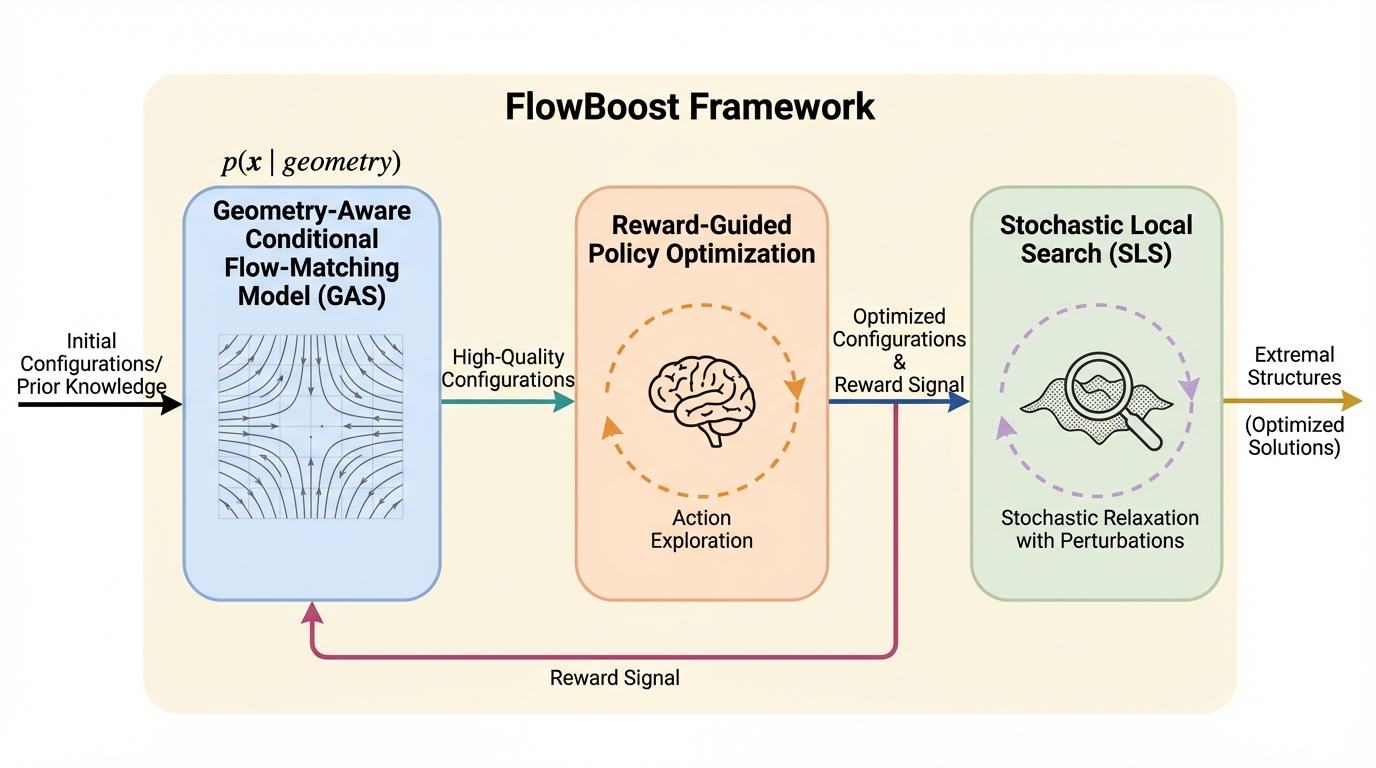
フローベースモデルによる極値的な数学的構造の発見
数学の極値幾何学における構造発見において、従来の離散的な手法や大規模言語モデル(LLM)に依存する手法の限界を打破するため、連続的な空間で直接動作する新しい生成フレームワークであるFlowBoostを提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
数学の極値幾何学における構造発見において、従来の離散的な手法や大規模言語モデル(LLM)に依存する手法の限界を打破するため、連続的な空間で直接動作する新しい生成フレームワークであるFlowBoostを提案しました。
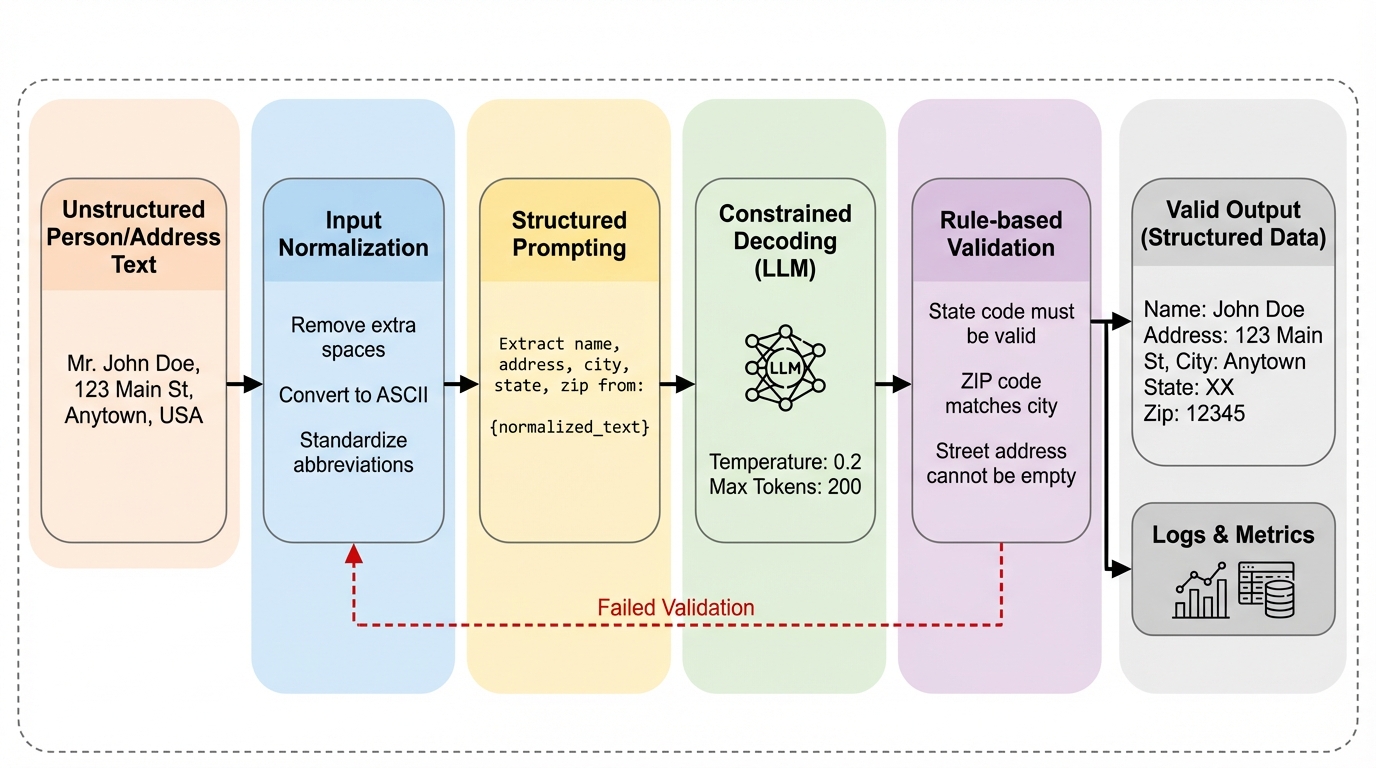
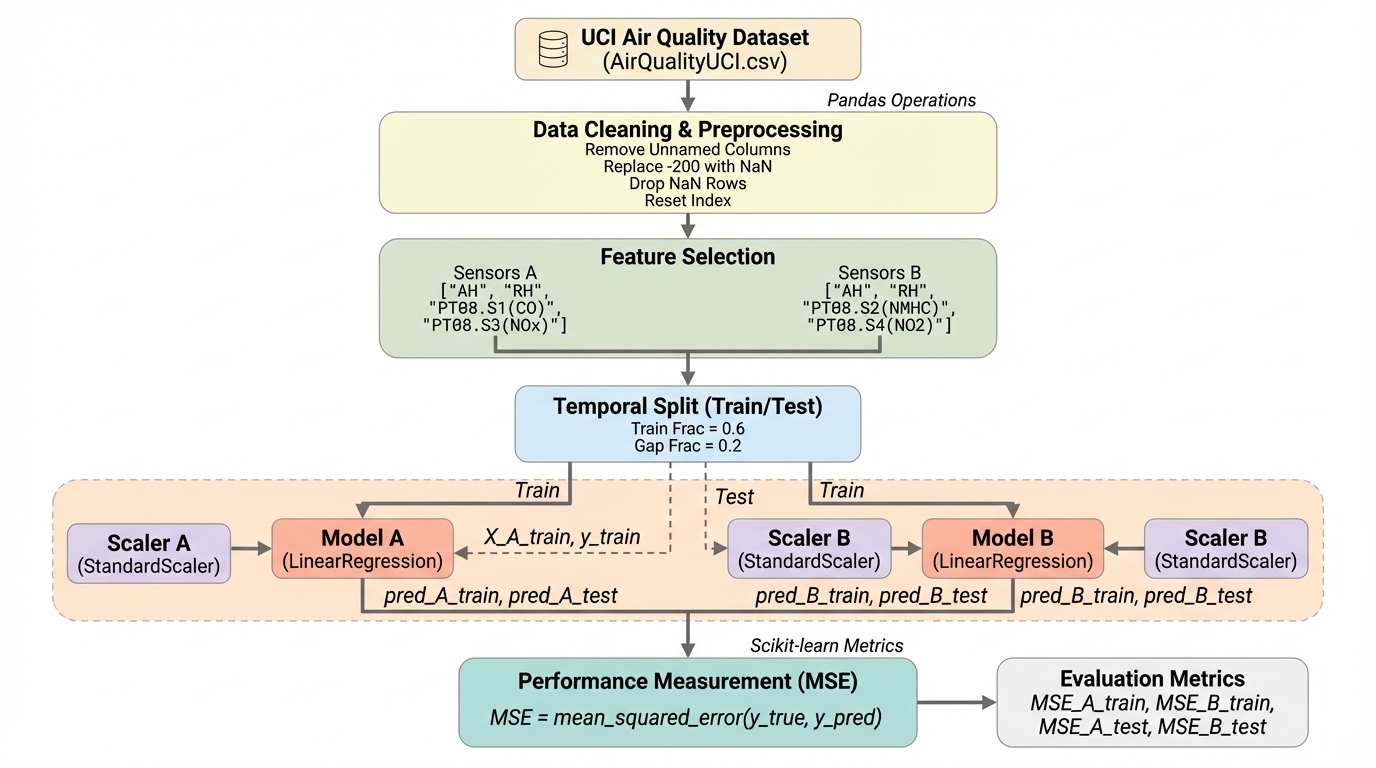
非構造化された氏名や住所のテキストを、大規模言語モデルと決定論的な検証レイヤーを組み合わせることで、17項目の詳細なスキーマに変換する新しいフレームワークを提案しました。 追加のファインチューニングを一切行わず、入力の正規化、構造化されたプロンプト、制約付きデコード、そして厳格なルールベースの検証を統合することで、99.8%という極めて高い解析精度を達成しています。 このシステムは、多言語対応や誤字脱字への耐性を持ちながら、郵便番号と州の整合性チェックなどの実世界の制約を強制することで、大規模な情報システムにおける信頼性と再現性の高いデータ抽出を低コストで実現します。
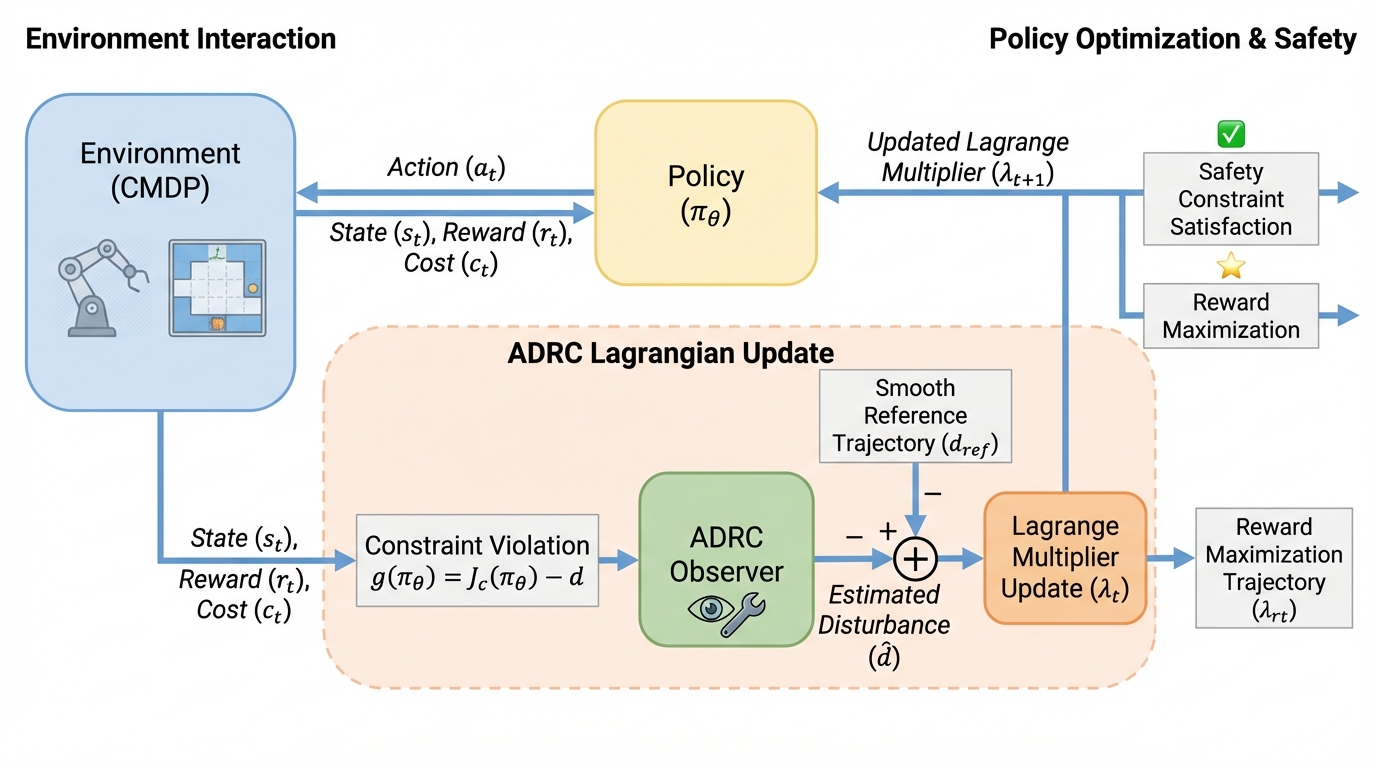
強化学習の安全性確保において、従来のラグランジュ法やPID法は学習の非定常性やノイズに起因する激しい振動と頻繁な制約違反という課題を抱えていたが、本研究は制御工学の能動的外乱抑圧制御(ADRC)を導入することで、学習中の不確実性を一括外乱としてリアルタイムに推定・相殺し、これを根本的に解決した。
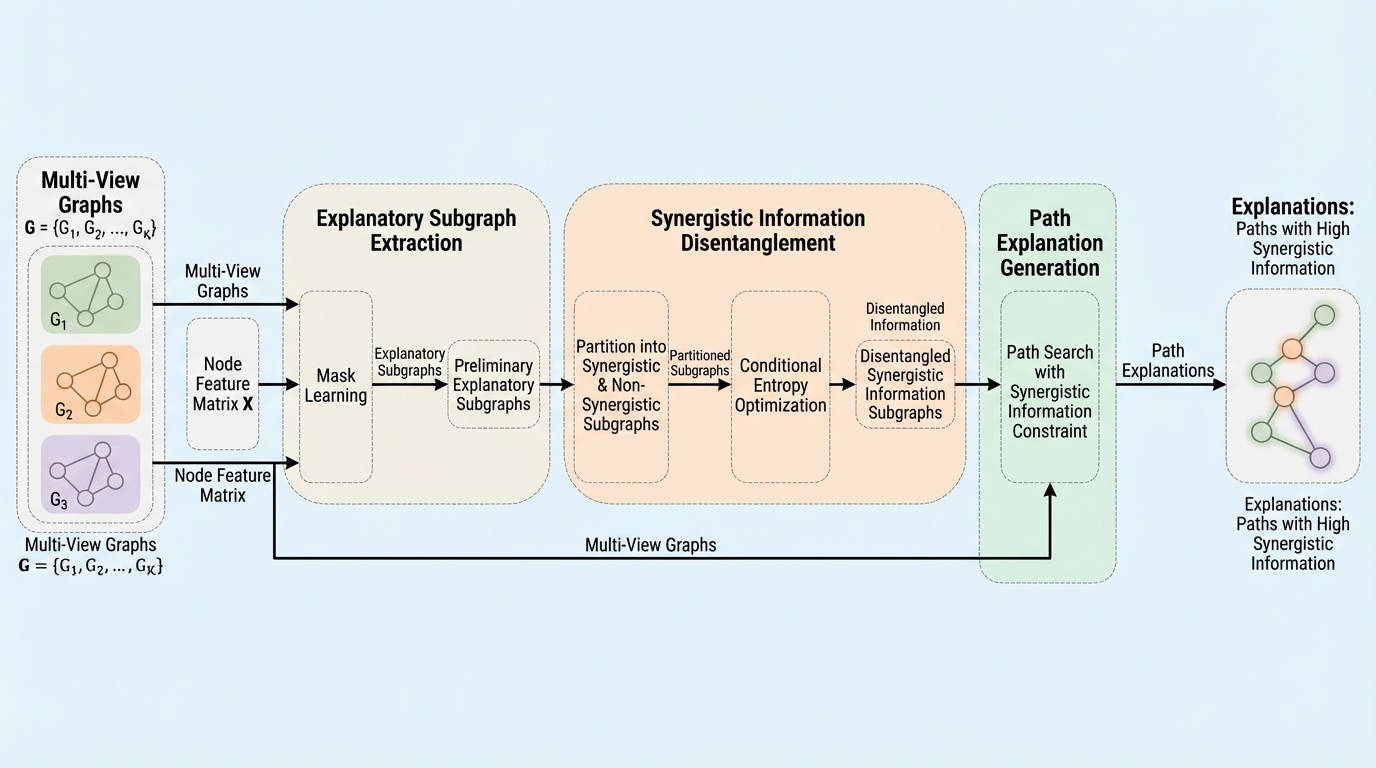
ソーシャルレコメンデーションにおいて、複数のネットワーク間に生じる相乗効果は、推薦精度を向上させる重要な要素でありながら、その非線形性と不透明さゆえに「なぜその推薦がなされたか」という根拠をユーザーが理解することを妨げるブラックボックスとなっていました。
機械学習モデルを単なる予測器ではなく、センサーデータ等から物理量などを算出する「測定機器」として利用する場面が増えていますが、従来の汎化性能や頑健性の指標だけでは、モデルが何を測定しているかを十分に評価できないという問題があります。
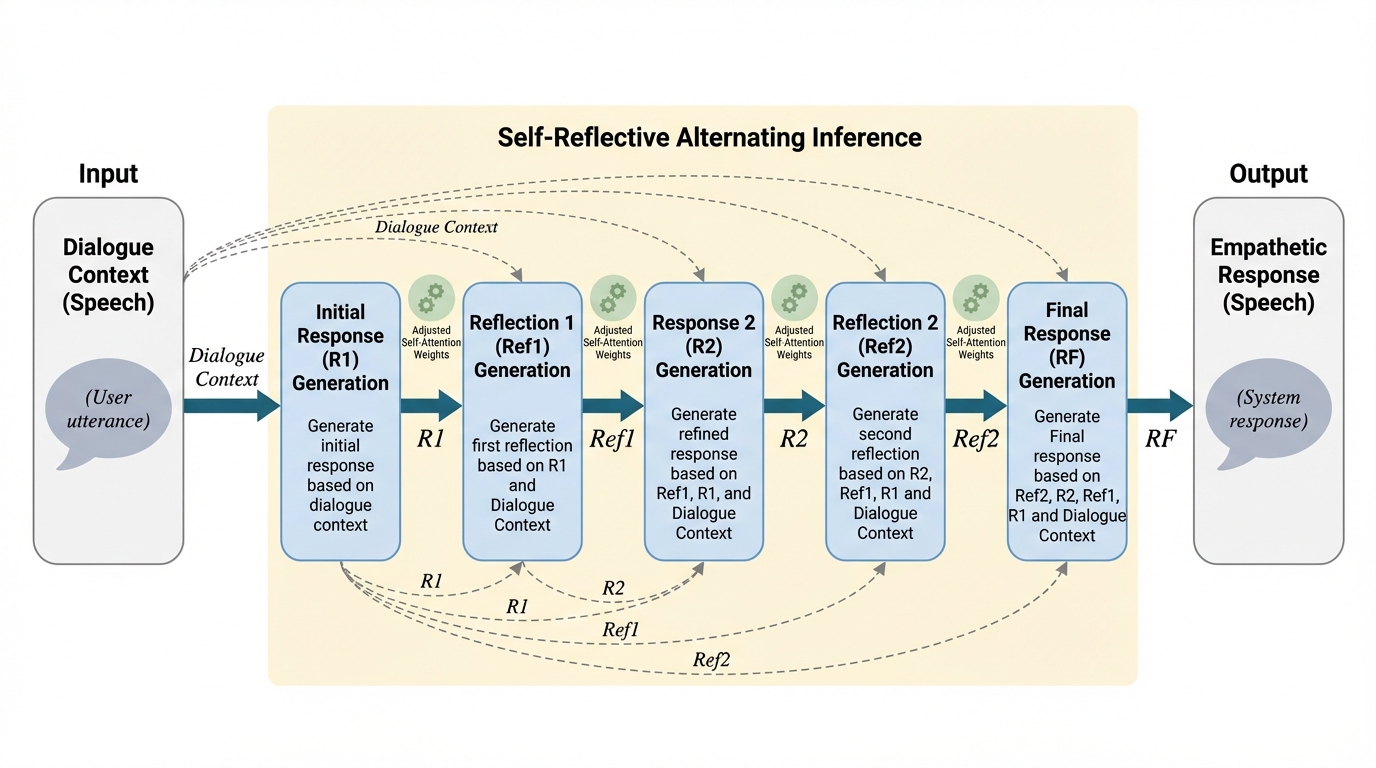
共感的な音声対話では、返答そのものだけでなく、相手の感情をどう読み取り、なぜその返答に至ったかという“途中の推論”まで扱わないと品質が伸びにくい、という問題設定が置かれています。 / そこで著者らは、共感の良し悪しを自然言語の説明として出力する評価器 EmpathyEval と、反省文と音声応答を交互に生成する ReEmpathy を組み合わせ、話す前に二度振り返るような推論過程を end-to-end の音声対話モデルへ埋め込みました。 / 実験では、記述型の共感評価、スコア型評価との相関、人手評価のいずれでも改善が見られ、単純な Chain-of-Thought を話す前に入れるだけでは足りず、反省と発話を交互に回す設計が効いていることが示されます。
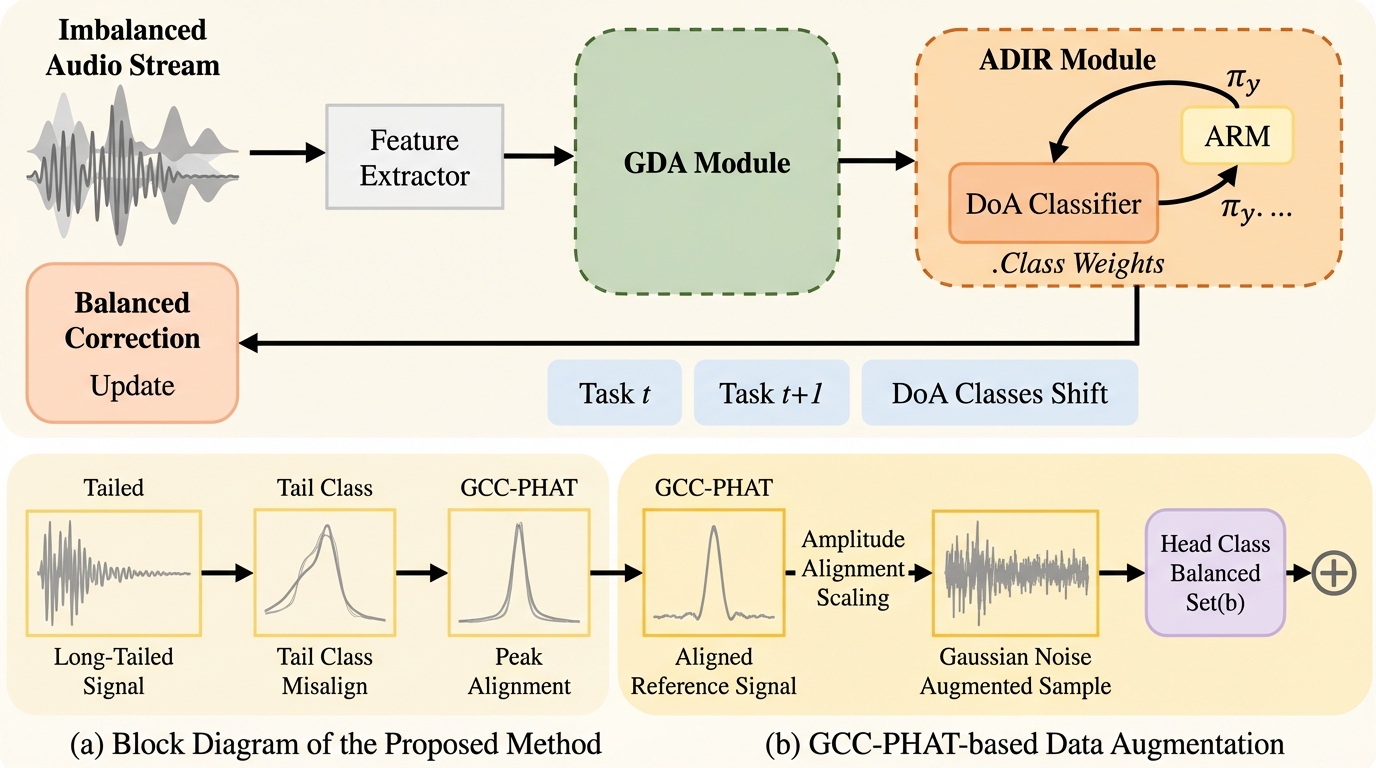
本研究は、音源定位(SSL)の増分学習において、特定の方向のデータが極端に多い「タスク内不均衡」と、タスク間でクラス分布が重なり歪む「タスク間不均衡」の二重の課題を解決する新フレームワーク「SSL-GCIL」を提案しました。
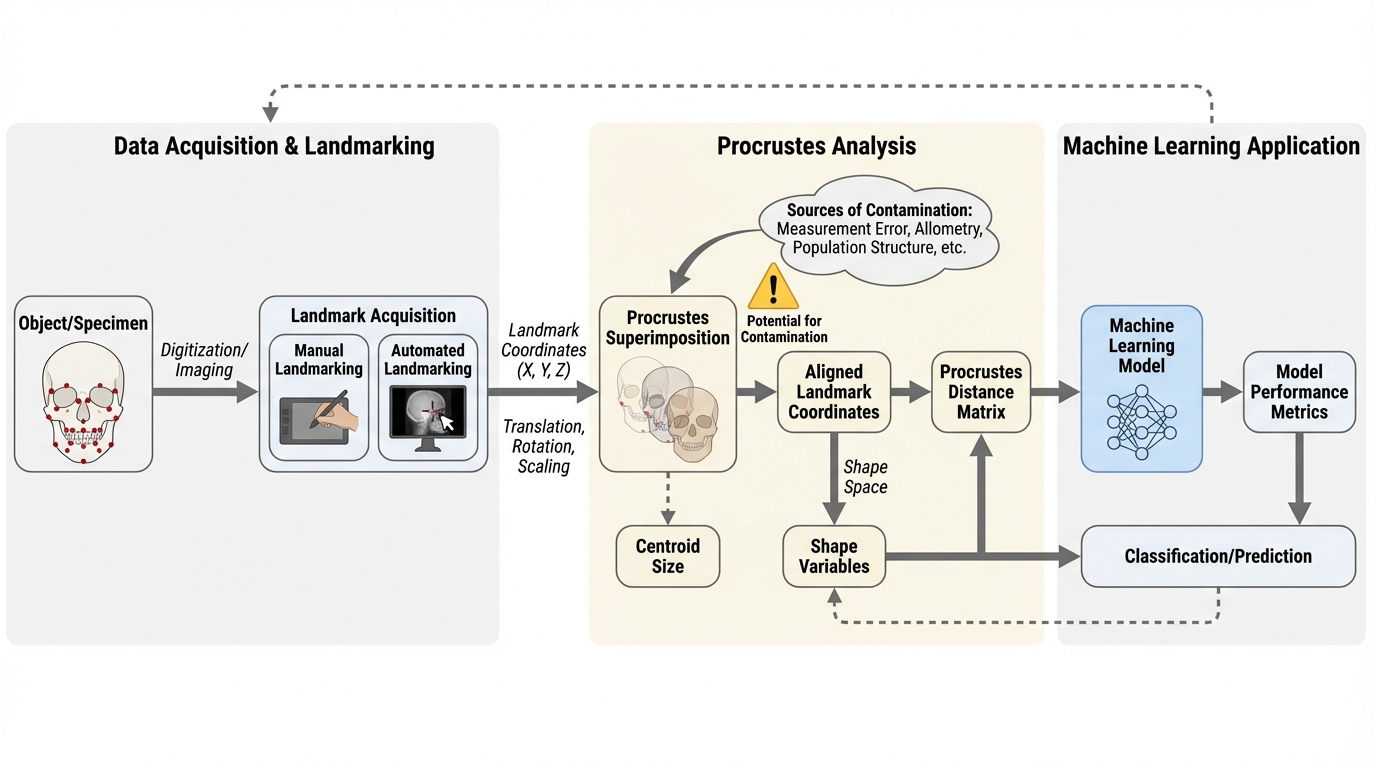
幾何学的形態測定学(GMM)を機械学習に統合する際、データ分割前に全標本を一括で整列させる標準的な一般化プロクラステス解析(GPA)が、訓練データとテストデータの間に不適切な統計的依存関係を生じさせ、予測精度を不当に高く見積もる「プロクラステス汚染」を引き起こすことを数学的・実験的に解明しました。
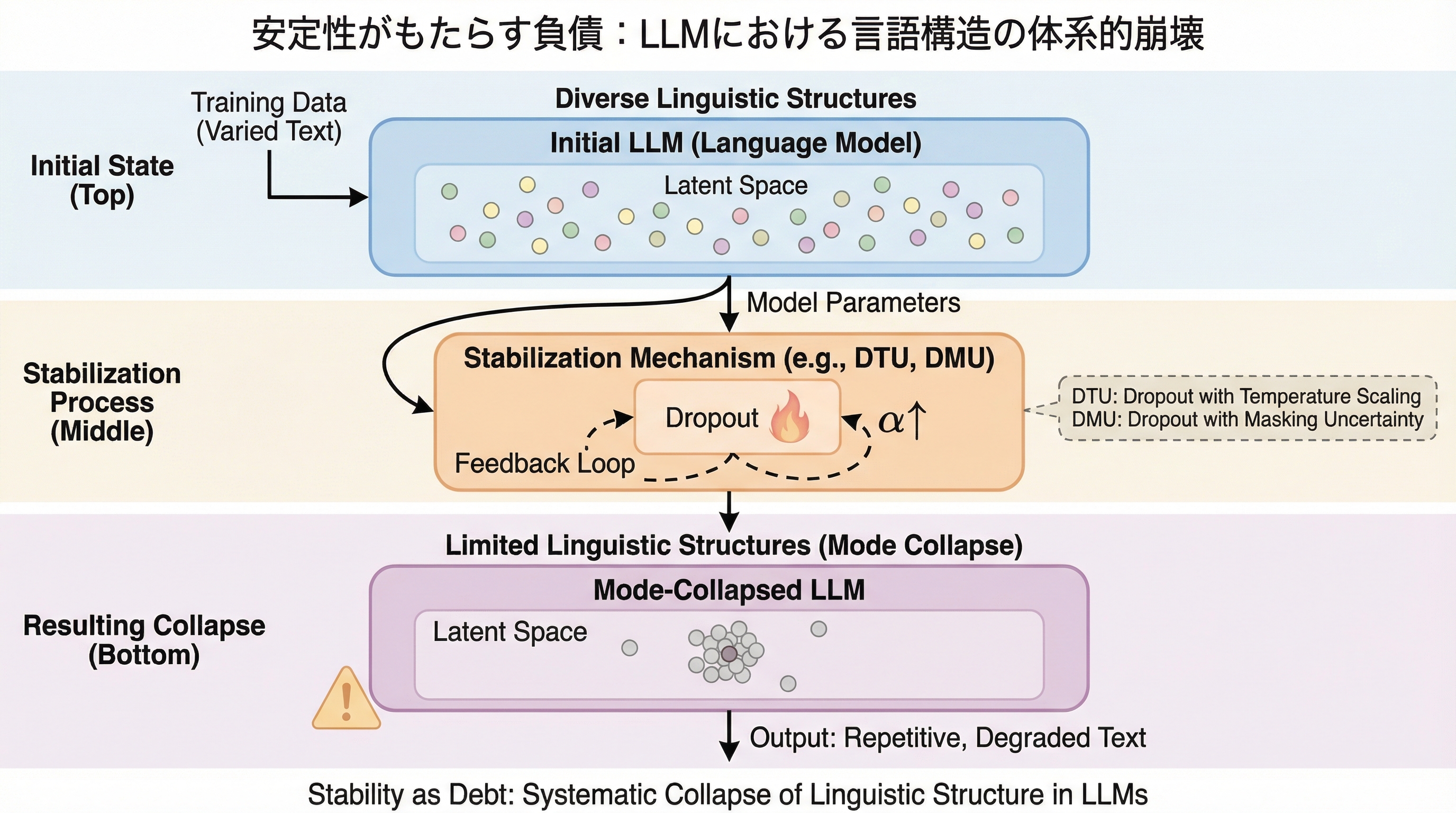
大規模言語モデルの学習において、従来は最適化の必須条件とされていた「学習の安定性」が、実は生成される言語構造の体系的な崩壊を招く「負債」となり得ることを、理論的証明と実験的検証の両面から明らかにしました。
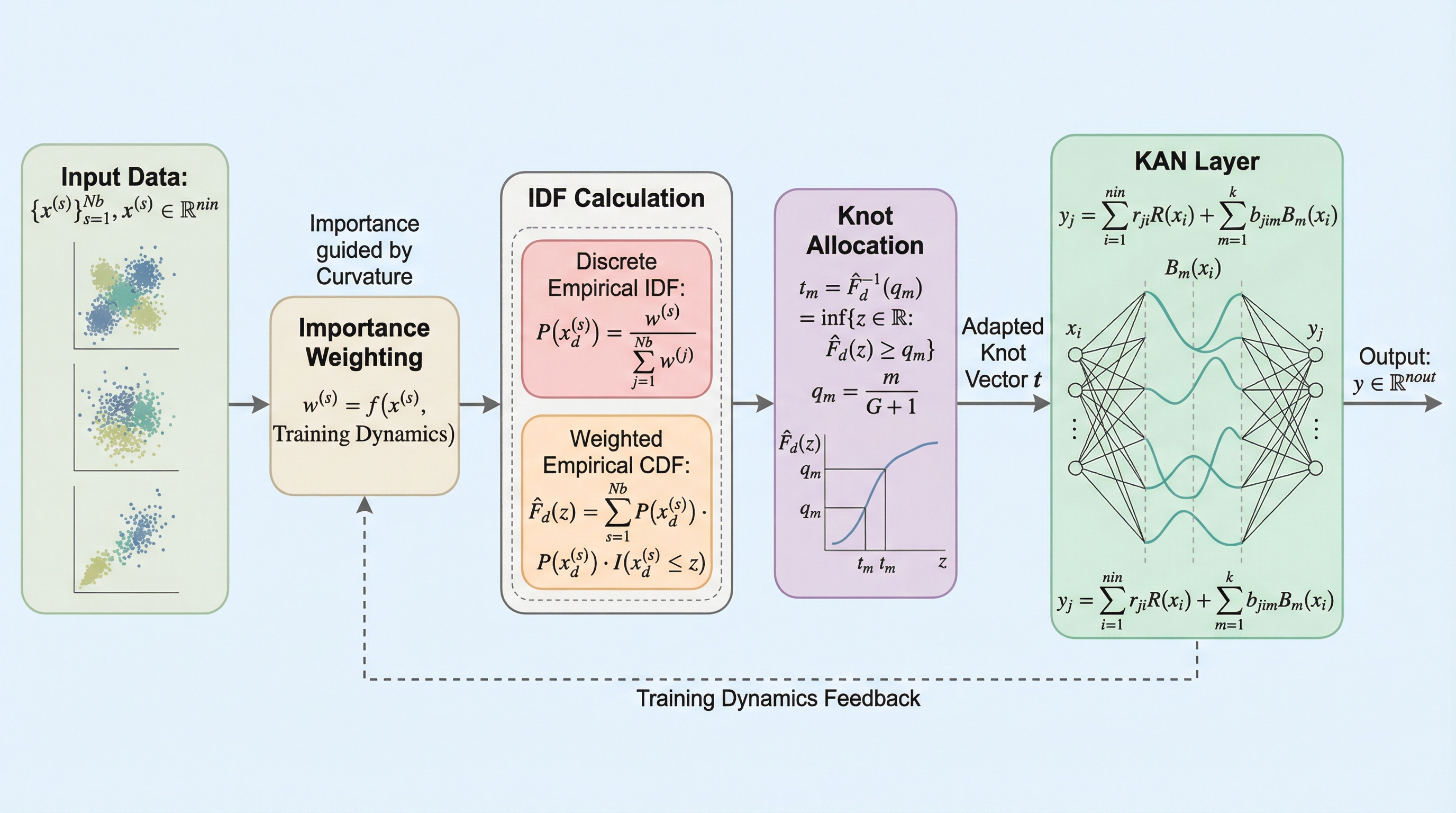
本研究は、コルモゴロフ・アーノルド・ネットワーク(KAN)の学習において、グリッドのノット配置を最適化するための「重要度密度関数(IDF)」に基づく新しい動的フレームワークを提案しました。従来の入力データの密度のみに依存する手法とは異なり、関数の幾何学的複雑さや学習中のダイナミクスを反映させるため、出力の曲率(2階偏導関数の和)を指標としてノットを再配置する戦略を導入しています。合成関数、Feynmanデータセット、および物理情報機械学習(PIML)を用いた検証の結果、提案手法は従来手法と比較して相対誤差を平均で9.4%から25.3%削減し、計算コストの増加を最小限に抑えつつ高い精度と安定性を実現したことが確認されました。