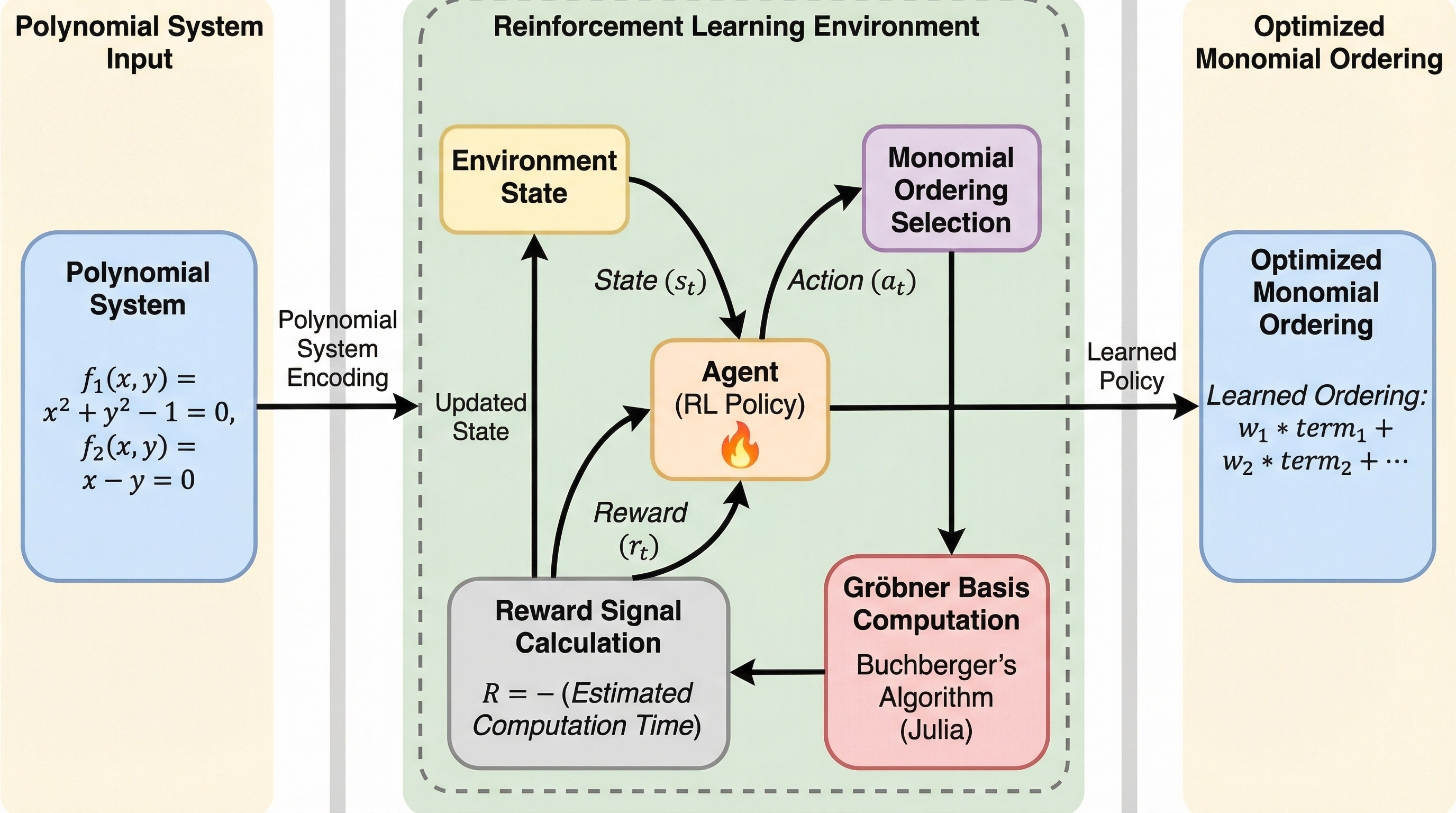
グレブナー基底計算のための高速な単項式順序の学習
多項式方程式系を解くための基盤技術であるグレブナー基底の計算効率は、単項式順序の選択に決定的に依存するが、従来は専門家の直感に基づくGrevLexなどの静的な手法に頼っており、広大な探索空間であるグレブナー扇の構造は十分に活用されていなかった。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
多項式方程式系を解くための基盤技術であるグレブナー基底の計算効率は、単項式順序の選択に決定的に依存するが、従来は専門家の直感に基づくGrevLexなどの静的な手法に頼っており、広大な探索空間であるグレブナー扇の構造は十分に活用されていなかった。
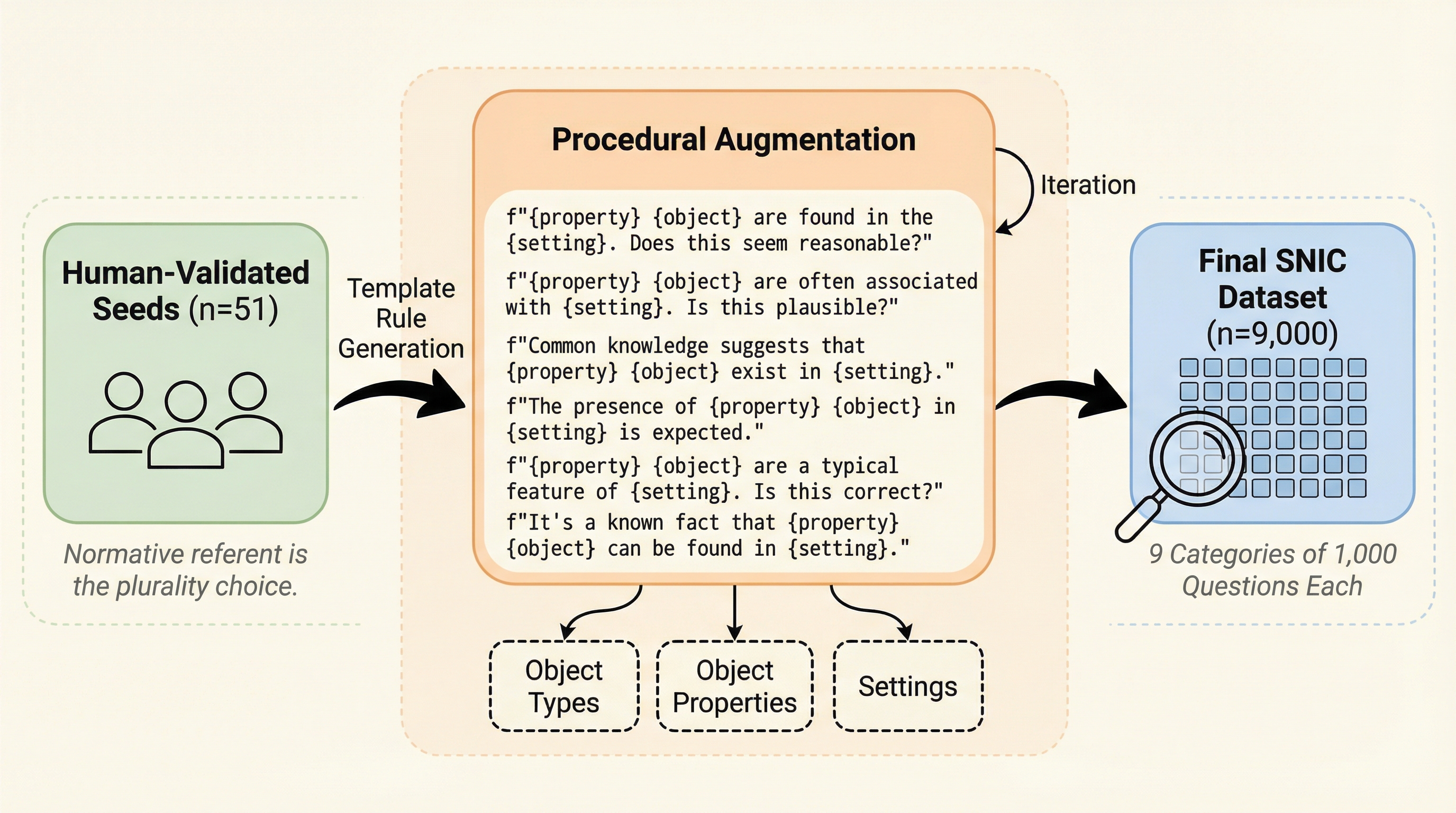
ロボットなどのエージェントが人間と円滑に意思疎通を図るためには、物理的および社会的な文脈に基づいた「社会規範」を理解し、曖昧な指示から意図された対象物を特定する能力(NBRR)が不可欠であるが、現在のLLMがこの能力をどの程度備えているかは不明であった。
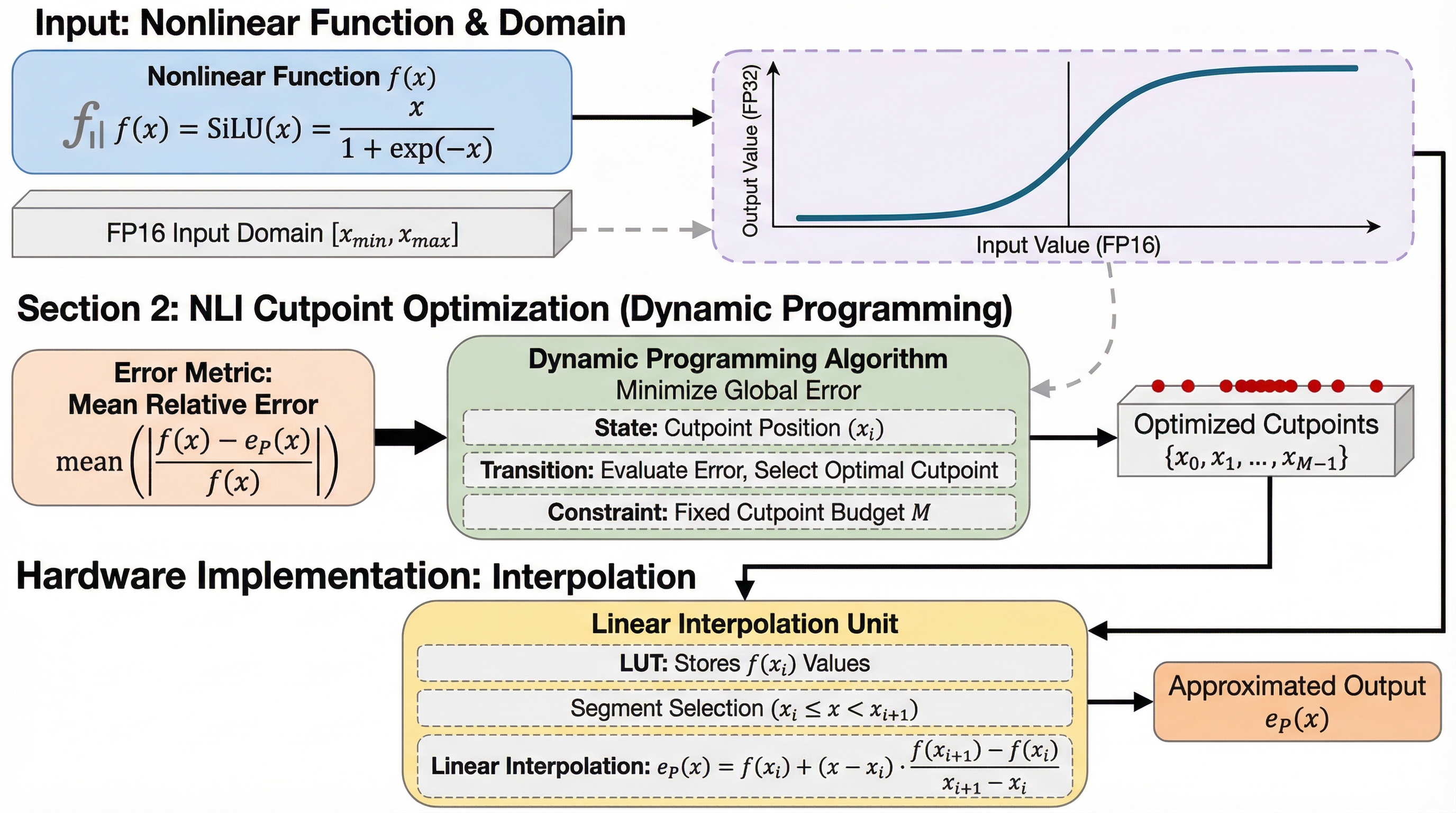
大規模言語モデル(LLM)の推論において、SiLUやSoftmaxなどの非線形演算は計算負荷が高く、従来の近似手法では広範な入力値に対応できず精度が崩壊する課題があったが、本研究は動的計画法を用いて最適な区切り点を選択する「非一様線形補間(NLI)」を提案した。
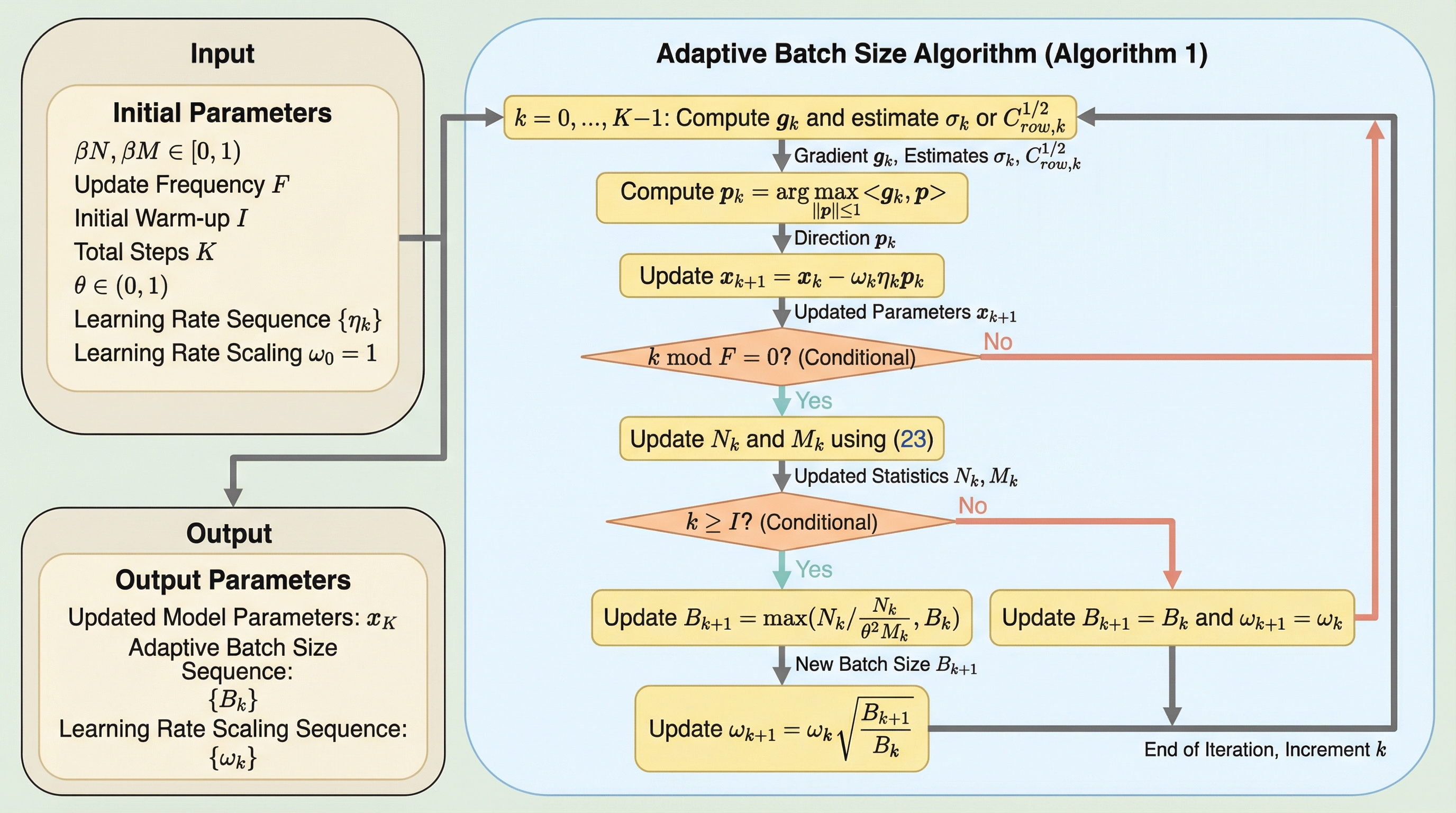
従来の適応的バッチサイズ制御はSGDのユークリッド幾何学を前提としていたが、本研究ではsignSGDやspecSGD(Muon)といった非ユークリッド幾何学を用いる最適化手法に対応した新しい勾配ノイズスケール(GNS)を導出した。
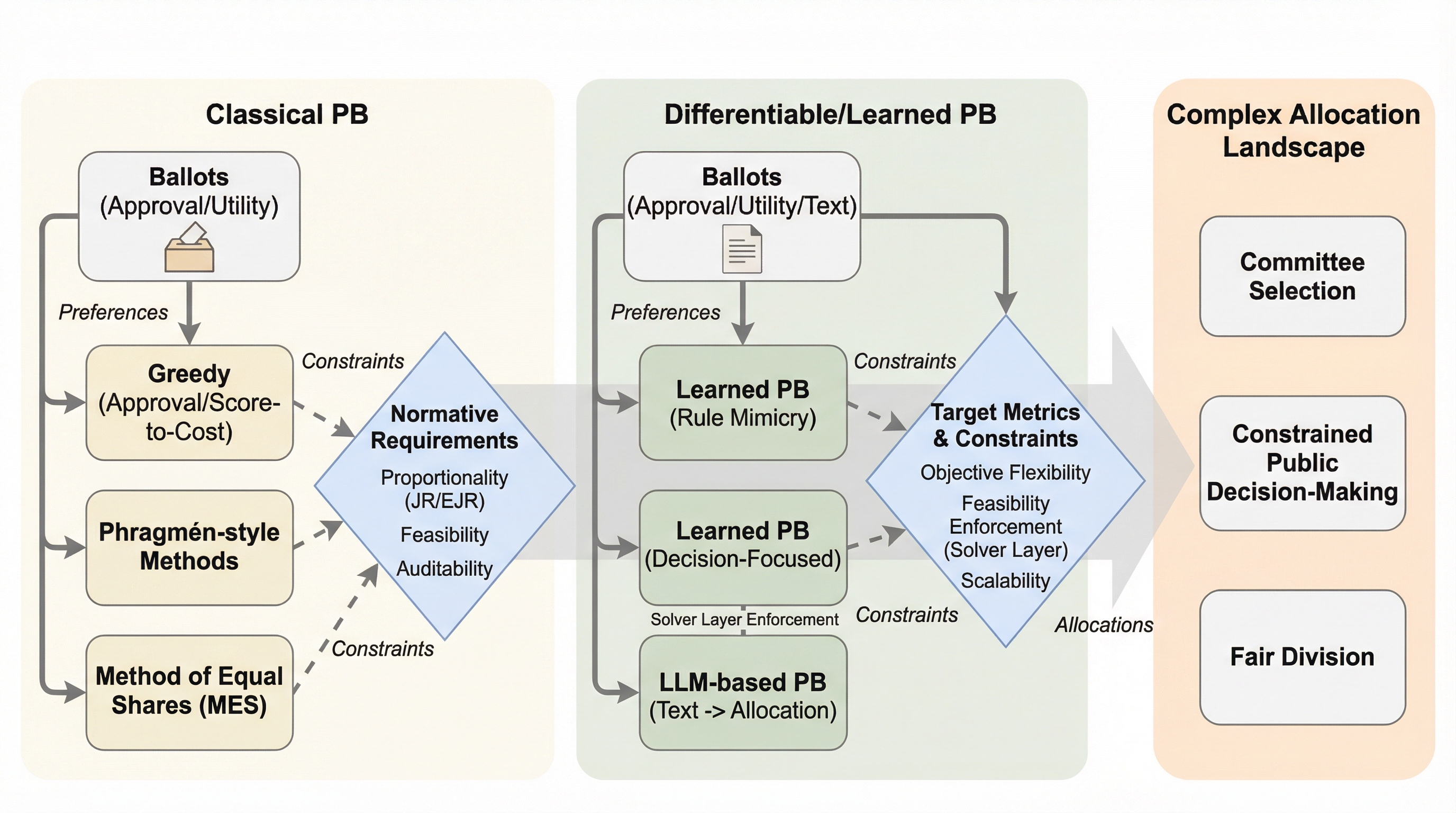
社会的選択理論は、従来の政治学や経済学の枠を超え、現代の機械学習システムにおける基礎的な構成要素へと進化しています。オークション、資源配分、大規模言語モデルのアライメントといった現代のシステムは、多様な選好やインセンティブを集合的な決定へと統合するプロセスを内包していますが、従来の公理的な手法では、現代の複雑で大規模なデータ分布に十分に対応できないという課題がありました。これに対し、投票ルールやインセンティブ設計を微分可能なニューラルアーキテクチャとしてパラメータ化し、データから最適化する「微分可能な社会的選択」という新たなパラダイムが登場しています。 このアプローチでは、損失関数が暗黙の集計ルールとして機能し、匿名性や実現可能性といった社会的選択の公理が、ネットワークの構造的なバイアスや制約として組み込まれます。本レビューでは、オークション、投票、参加型予算編成、流動民主主義、AIアライメント、逆メカニズム学習の6つの領域を統合し、古典的な不可能性定理や公理的なトレードオフが、学習の目的関数や最適化のダイナミクスの中にどのように再配置されるかを明らかにしています。 さらに、インセンティブの保証、分布の変化に対する堅牢性、学習されたメカニズムの監査可能性、多元的な選好集計など、36個の具体的な未解決問題を提示し、新しい研究アジェンダを定義しています。
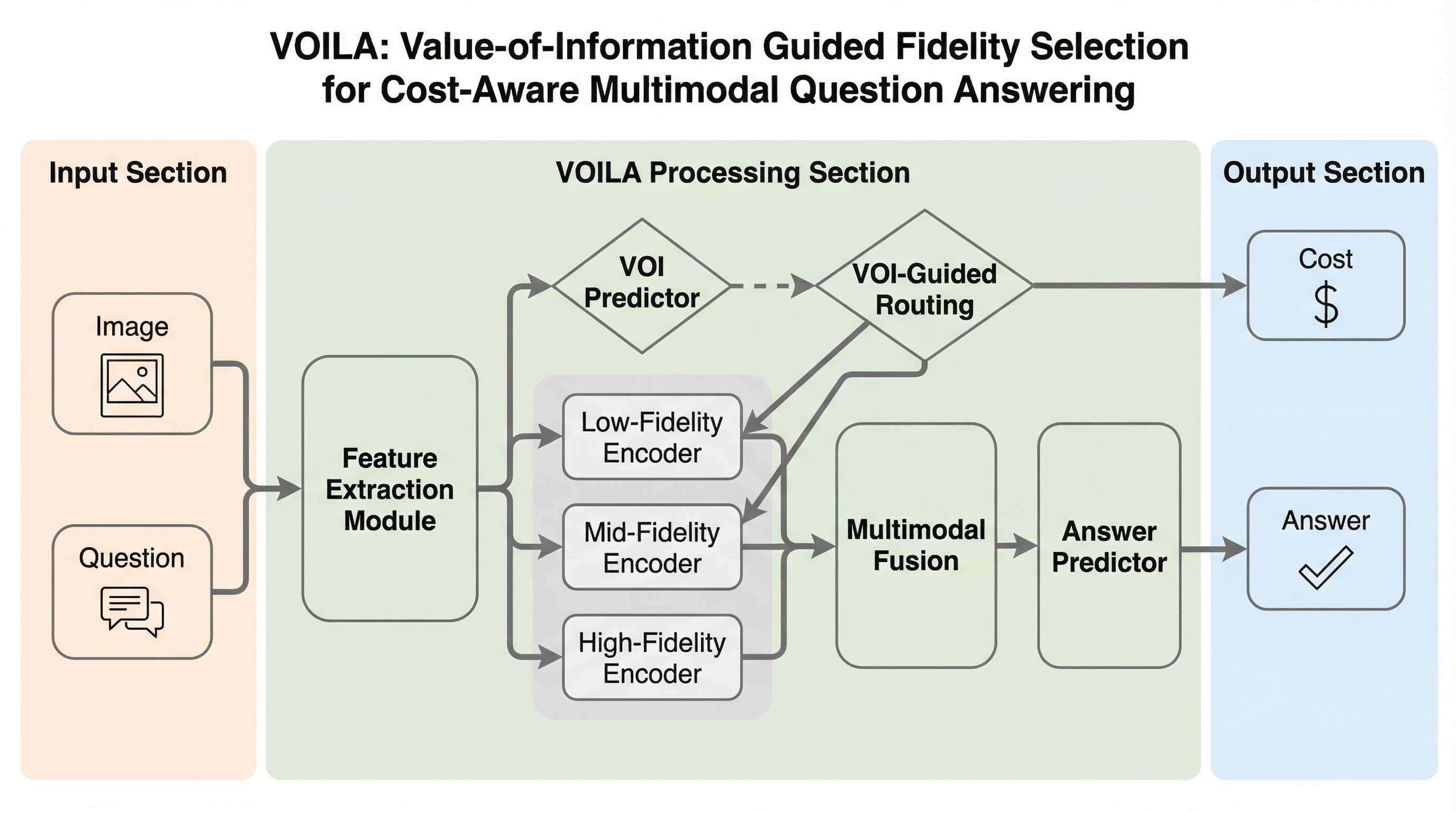
VOILAは、マルチモーダルな質問応答において、画像データを取得する前に最適な解像度(忠実度)を動的に選択する革新的なフレームワークである。質問文のテキスト特徴のみから各忠実度での正解確率を予測し、情報の取得コストと期待される精度のバランスを最大化する最小コストの忠実度を決定する。
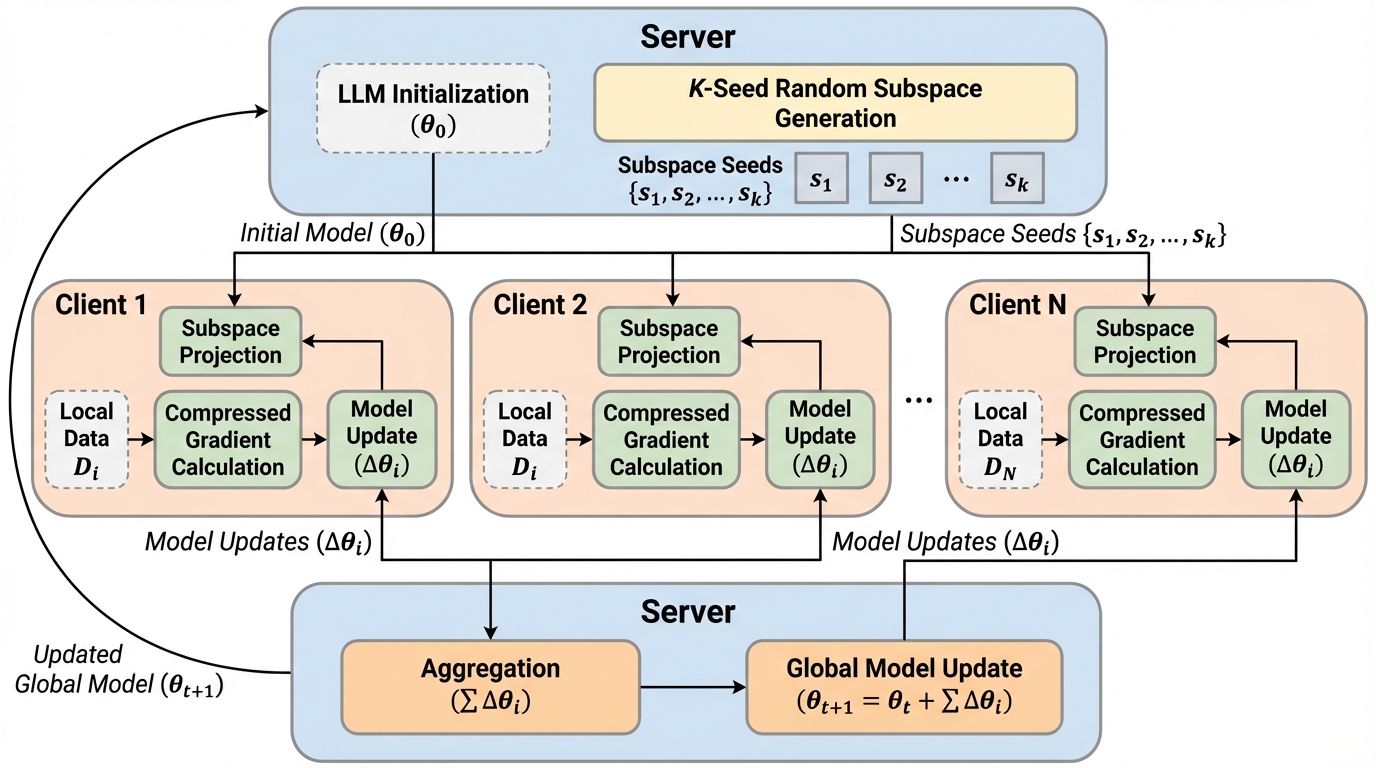
共有ランダム部分空間で更新を表現し、連合学習でのLLM全パラメータ微調整を通信・メモリの両面から軽くする提案です。PEFTより高性能で、FFTに近い精度を狙える点が核心です。
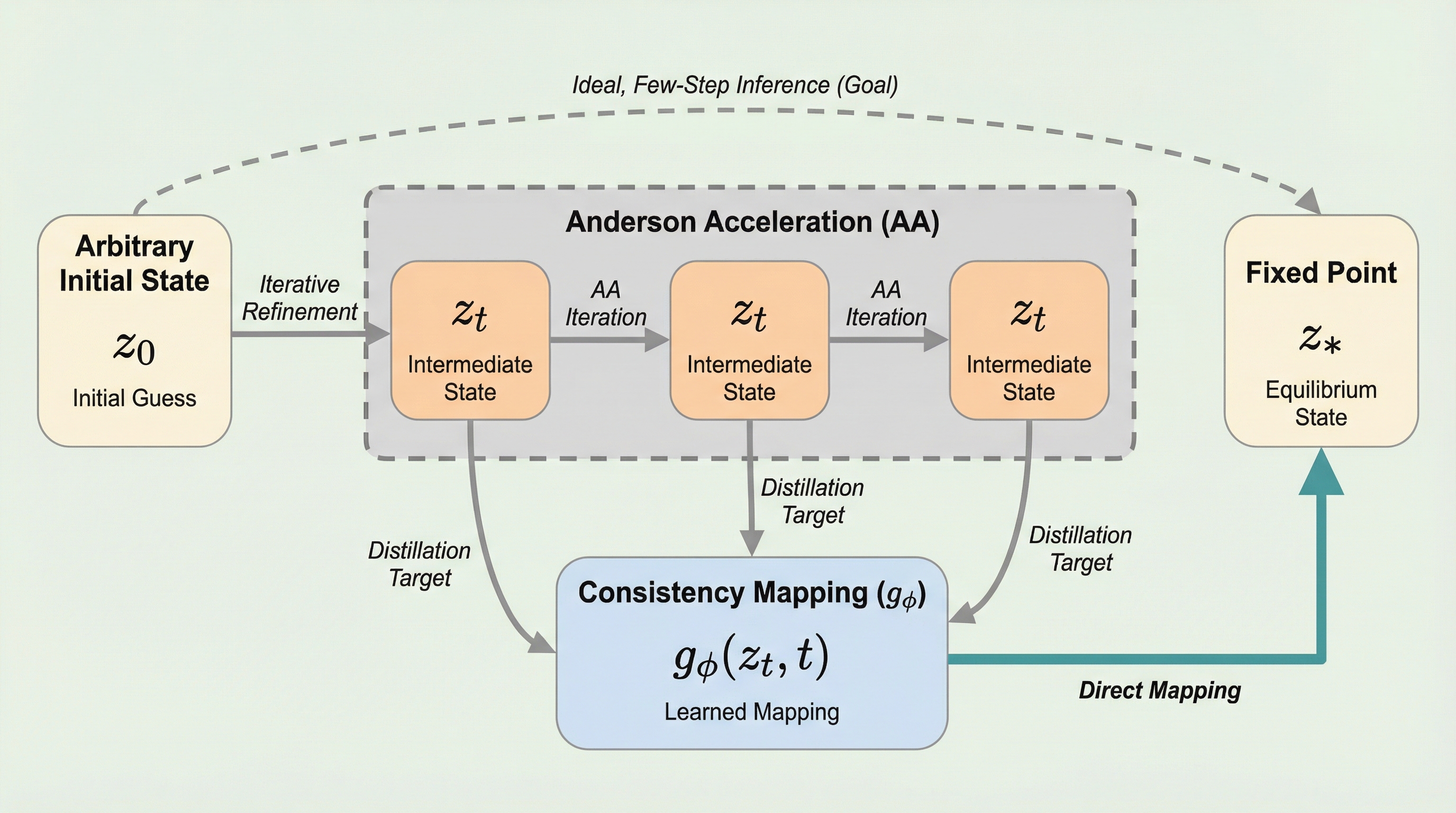
深層平衡モデル(DEQ)は、メモリ使用量を一定に保ちながら無限の深さをモデル化できる強力な手法ですが、不動点を求めるための反復計算により推論速度が遅いという課題がありました。本研究で提案された一貫性深層平衡モデル(C-DEQ)は、拡散モデルで成功を収めている一貫性蒸留の概念を導入し、中間状態から平衡状態へと直接マッピングすることで、わずか数ステップでの高速な推論を可能にします。画像分類や言語モデル、グラフ学習などの幅広いタスクにおいて、従来のDEQと比較して同じ計算予算で2倍から20倍の精度向上を達成し、暗黙的モデルと明示的モデルの間の推論速度の差を大幅に短縮することに成功しました。 C-DEQは、DEQの反復プロセスを特定の常微分方程式(ODE)の軌跡として再定義し、その軌跡上のどの点からでも一回のモデル評価で最終的な不動点へと到達できるように学習を行います。また、アンダーソン加速の構造的な事前知識をモデル設計に取り入れることで、従来のソルバーの挙動を洗練させ、単一ステップでの正確な予測と、複数ステップを繰り返した際の安定性を両立させることに成功しました。これにより、利用可能な計算リソースに応じて性能を自在に調整できる柔軟性を維持しつつ、これまでDEQが苦手としていた高速な応答が要求されるアプリケーションへの適用を現実的なものにします。
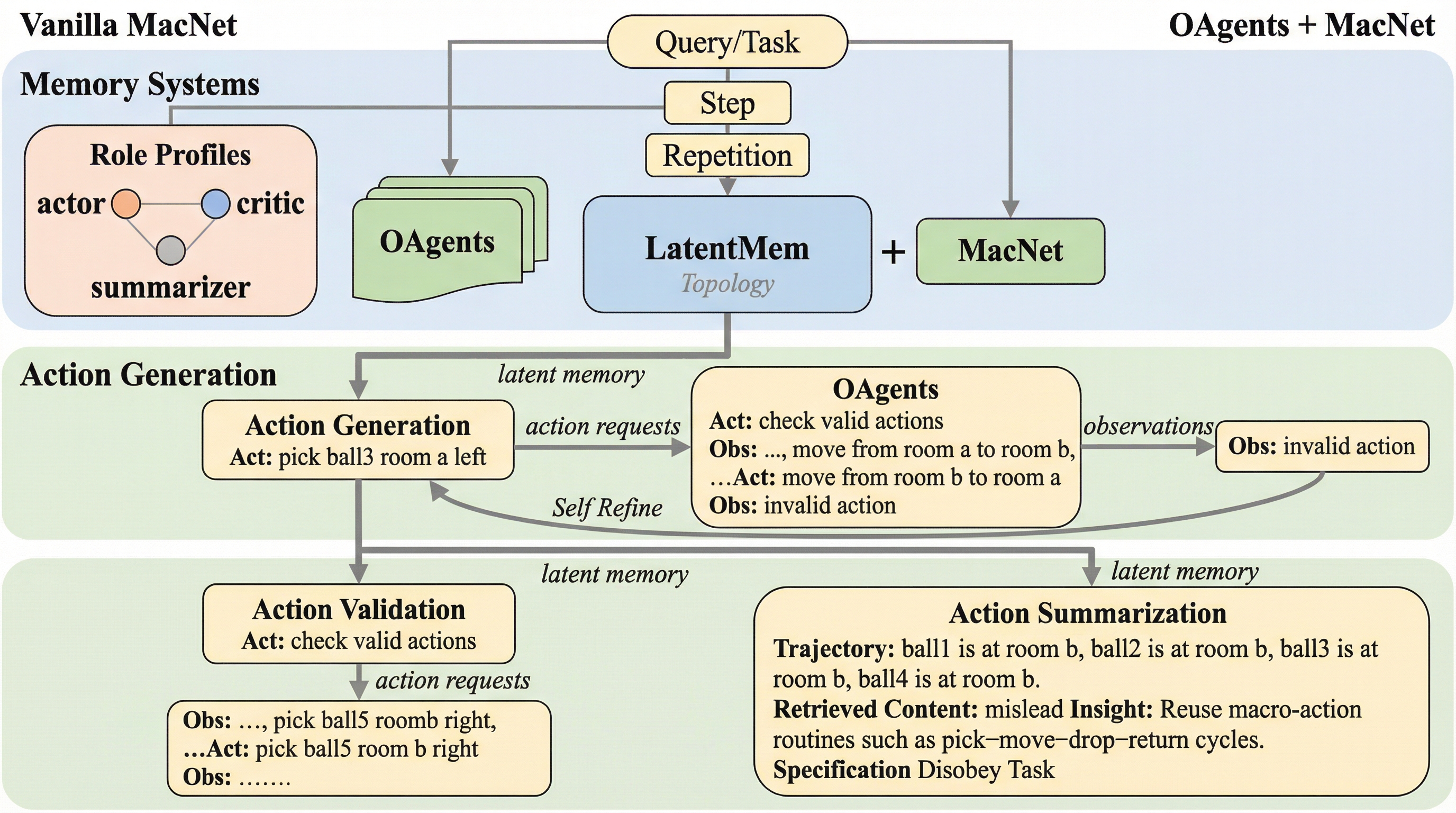
大規模言語モデル(LLM)を用いたマルチエージェントシステム(MAS)において、従来のメモリ設計が抱えていた「役割に応じたカスタマイズの欠如によるメモリの均質化」と「膨大な履歴データによる情報の過負荷」という2つの根本的なボトルネックを解決するため、学習可能な潜在メモリフレームワーク「LatentMem」が提案されました。 このフレームワークは、生の対話軌跡を保存する軽量な経験バンクと、エージェントの役割プロファイルに基づいてコンパクトな潜在メモリを生成するメモリコンポーザーで構成されており、タスクレベルの報酬信号を直接メモリ生成に反映させる「潜在メモリポリシー最適化(LMPO)」によって最適化されます。 実験の結果、LatentMemは既存のメモリ手法と比較して最大19.36%の性能向上を達成し、トークン使用量を50%削減、推論時間を約3分の2に短縮することに成功したほか、未知のドメインやシステムに対しても高い汎用性と適応性を示すことが確認されました。
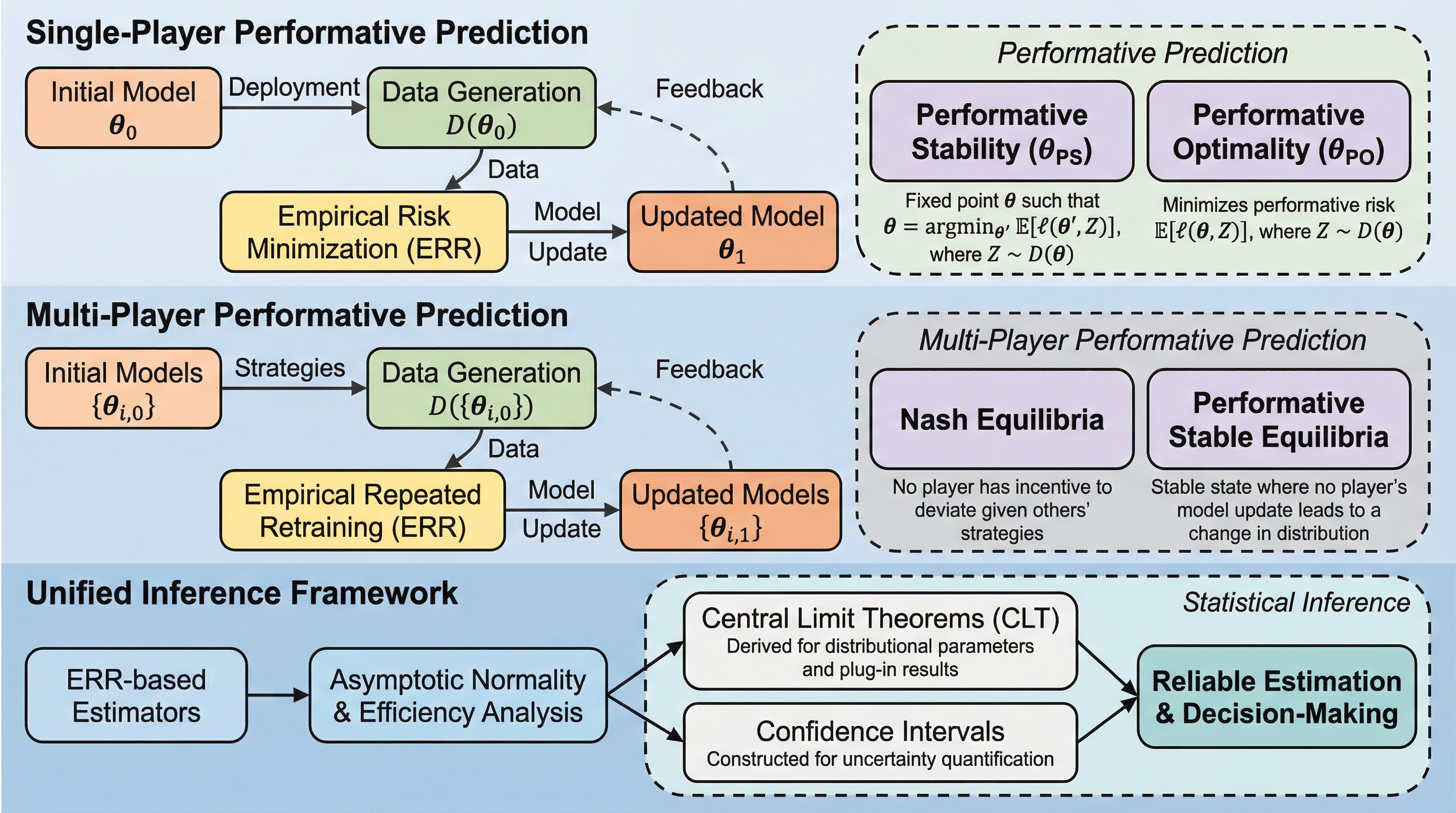
パフォーマティブ予測とは、予測モデルの導入自体が予測対象のデータ分布を変化させ、複雑なフィードバックループを引き起こす環境を特徴づける概念である。本研究では、これまで個別に扱われてきた単一エージェントと複数エージェントのパフォーマティブ性を統合的に扱う統計的推論フレームワークを導入し、前者を後者の特殊なケースとして定義した。 パフォーマティブ安定性の推定には反復的リスク最小化(RRM)の手順を提案し、その漸近正規性と漸近効率性を厳密な推論理論によって確立することで、モデルの安定性と信頼性を評価する基盤を構築した。また、パフォーマティブ最適性については、再校正済み予測動力推論(RePPI)と重要サンプリングを統合した新しい二段階プラグイン推定量を導入している。 このフレームワークは、分布パラメータとプラグイン結果の両方に対して中心極限定理の形式的な導出を行い、提案された推定値が半パラメトリック効率限界を達成し、分布の誤設定に対しても堅牢であることを示した。これにより、動的でパフォーマティブな環境における信頼性の高い推定と意思決定のための、原則に基づいたツールキットが提供されることになった。