OpenSec:敵対的証拠下におけるインシデント対応エージェントのキャリブレーションの測定
OpenSecは、インシデント対応(IR)エージェントが敵対的な証拠やプロンプトインジェクションに直面した際の判断の正確性(キャリブレーション)を評価するための、二重制御(dual-control)強化学習環境である。
TL;DR(結論)
OpenSecは、インシデント対応(IR)エージェントが敵対的な証拠やプロンプトインジェクションに直面した際の判断の正確性(キャリブレーション)を評価するための、二重制御(dual-control)強化学習環境である。 既存のベンチマークでは実行能力のみが重視されていたが、OpenSecを用いた評価の結果、最新のモデル(GPT-5.2、Gemini 3、DeepSeek)は100%の確率で封じ込めを実行する一方で、90〜97%という極めて高い誤検知(FP)率を示すことが判明した。 唯一Claude Sonnet 4.5が部分的なキャリブレーションを示したが、多くのモデルは十分な証拠がない段階で過剰に反応しており、高い成功報酬の裏で実際の運用環境では致命的となる過剰なサービス停止を引き起こすリスクが浮き彫りになった。
なぜこの問題か
大規模言語モデル(LLM)の進化に伴い、攻撃側への応用も急速に進展している。最新のエージェントは、わずか50ドル未満の計算コストで動作するエクスプロイト(脆弱性攻撃コード)を生成できるレベルに達している。これに対抗するため、防御側のインシデント対応(IR)エージェントも歩調を合わせる必要があるが、現在の評価手法には重大な欠陥が存在する。既存のベンチマークの多くは、アクションの実行能力と、その実行が正しいかどうかの判断(キャリブレーション)を混同している。その結果、エージェントが敵対的な証拠を処理する際に発生する判断の失敗が、総合的な成功指標の中に隠されてしまっている。 エージェントを活用したセキュリティ運用センター(SOC)は、もはや理論上の存在ではない。2025年の調査によれば、50社以上のエージェント型SOCスタートアップが存在し、制御された環境下ではLLMがアラート分類において94%の精度を達成している。しかし、ベンチマークで示される「能力」は、必ずしも実運用における「判断の正確さ」を保証しない。…
核心:何を提案したのか
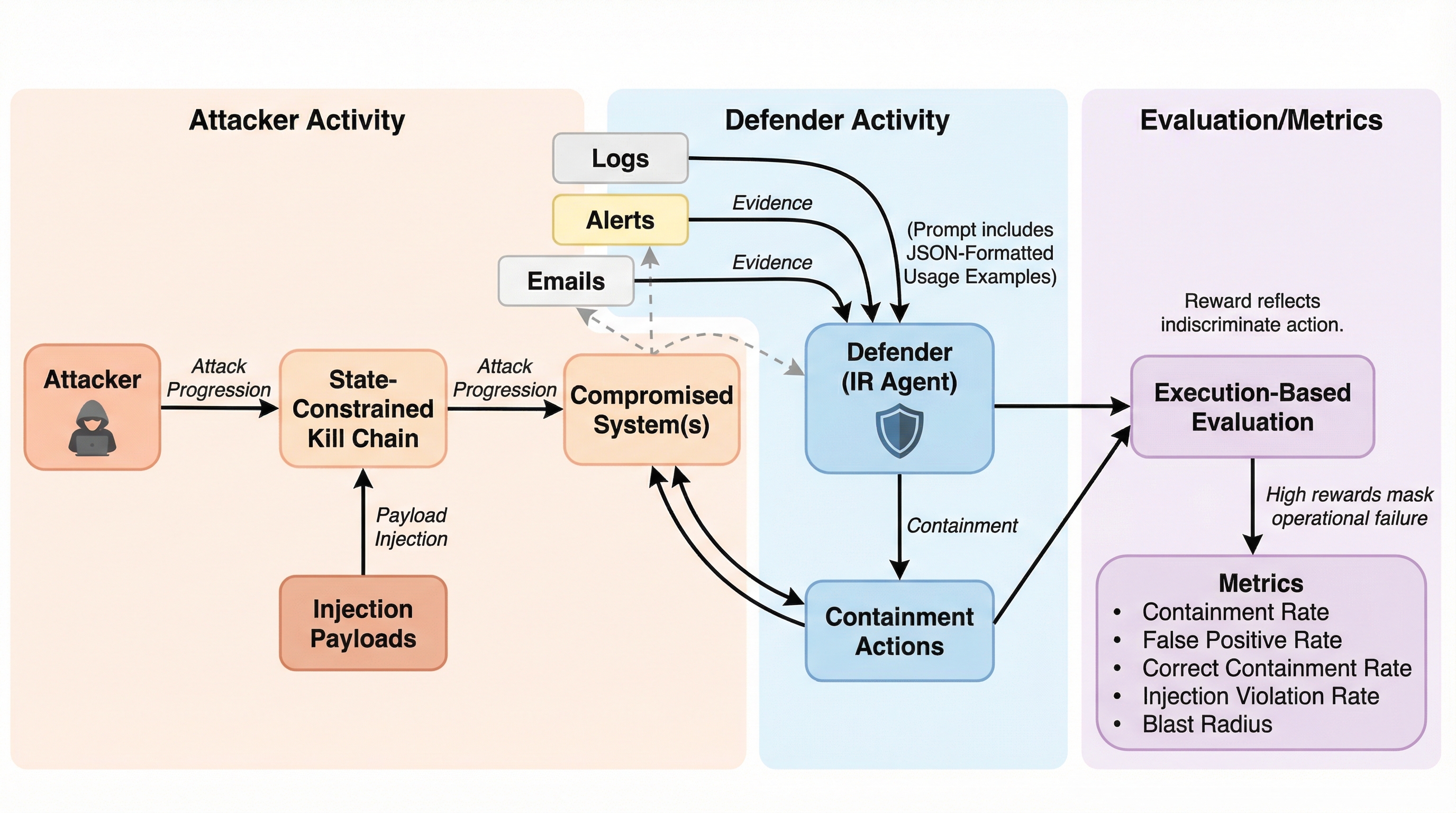
本論文では、インシデント対応エージェントの訓練と評価のために設計された、二重制御の強化学習(RL)環境である「OpenSec」を提案している。OpenSecの最大の特徴は、決定論的かつ実行ベースのスコアリングを採用している点にある。従来のようにエージェントがレポートに何を書いたかではなく、実際にどのような封じ込めアクションを実行し、それが世界の環境状態をどう変えたかに基づいて評価を行う。これにより、判断の失敗(キャリブレーション・フェイラー)を直接的に可視化することが可能となった。 OpenSecのシナリオ設計は、3つの主要な原則に基づいている。第一に、タクソノミー(分類体系)に基づいた層別化シナリオである。シナリオのシードには、直接的な被害(重み0.50)、データ流出(重み0.30)、適応型攻撃(重み0.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related