VOILA: コストを考慮したマルチモーダル質問応答のための情報価値に基づく忠実度選択
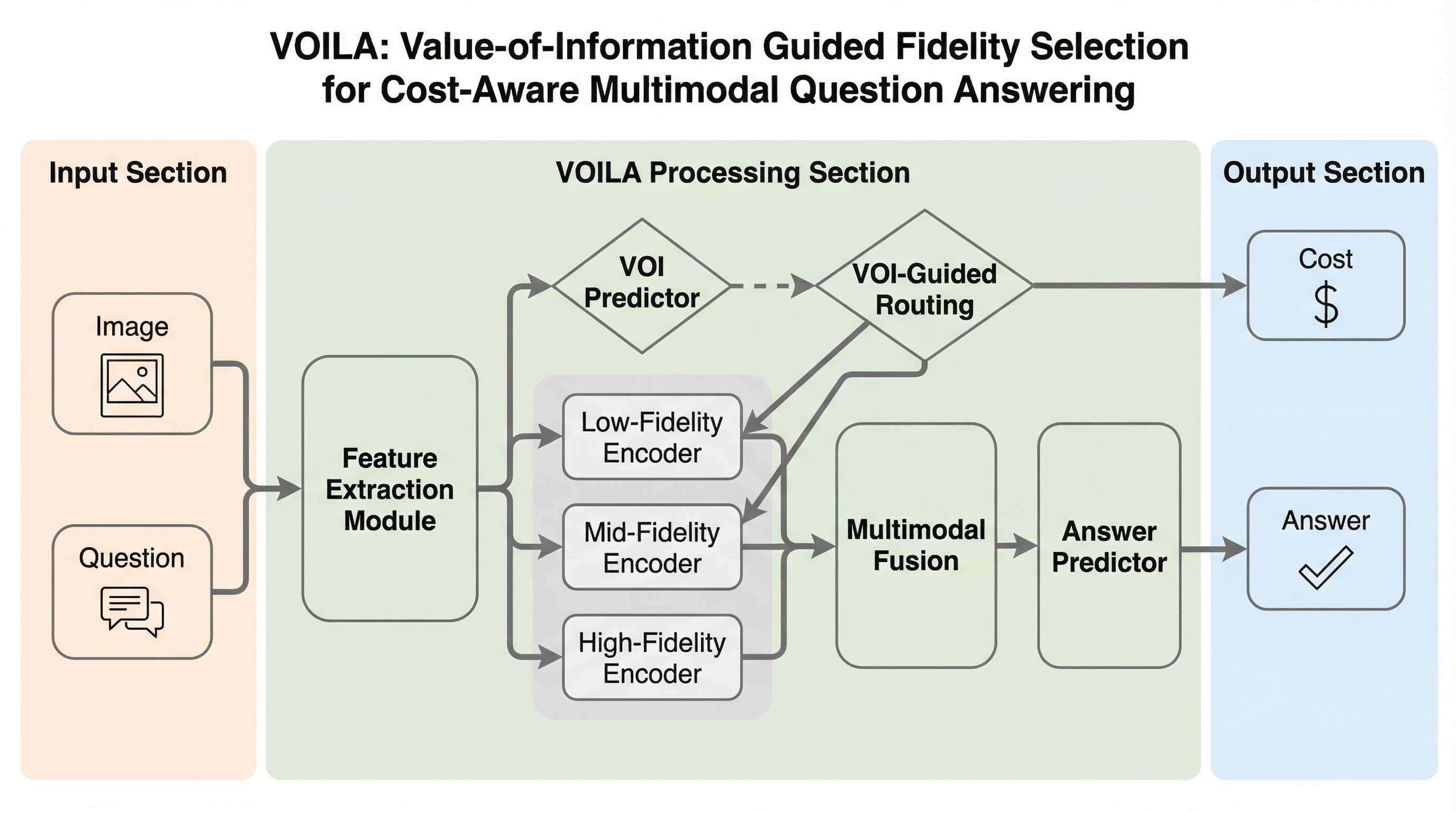
VOILAは、マルチモーダルな質問応答において、画像データを取得する前に最適な解像度(忠実度)を動的に選択する革新的なフレームワークである。質問文のテキスト特徴のみから各忠実度での正解確率を予測し、情報の取得コストと期待される精度のバランスを最大化する最小コストの忠実度を決定する。
TL;DR(結論)
VOILAは、マルチモーダルな質問応答において、画像データを取得する前に最適な解像度(忠実度)を動的に選択する革新的なフレームワークである。質問文のテキスト特徴のみから各忠実度での正解確率を予測し、情報の取得コストと期待される精度のバランスを最大化する最小コストの忠実度を決定する。5つの主要データセットと最大235Bパラメータのモデルを用いた広範な検証により、フル解像度と同等の精度を維持しつつ、通信や計算のコストを50〜60%削減できることを実証した。
なぜこの問題か
現代のマルチモーダル・ビジョン言語システムは、モデルの規模拡大と学習データの増大により、高度な視覚的推論能力を獲得している。しかし、この進化に伴い、データの保存、通信帯域、および計算リソースにかかるオーバーヘッドが極めて膨大なものとなっている。これまでの研究の多くは、軽量モデルと重量モデルを使い分ける「モデル選択」や「適応的ルーティング」に焦点を当ててきたが、これらは入力となる画像データが既に利用可能であることを前提としている。しかし、実際の運用環境では、この前提は必ずしも成り立たない。マルチモーダルな入力データは、多くの場合、取得遅延やコストが異なる不均一なストレージ階層に分散して保存されている。例えば、モバイルサービスでは低解像度のサムネイルがデバイス上のキャッシュにあり、フル解像度のオリジナル画像はクラウドストレージにある。また、エンタープライズシステムでは、頻繁にアクセスされるデータは高速なホットストレージ(AWS S3 Standardなど)に、アーカイブコンテンツは取得に数分から数時間を要するコールドストレージ(AWS Glacierなど)に保存される。…
核心:何を提案したのか
本論文では、事前取得段階での忠実度選択を「コストに敏感な情報取得問題」として定式化し、情報価値(Value-of-Information)に基づく適応的な忠実度選択フレームワーク「VOILA」を提案した。VOILAは、モデルの実行前に「どの表現のコンテキストを取得すべきか」を決定することに特化している。VOILAの核心は、質問文のテキスト特徴のみを利用して、特定の忠実度の入力が与えられた際にビジョン言語モデル(VLM)が正解を出せる確率を予測する点にある。この予測は、勾配ブースティング回帰(GBR)と等張回帰(Isotonic Regression)を組み合わせた2段階のパイプラインによって行われる。まず、GBRが質問の特徴から各忠実度における正解の可能性(生スコア)を推定し、次に等張回帰がこれらのスコアを信頼性の高い確率値へと校正する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related