NLI: 非一様線形補間による非線形演算の近似を用いた効率的なLLM推論
大規模言語モデル(LLM)の推論において、SiLUやSoftmaxなどの非線形演算は計算負荷が高く、従来の近似手法では広範な入力値に対応できず精度が崩壊する課題があったが、本研究は動的計画法を用いて最適な区切り点を選択する「非一様線形補間(NLI)」を提案した。
TL;DR(結論)
大規模言語モデル(LLM)の推論において、SiLUやSoftmaxなどの非線形演算は計算負荷が高く、従来の近似手法では広範な入力値に対応できず精度が崩壊する課題があったが、本研究は動的計画法を用いて最適な区切り点を選択する「非一様線形補間(NLI)」を提案した。 NLIはデータの事前較正を必要とせず、FP16ドメイン全体で補間誤差を最小化するグローバルな最適解をベルマンの最適性原理に基づいて導き出すアルゴリズムと、それに基づいたプラグアンドプレイ可能なハードウェアエンジンで構成されており、多様なモデルや層で再利用が可能である。 検証の結果、Llama3やQwenなどの主要なLLMにおいてFP32と同等の精度を維持しつつ、既存の最先端設計と比較してハードウェアの計算効率を4倍以上に向上させることに成功しており、リソース制約のあるエッジデバイスへのLLM展開を強力に支援する。
なぜこの問題か
大規模言語モデル(LLM)は、テキスト翻訳や画像分類、テキスト生成など多岐にわたる分野で驚異的な成果を上げているが、その展開には膨大なメモリフットプリントと計算コストが伴う。近年の研究では、線形層の圧縮と加速において大きな進展があり、SmoothQuantやOSTquantといった手法によって、重みや活性化値を低ビットの整数(INT8やW4A8など)に量子化することが可能になった。また、NVIDIA H100のTensor CoreやGemminiのようなハードウェアアーキテクチャも、これらの低ビット線形演算をネイティブにサポートしている。しかし、SiLU、RMSNorm、Softmaxといった非線形層の計算は、依然として高精度な浮動小数点演算(FP32など)に大きく依存しており、これが推論全体のボトルネックとなっている。 例えば、H100 SXM5において、FP16の線形演算能力は特殊関数ユニットの1024倍に達するが、ヘッドアテンションサイズが128のシナリオでは、線形演算の需要は非線形演算の256倍にとどまる。この演算能力と需要の乖離が、LLM推論における線形操作と非線形操作の性能差をさらに悪化させている。…
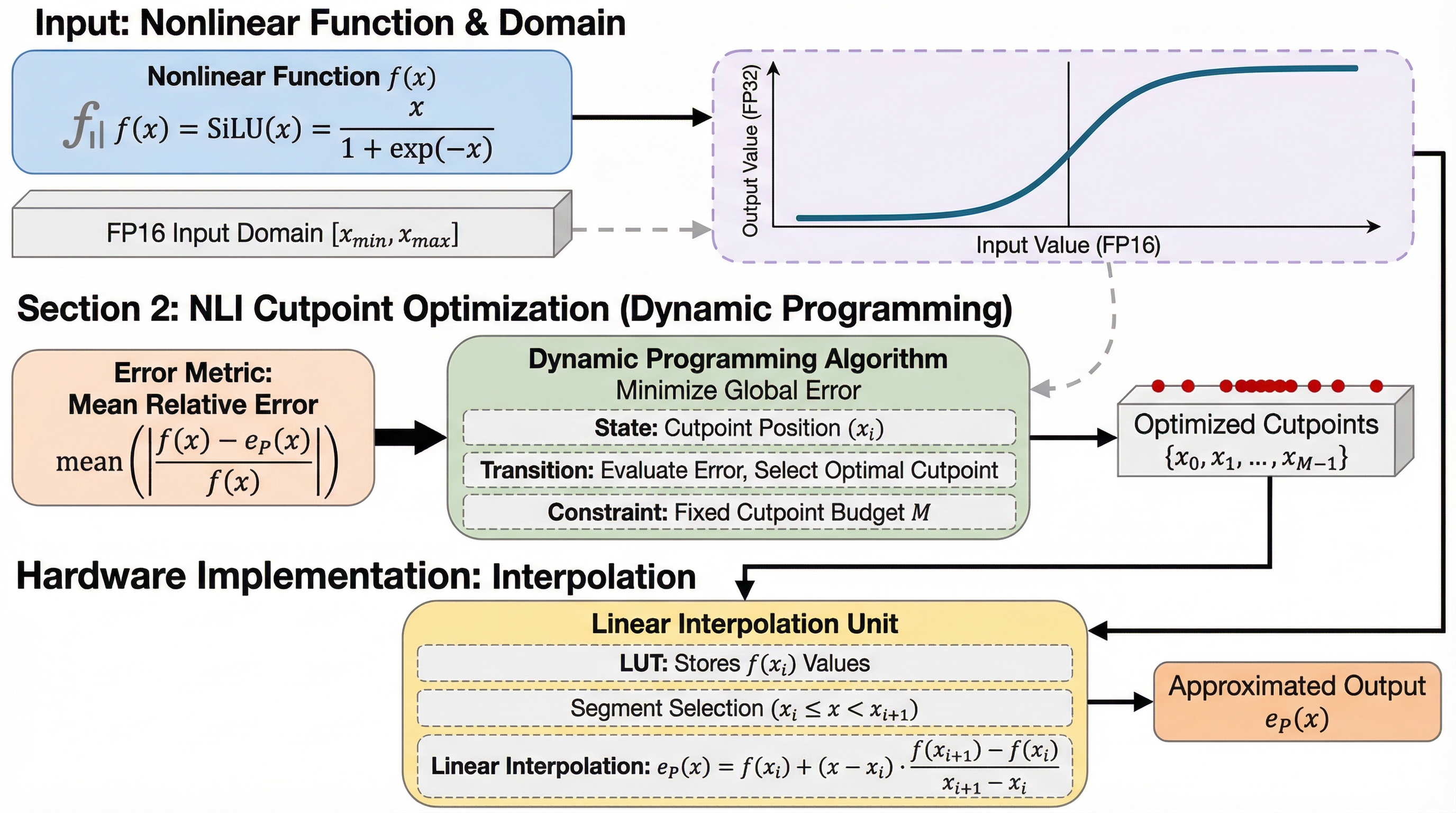
核心:何を提案したのか
本論文では、較正不要で動的計画法による最適化を適用した、ハードウェア親和性の高いフレームワーク「非一様線形補間(NLI)」を提案している。このフレームワークは、ソフトウェア側の「NLI-Algorithm」とハードウェア側の「NLI-Engine」の2つの主要コンポーネントで構成されている。NLIの核心的なアイデアは、非線形関数の評価をFP16ドメインにおける非一様な線形補間に置き換えることにある。従来の等間隔なサンプリングとは異なり、関数の曲率や計算精度を考慮して、誤差を最小化するように区切り点(カットポイント)を戦略的に配置する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related