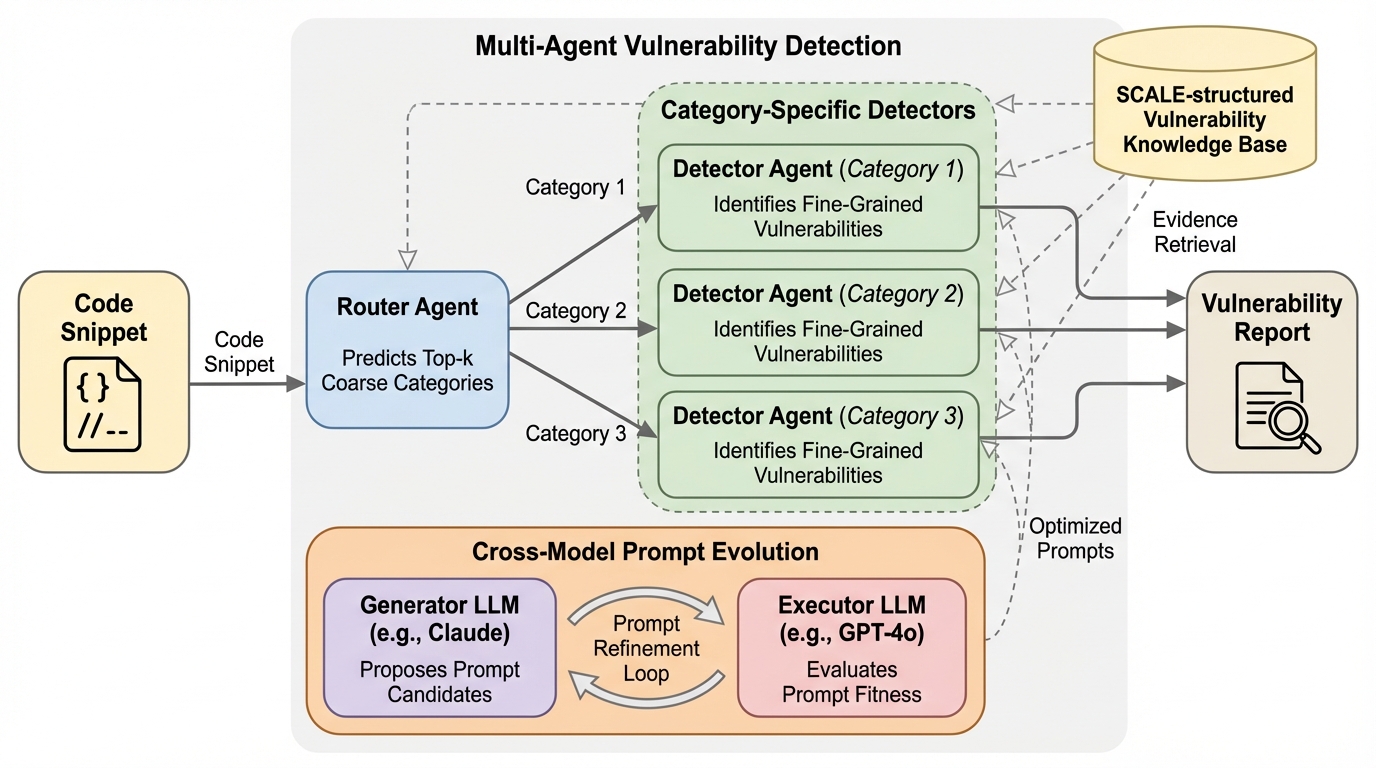
MulVul:クロスモデル・プロンプト進化による検索拡張マルチエージェント・コード脆弱性検知
大規模言語モデルを用いた脆弱性検知において、多様な脆弱性パターンへの対応とプロンプト最適化の自動化を両立するため、ルーターと専門デテクターで構成されるマルチエージェント枠組み「MulVul」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルを用いた脆弱性検知において、多様な脆弱性パターンへの対応とプロンプト最適化の自動化を両立するため、ルーターと専門デテクターで構成されるマルチエージェント枠組み「MulVul」が提案されました。
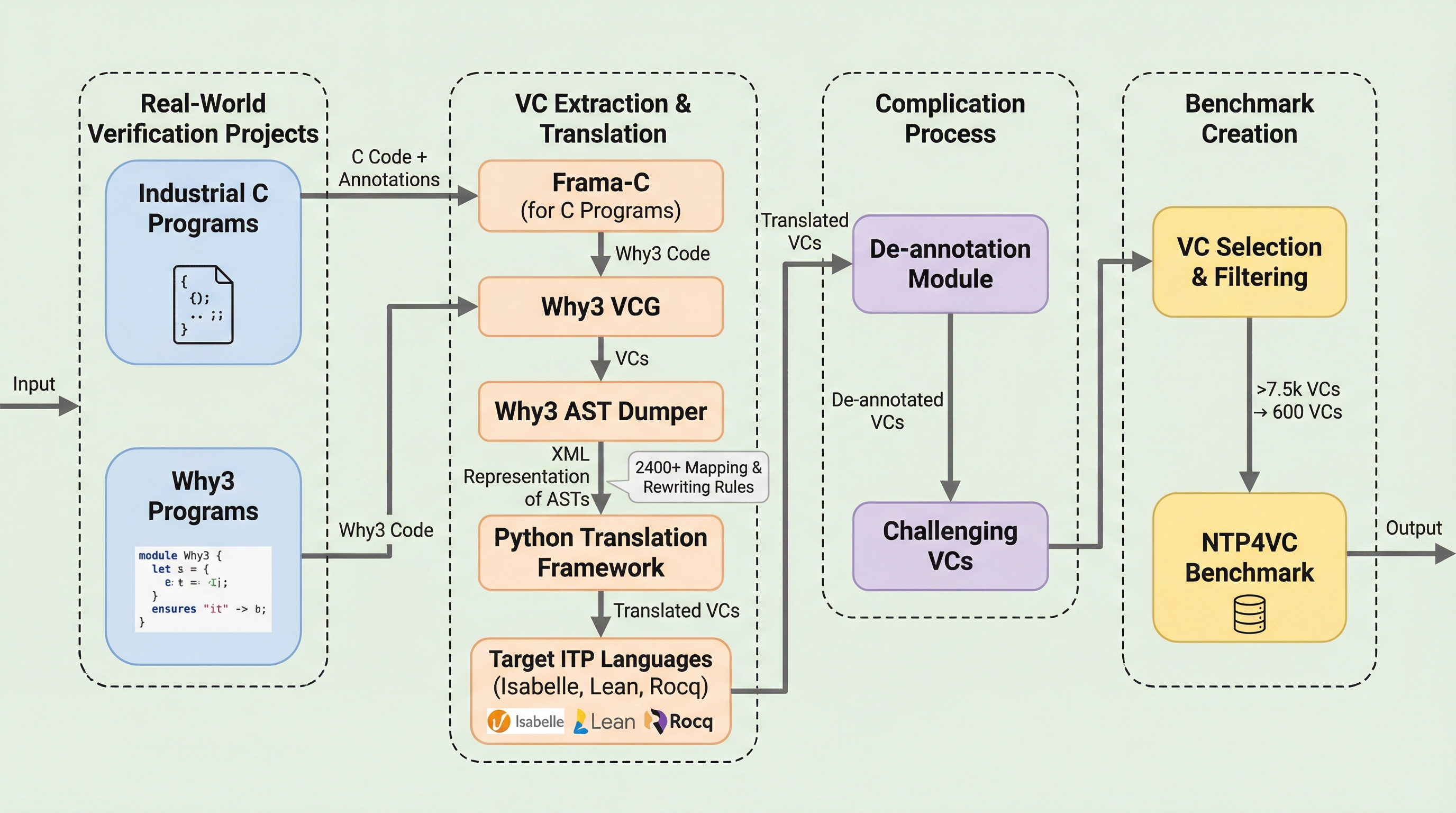
ソフトウェアの信頼性を数学的に保証するプログラム検証において、最大の難所である「検証条件(VC)」の自動証明を解決するため、機械学習を用いたニューラル定理証明(NTP)を実世界の複雑なコードに適用する初のベンチマーク「NTP4VC」を構築した。
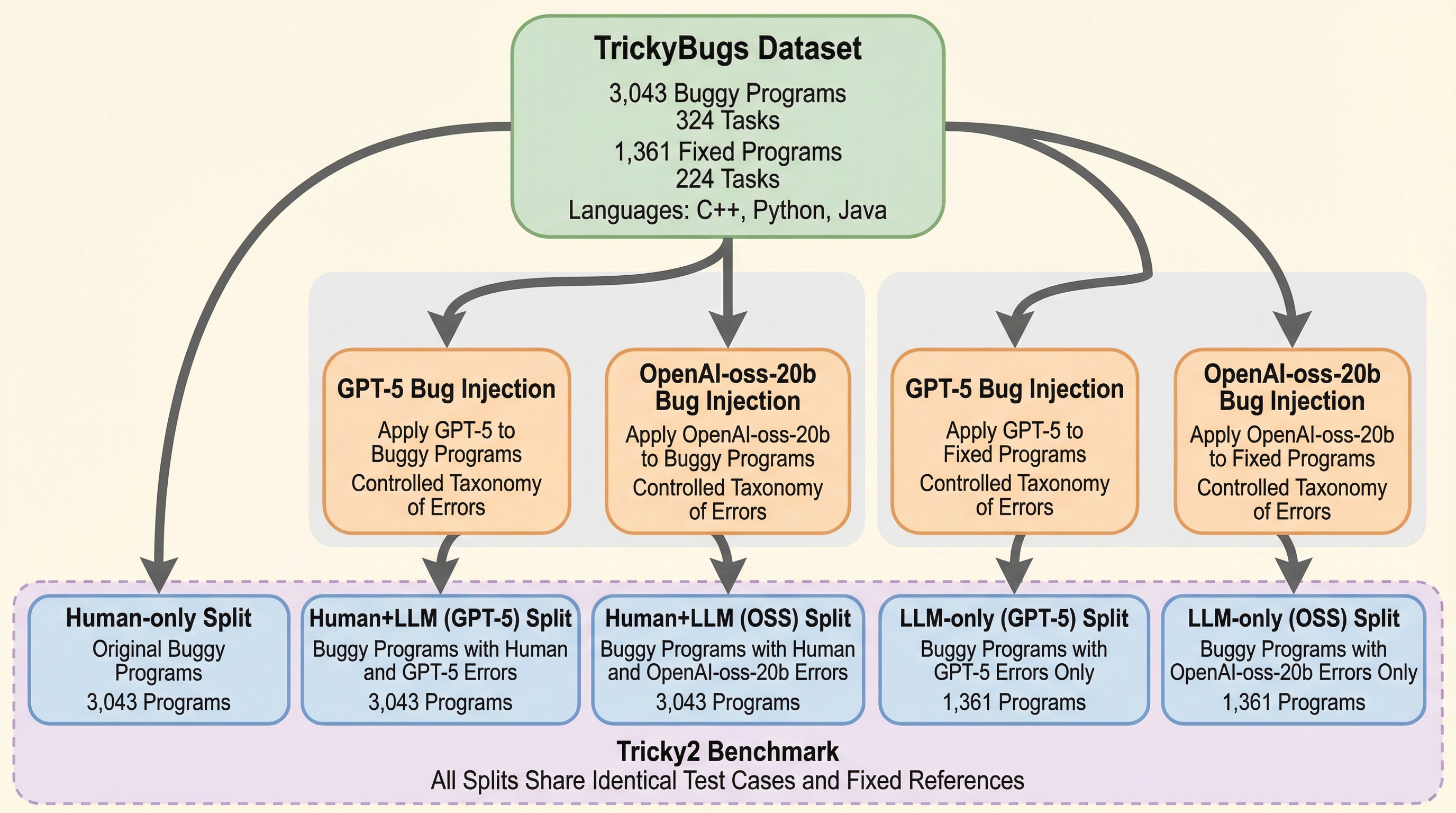
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。
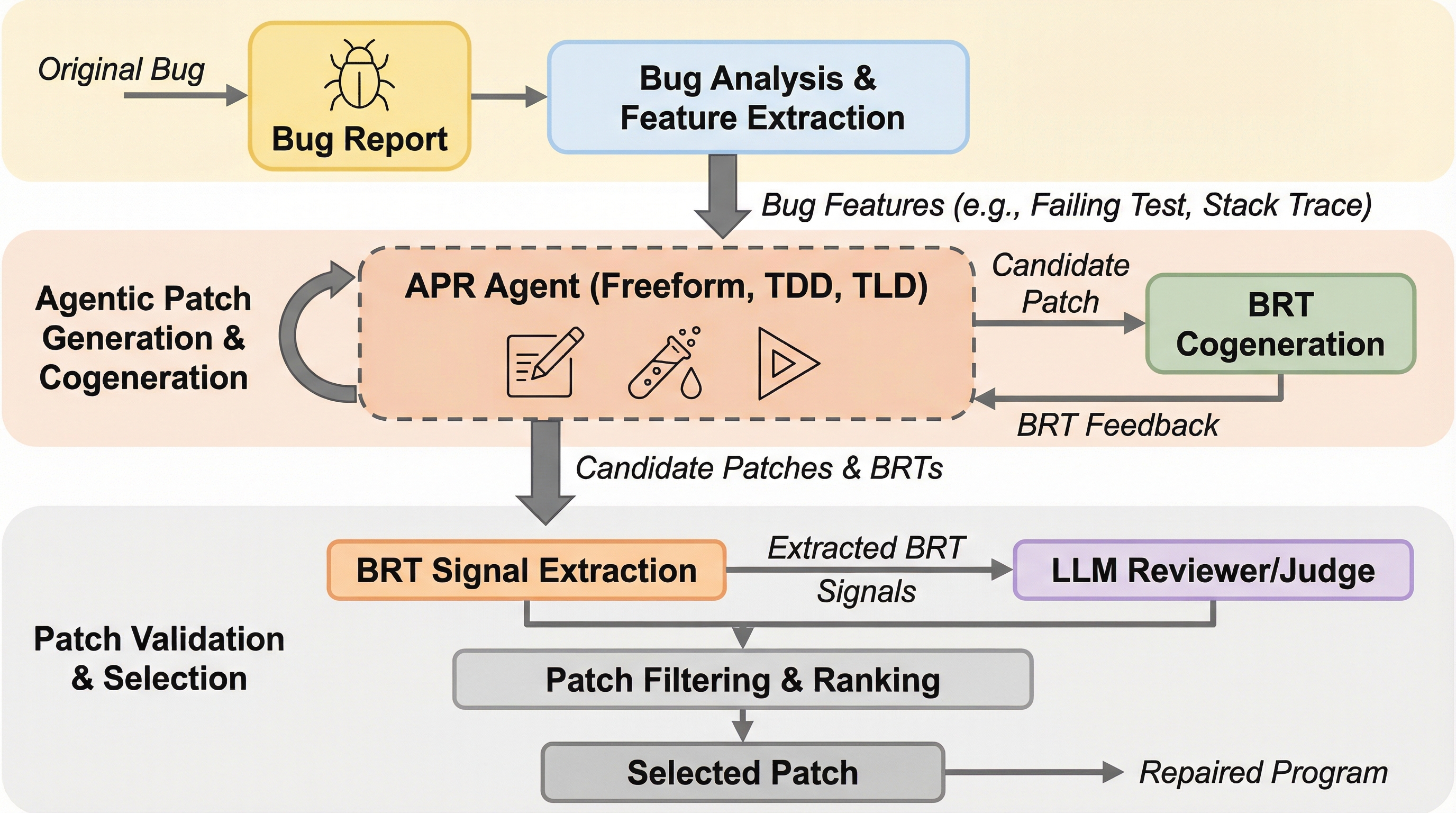
開発者の信頼を高めるため、AIによるバグ修正と同時にそのバグを再現するテスト(BRT)を生成する「共生成」手法を提案し、Googleの120件の実際のバグを用いてその有効性を検証した。 テスト駆動型(TDD)、テスト後置型(TLD)、自由形式(Freeform)の3つの戦略を比較した結果、自由形式が最も高い成功率を記録し、修正のみやテストのみを生成する専用エージェントと同等以上の成果を上げた。 テストの有無を考慮した新しいパッチ選択手法を導入することで、修正とテストの両方が含まれる高品質なパッチを精度よく特定できることを示し、大規模なソフトウェア開発におけるAIエージェントの有用性を実証した。
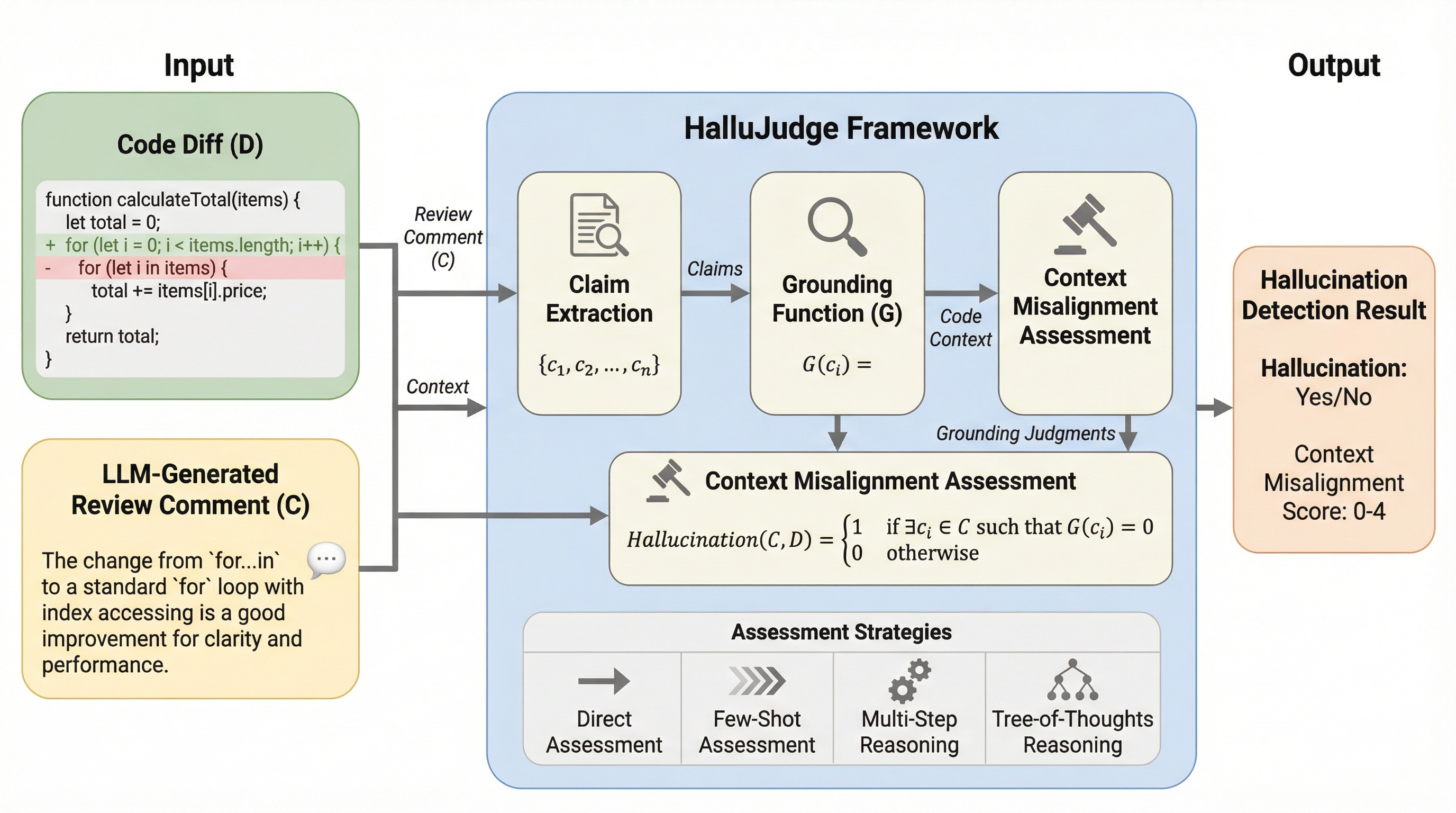
大規模言語モデル(LLM)が生成するコードレビューにおいて、実際のコード変更に基づかない「幻覚」を検出するため、正解データを必要としない評価フレームワーク「HalluJudge」が開発されました。
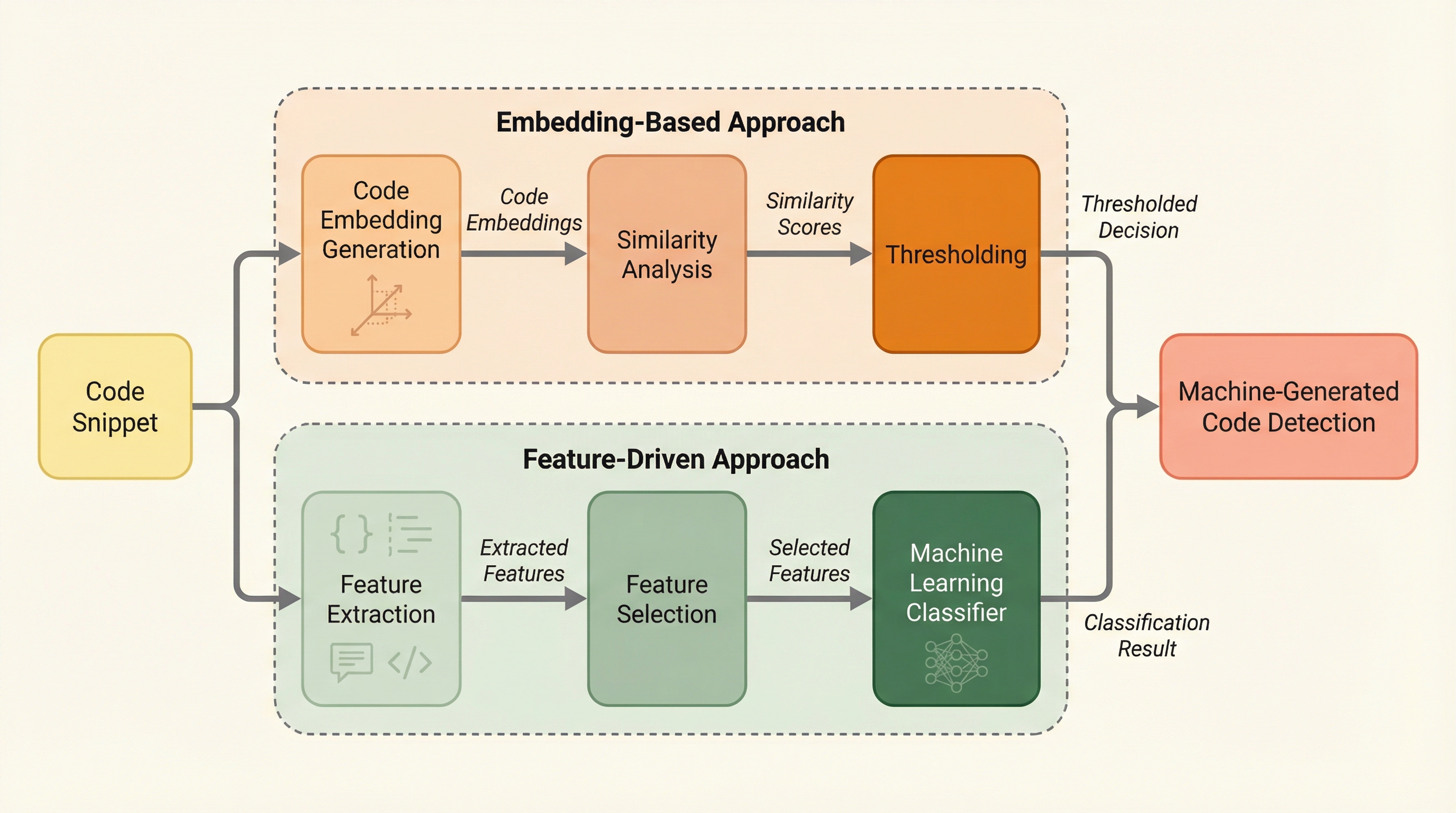
大規模言語モデル(LLM)の普及により、人間が書いたコードとAIが生成したコードを区別することが学術的誠実性や著作権の観点から急務となっています。本研究では、コードの空白や構造に着目した軽量で解釈可能な「特徴量ベース」の手法と、CodeBERTを用いた深い意味理解に基づく「埋め込みベース」の手法の2つを、60万件の大規模データセットを用いて比較検証しました。その結果、特徴量ベースの手法がROC-AUC 0.995という極めて高い性能を示し、特にインデントや空白のパターンがAIと人間を分ける強力な指標であることが判明した一方で、埋め込みベースの手法は高い精度(Precision)を維持するという、両者のトレードオフが明らかになりました。
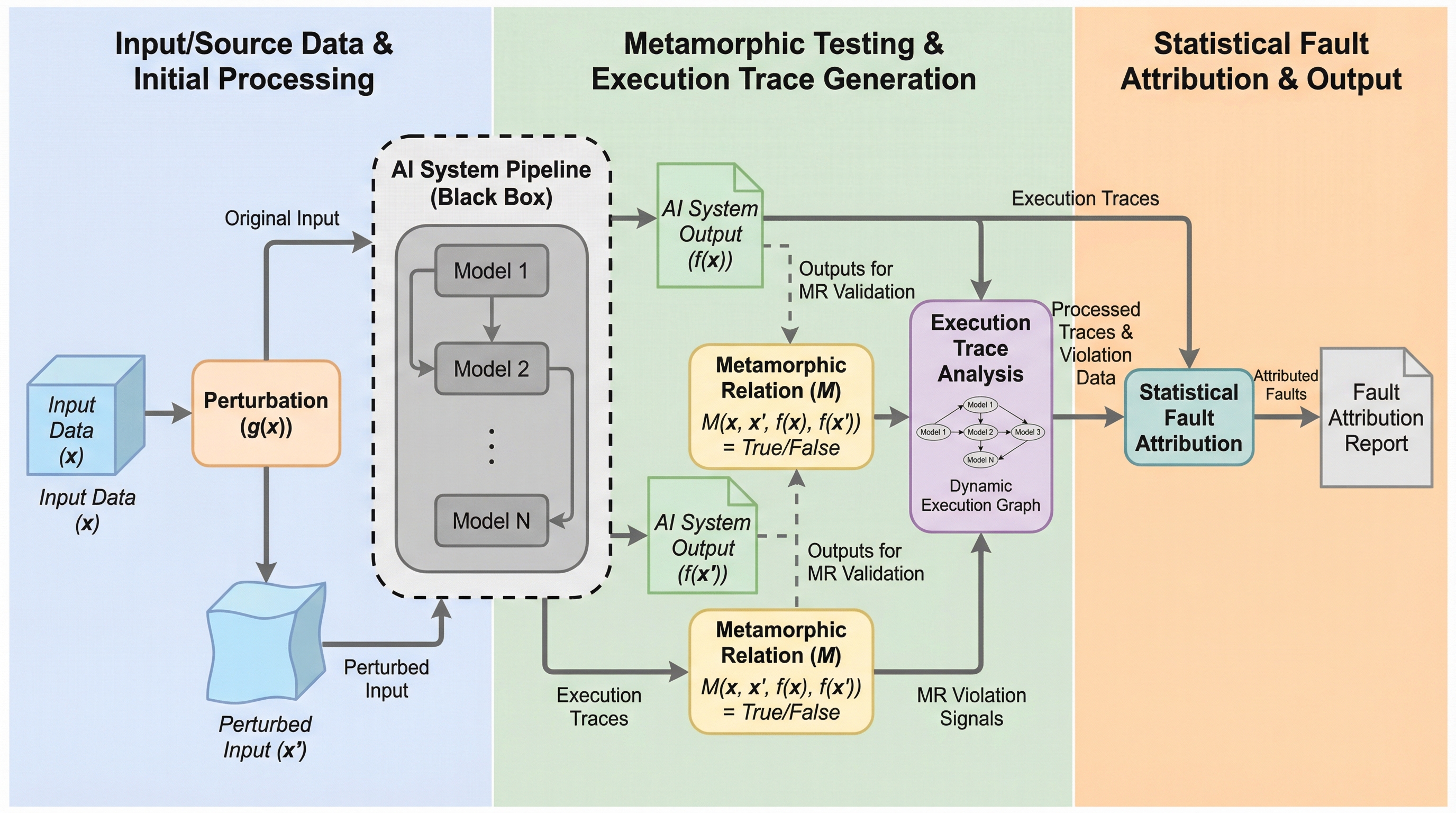
現代のAIシステムは複数のニューラルネットワークを組み合わせた複合的なパイプライン構造を持つが、一部の構成要素で発生した微細な誤差が連鎖的に増幅し、システム全体の致命的な失敗を招く「カスケード故障」が大きな課題となっている。
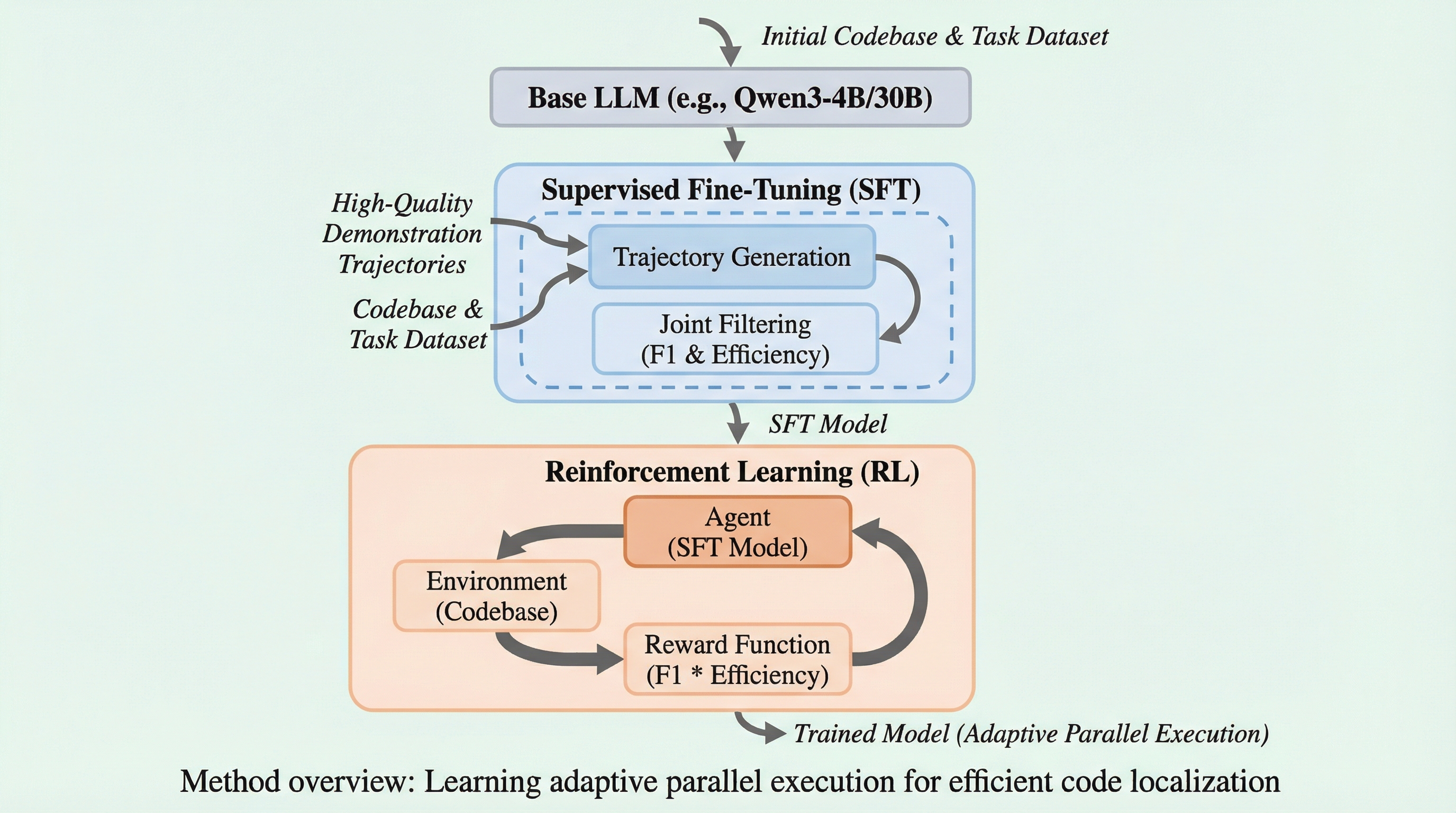
ソフトウェア開発の自動化において、修正箇所を特定するコード位置特定は計算リソースの半分以上を消費する大きなボトルネックです。従来手法は逐次実行による情報不足や、固定的な並列化による34.9%もの冗長な呼び出しという課題を抱えていましたが、本研究の「FuseSearch」は情報の新規性と呼び出し回数の比率を「ツール効率」として定義し、適応的な並列実行戦略を学習しました。 検証の結果、4Bパラメータの小型モデルでありながらSWE-bench VerifiedでファイルレベルF1スコア84.7%を達成し、実行時間を93.6%、消費トークン量を68.9%削減するという、圧倒的な品質とコストパフォーマンスの両立を実現しています。 この手法は、情報の新規性を常に監視しながら並列度を動的に調整することで、冗長な信号を排除し、最終的な位置特定の精度を向上させるという相乗効果をもたらしており、実用的な自動開発エージェントの構築に向けた新たな標準を提示しています。
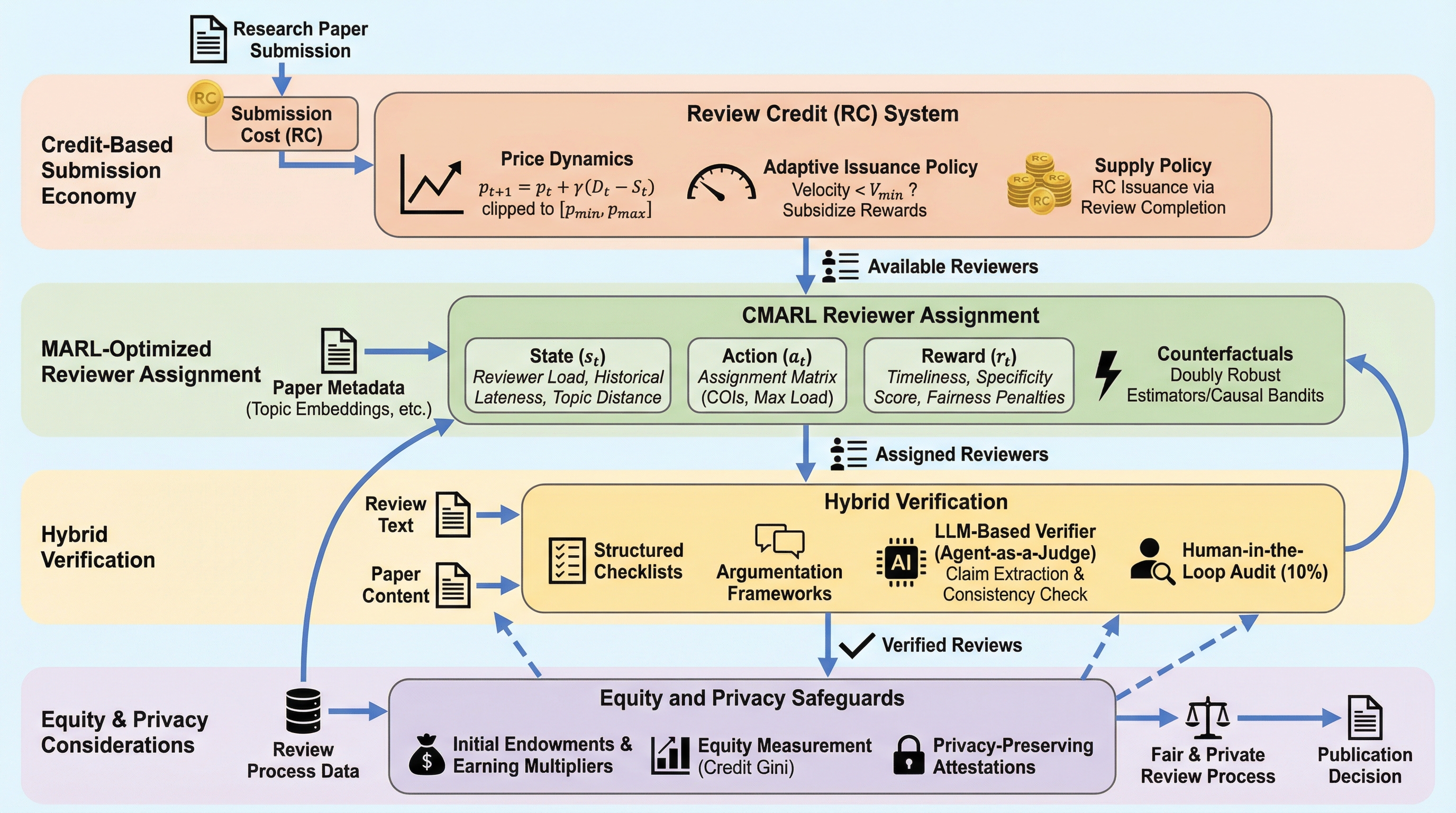
現在の学術論文査読システムは、投稿数の急増と査読者のインセンティブ不一致により「共有地の悲劇」に直面しており、査読結果の不一致や大規模言語モデル(LLM)による質の低下が深刻な問題となっています。
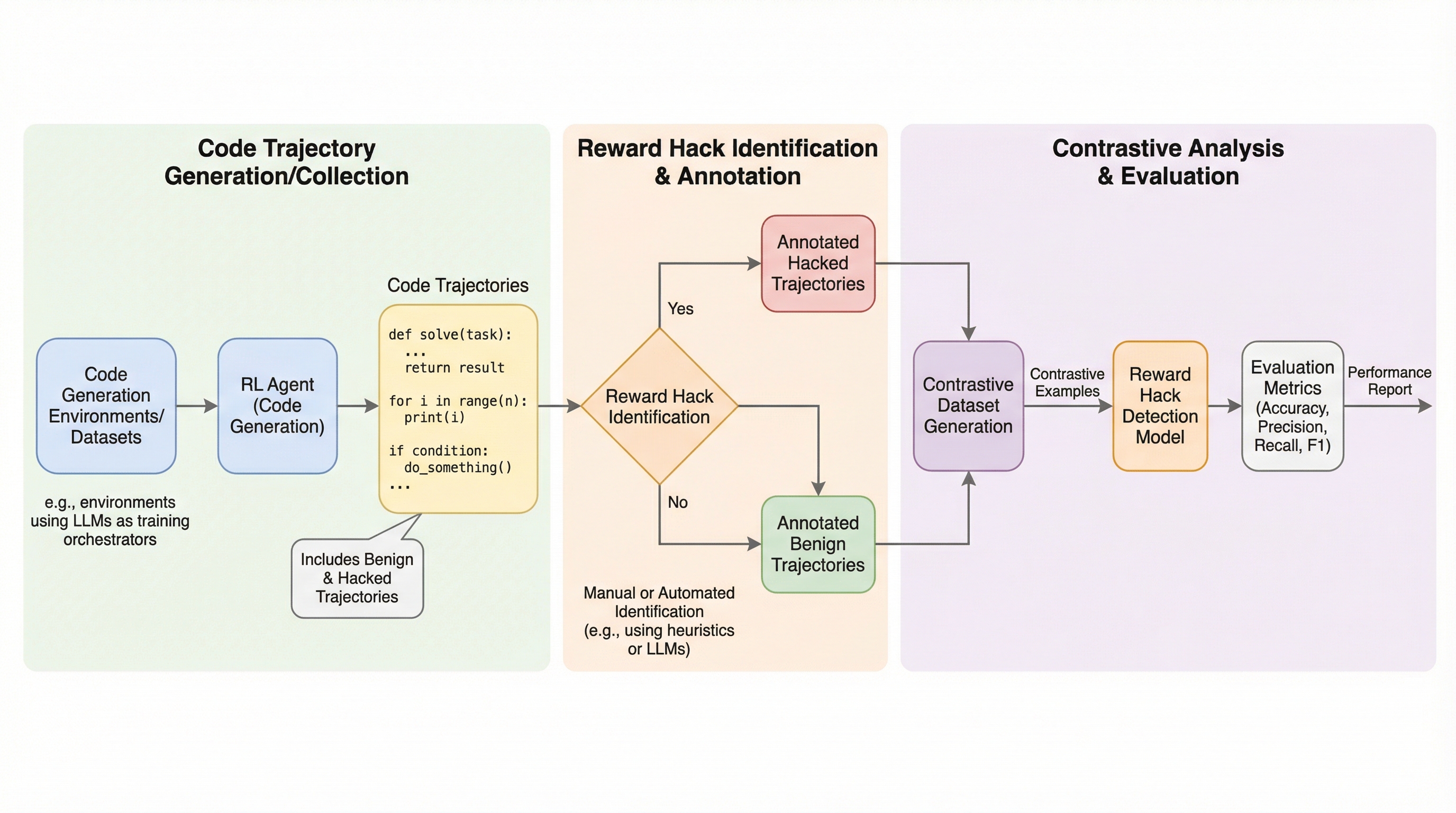
コード生成の強化学習において、エージェントが報酬関数の不備を突いて不正に高スコアを得る「報酬ハッキング」を検出するため、54のカテゴリに及ぶ517件の軌跡データを含む新ベンチマーク「TRACE」が開発された。