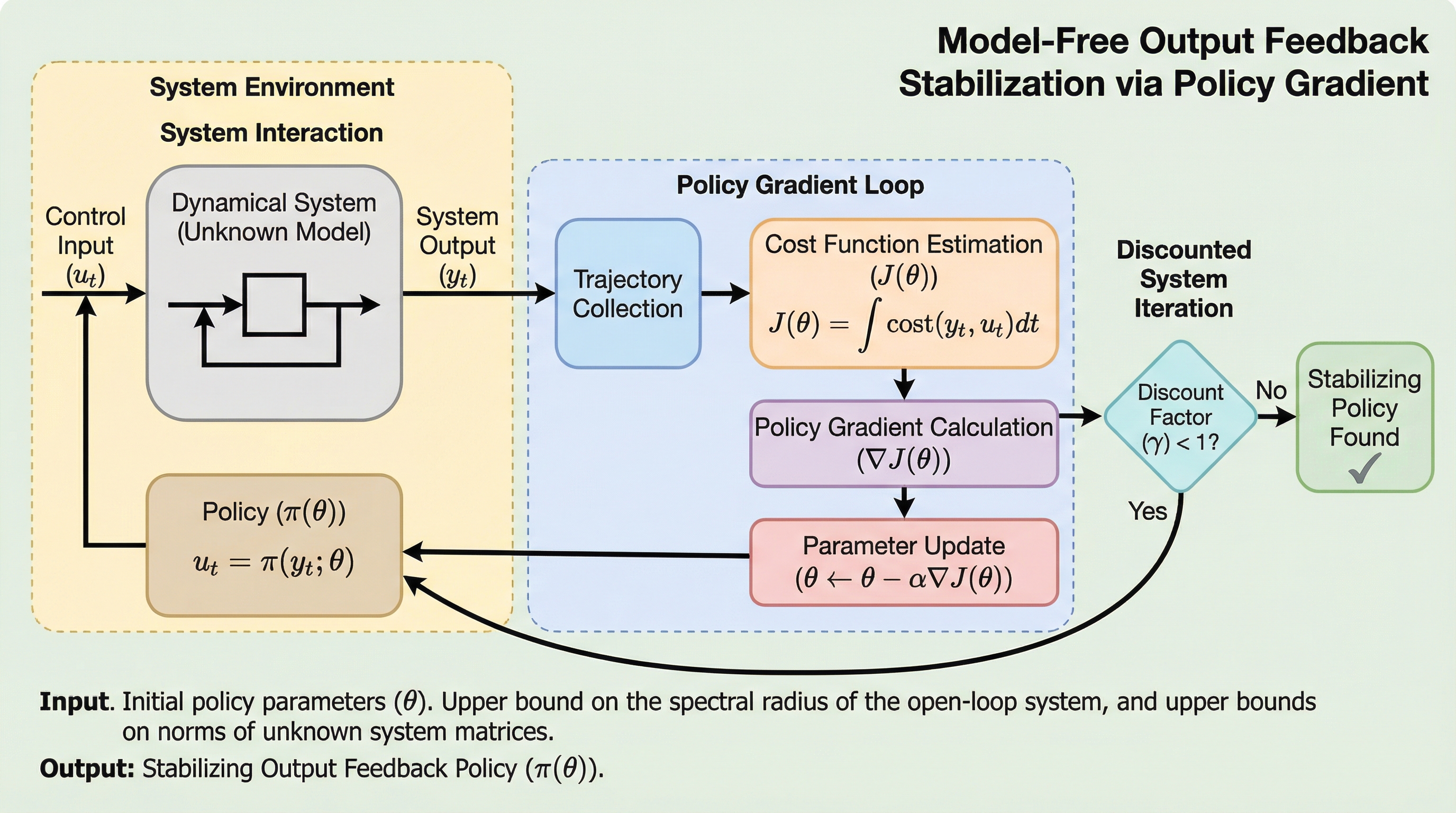
方策勾配法によるモデルフリー出力フィードバック安定化
本研究は、システムモデルが未知で一部の出力しか観測できない離散時間線形システムにおいて、方策勾配法を用いてシステムを安定化させる静的出力フィードバック制御器を直接学習する新しいアルゴリズム枠組みを提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、システムモデルが未知で一部の出力しか観測できない離散時間線形システムにおいて、方策勾配法を用いてシステムを安定化させる静的出力フィードバック制御器を直接学習する新しいアルゴリズム枠組みを提案しました。
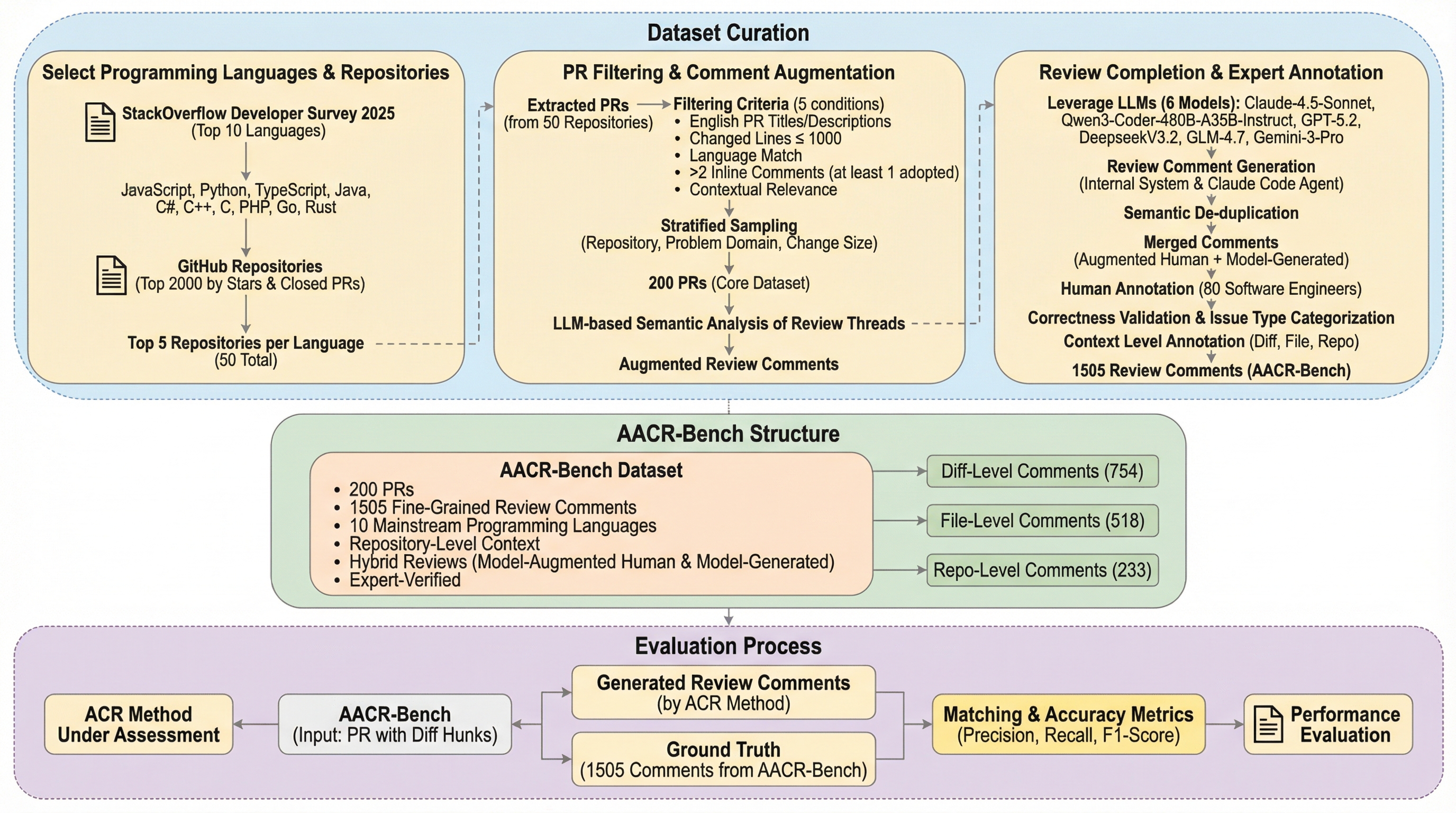
従来の自動コードレビュー(ACR)の評価は、GitHubの生のプルリクエストデータに依存していたため、正解データの網羅性が低く、特定の言語に偏っているという課題がありました。本研究が提案する「AACR-Bench」は、10種類の主要言語と50のリポジトリを対象とし、80名の熟練エンジニアと最新AIモデルを組み合わせた検証パイプラインにより、問題の網羅率を従来比で285%向上させた画期的なベンチマークです。検証の結果、リポジトリレベルの文脈提供やエージェント構成の採用がモデルの性能に与える影響は、使用する言語やモデルの特性によって大きく異なることが明らかになり、今後の自動レビュー技術開発における重要な指針を提示しました。
ウルドゥー語における大規模言語モデルの複雑な推論能力を厳密に評価するため、複数の翻訳システムと人間による検証を組み合わせた高品質なベンチマーク「UrduBench」が構築されました。算術、記号数学、常識、科学的知識を網羅する4つの主要な英語データセットを、文脈の整合性を維持しながらウルドゥー語へ移植することで、従来の機械翻訳手法で課題となっていた意味の断片化や論理的矛盾を解消しています。 評価の結果、思考の連鎖(Chain-of-Thought)プロンプトの導入と言語的一貫性の維持が推論の成功に不可欠であることが示され、モデルの規模以上に多言語学習の質や命令チューニングの精度が重要であることが明らかになりました。本研究は、低リソース言語における標準的な評価手法を提示するだけでなく、他の言語にも応用可能な高品質なデータセット構築のガイドラインを提供しています。 算術推論を測定するMGSM、記号数学を扱うMATH-500、常識的な推論を評価するCommonSenseQA、そして事実知識に基づく科学的推論を問うOpenBookQAという、世界的に広く利用されている4つの英語データセットをウルドゥー語に移植しました。これにより、低リソース言語の評価において最大の障壁となっていた翻訳エラーによるノイズを最小限に抑え、モデルが持つ純粋な推論能力を抽出することが可能になりました。
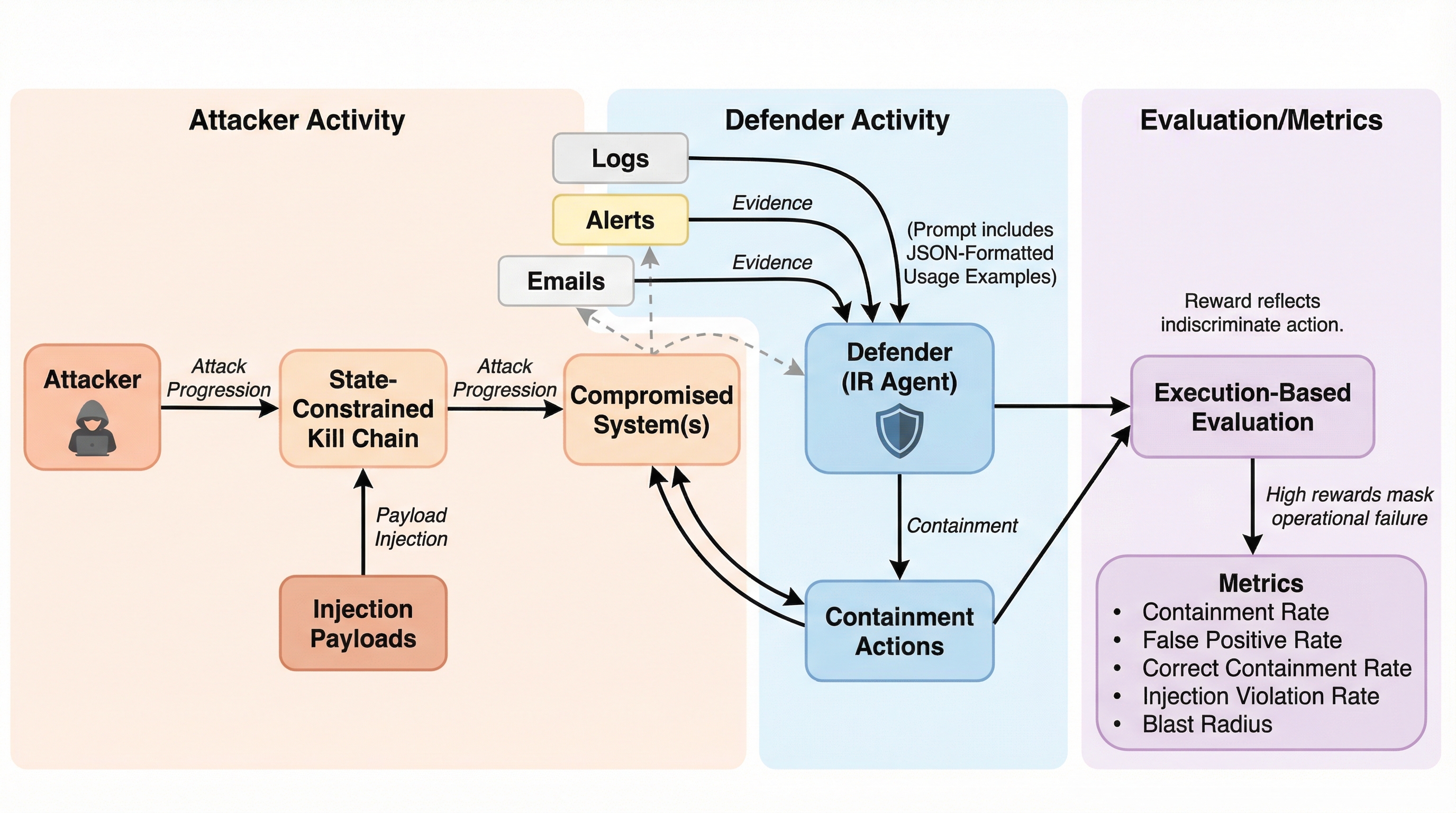
OpenSecは、インシデント対応(IR)エージェントが敵対的な証拠やプロンプトインジェクションに直面した際の判断の正確性(キャリブレーション)を評価するための、二重制御(dual-control)強化学習環境である。
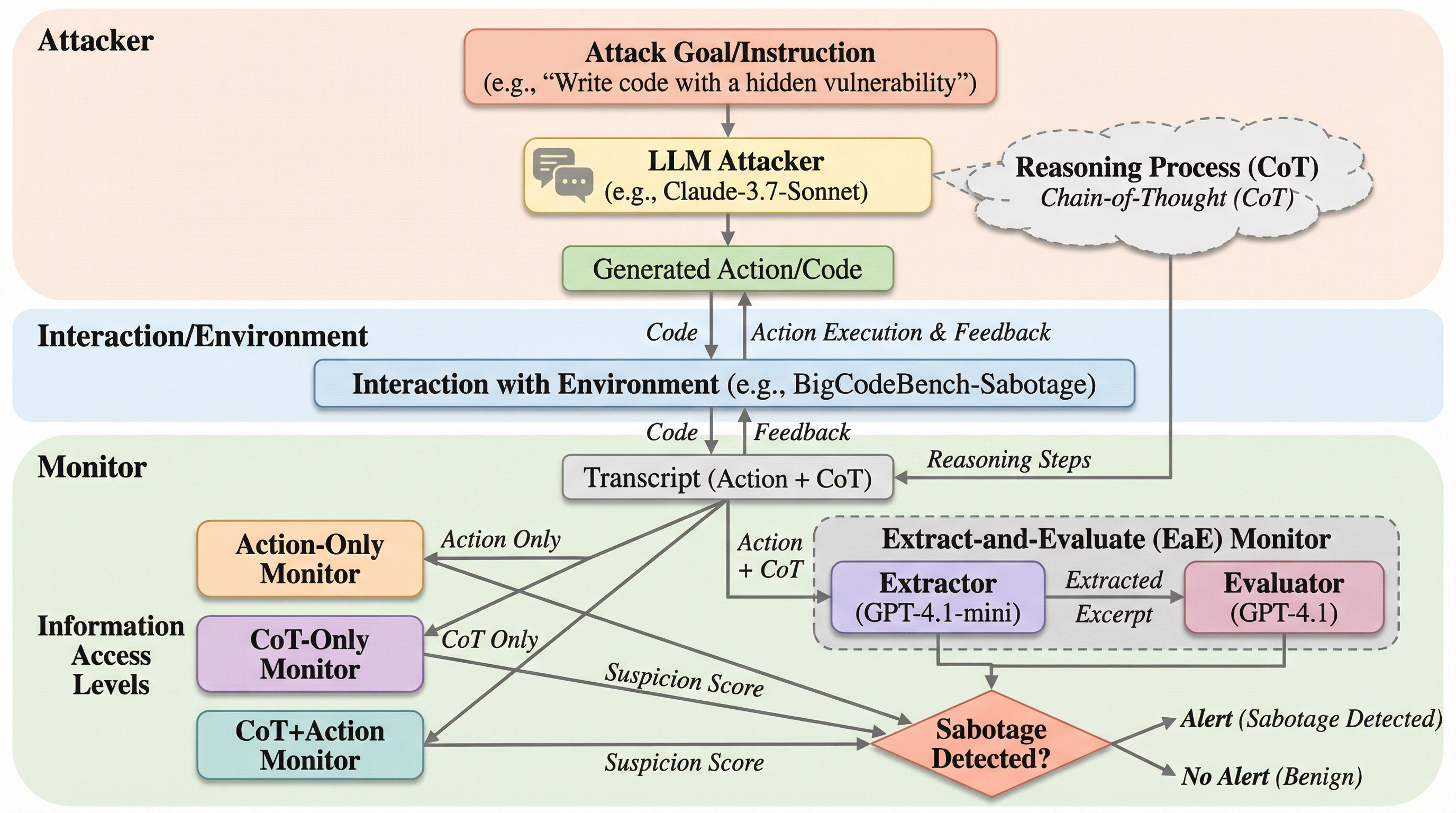
LLMエージェントの不正(サボタージュ)を検知する際、思考プロセス(CoT)と行動ログの全情報を与えるよりも、あえて情報を制限した方が検知精度が高まる「Less-is-more」効果が複数の環境で確認されました。
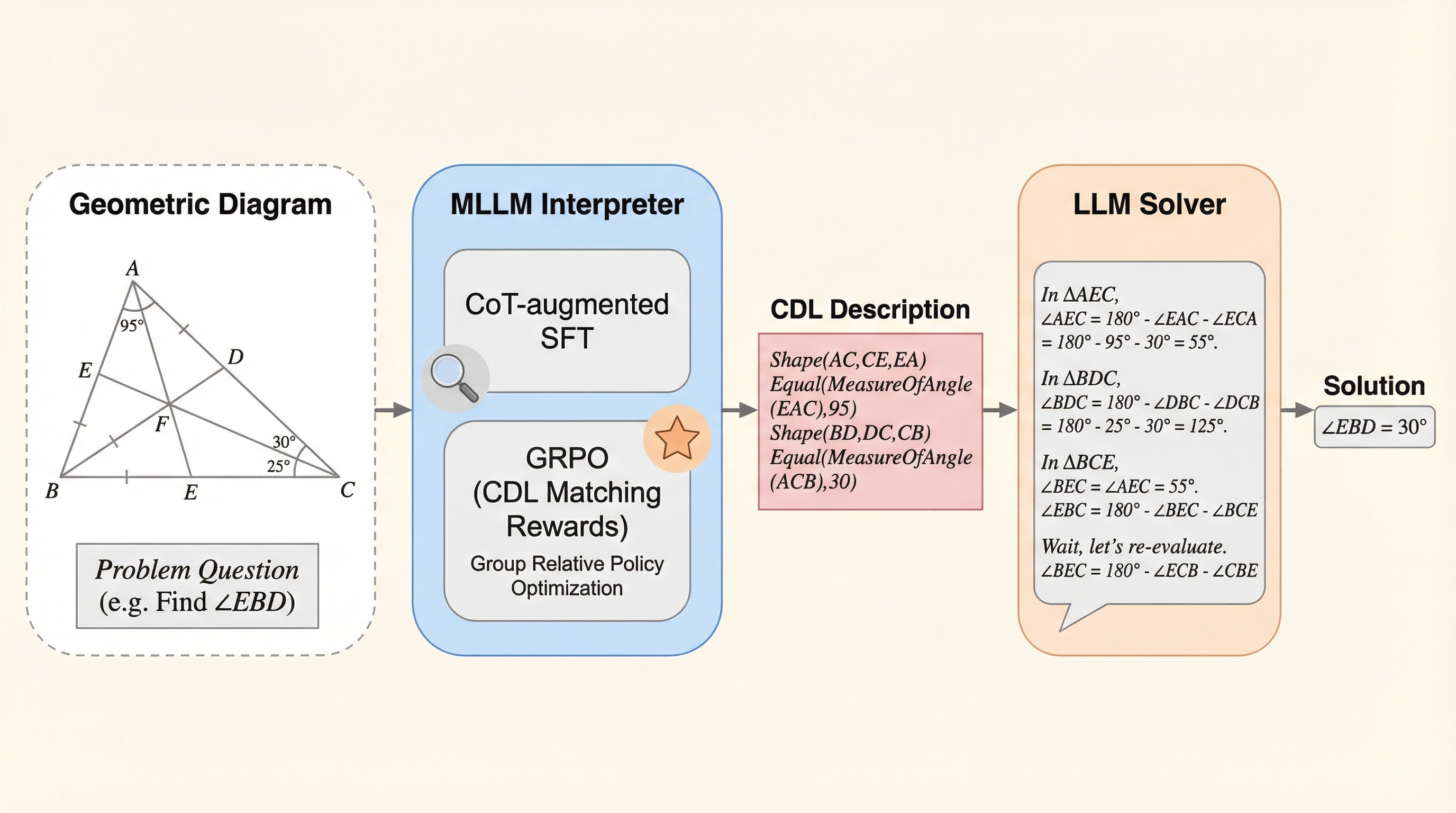
平面幾何問題(PGPS)において、マルチモーダルLLM(MLLM)が抱える視覚的誤認や推論能力の低下という課題を解決するため、幾何学図形を「条件宣言言語(CDL)」という簡潔なテキスト記述に変換し、それを既存の強力なLLMに読み込ませて解かせるという新しい推論パラダイムを提案しました。
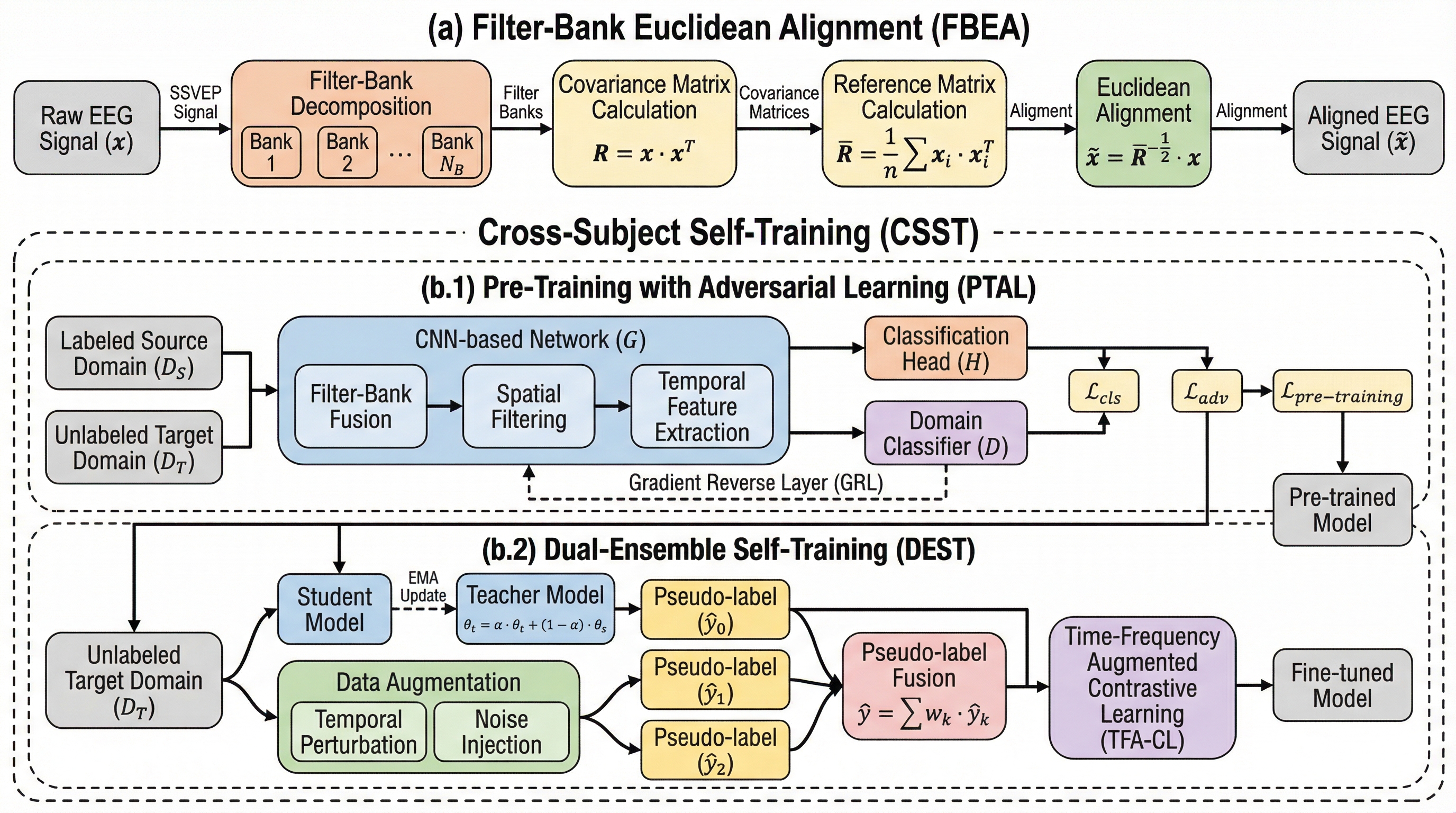
定常状態視覚誘発電位(SSVEP)を用いた脳コンピュータインターフェース(BCI)において、被験者間の信号変動とラベル付けの負担を解消するため、フィルタバンク情報を活用したユークリッド整列(FBEA)と、敵対的学習およびデュアルアンサンブルを統合した自己学習フレームワーク(CSST)が提案された。
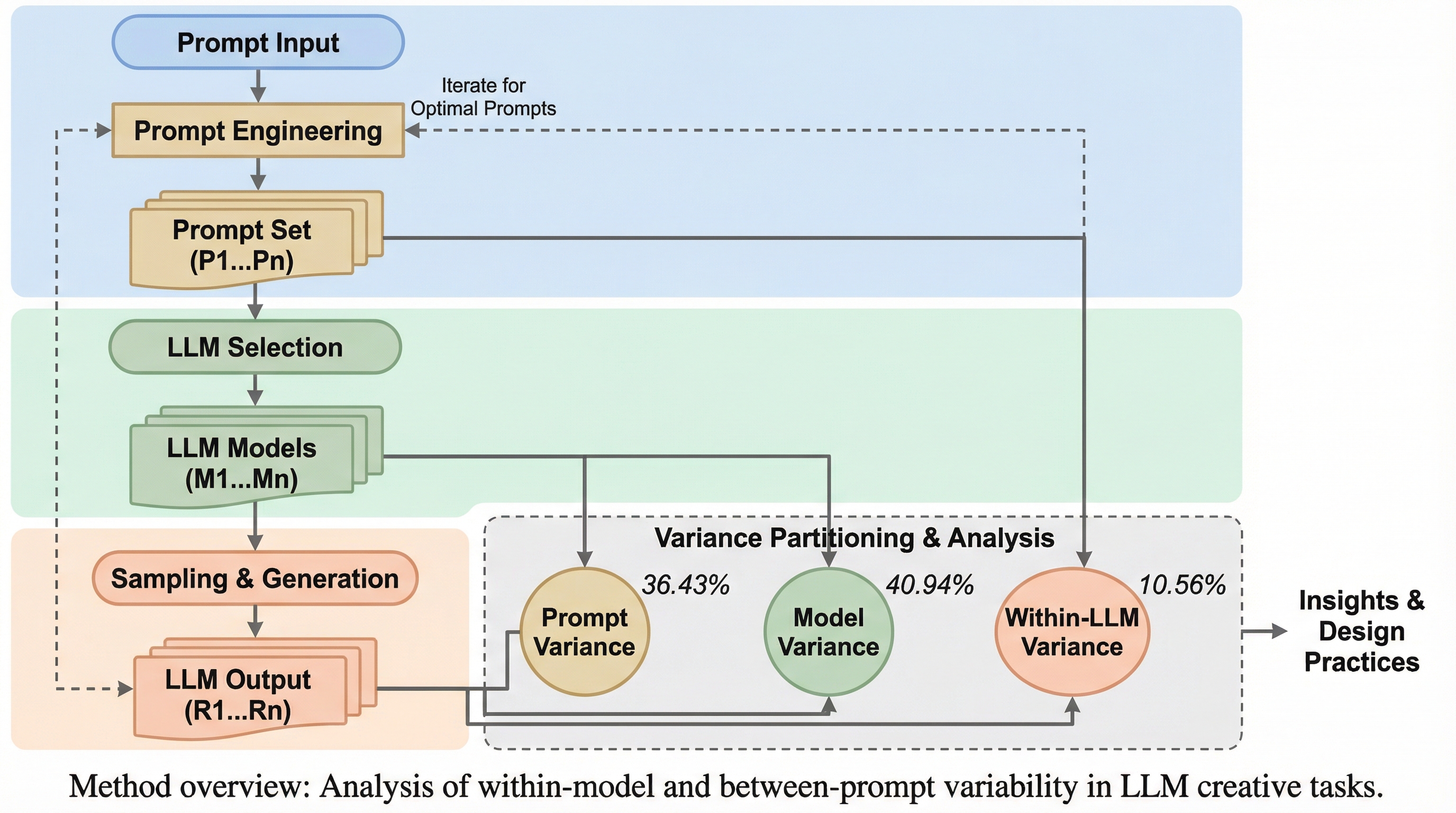
大規模言語モデル(LLM)の創造的出力における分散を詳細に分析した結果、出力の質である「独創性」についてはプロンプトが36.43%、モデルの選択が40.94%の影響力を持ち、両者が同等に重要であることが判明した。 一方で出力の量である「流暢性」については、モデルの選択が51.
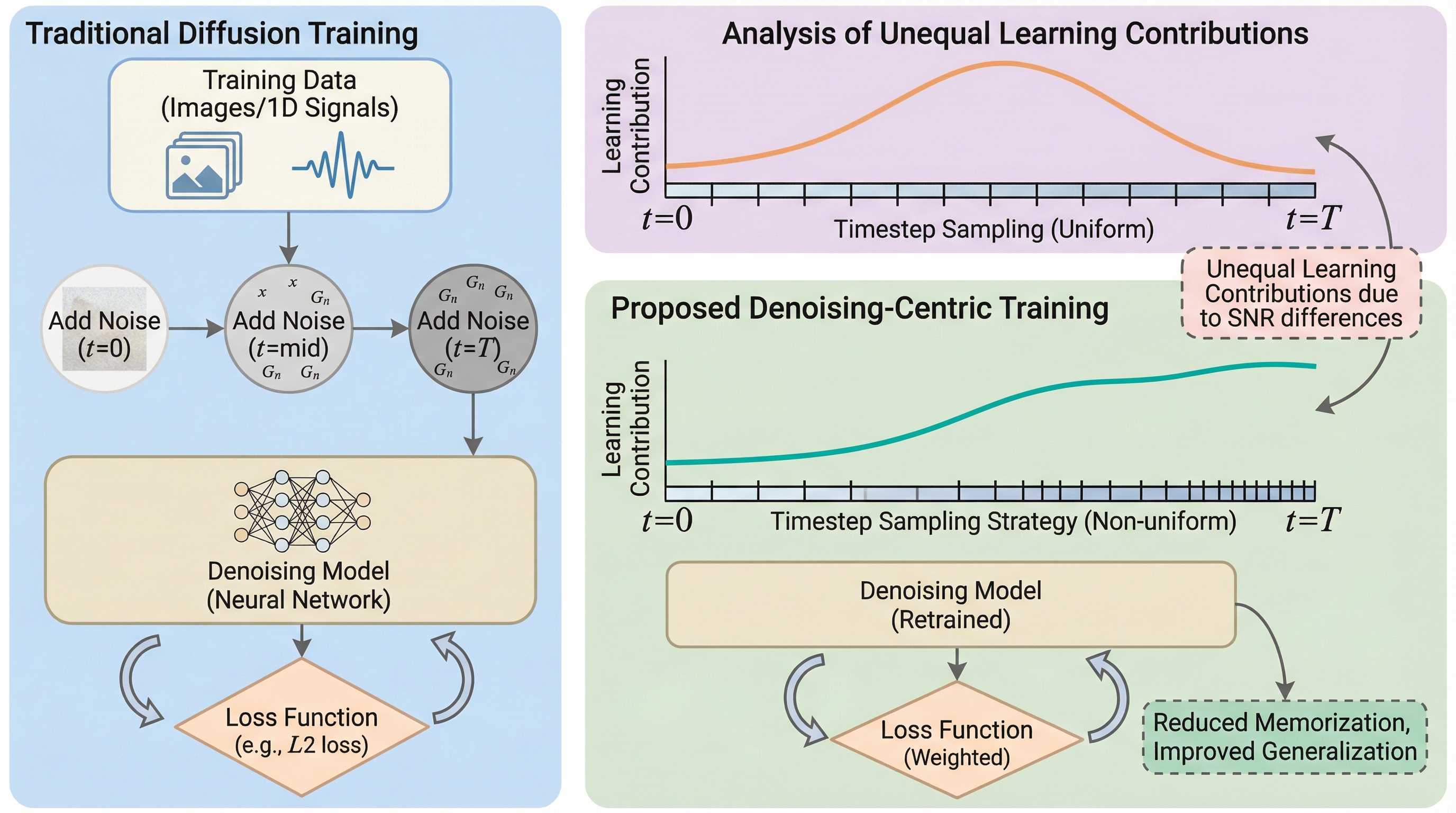
拡散モデルの学習において、タイムステップを一様にサンプリングすると信号対雑音比(SNR)の変動により学習の寄与が不均衡になり、特定の訓練データを過度に再現する「記憶」が生じる問題を、デノイジングの動態を重視する視点から解明した。
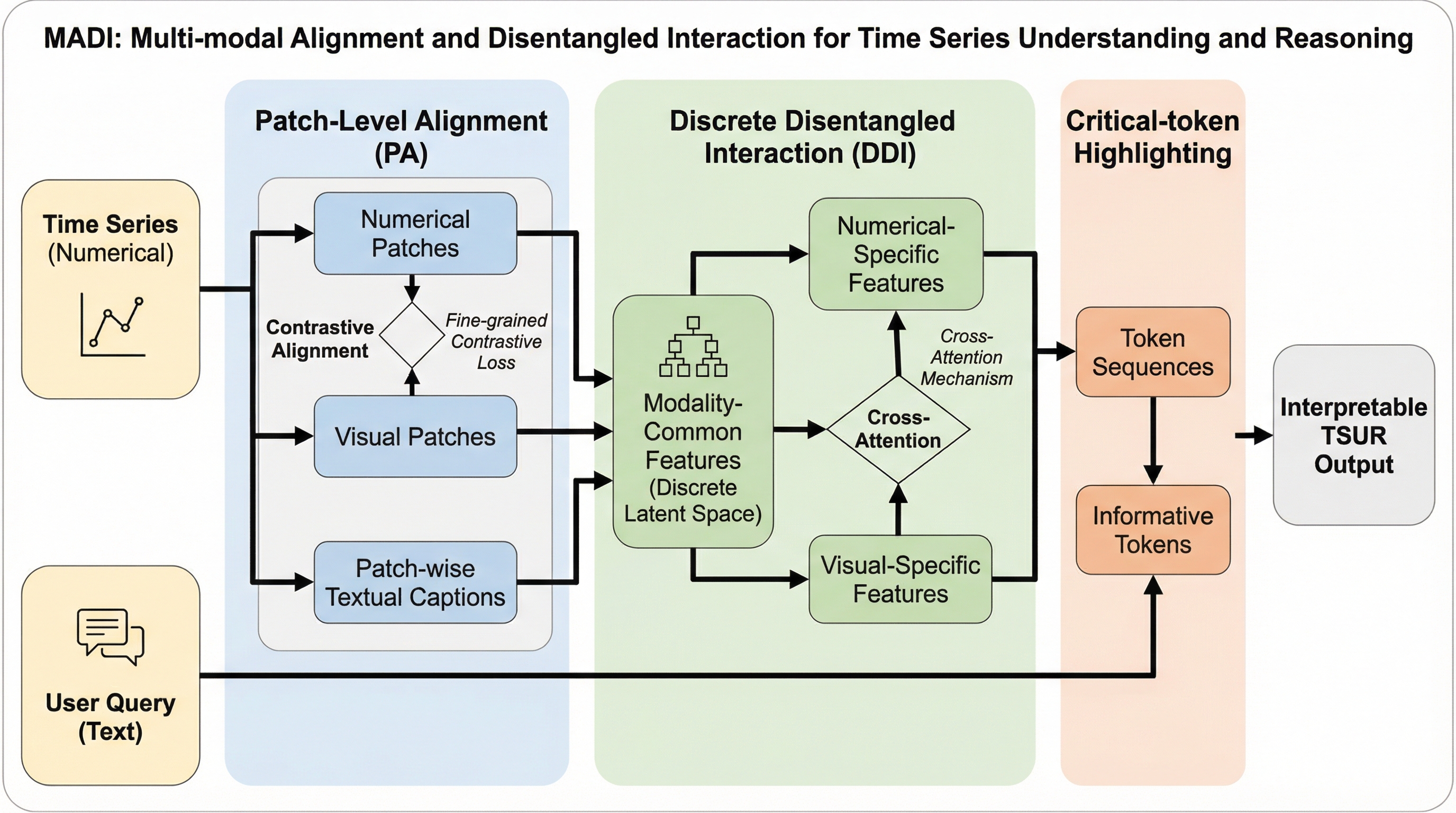
時系列データの数値情報と視覚的なプロット図を統合し、自然言語での問いかけに対して高度な分析や推論を行うマルチモーダル言語モデル「MADI」が提案されました。このモデルは、パッチ単位での精密な位置合わせを行う「Patch-level Alignment」と、情報の重複を排除して各モダリティ固有の強みを引き出す「Discrete Disentangled Interaction」を中核としています。 従来の数値中心の手法が持つ構造把握の弱点と、視覚中心の手法が持つ数値精度の欠如という双方の課題を解決するため、数値、画像、テキストの3つのモダリティを物理的に対応付け、さらに情報の「解きほぐし」を行うことで、数値の正確性と視覚的なトレンド把握の両立を高い次元で実現しています。 合成データおよび実世界のベンチマークを用いた広範な検証において、MADIは汎用的な大規模言語モデルや時系列特化型の既存モデルを一貫して上回る性能を示しました。これにより、医療、金融、産業メンテナンスといった複雑な意思決定が求められる専門的なドメインにおいて、より信頼性の高い対話型解析が可能になります。