Magellan:AlphaEvolveを用いた新規コンパイラ最適化ヒューリスティクスの自律的発見
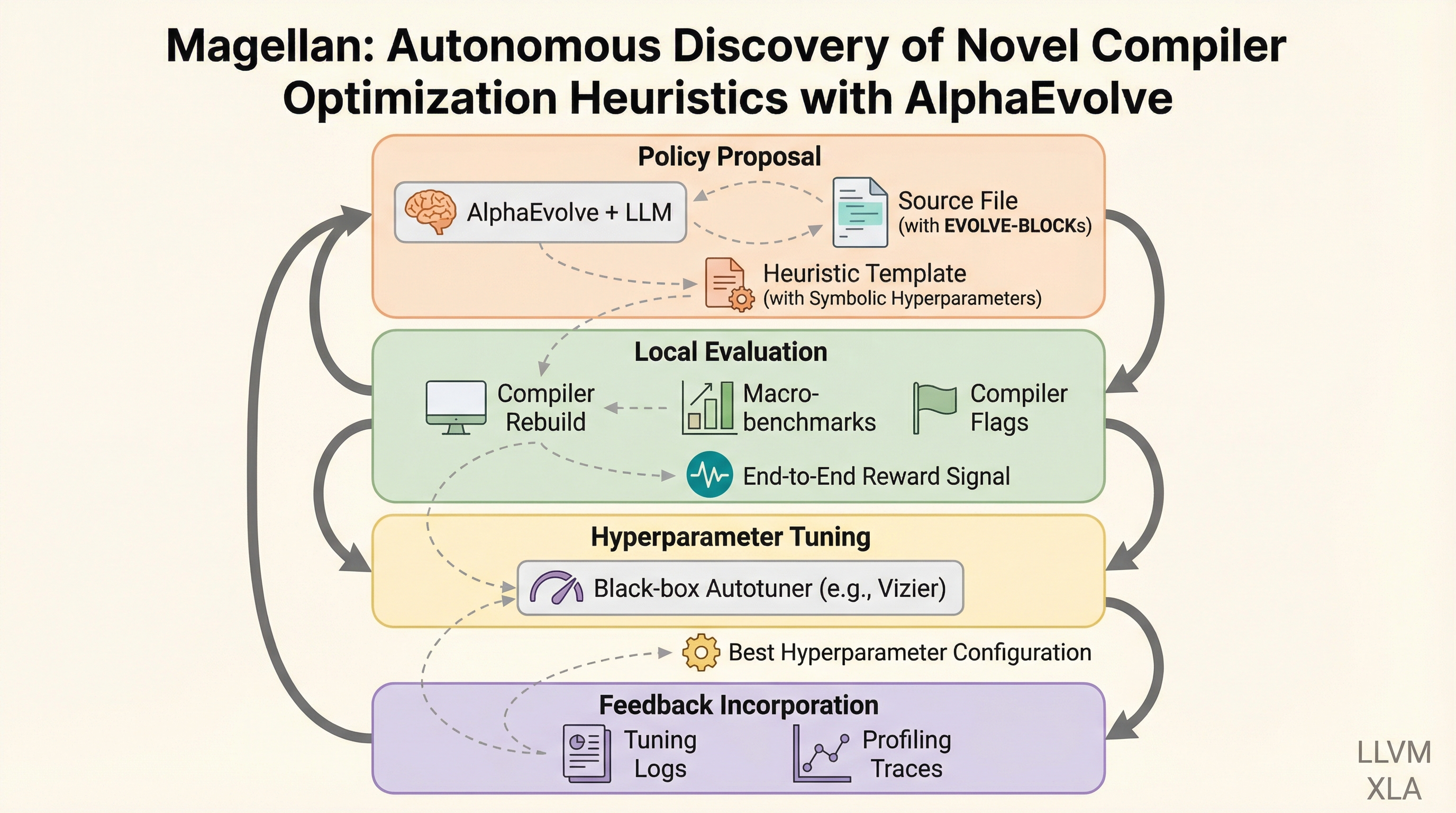
現代のコンパイラが依存する手動設計のヒューリスティクスは、複雑なソフトウェアや多様なハードウェアへの適応が困難で保守負担も大きいという課題がありますが、本研究ではLLMと進化探索、自動チューニングを組み合わせたエージェント型フレームワーク「Magellan」を提案し、実行可能なC++の決定ロジックを直接合成することでこの問題を解決します。 LLVMの関数インライニングにおいて、Magellanは数十年にわたる専門家の手動設計を上回る新しいヒューリスティクスを合成し、バイナリサイズの削減率で5.23%の向上を達成したほか、生成されたコードは手動実装の約15分の1という極めて簡潔な記述でありながら、既存のコンパイラに直接統合して運用できる高い実用性を備えていることが確認されました。 この手法はレジスタ割り当てやXLAなどの異なる最適化タスクやコンパイラ基盤にも適用可能であり、特定のベンチマークへの過学習を避けつつ、時間の経過や異なるアプリケーション領域に対しても高い汎用性を示すことが実証されており、ニューラルネットワークを直接コンパイラに組み込む手法に代わる、保守性と性能を両立した新しい自動設計の道を切り拓いています。