一貫性深層平衡モデル
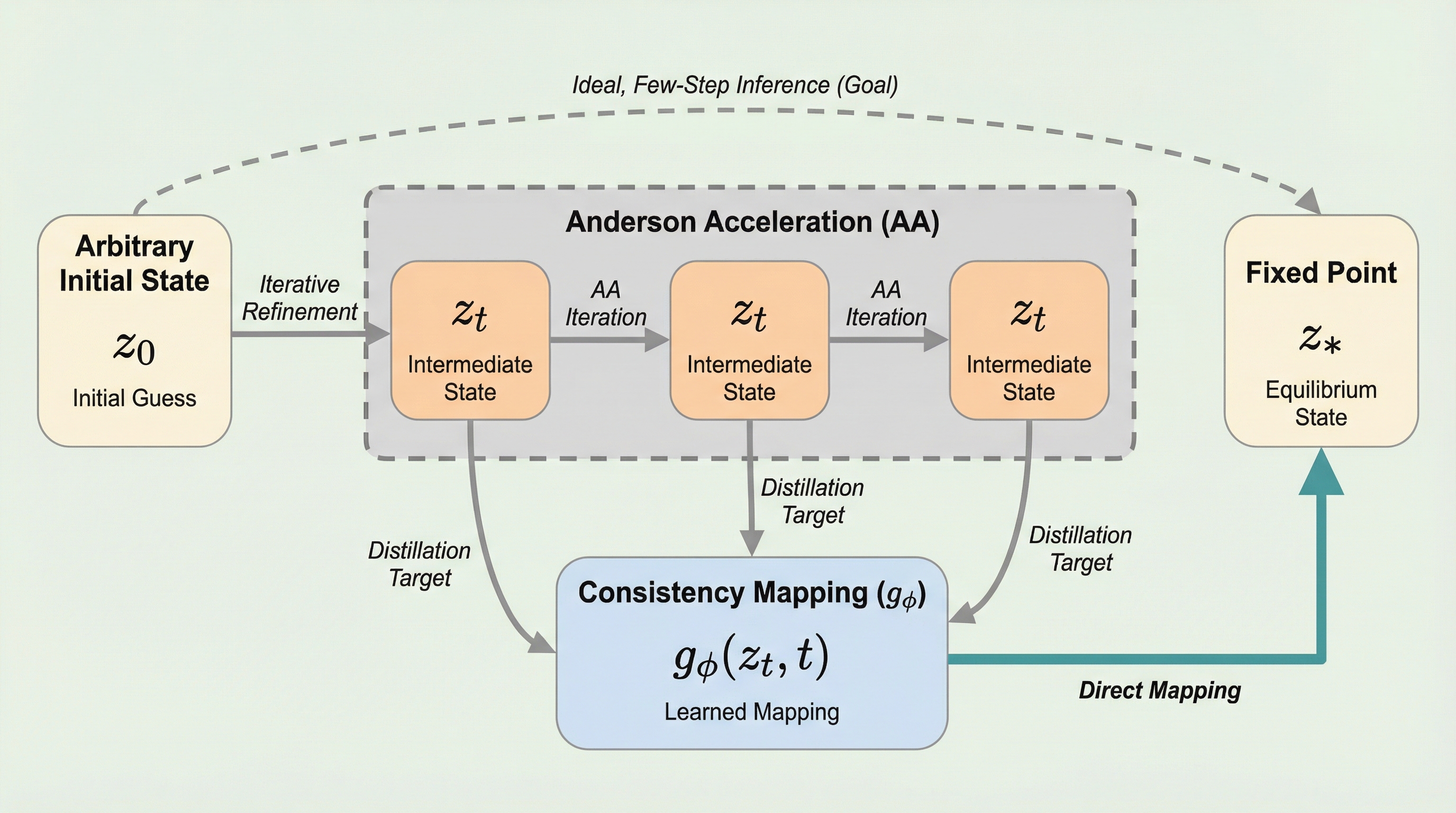
深層平衡モデル(DEQ)は、メモリ使用量を一定に保ちながら無限の深さをモデル化できる強力な手法ですが、不動点を求めるための反復計算により推論速度が遅いという課題がありました。本研究で提案された一貫性深層平衡モデル(C-DEQ)は、拡散モデルで成功を収めている一貫性蒸留の概念を導入し、中間状態から平衡状態へと直接マッピングすることで、わずか数ステップでの高速な推論を可能にします。画像分類や言語モデル、グラフ学習などの幅広いタスクにおいて、従来のDEQと比較して同じ計算予算で2倍から20倍の精度向上を達成し、暗黙的モデルと明示的モデルの間の推論速度の差を大幅に短縮することに成功しました。 C-DEQは、DEQの反復プロセスを特定の常微分方程式(ODE)の軌跡として再定義し、その軌跡上のどの点からでも一回のモデル評価で最終的な不動点へと到達できるように学習を行います。また、アンダーソン加速の構造的な事前知識をモデル設計に取り入れることで、従来のソルバーの挙動を洗練させ、単一ステップでの正確な予測と、複数ステップを繰り返した際の安定性を両立させることに成功しました。これにより、利用可能な計算リソースに応じて性能を自在に調整できる柔軟性を維持しつつ、これまでDEQが苦手としていた高速な応答が要求されるアプリケーションへの適用を現実的なものにします。
TL;DR(結論)
深層平衡モデル(DEQ)は、メモリ使用量を一定に保ちながら無限の深さをモデル化できる強力な手法ですが、不動点を求めるための反復計算により推論速度が遅いという課題がありました。本研究で提案された一貫性深層平衡モデル(C-DEQ)は、拡散モデルで成功を収めている一貫性蒸留の概念を導入し、中間状態から平衡状態へと直接マッピングすることで、わずか数ステップでの高速な推論を可能にします。画像分類や言語モデル、グラフ学習などの幅広いタスクにおいて、従来のDEQと比較して同じ計算予算で2倍から20倍の精度向上を達成し、暗黙的モデルと明示的モデルの間の推論速度の差を大幅に短縮することに成功しました。 C-DEQは、DEQの反復プロセスを特定の常微分方程式(ODE)の軌跡として再定義し、その軌跡上のどの点からでも一回のモデル評価で最終的な不動点へと到達できるように学習を行います。また、アンダーソン加速の構造的な事前知識をモデル設計に取り入れることで、従来のソルバーの挙動を洗練させ、単一ステップでの正確な予測と、複数ステップを繰り返した際の安定性を両立させることに成功しました。これにより、利用可能な計算リソースに応じて性能を自在に調整できる柔軟性を維持しつつ、これまでDEQが苦手としていた高速な応答が要求されるアプリケーションへの適用を現実的なものにします。
なぜこの問題か
深層学習における従来のネットワーク構造は、層を積み重ねることで深さを表現する明示的な設計が主流でしたが、深層平衡モデル(DEQ)はこの概念を根本から変えるパラダイムとして登場しました。DEQは、各層を個別に定義するのではなく、入力と隠れ状態の関係を不動点方程式として定義し、その平衡状態を直接解くことで無限の深さをシミュレートします。このアプローチの最大の利点は、学習時のメモリ消費量がモデルの深さに依存せず一定であるという点にあり、画像認識や自然言語処理、グラフ学習などの多様な分野で高い表現力を示してきました。しかし、理論的な優雅さや高い性能とは裏腹に、実用化における最大の障壁となっているのが推論時のレイテンシです。平衡状態に到達するためには、アンダーソン加速やブロイデン法といった反復的な数値解法を用いる必要があり、一回の推論で数十回のネットワーク評価を繰り返さなければなりません。 これまでの研究では、初期値の推定を工夫する手法や学習可能なソルバーを導入する試みが行われてきましたが、依然として局所的なステップごとの更新に留まっており、明示的な有限層ネットワークと比較して推論速度が著しく遅いという問題が解決されていませんでした。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related