MEGにおける次脳トークン予測のスケーリング
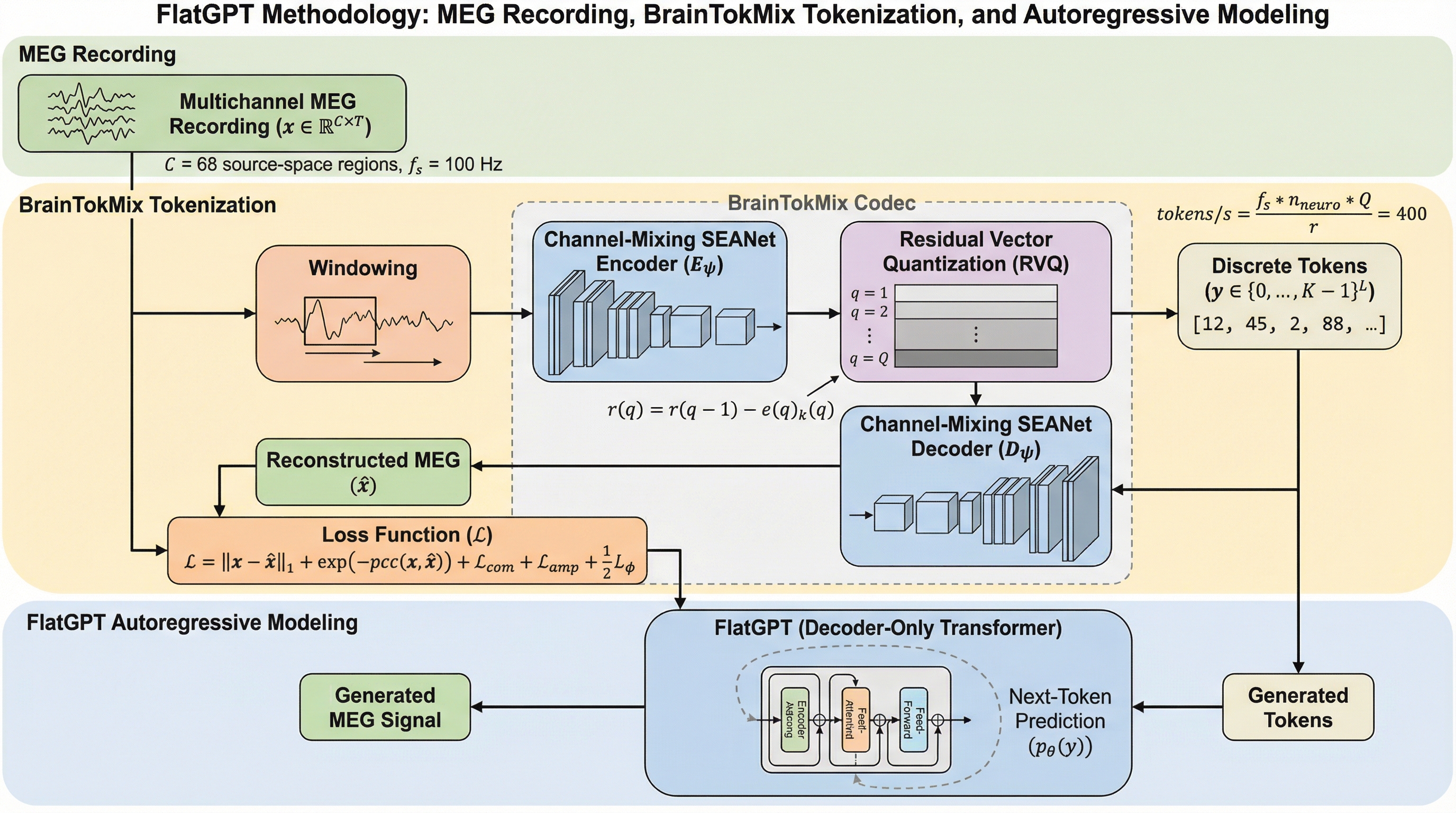
本研究は、500時間以上の大規模な脳磁図(MEG)データセットを用い、次トークン予測のパラダイムを脳信号に適用した大規模自己回帰モデル「FlatGPT」を提案しています。 多チャネルのMEG信号を「BrainTokMix」という独自のトークナイザーで離散的なトークン列に変換し、Qwen2.
TL;DR(結論)
本研究は、500時間以上の大規模な脳磁図(MEG)データセットを用い、次トークン予測のパラダイムを脳信号に適用した大規模自己回帰モデル「FlatGPT」を提案しています。 多チャネルのMEG信号を「BrainTokMix」という独自のトークナイザーで離散的なトークン列に変換し、Qwen2.5-VLをベースとしたモデルで数分間にわたる脳活動の生成と予測を可能にしました。 検証の結果、提案モデルは未知のデータセットに対しても安定した生成能力を示し、入力された文脈(プロンプト)に対して神経生理学的に妥当で特異性の高い脳活動を再現できることが確認されました。
なぜこの問題か
自然言語処理や画像生成の分野では、次の単語やパッチを予測する「次トークン予測」のスケーリングが大きな成功を収めていますが、これを脳信号の理解に応用する試みはまだ初期段階にあります。脳科学において、予測符号化や自由エネルギー原理は、知覚や認知を継続的な予測と修正のプロセスとして捉えており、機械学習における自己回帰モデルの考え方と密接な関連があります。脳信号、特に脳磁図(MEG)はミリ秒単位の高い時間分解能を持ち、知覚、認知、行動を媒介する内部ダイナミクスを直接的に観察できる特権的なデータです。しかし、MEGは多チャネルの連続値からなる時系列データであり、信号対雑音比(SNR)が低く、人間にとっての解釈性が乏しいため、生成モデルの構築と評価が極めて困難でした。 これまでの研究では、少数のセッションに限定されたモデルや、特定のタスクに依存した手法が主流であり、多様なスキャナーや被験者、タスクを横断して汎用的に機能するモデルは存在しませんでした。…
核心:何を提案したのか
本研究の核心は、多チャネルのMEG信号を効率的にトークン化し、大規模なデコーダー専用トランスフォーマーを用いて次トークン予測を行う「FlatGPT」というフレームワークの提案です。まず、MEGのソース空間における68領域の信号を扱うために、因果的なチャネル混合型トークナイザーである「BrainTokMix」を開発しました。これは、先行研究のBrainOmniを改良したもので、SEANetスタイルのエンコーダー・デコーダー構造を採用し、空間的および時間的な圧縮を同時に行います。このトークナイザーにより、高帯域な連続信号が、1秒あたり400トークンという管理可能な速度の離散トークン列へと変換されます。 次に、このトークン列を用いて、Qwen2.5-VLのアーキテクチャをベースとしたトランスフォーマーモデルをゼロから訓練しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related