MergeMix: 学習可能なモデルマージによる学習途中データ混合比の最適化
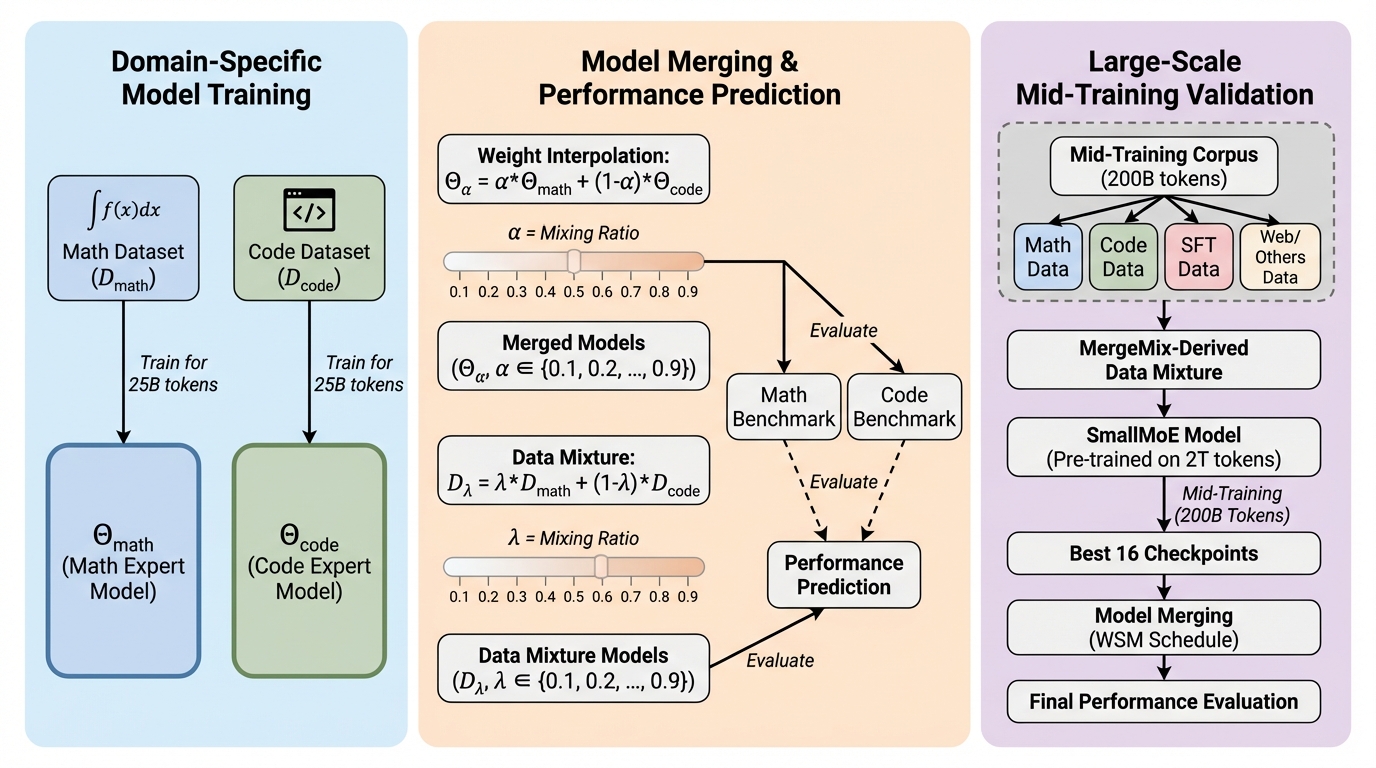
MergeMixは、大規模言語モデル(LLM)の中間学習における最適なデータ混合比を、モデルマージの重みを代理指標(プロキシ)として活用することで効率的に特定する新しい手法である。 従来のデータ混合比の最適化は、膨大な計算コストを伴う試行錯誤やスケーリング則の推定に依存していたが、本手法は少量のトークンで学習したドメイン専門家モデルを線形補間することで、実トレーニングなしに下流タスクの性能を予測する。 実験では8Bおよび16Bのモデルにおいて、手動による網羅的な調整と同等以上の性能を達成しつつ、探索コストを100倍以上削減することに成功しており、高いランク相関とスケールを跨いだ転移性も確認されている。