大規模言語モデルにおいて回答すべきでない時を学ぶ知的謙虚さに報酬を与える
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーションを抑制するため、正解には正の報酬、不正解には負の報酬、そして「分からない」という棄権回答には特定の報酬($r_{abs}$)を与える「検証可能な報酬による強化学習(RLVR)」という枠組みを導入し、モデルに知的謙虚さを学習させた。
TL;DR(結論)
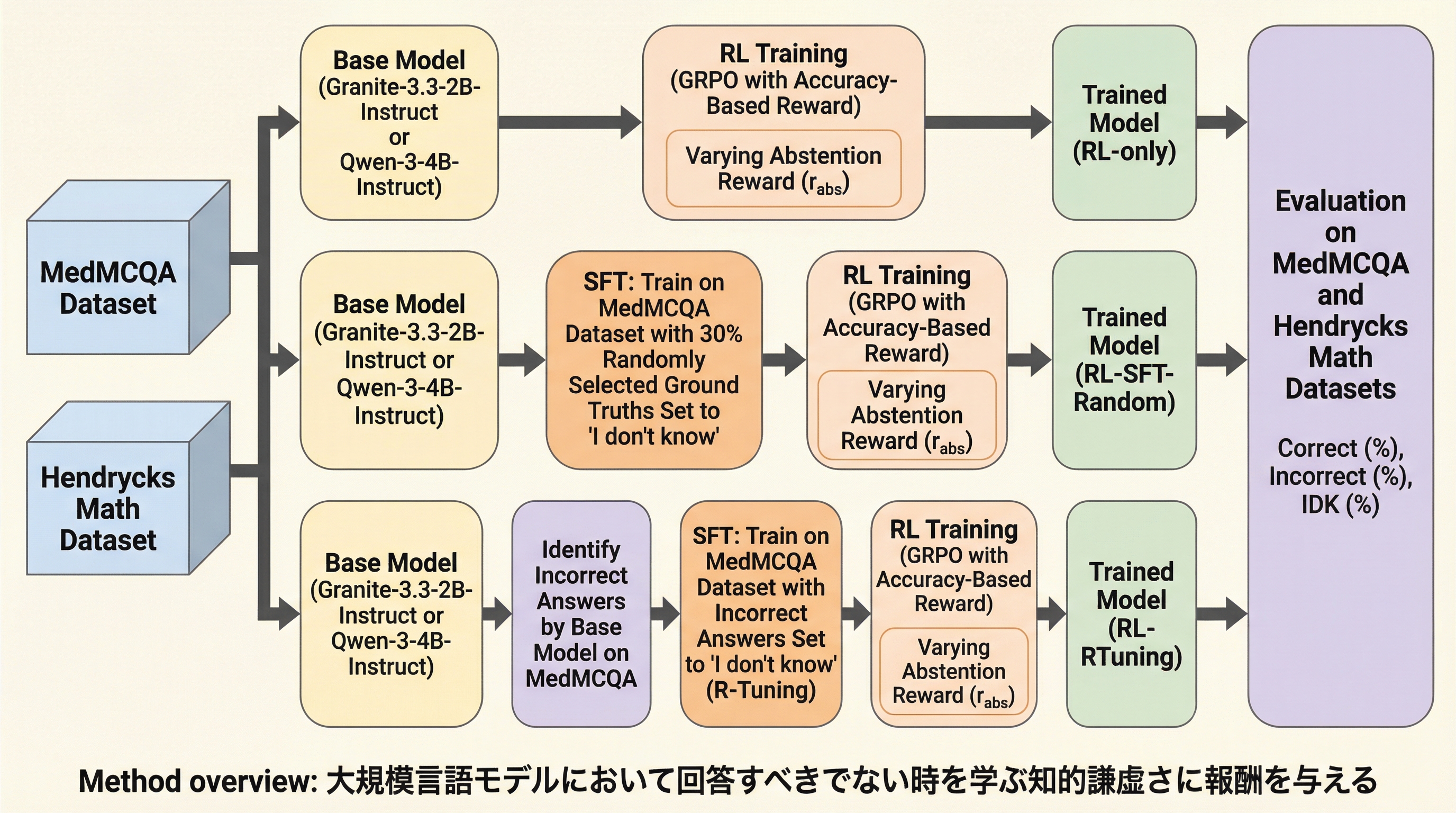
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーションを抑制するため、正解には正の報酬、不正解には負の報酬、そして「分からない」という棄権回答には特定の報酬($r_{abs}$)を与える「検証可能な報酬による強化学習(RLVR)」という枠組みを導入し、モデルに知的謙虚さを学習させた。 Granite-3.3-2B-InstructとQwen-3-4B-Instructを用いた実験の結果、棄権報酬を-0.25から0.3の適切な範囲に設定することで、正解率を大幅に低下させることなく不正解(ハルシネーション)を効果的に削減できることが示され、特に大規模なモデルほど棄権のインセンティブに対して頑健であることが確認された。 選択肢形式のMedMCQAや記述式のHendrycks Mathデータセットにおいて、強化学習単体では棄権を躊躇する傾向があるが、事前に「分からない」と答えるように教師あり微調整(SFT)を組み合わせることで、モデルの不確実性を適切に処理し、信頼性の高い回答を生成できることが明らかになった。
なぜこの問題か
大規模言語モデル(LLM)は、専門的な業務や研究の領域において広く普及しているが、事実として誤っている情報や検証不可能な内容を自信満々に生成してしまうハルシネーションという問題に依然として直面している。この問題が発生する一因として、現在のLLMの学習目的が常に何らかの回答を生成することに報酬を与えており、不確実な場合に回答を控える(棄権する)ことを明示的に学習していない点が挙げられる。既存のハルシネーション抑制手法として、教師あり微調整(SFT)や人間によるフィードバックを用いた強化学習(RLHF)が存在するが、これらはコストが高く、人間が介在するフィードバックループに大きく依存している。 本研究では、モデルが自身の知識の限界を認識し、不確実なときには「分かりません(I don't know)」と答える「知的謙虚さ」を身につけることが、信頼性の高いAIを構築するために不可欠であると考えている。特に医療分野(MedMCQA)や高度な数学問題(Hendrycks Math)のような、正確性が極めて重要視されるドメインにおいては、誤った情報を提示するよりも、分からないことを認める能力が重要となる。…
核心:何を提案したのか
本研究の核心は、検証可能な報酬による強化学習(RLVR)を拡張し、正解(Correct)、不正解(Incorrect)、そして棄権(Abstention)の3つの状態に対して報酬を割り当てる「三値報酬構造(Ternary Reward Structure)」を提案したことにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related