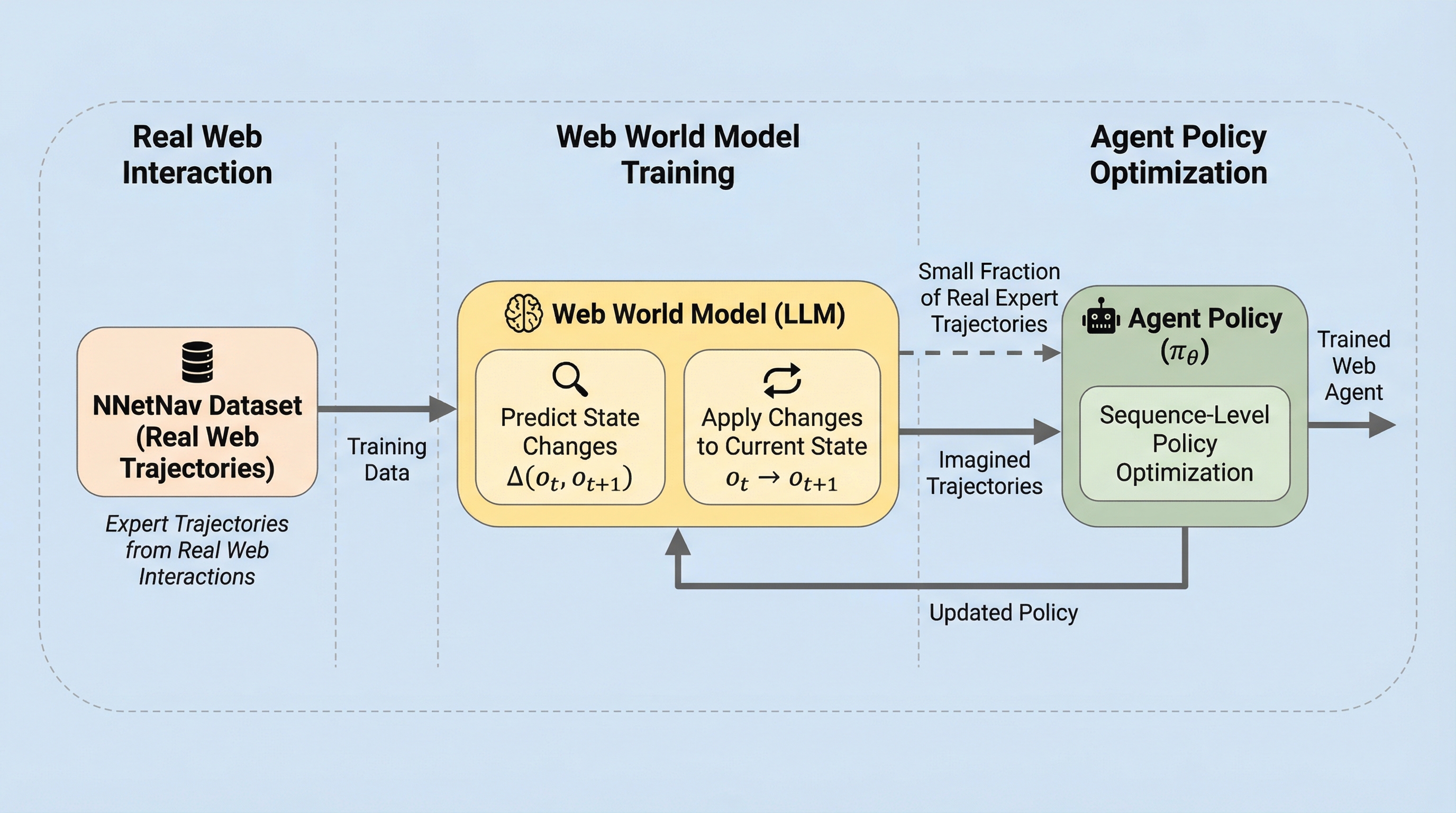
DynaWeb: ウェブエージェントのためのモデルベース強化学習フレームワーク
従来のウェブエージェントの強化学習は、実際のインターネット上での試行錯誤を必要としていましたが、これには高額なコストや予期せぬ購入といったリスク、そして動作の非効率性という大きな課題がありました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のウェブエージェントの強化学習は、実際のインターネット上での試行錯誤を必要としていましたが、これには高額なコストや予期せぬ購入といったリスク、そして動作の非効率性という大きな課題がありました。
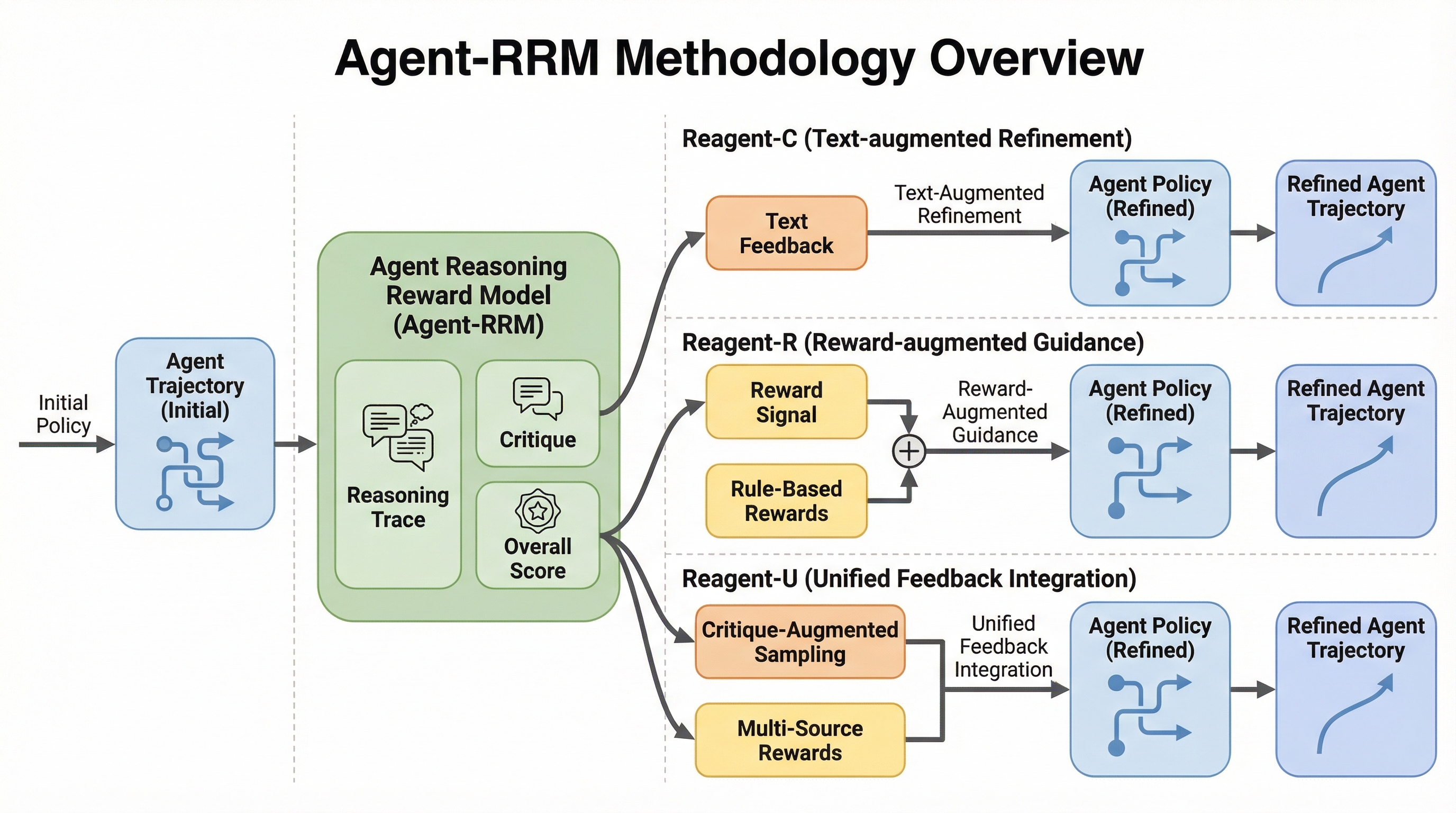
従来のエージェント学習が最終結果の正誤のみに依存する稀薄な報酬に頼っていたのに対し、本研究は推論の過程を詳細に評価する「Agent-RRM」を提案しました。 このモデルは、推論の論理性を分析するトレース、具体的な欠陥を指摘する批判、全体的な品質スコアという3つの構造化されたフィードバックを生成し、エージェントに多角的な学習信号を提供します。 12種類のベンチマークを用いた検証の結果、提案手法の「Reagent-U」はGAIAで43.7%、WebWalkerQAで46.2%という高い性能を達成し、複雑なタスクにおける推論報酬モデルの有効性が証明されました。
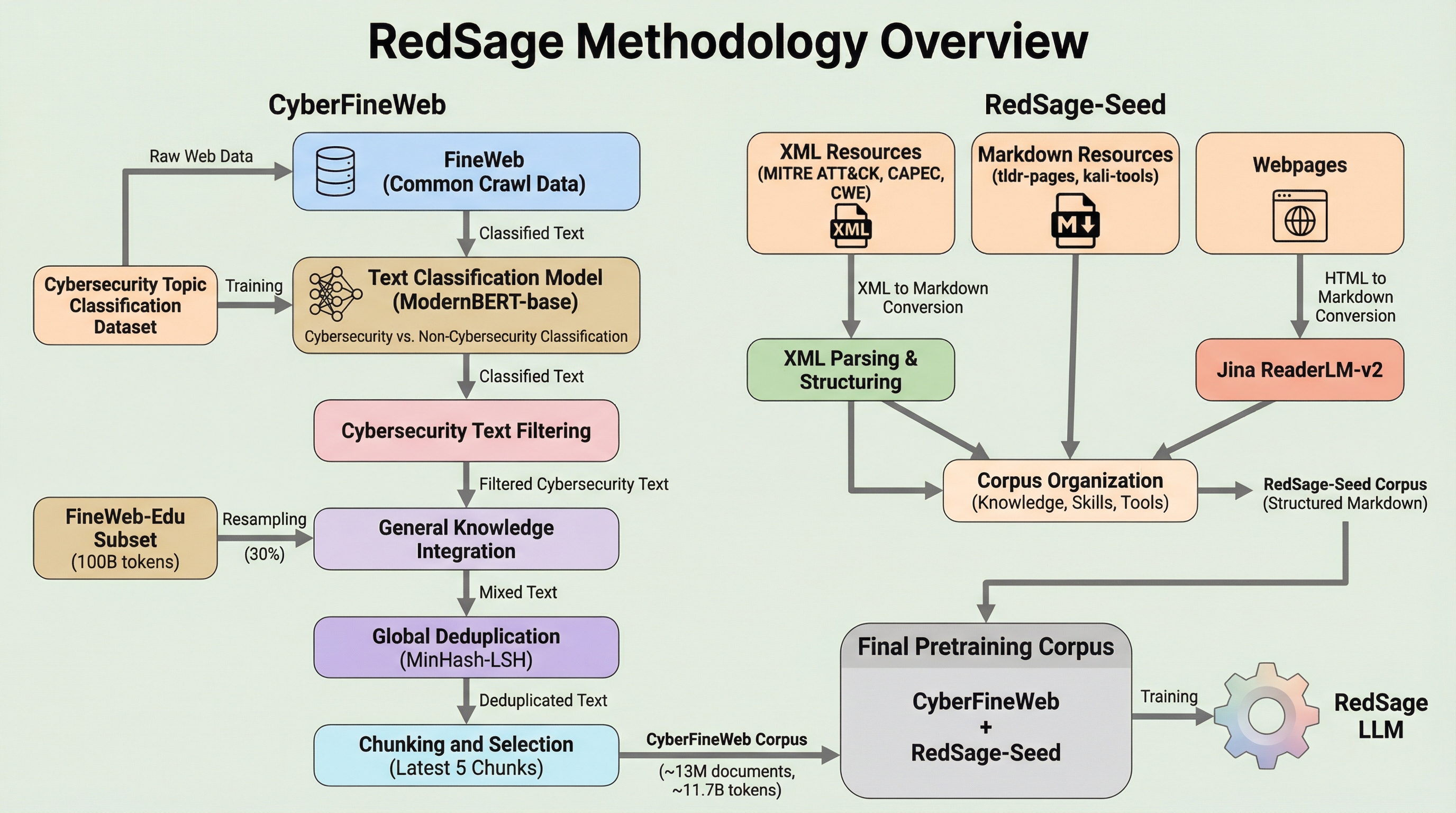
RedSageは、11.8Bトークンの専門データを用いた継続事前学習と、エージェントによる266K件の高品質な対話データ拡充を組み合わせ、サイバーセキュリティ領域に特化したオープンソースの8Bパラメータモデルである。
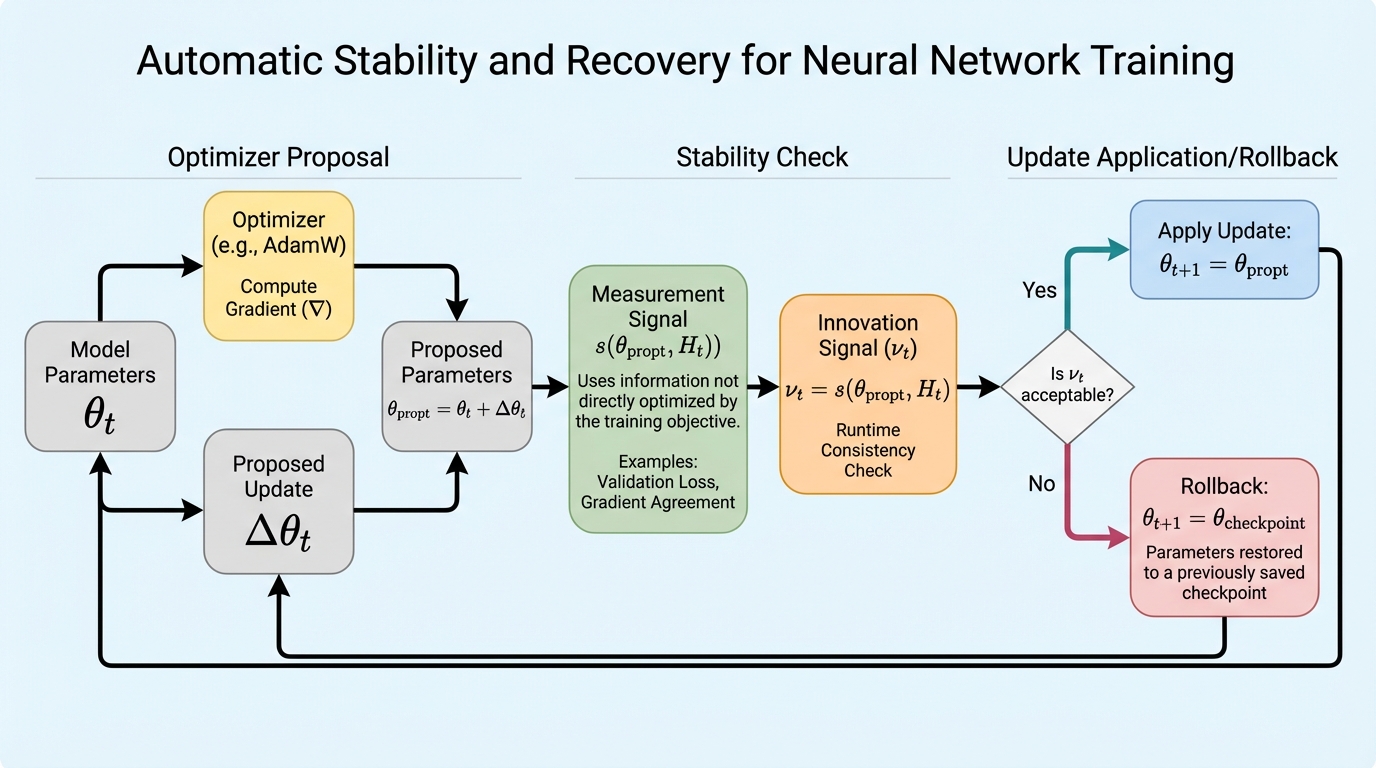
現代のニューラルネットワーク学習は非常に脆弱であり、稀に発生する深刻な不安定な更新が、回復不能な発散や静かな性能低下を引き起こすことが大きな課題となっている。既存の最適化手法は主にオプティマイザ内部に組み込まれた予防的なメカニズムに依存しており、一度不安定性が生じるとそれを検知して回復する能力が限られているため、計算資源の浪費や実験結果の不確実性を招く要因となっている。 本研究では、最適化を制御された確率過程として扱う監視型の実行時安定性フレームワークを提案し、バリデーションプローブなどの二次的な計測信号から導出される「イノベーション信号」を分離して利用することで、基底となるオプティマイザを変更することなく不安定な更新の自動検知と回復を可能にした。このフレームワークは、提案された更新が安定した学習動態と一致するかを評価し、異常が検知された場合には更新を拒否して以前の正常な状態へとロールバックする。 理論的には、有界な劣化と回復を定式化した実行時の安全保証を提供し、ResNet-18やTransformerを用いた実験において、標準的なパイプラインが失敗するような壊滅的な更新からも迅速に回復し、学習の発散を抑制して堅牢性を向上させることを実証した。この実装はメモリ制約のある環境にも対応しており、計算オーバーヘッドを最小限に抑えつつ、既存の多様なオプティマイザと組み合わせて使用できる実用的な制御レイヤーとして機能する。
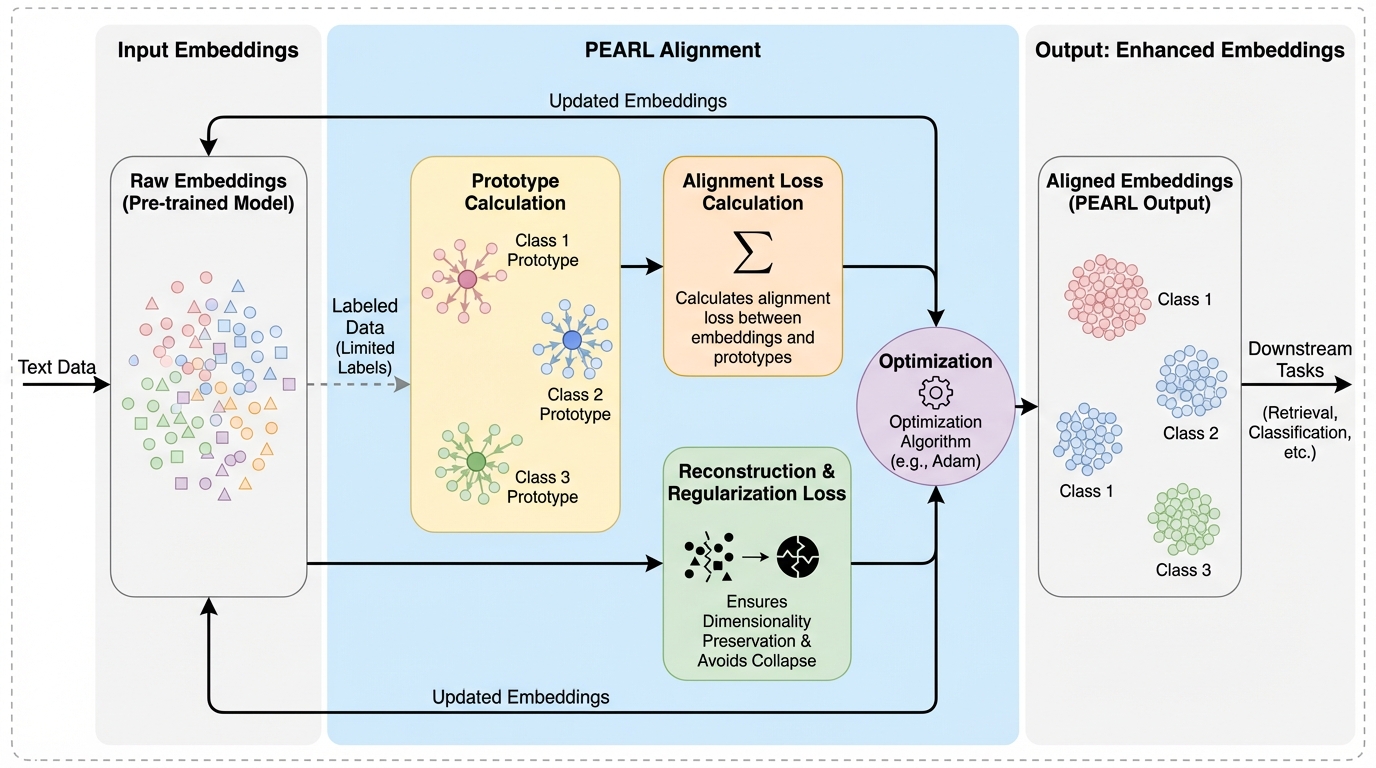
デジタルガバナンス等の実運用システムでは、固定された埋め込み表現の近傍構造が不正確で誤った事例を検索してしまう課題があるが、本研究が提案するPEARLは、限られたラベル情報を用いて埋め込みをクラスプロトタイプに軟らかく整列させることで、次元数を維持したまま近傍の幾何学的構造を劇的に改善する。
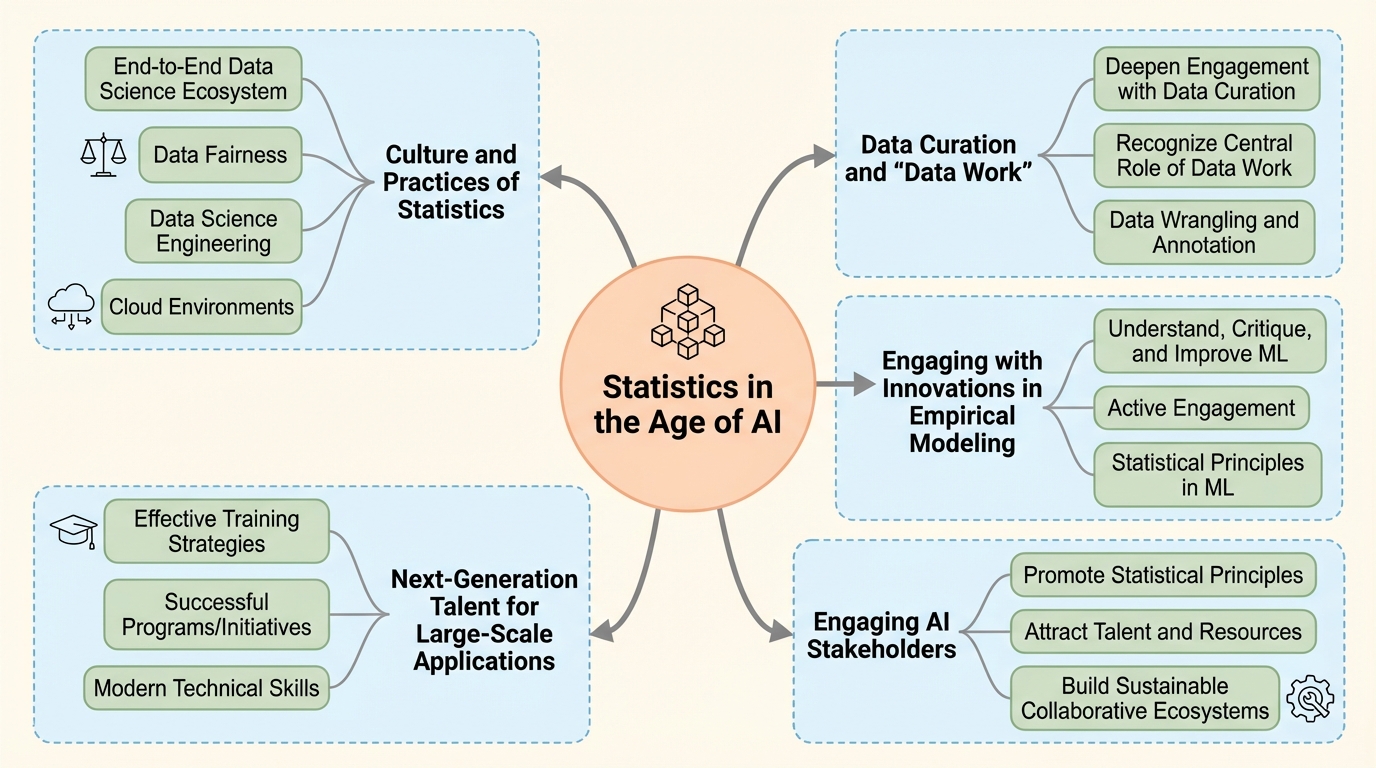
2024年の合同統計会議(JSM)で開催された討論会では、AIや大規模言語モデルの急速な進展に対応するため、統計学を「エンドツーエンドのデータサイエンス・エコシステム」として再定義する必要性が提言されました。
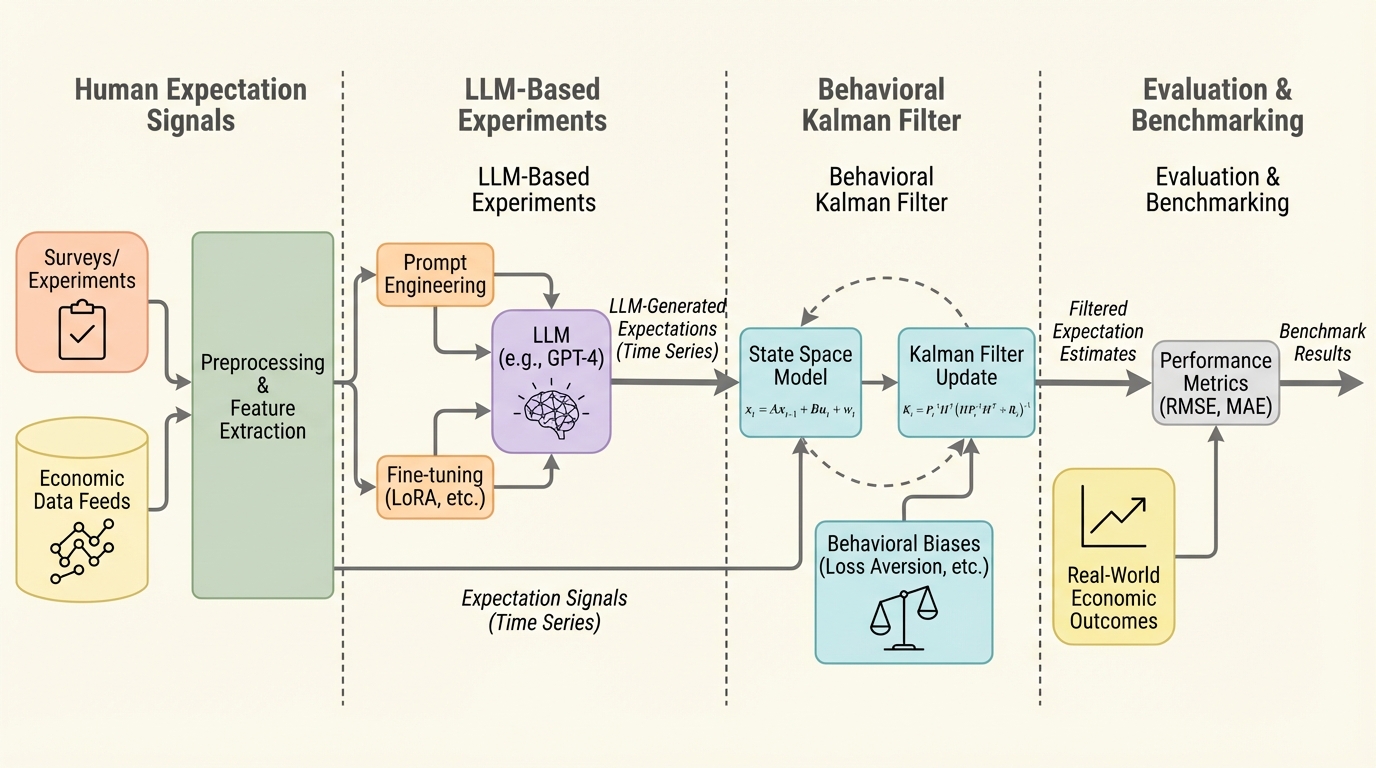
大規模言語モデル(LLM)を家計や企業の最高経営責任者(CEO)といった経済主体として扱い、個人の所得変化(ミクロ信号)と国全体の経済成長(マクロ信号)をどのように統合して将来予測を行うかを、新たに提案した「行動カルマンフィルター(BKF)」を用いて定量化した。
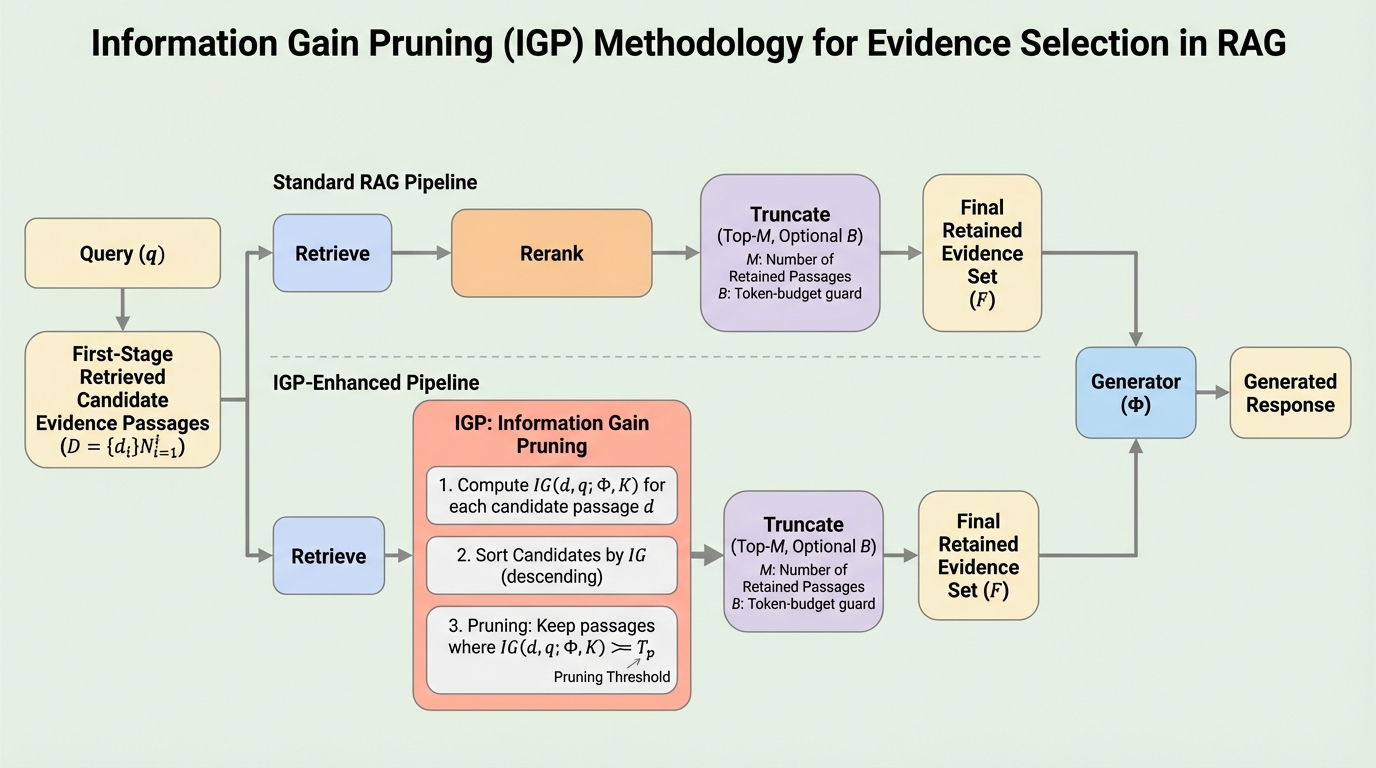
RAG(検索拡張生成)において、検索の関連性指標と最終的な回答精度が必ずしも一致せず、複数の証拠を注入すると冗長性や矛盾によって生成が不安定になるという「関連性と実用性のミスマッチ」を解消するため、生成モデルの不確実性の減少量を基準に証拠を選択する手法「Information Gain Pruning (IGP)」を提案しました。 / IGPは、追加の学習やラベルを必要とせず、生成モデルが出力するトークンの確率分布(ロジット)のみを用いて、回答の安定性に寄与する「情報利得」が高い証拠を特定し、生成を混乱させる低利得な情報をコンテキスト予算に到達する前に排除することで、限られたリソース内での最適な証拠選択を実現します。 / 5つのオープンドメイン質問回答ベンチマークを用いた検証において、IGPは従来手法と比較して回答精度(F1スコア)を約12〜20%向上させると同時に、生成モデルへの入力トークン数を約76〜79%削減するという、精度向上とコスト削減を同時に達成する極めて優れたパフォーマンスを実証しました。
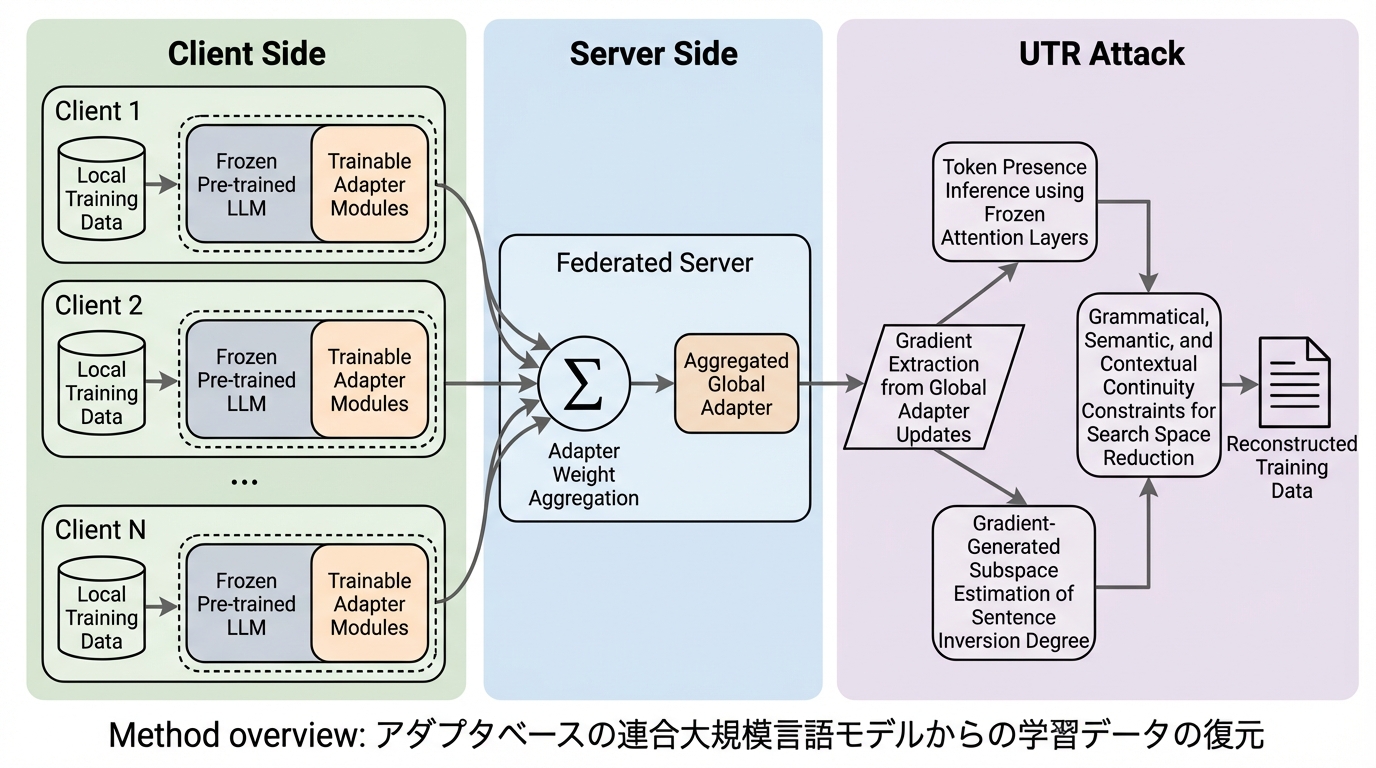
アダプタベースの連合大規模言語モデル(FedLLM)は、計算資源の節約とプライバシー保護を両立する手法として広く採用されていますが、本研究は「UTR」という新しい攻撃手法を用いることで、凍結されたモデル背後にある秘密の学習データを極めて高い精度で復元できることを明らかにしました。
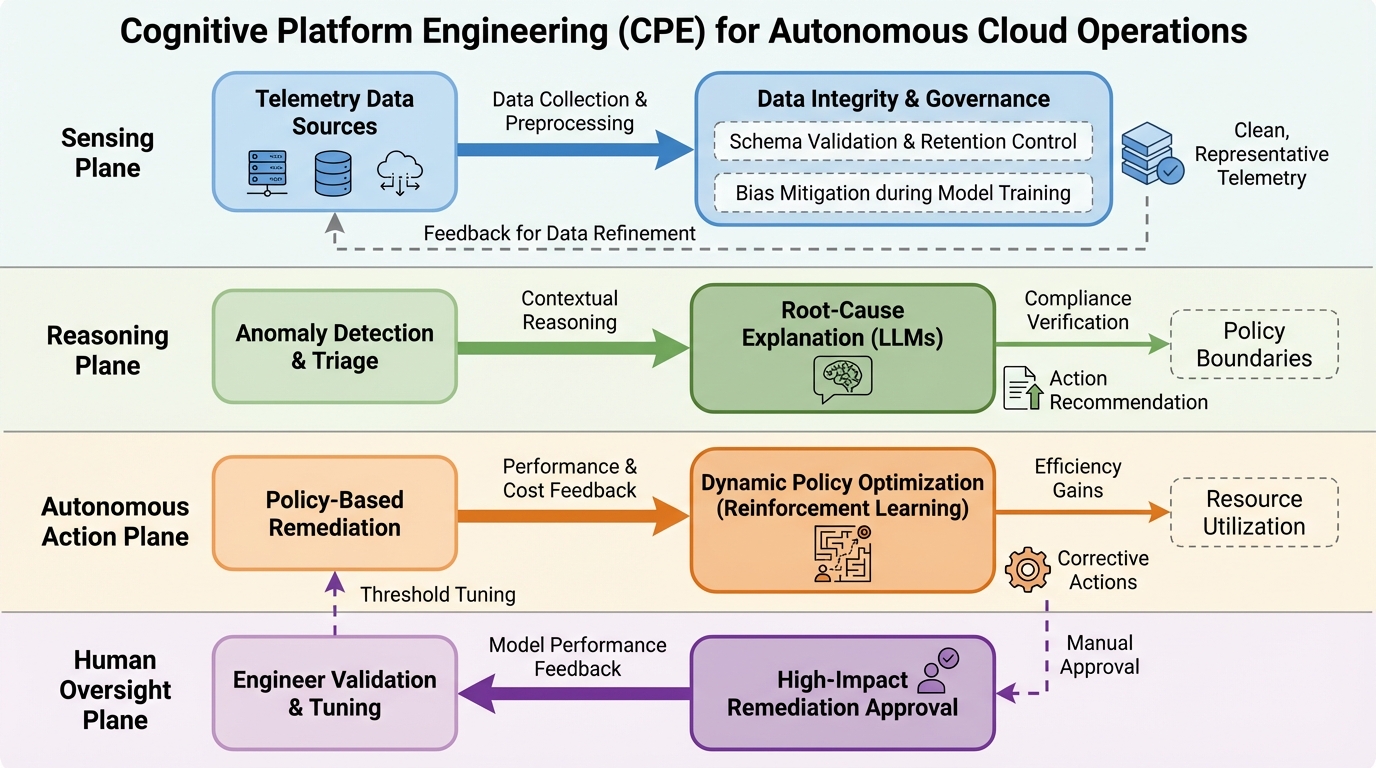
現代の複雑なクラウドネイティブ環境において、従来のDevOpsによる静的な自動化の限界を打破するため、感知・推論・行動を統合した「コグニティブ・プラットフォーム・エンジニアリング(CPE)」が提案されました。