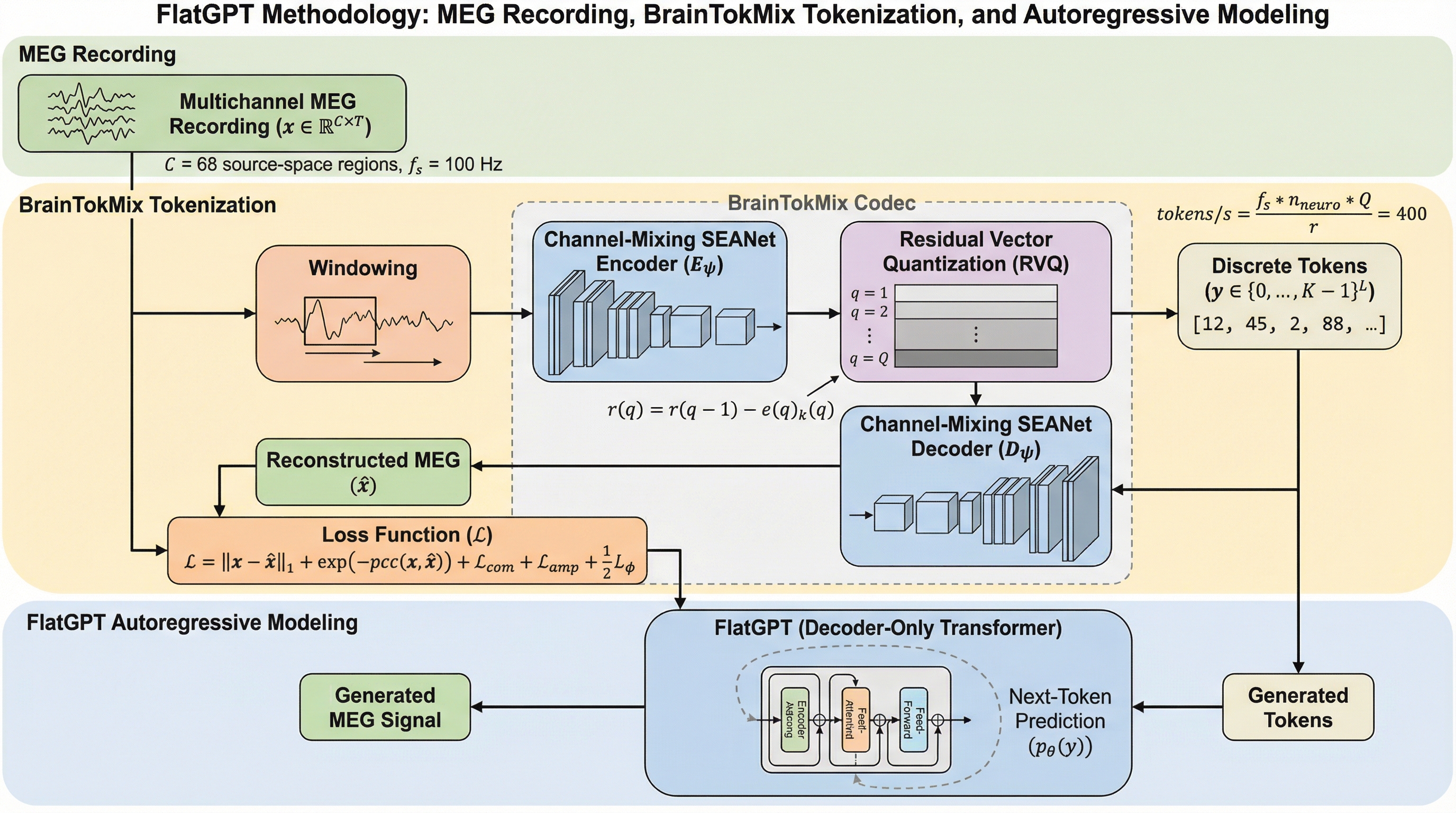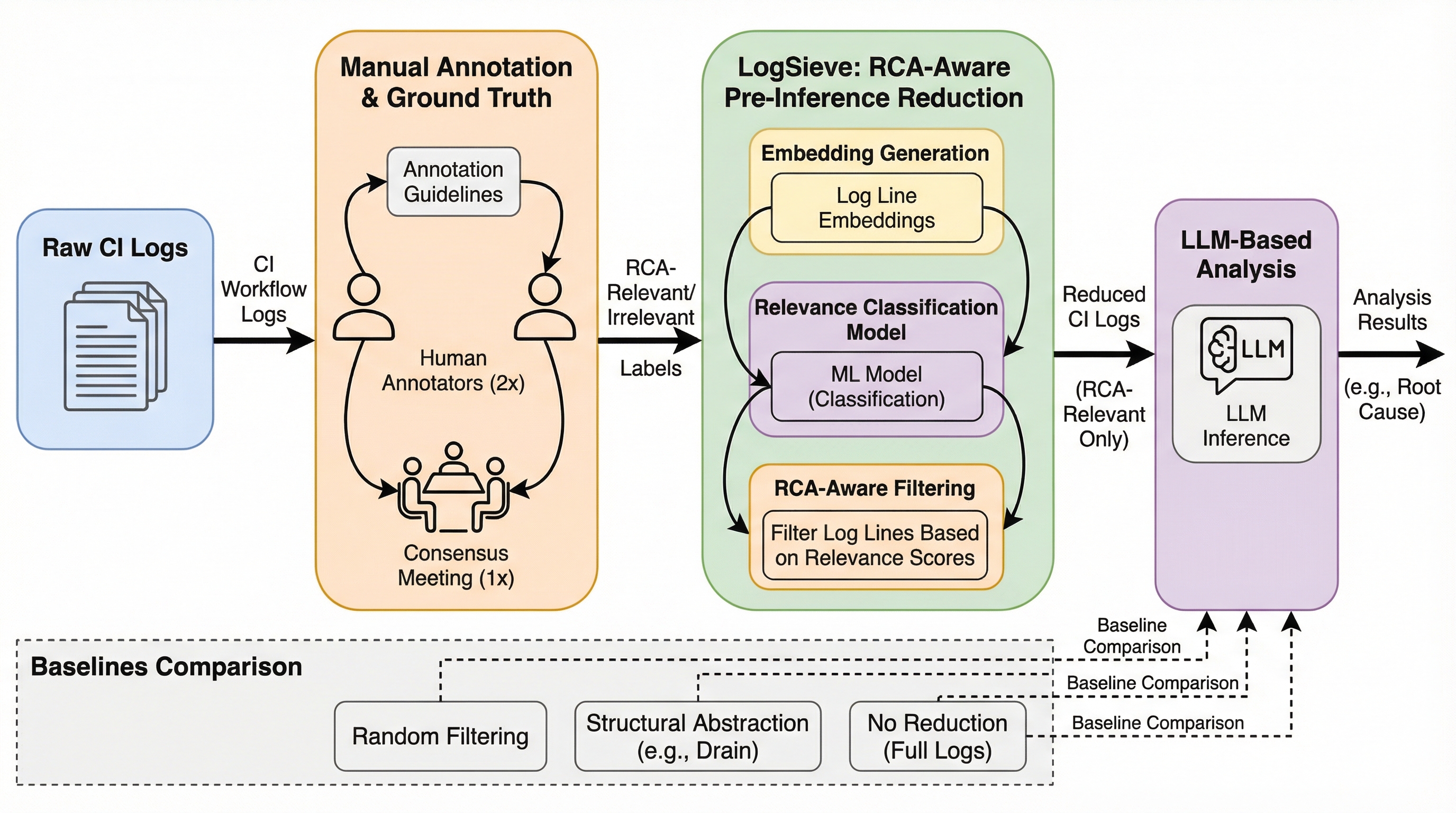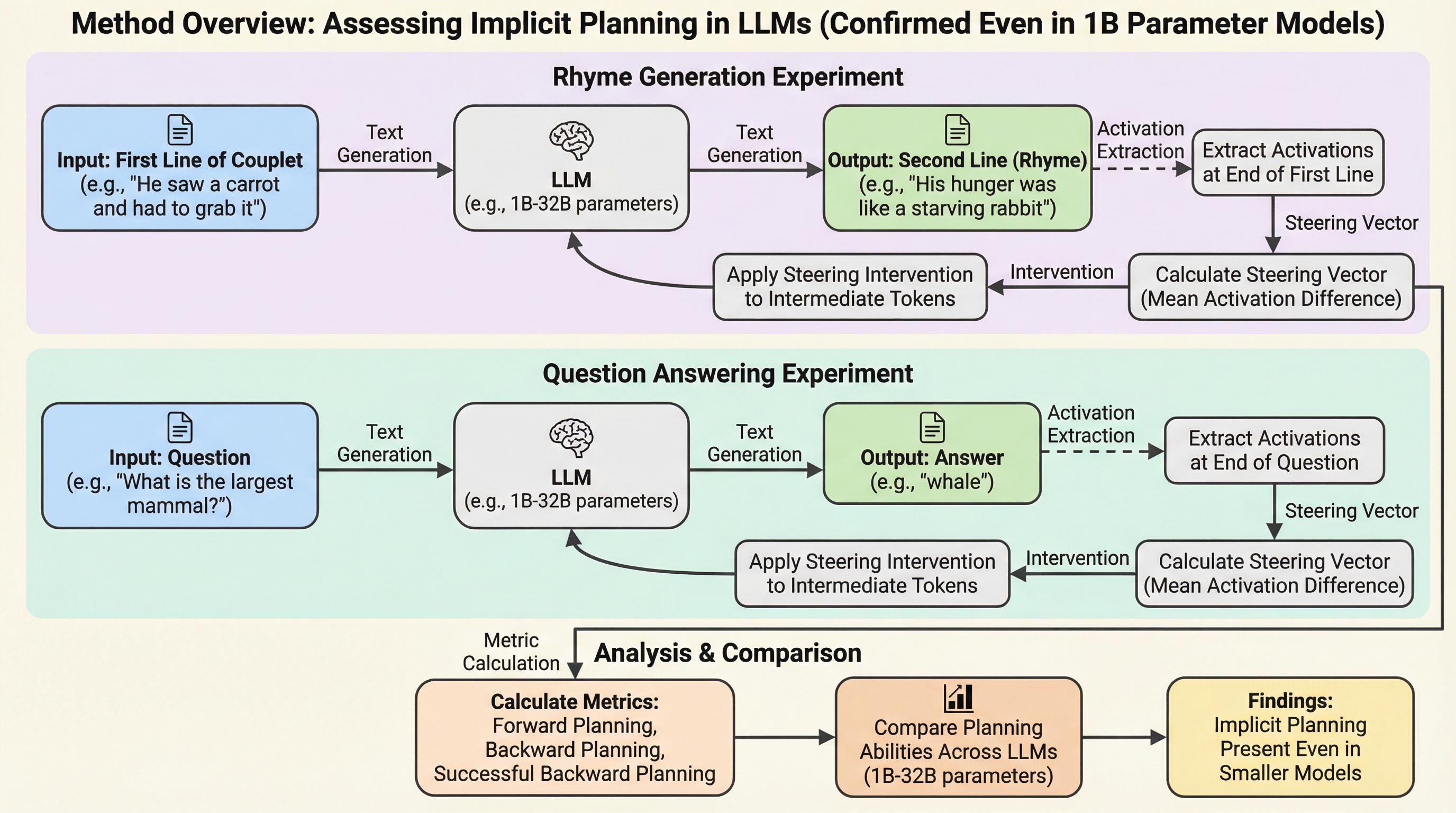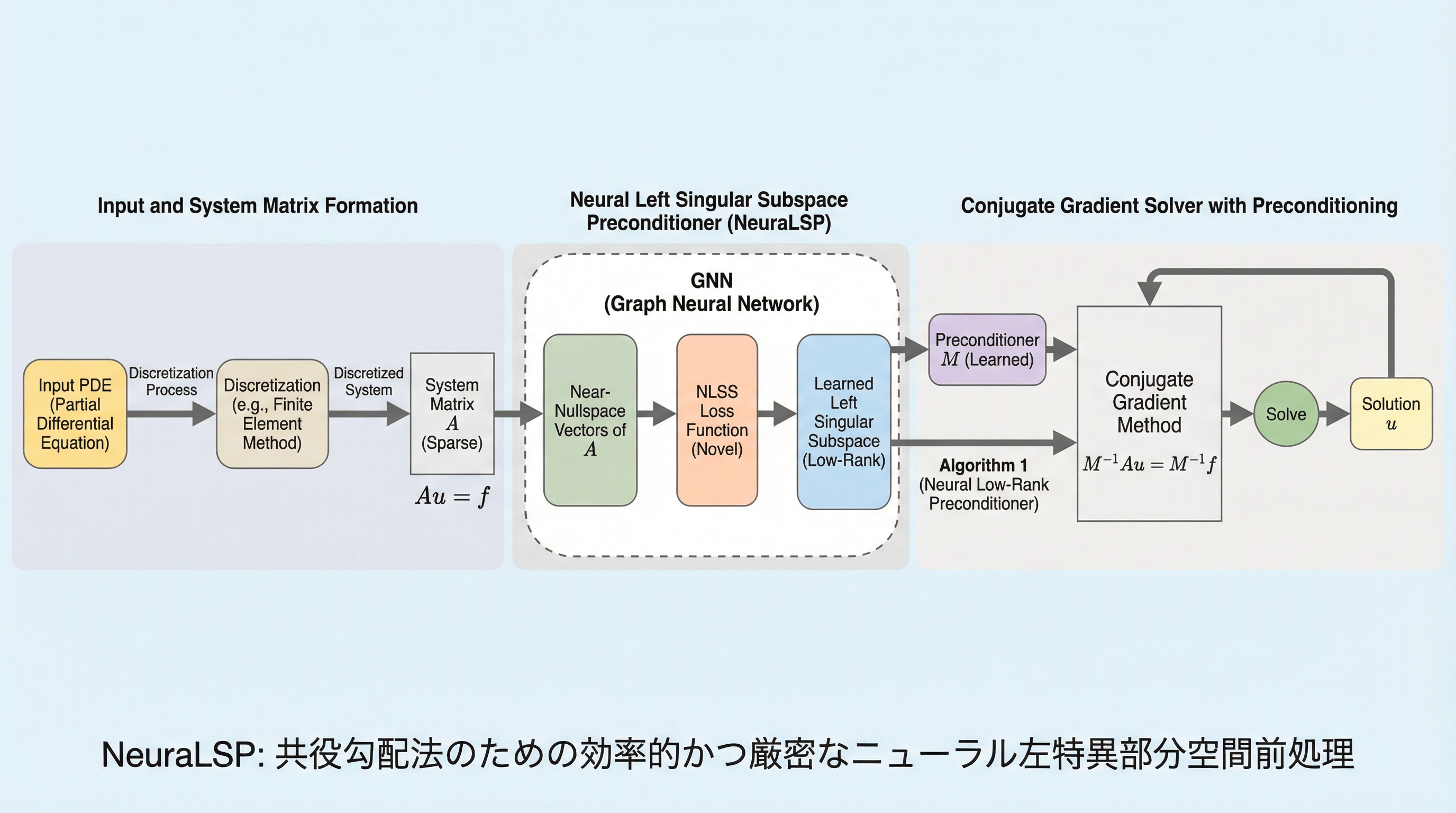
ヒートパイプ型マイクロ原子炉の技術経済的最適化 第2部:多目的最適化解析
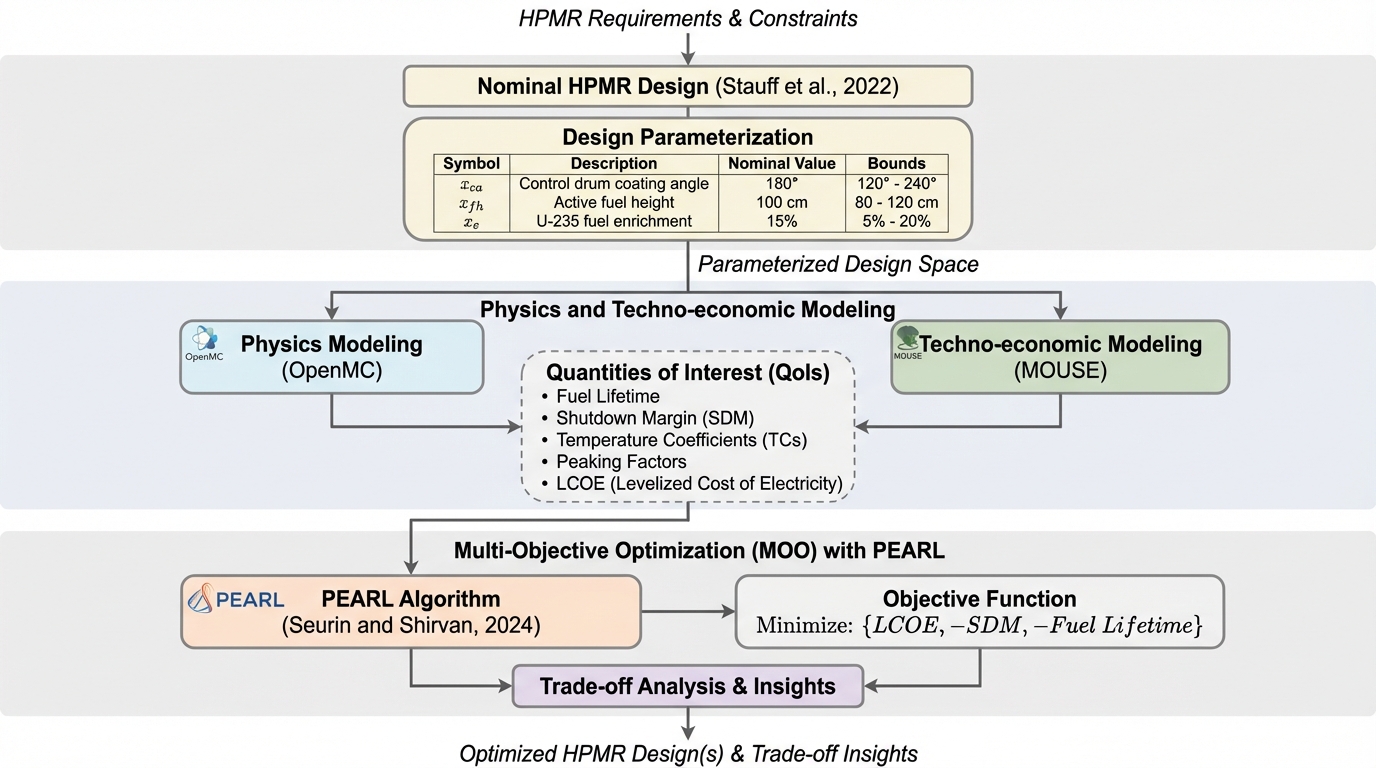
熱パイプ式マイクロリアクターでは、発電コストだけを下げようとすると、出力偏りや停止余裕のような安全・運用側の指標との衝突が起きやすいです。 / 本研究は、LCOEとロッド積分ピーキング係数を同時に最適化する多目的設計問題として捉え、PEARLを用いて複数のコスト前提ごとのPareto解を比較しています。 / 反射体コスト、制御ドラム依存、TRISO燃料、燃焼度の扱いが設計戦略を大きく左右し、安価な設計を探すだけでなく「どの安全余裕をどこまで買うか」を明示的に決める必要があると分かります。