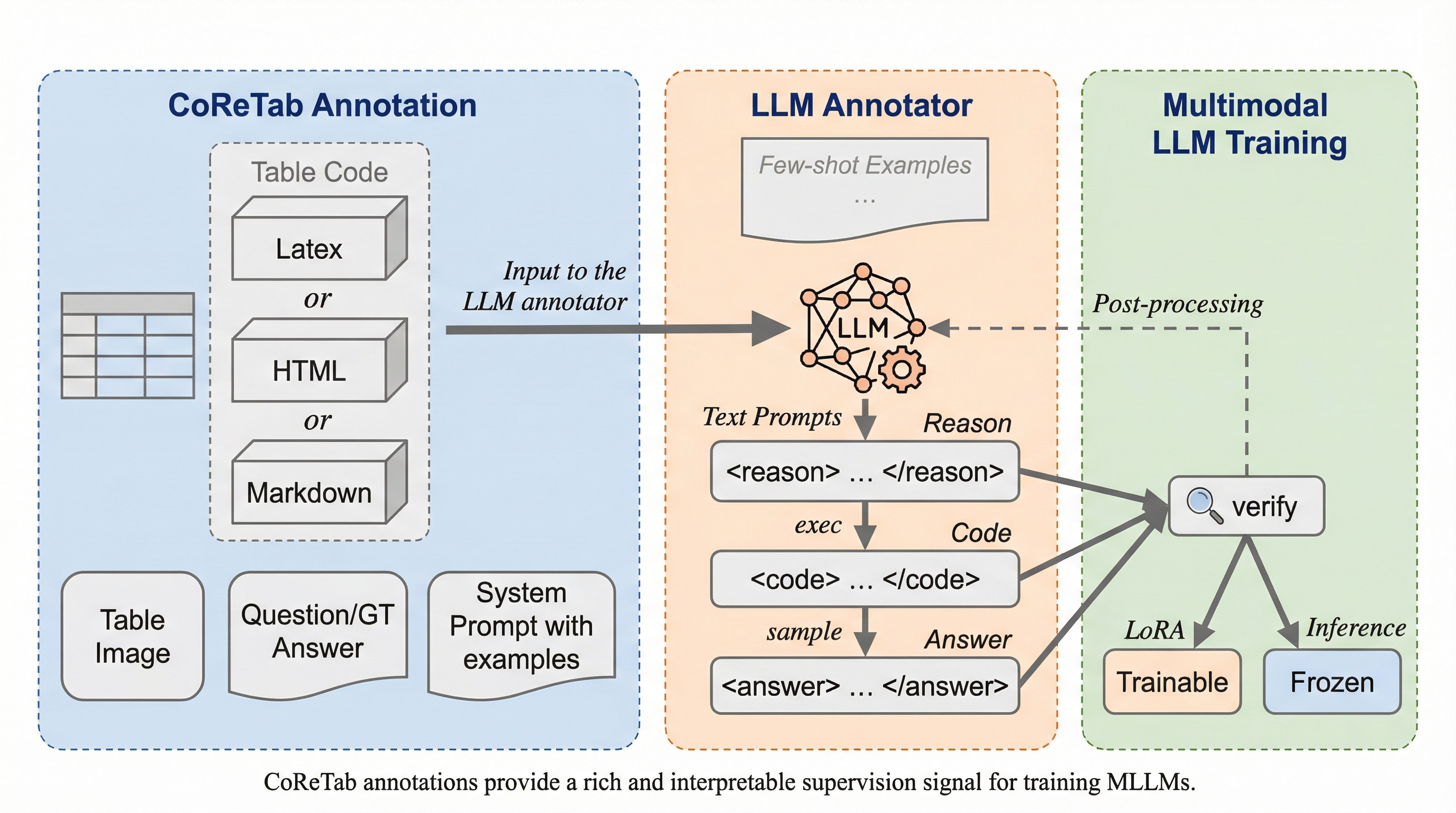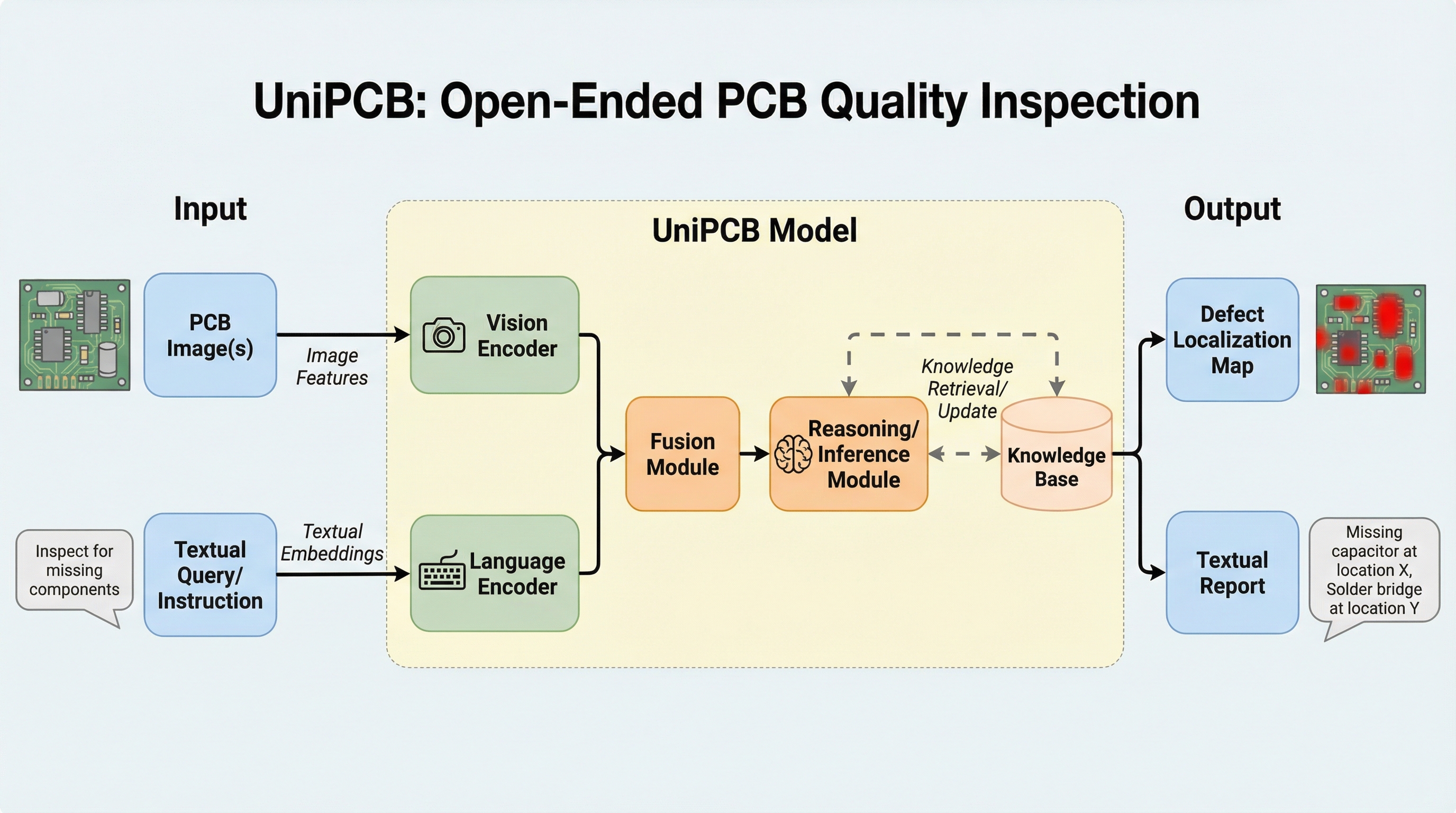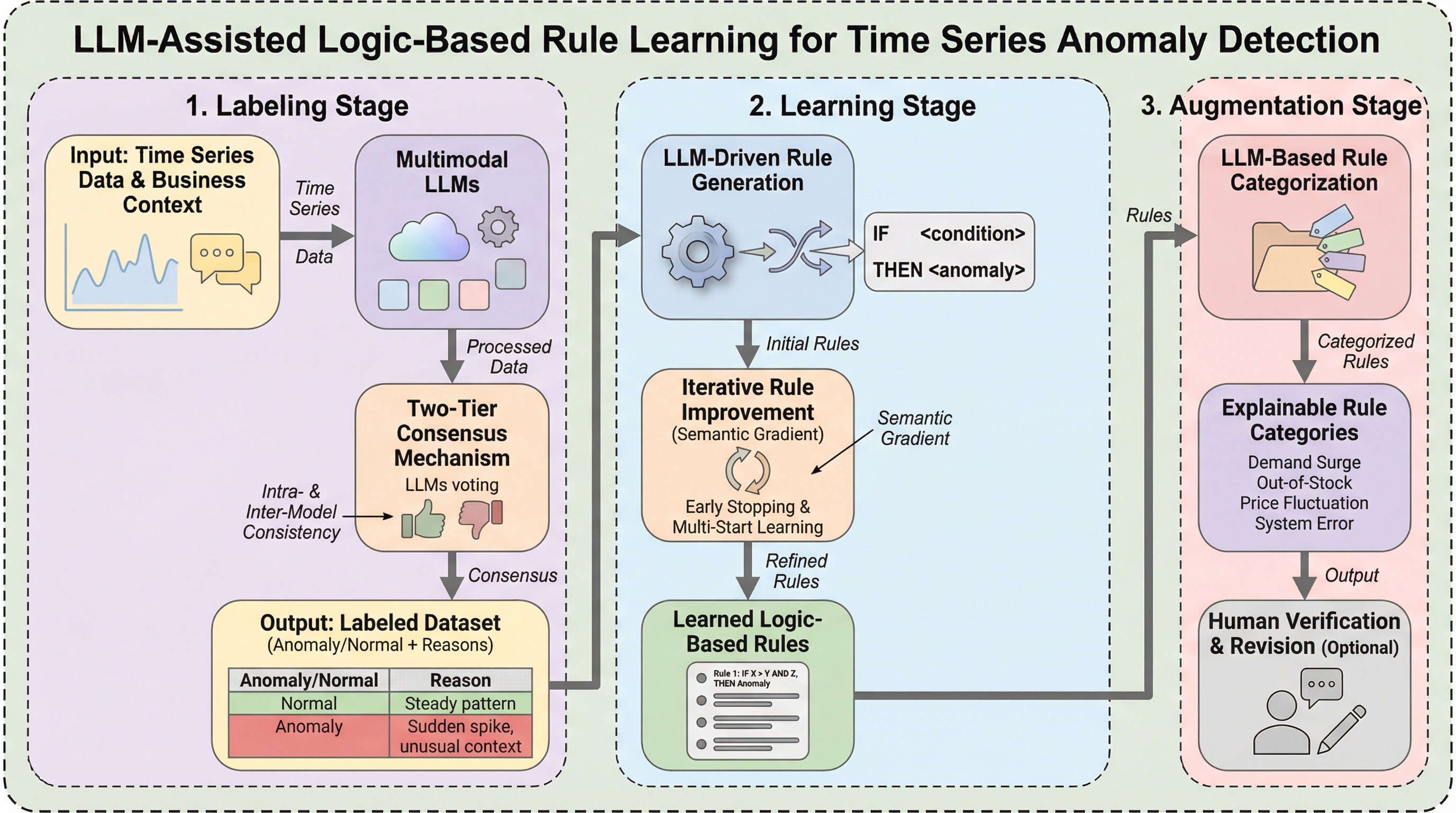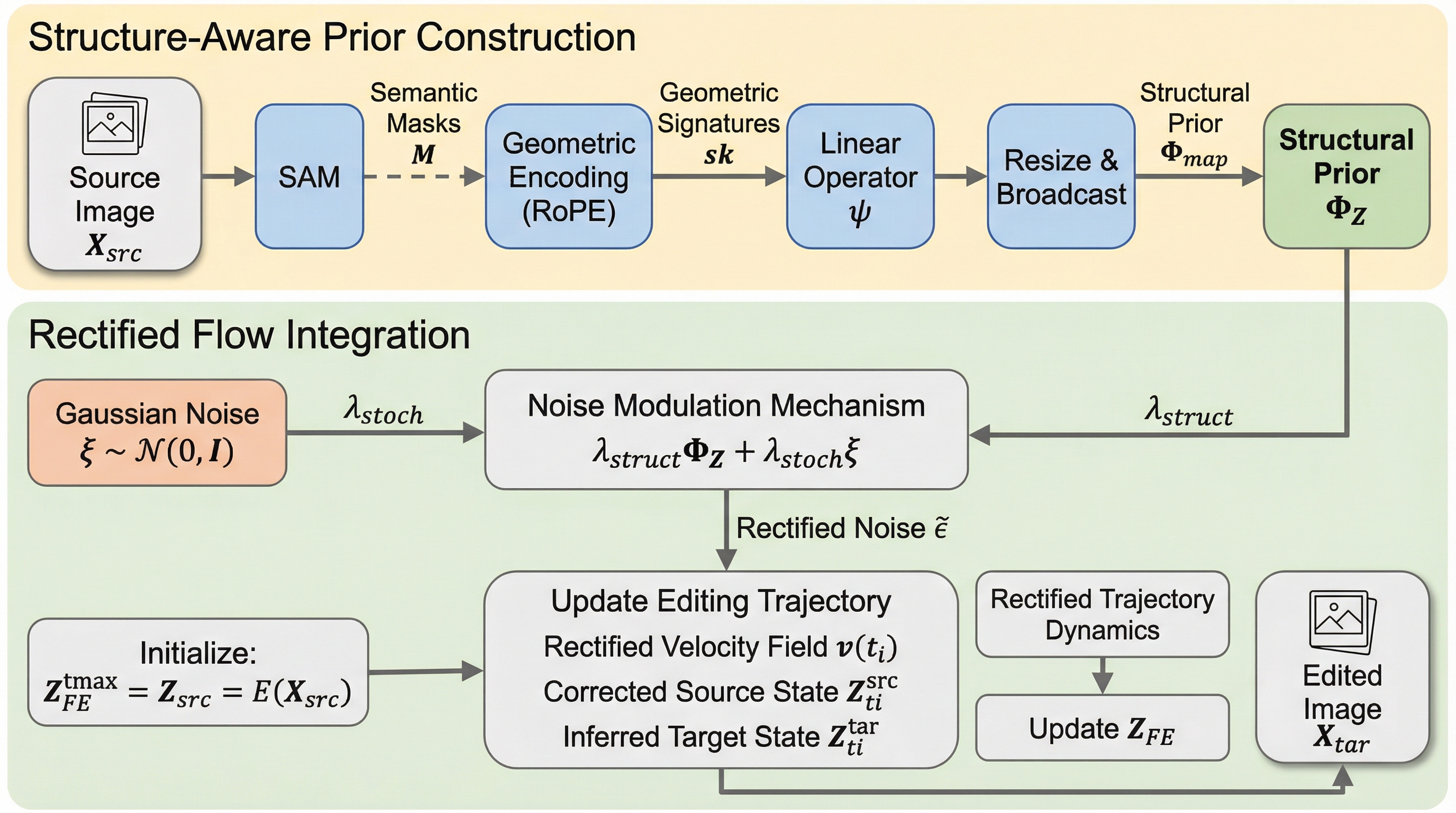
SNR-Edit: インバージョン不要なフローベース編集のための構造認識型ノイズ補正
近年のStable Diffusion 3やFLUXなどのフローベース生成モデルを用いた画像編集において、既存の「反転不要(Inversion-Free)」な手法は、ソース画像の軌跡構築に固定ガウスノイズを使用するため、実際の画像分布との間に「構造的・確率的不一致」が生じ、編集過程での軌跡のズレや背景の崩れといった構造劣化を招くという課題があった。 この問題を解決するために提案された「SNR-Edit」は、セグメンテーションモデル(SAM2)と幾何学的エンコーディング(RoPE)を用いて画像固有の構造的制約を初期ノイズに注入する「構造認識型ノイズ整流」機構を導入したトレーニング不要のフレームワークであり、確率的なノイズ成分を実際の画像の潜在的な位置に固定することで編集軌跡の漂流を抑制するものである。 PIE-Benchおよび新たに構築されたSNR-Benchを用いたSD3とFLUX上での評価において、SNR-Editは既存のFlowEditやDNAEditと比較してPSNRやSSIMなどのピクセルレベル指標およびVLMベースのスコアで優れた性能を示し、画像1枚あたり約1秒の追加コストで非編集領域の構造を忠実に保持しながらテキスト指示に忠実な編集を実現したことが実証された。