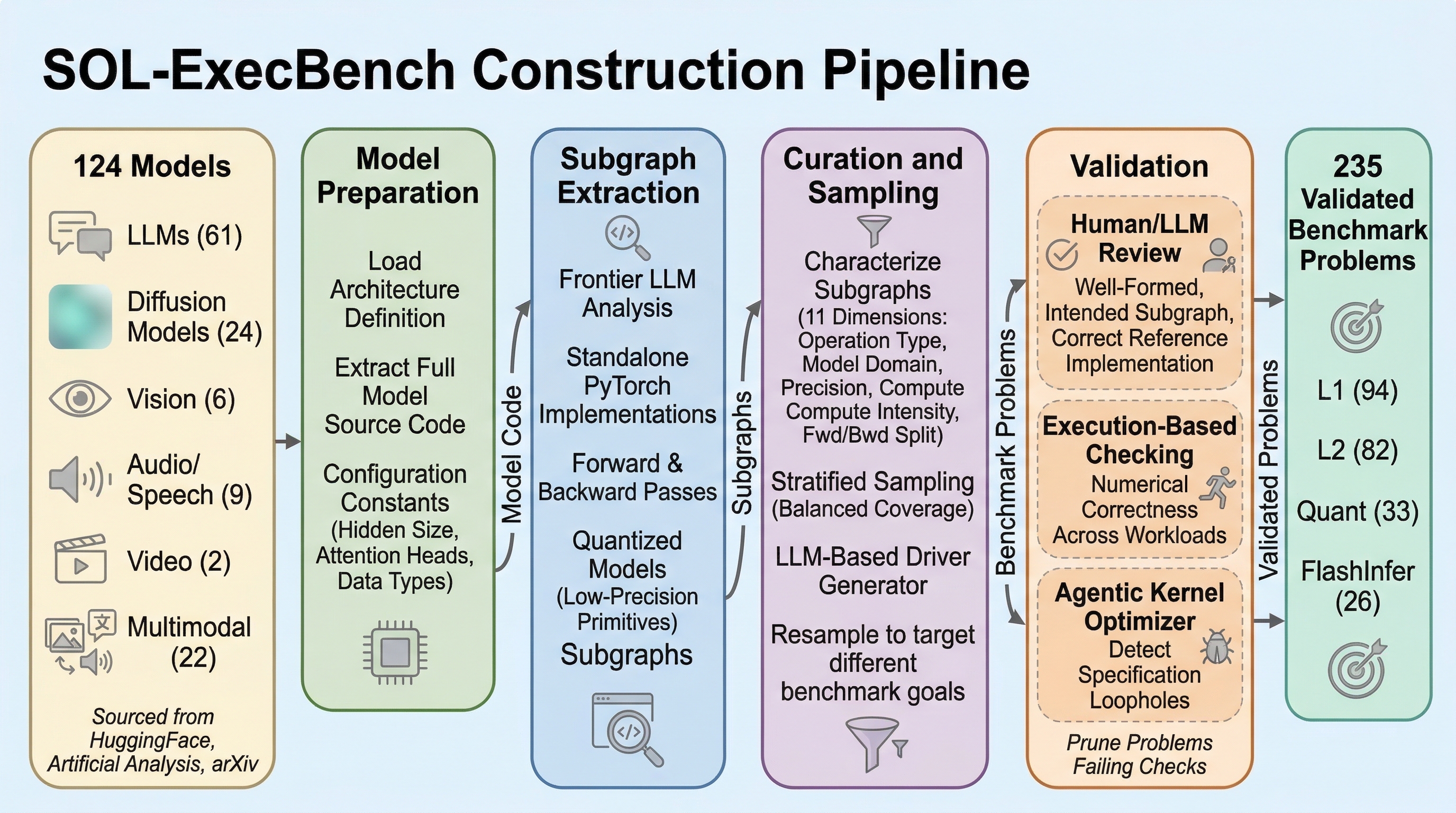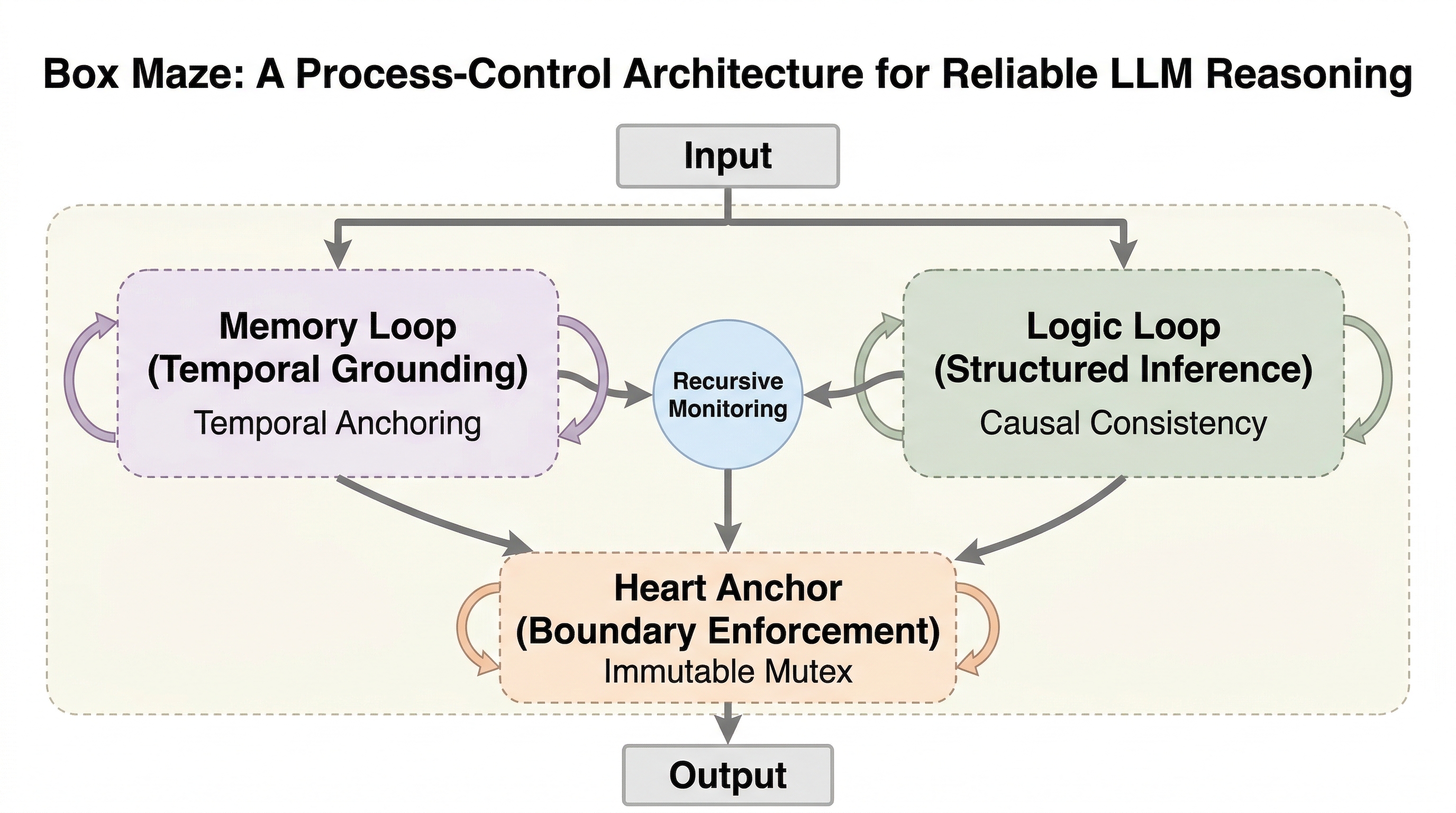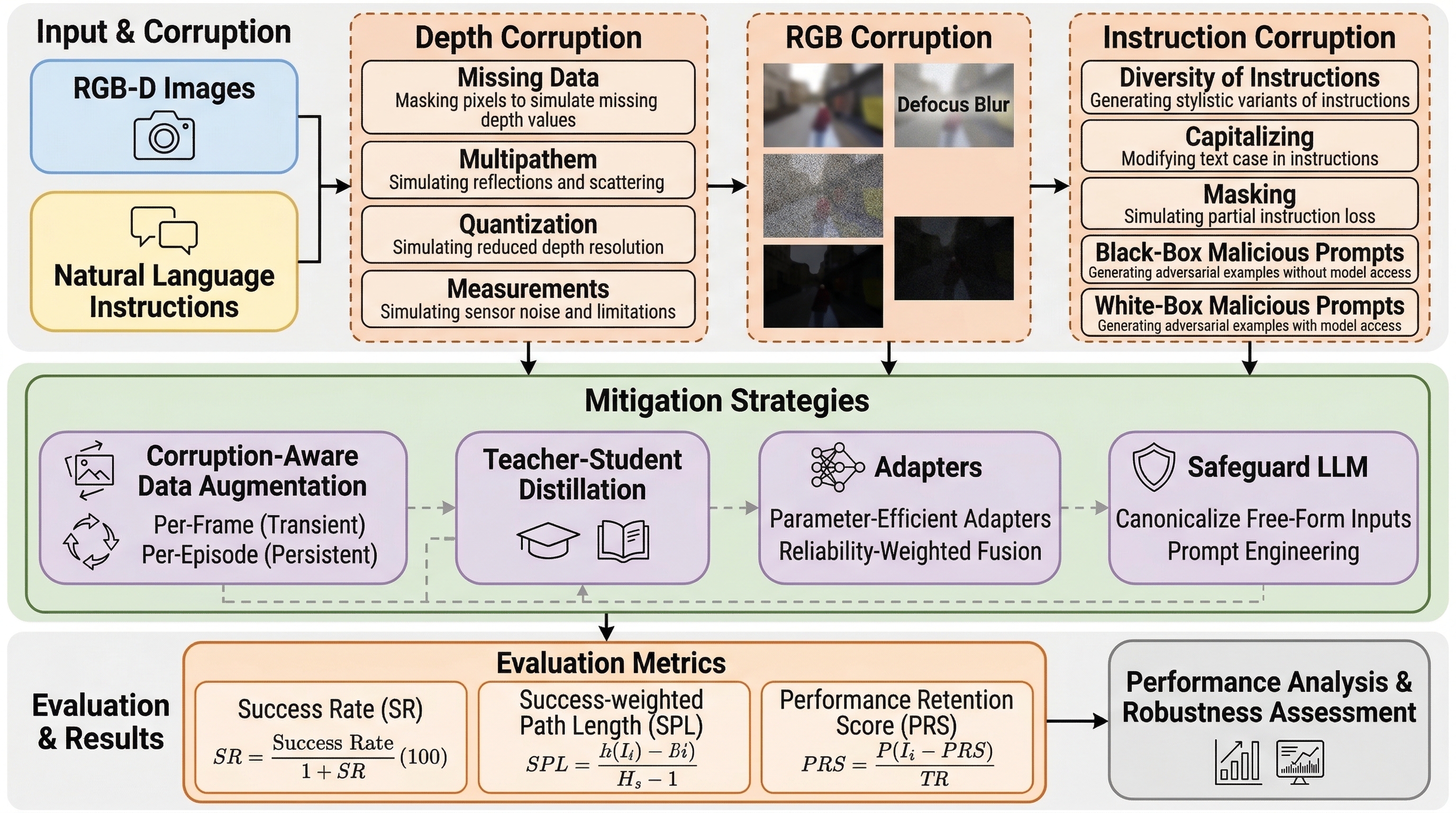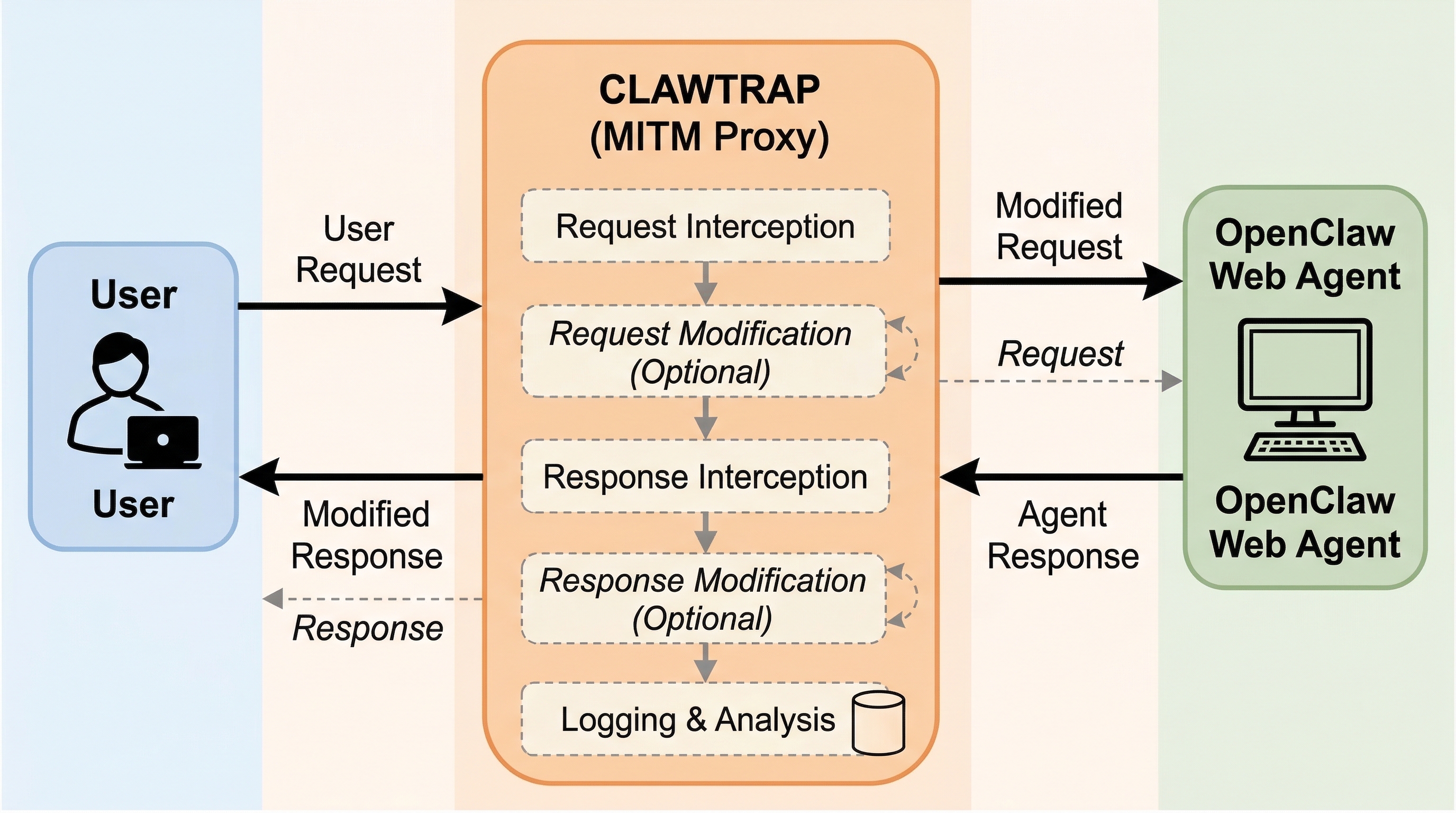
並列サンプリングはなぜ逐次サンプリングより強いのか:推論時計算の差を分解した研究
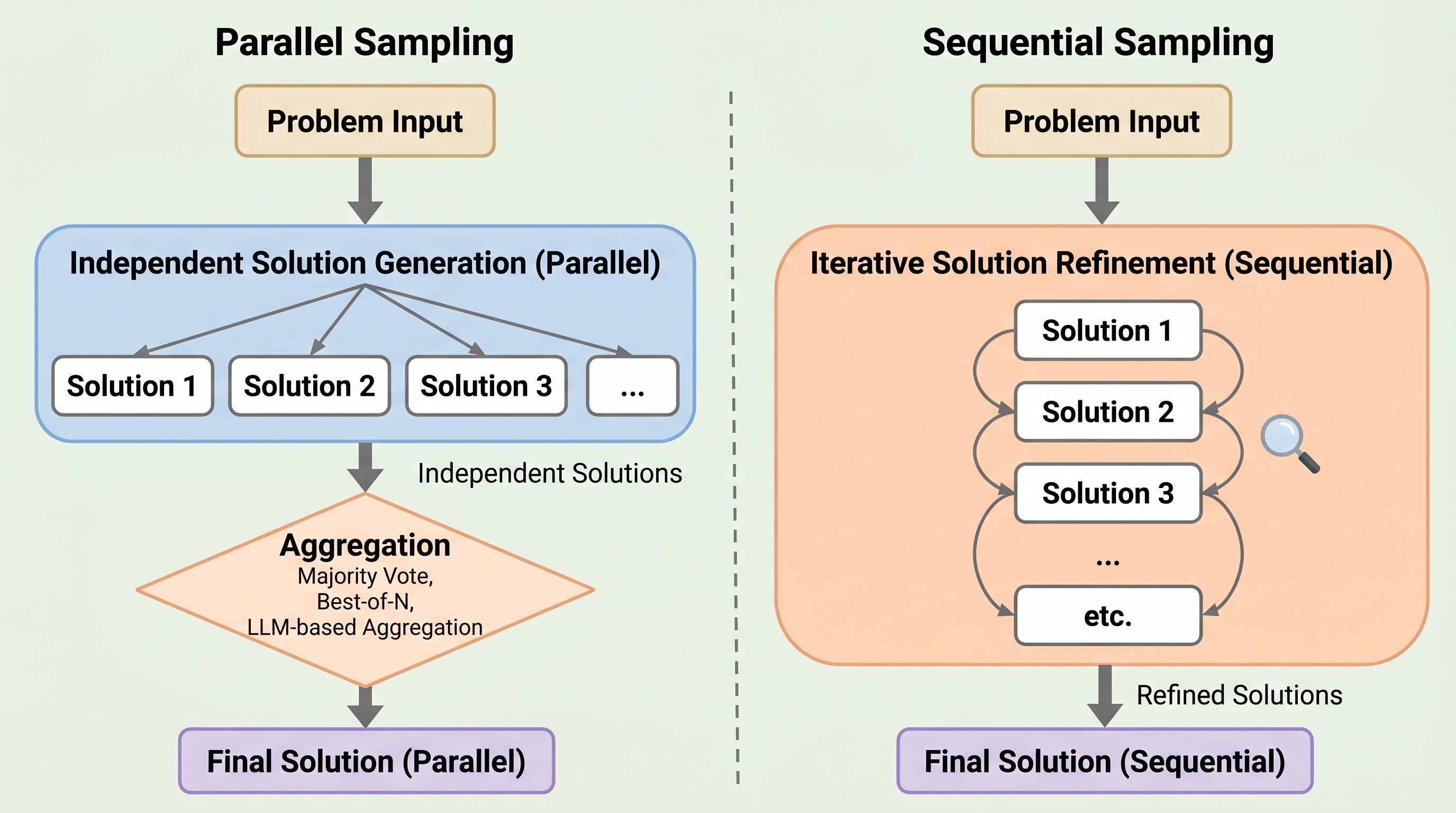
- 大規模推論モデルの推論時計算の拡張では、答え候補を独立にたくさん出して最後に集約する並列サンプリングの方が、前の答えを見ながら順に改善していく逐次サンプリングより強いことが知られていましたが、その理由は曖昧でした。 - この研究は AIME2025 と LiveCodeBench v5、さらに Qwen3・DeepSeek-R1 distilled・Gemini 2.5 をまたいで比較し、差の主因は集約や長い文脈そのものではなく、逐次方式で解探索が狭まりやすいことだと示しています。 - 特に逐次サンプリングでは前の解を強く参照する誘導ヘッドが現れ、似た解を繰り返しやすくなると分析しています。言い換えると、逐次改善が弱いのではなく、「前の答えに引きずられて別解を試せなくなる」ことが効いている、という結論です。