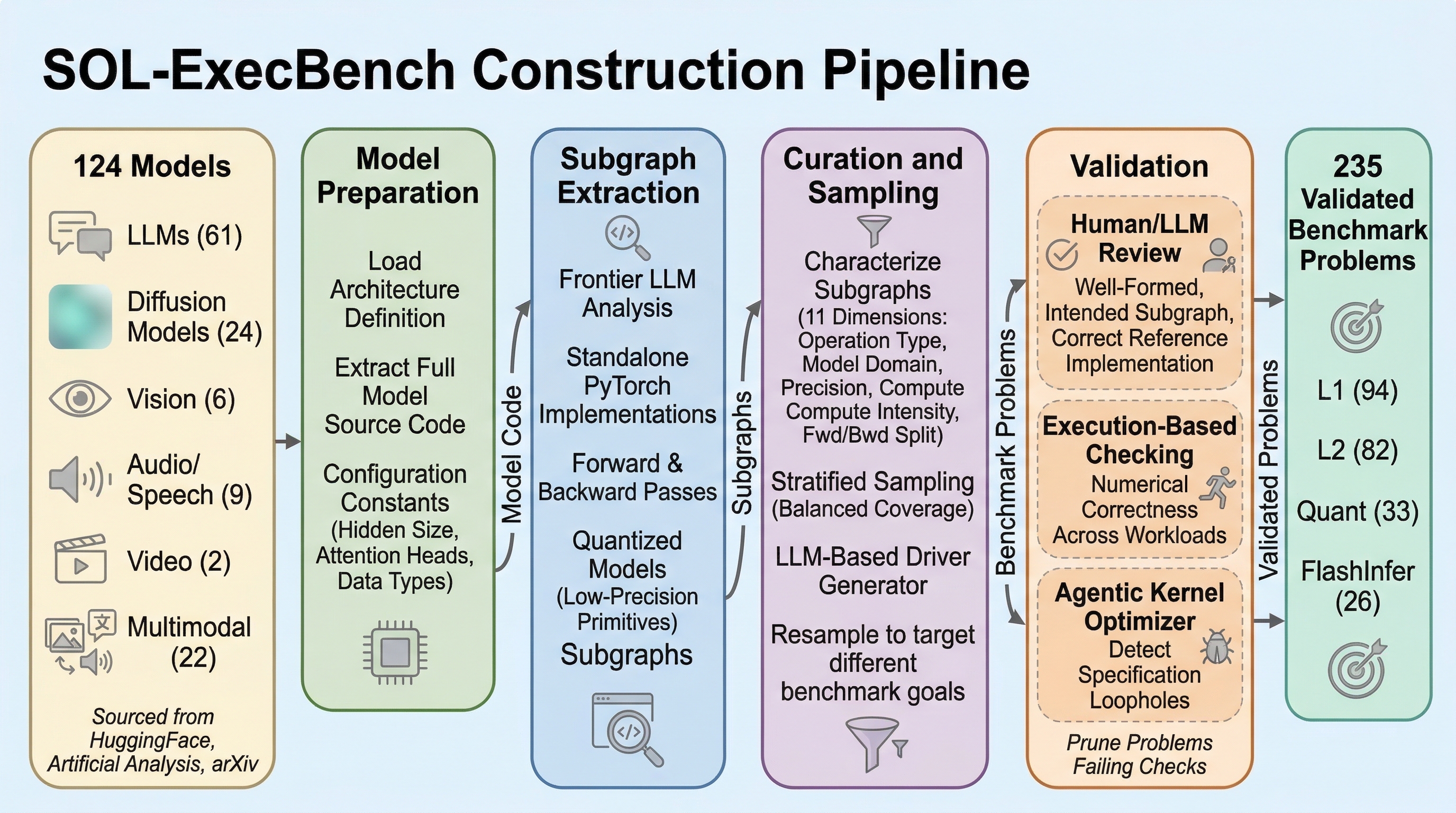
SOL-ExecBench:GPUカーネル最適化を「ハード限界との差」で測る新基準
SOL-ExecBench は、AI エージェントが GPU カーネルを最適化するとき、単なるソフトウェア実装比の高速化ではなく、ハードウェアの理論上限までどこまで近づけたかで測るベンチマークです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
SOL-ExecBench は、AI エージェントが GPU カーネルを最適化するとき、単なるソフトウェア実装比の高速化ではなく、ハードウェアの理論上限までどこまで近づけたかで測るベンチマークです。
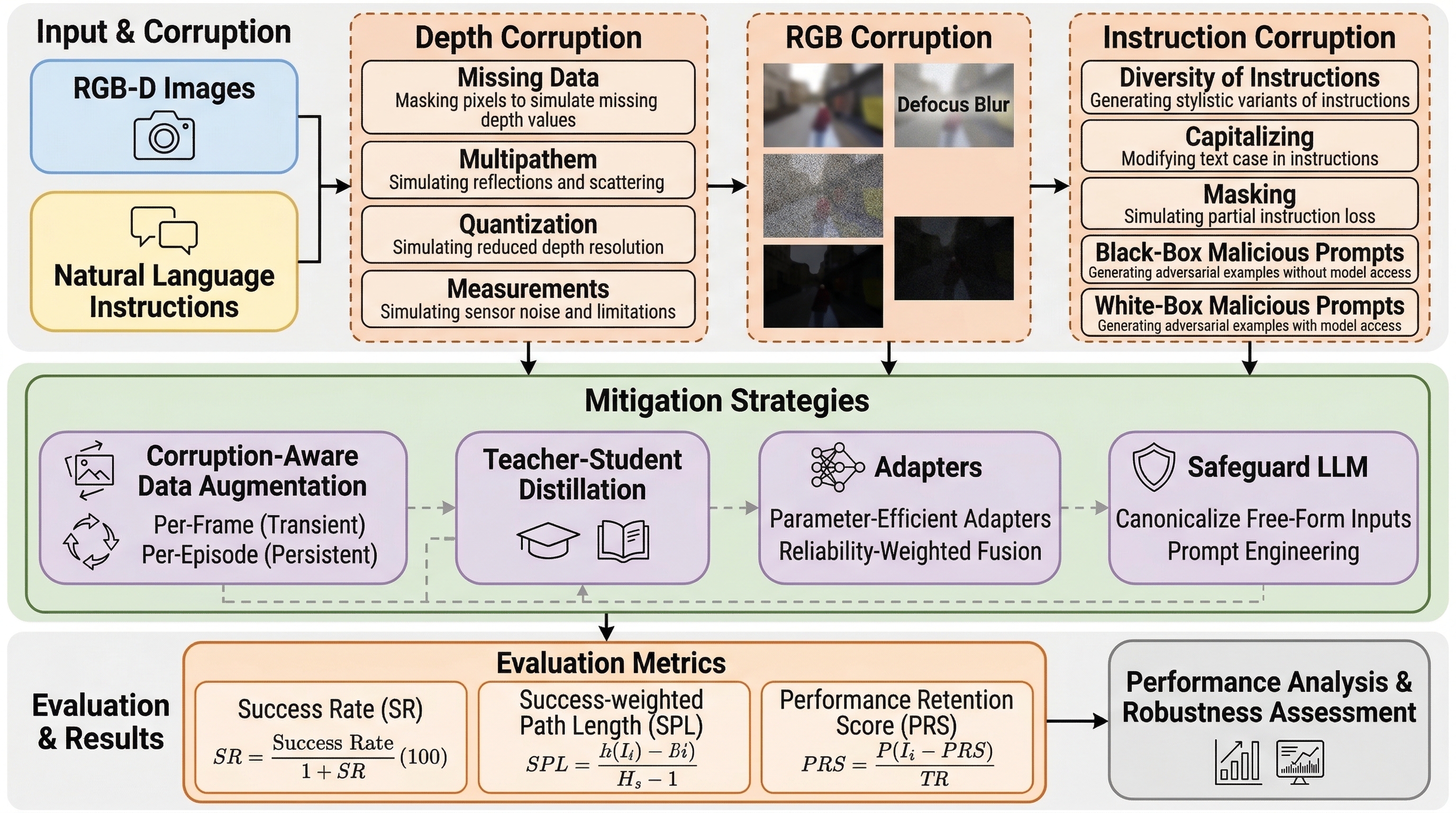
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
能動学習では、どのサンプルを次にラベル付けするかで性能が大きく変わりますが、既存戦略は条件ごとの当たり外れが大きいままです。BoSS は複数戦略から候補バッチを作り、その中で最も性能向上をもたらすものを選ぶことで、大規模条件でも使える強いオラクル基準を与えます。
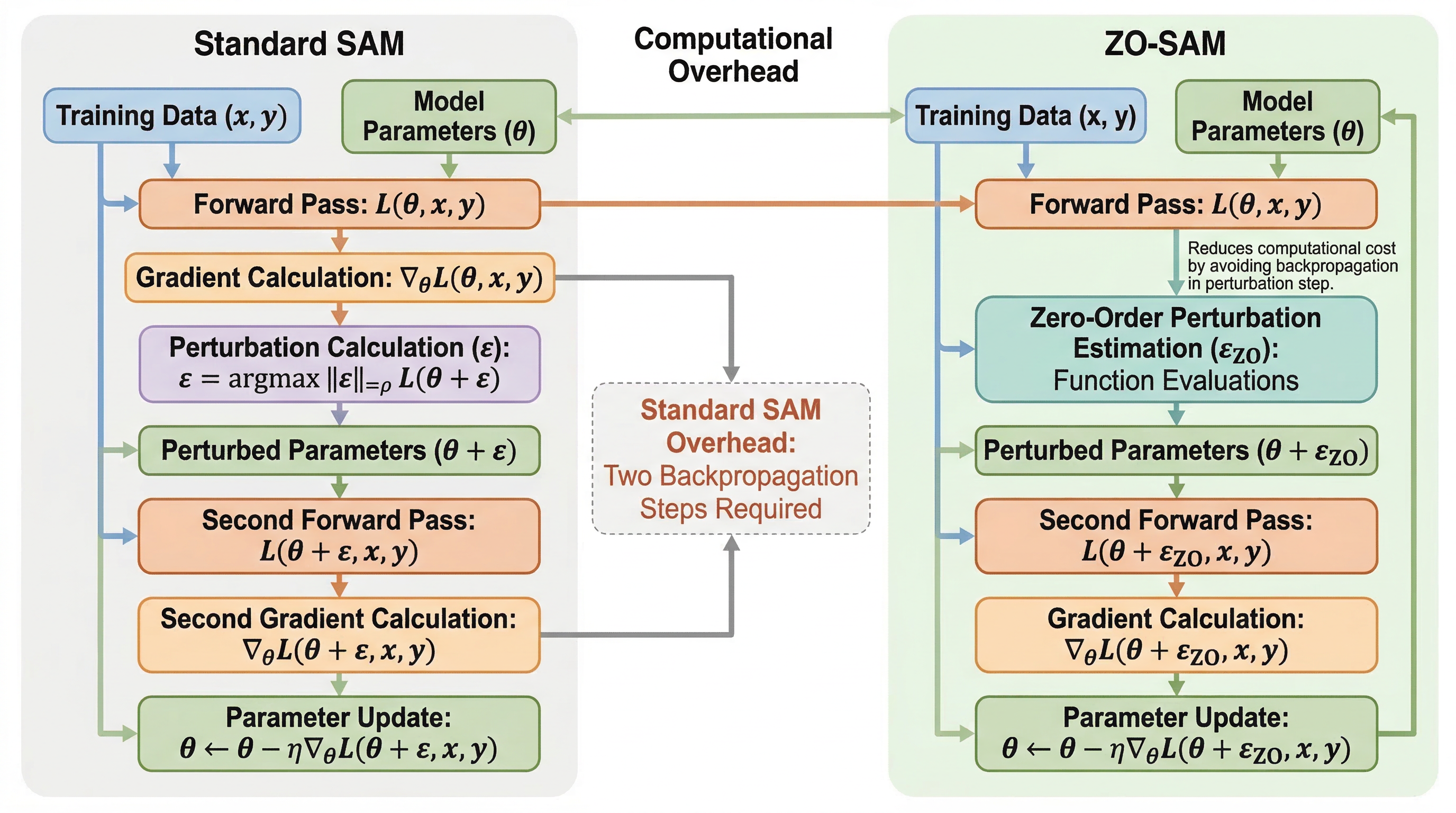
高い疎性では勾配が荒れやすく、スパース学習は収束も汎化も不安定になりがちです。ZO-SAM は SAM の摂動生成だけをゼロ次最適化に置き換え、平坦な解を探す利点を残しながら計算負荷を抑えることで、精度・収束・頑健性の三つを同時に改善しようとします。
メンバーシップ推論攻撃の脆弱性はモデル全体ではなく、ごく少数の重みに集中しており、その多くは精度にも重要でした。論文は、危険な重みを削除する代わりに初期値へ巻き戻して固定し、残りだけを微調整する CWRF を提案し、LiRA や RMIA に対する耐性と精度の両立を示します。
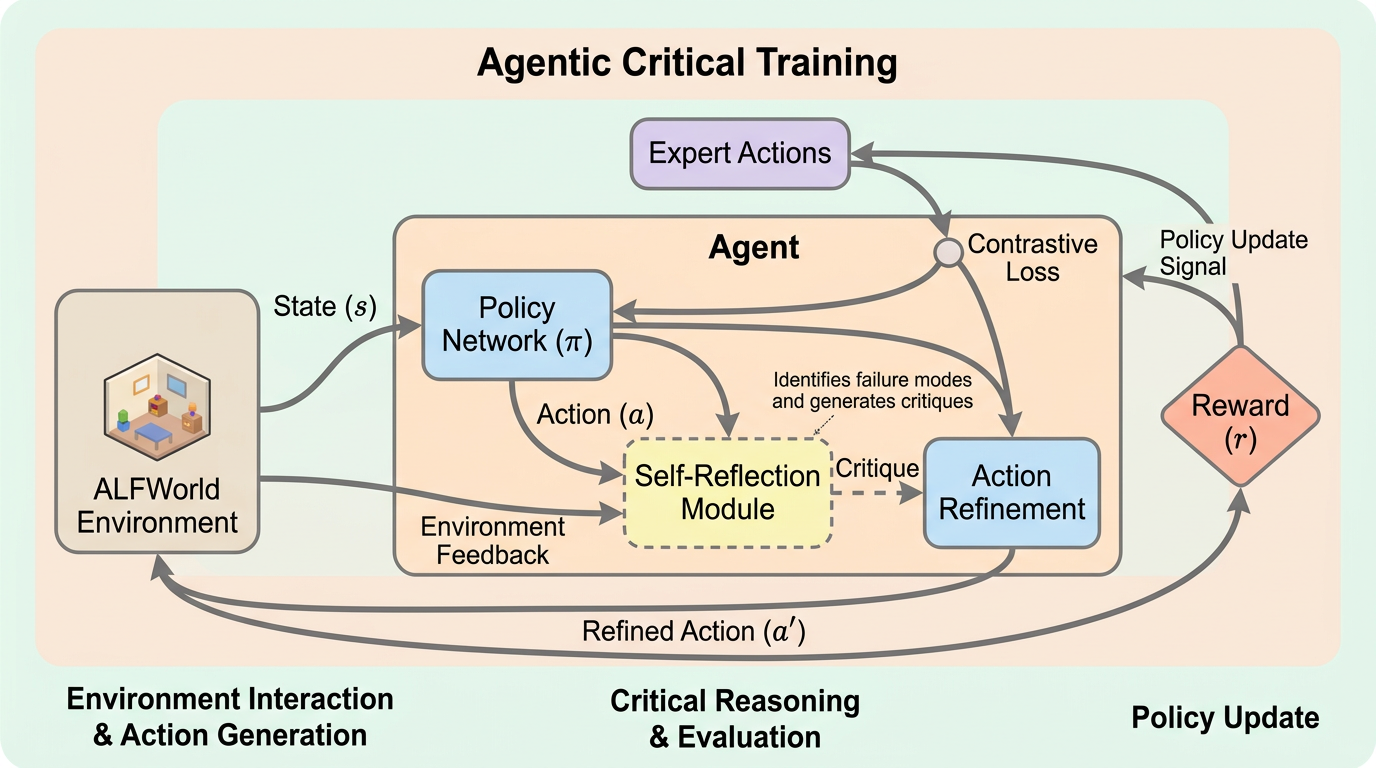
Agentic Critical Training(ACT)は、LLMエージェントに反省文をまねさせるのではなく、複数の行動候補のうちどちらが良いかを強化学習で判定させることで、行動の良し悪しを自律的に考える力を内在化させる枠組みです。 ALFWorld、WebShop、ScienceWorld の3ベンチで、模倣学習より平均 5.07 ポイント、通常の強化学習より平均 4.62 ポイント、既存の自己反省蒸留法より平均 2.42 ポイント改善しました。 しかも改善は agent benchmark の内側だけでなく OOD 設定や MATH-500 などの一般推論にも波及しており、エージェント環境での行動品質判定が、より広い reasoning 能力の訓練になり得ることを示しています。
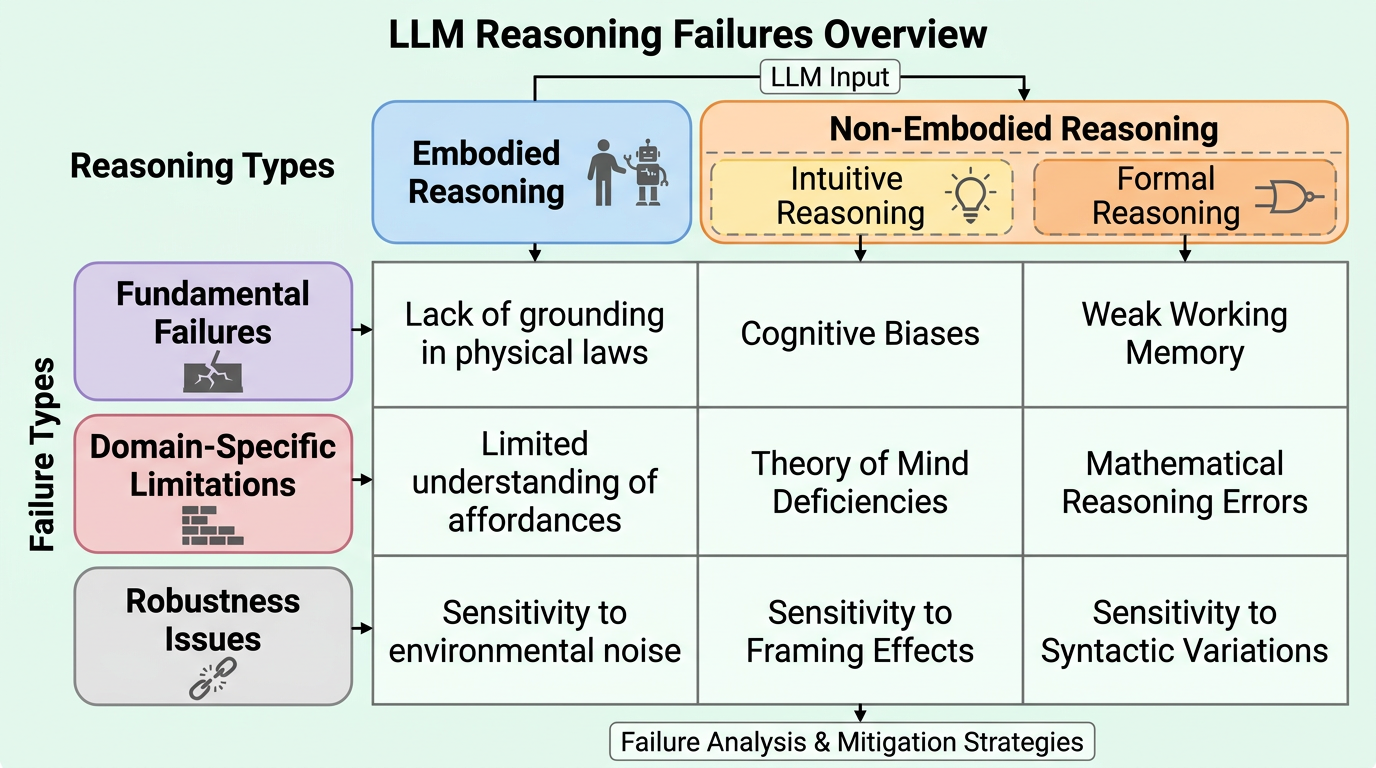
この論文は、LLM の推論失敗を「身体性を伴う推論 / 非身体的推論」と「根本的失敗 / 領域固有の限界 / 頑健性の問題」の二軸で整理する包括サーベイです。
SOTAlign は、少数の画像・テキスト対と大量の非ペアデータを使って、視覚と言語の表現空間をそろえる半教師あり手法です。線形教師で作った粗い共通幾何を KLOT により非ペア側へ移し、検索やゼロショット分類で既存手法を広く上回ります。
SteuerEx は、実際のドイツ大学税法試験から構築された公開ベンチマークです。これに特化した 28B の SteuerLLM は、72B 級の汎用 instruction-tuned モデルや GPT-4o-mini を上回り、税法ではサイズより専門特化が効くことを示しました。
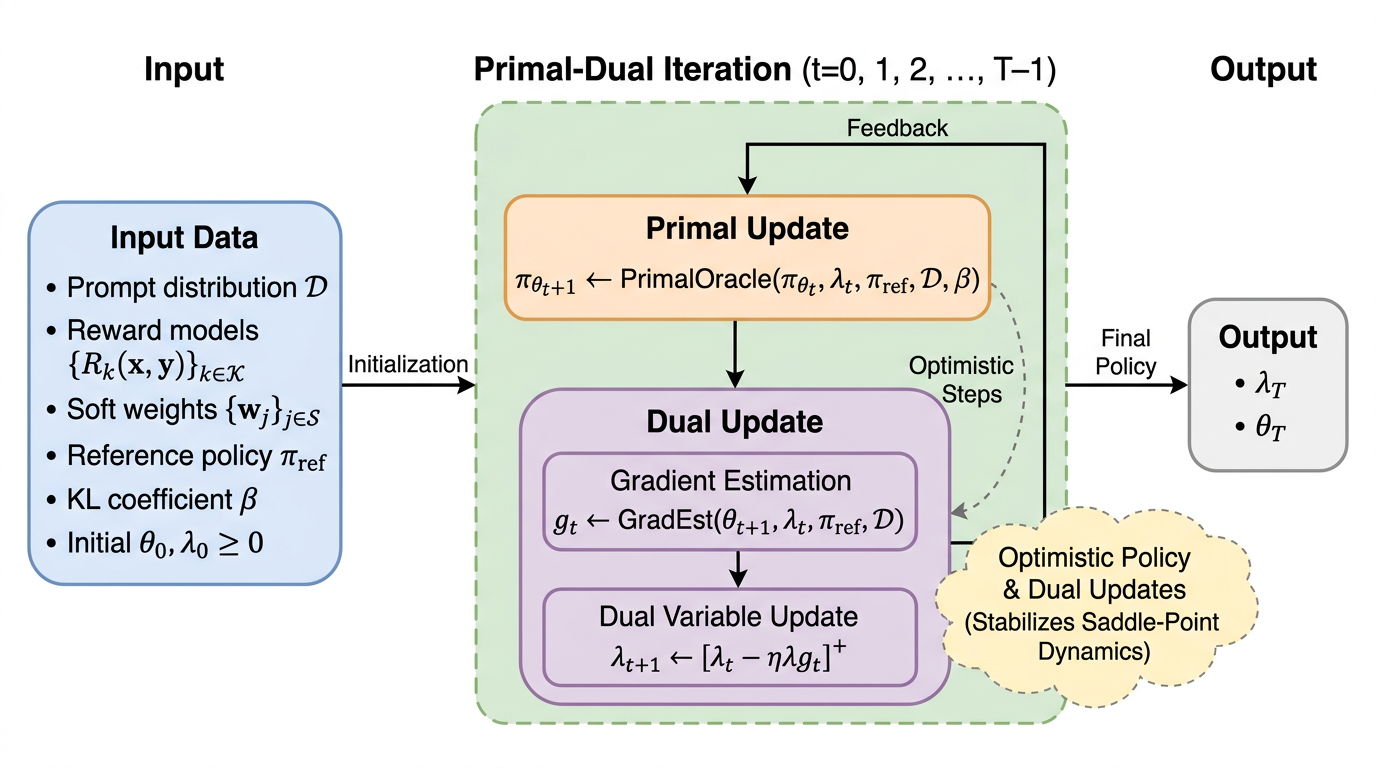
期待報酬の制約を伴う多目的セーフRLHFは方策と非負の双対変数の鞍点問題として書けますが、標準的な同時プライマル・デュアル更新は最終反復が振動して不安定になりやすく、学習の最後の方策をそのまま配備する運用と噛み合いにくいです。