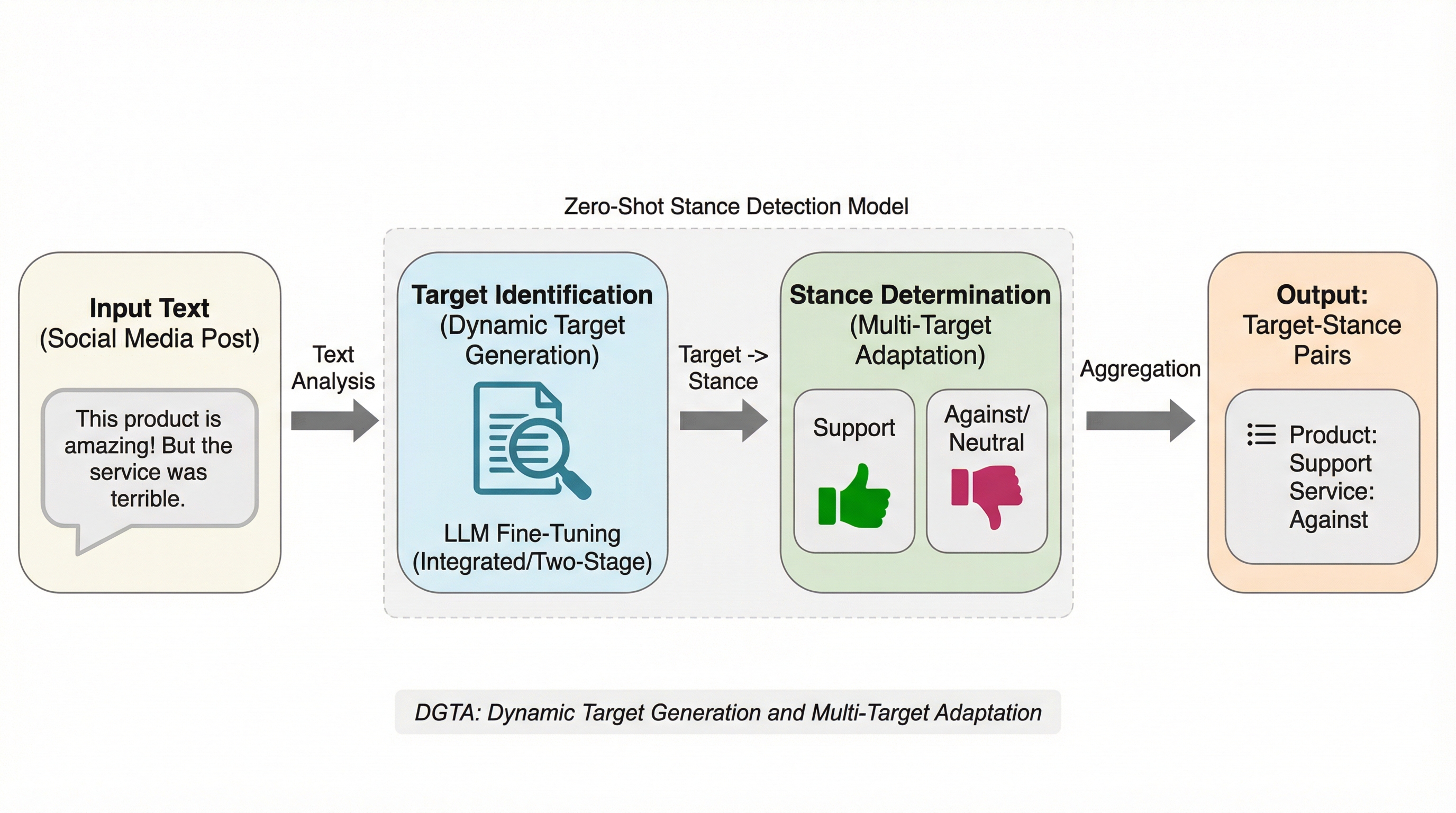
実環境におけるゼロショット・スタンス検出:動的ターゲット生成とマルチターゲット適応
従来の立場検出はあらかじめ定義されたターゲットに依存していましたが、現実のソーシャルメディアではターゲットが動的で複雑であるため、未知のターゲットを自動特定し立場を判定する新タスク「DGTA」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の立場検出はあらかじめ定義されたターゲットに依存していましたが、現実のソーシャルメディアではターゲットが動的で複雑であるため、未知のターゲットを自動特定し立場を判定する新タスク「DGTA」が提案されました。
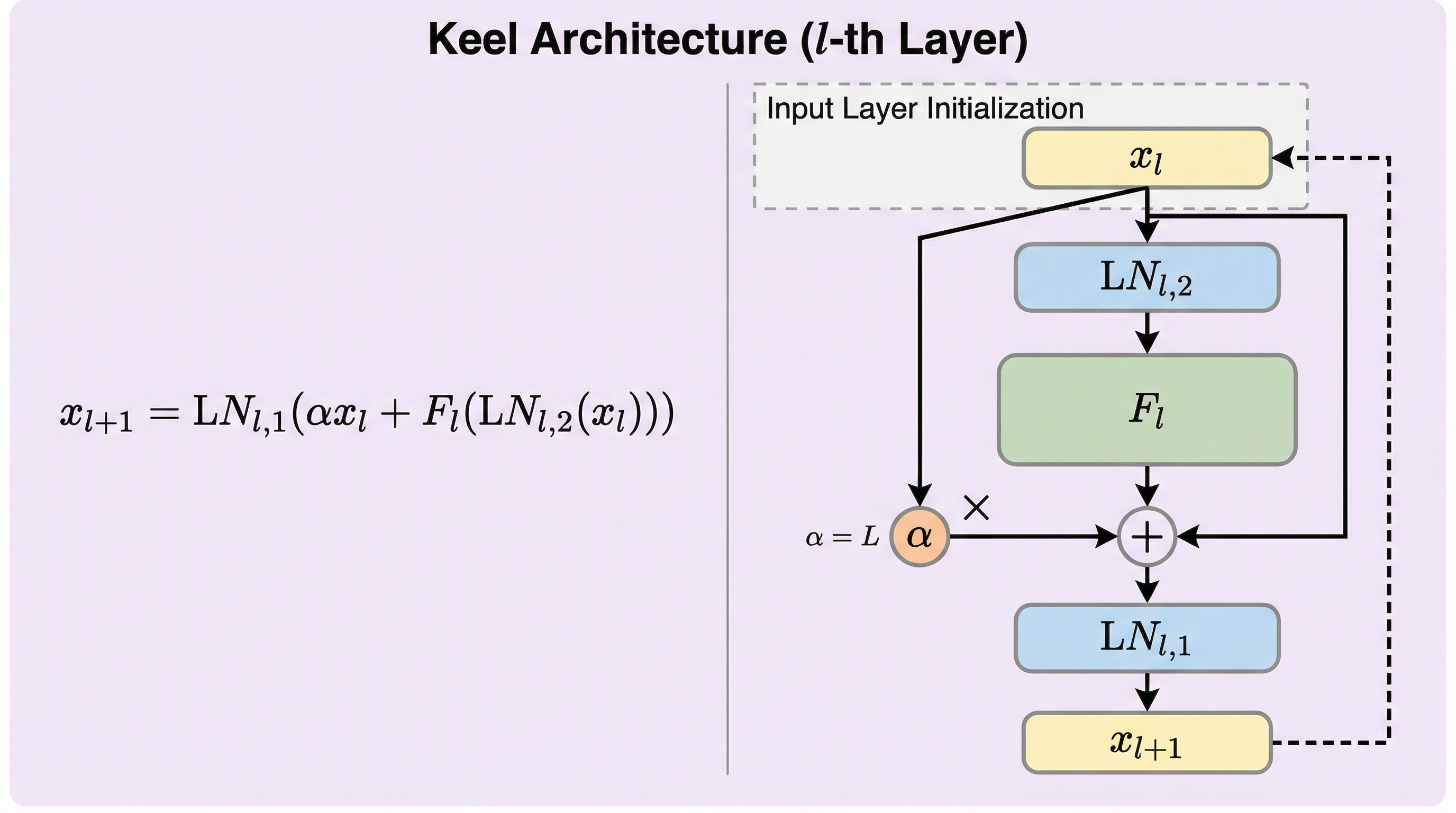
大規模言語モデル(LLM)のスケーリングが限界に達しつつある中、従来のPre-LayerNormに代わり、高い表現力を持つPost-LayerNormを改善した新アーキテクチャ「Keel」が提案されました。
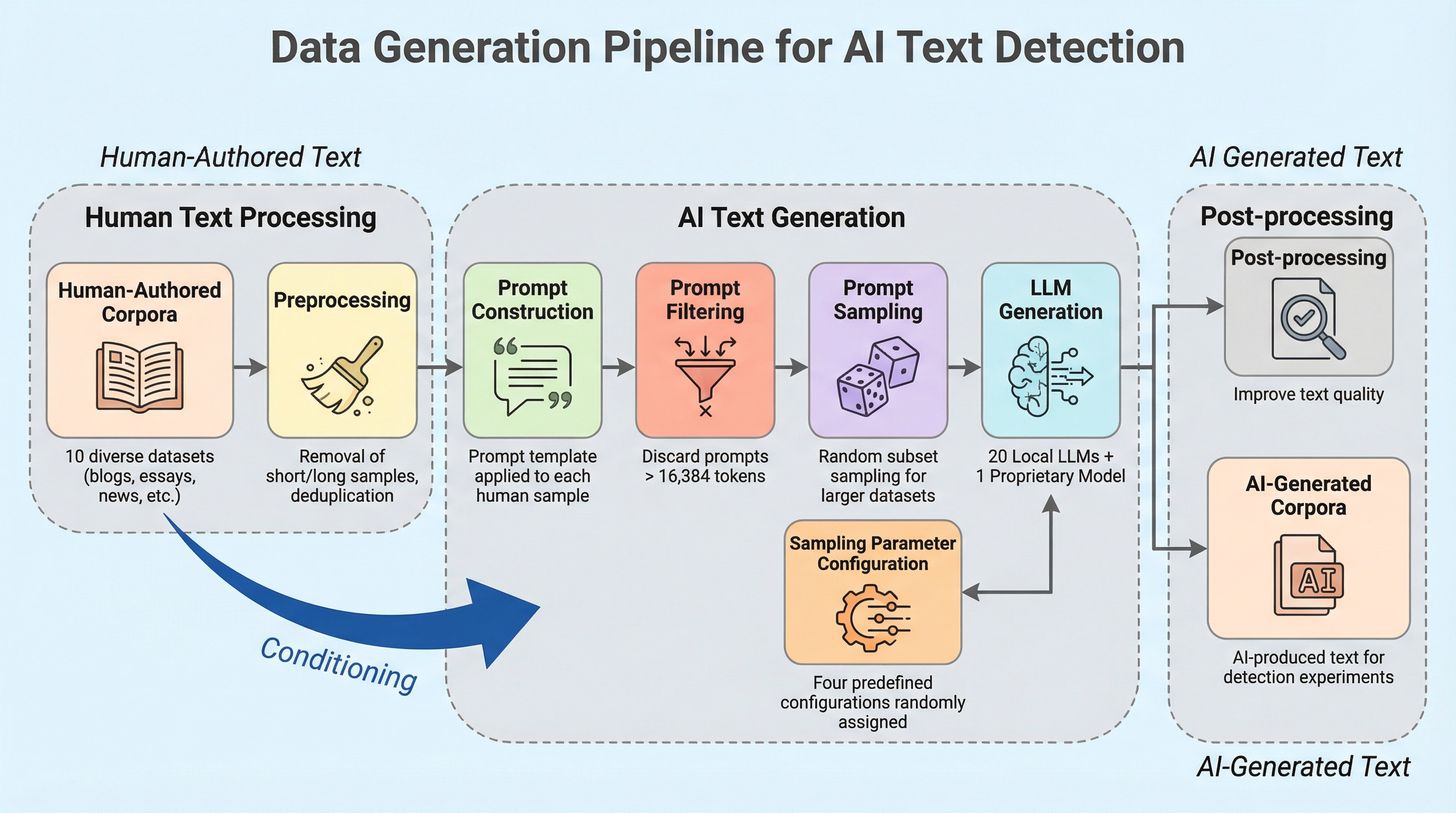
人間が書いた10億トークンの著作物と、21種類の言語モデルから生成された19億トークンのテキストを組み合わせた、合計29億トークンに及ぶ大規模なコーパスを構築し、AI生成テキストを識別するための新しい学習手法を提案した。
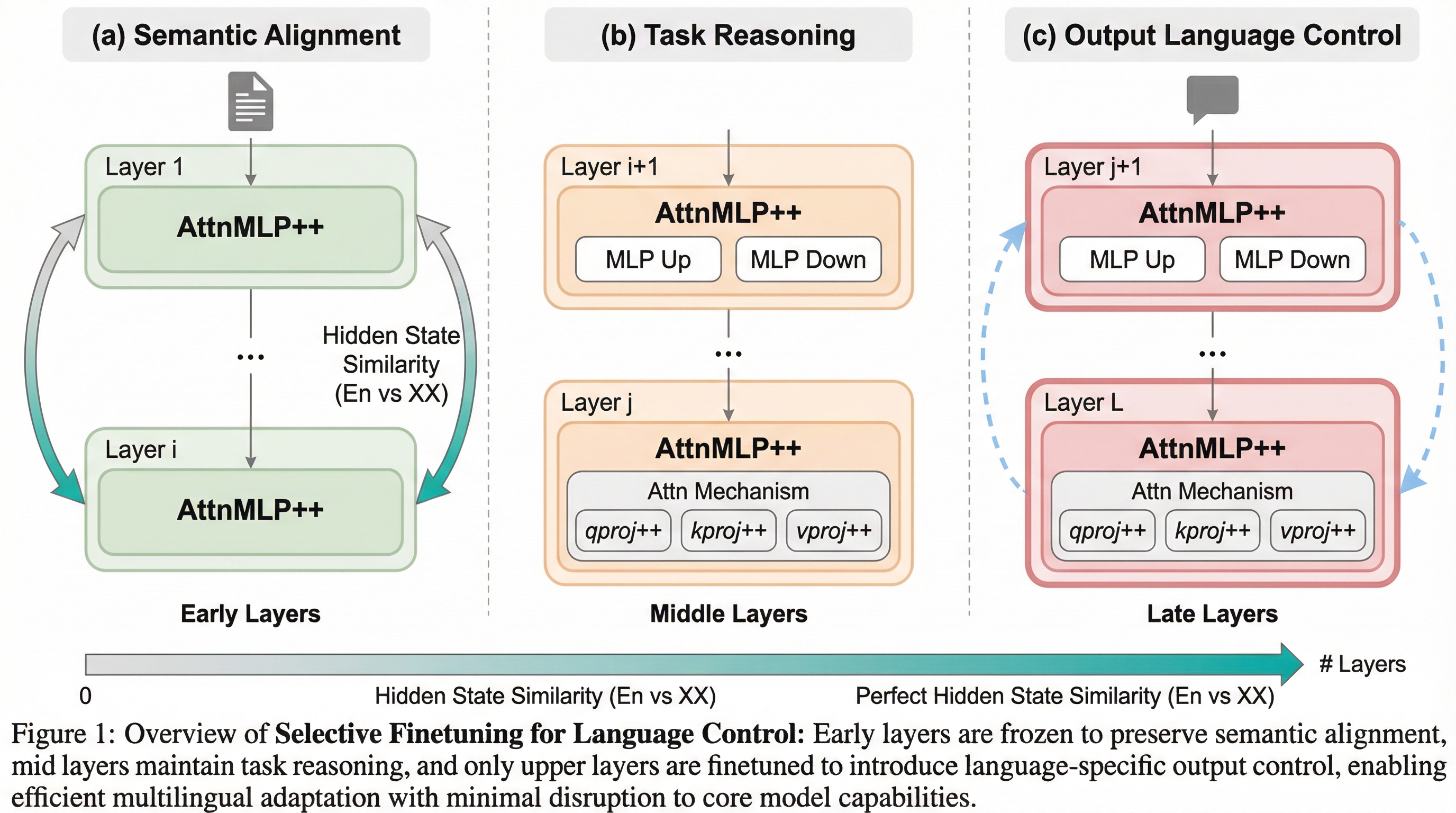
多言語大規模言語モデルが直面する「回答は正しいが出力言語を誤る」という言語一貫性の欠如と、「言語は正しいがタスクに失敗する」という多言語転送の停滞という二つの主要なボトルネックを特定し、モデル内部の層が「初期の意味整合」「中間のタスク推論」「終盤の言語制御」という明確な三段階の機能構造を持つことを解明しました。
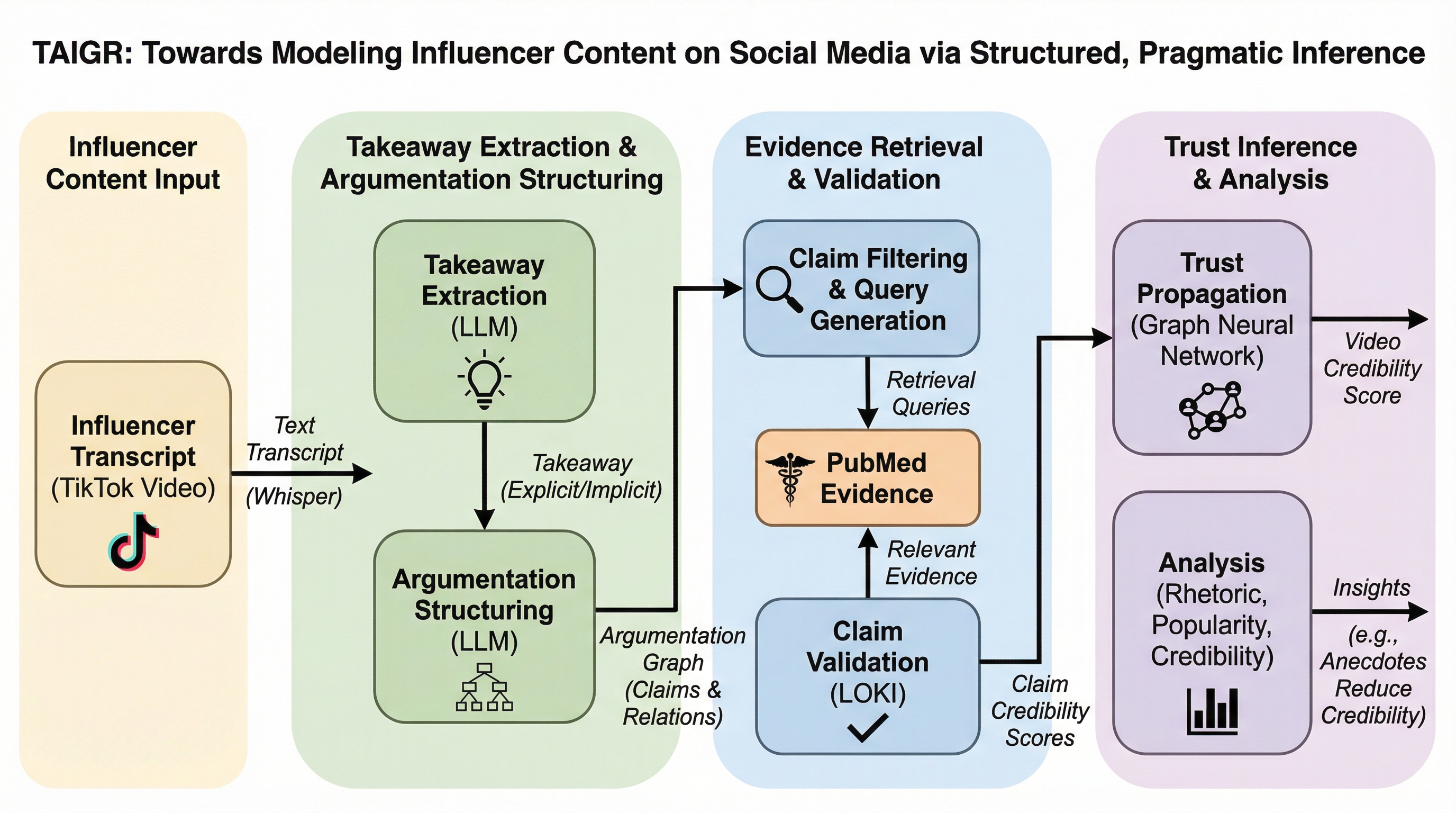
健康分野のインフルエンサーは、事実の断定よりも個人的な物語や修辞的戦略を多用するため、従来の「主張」単位の検証では、視聴者が受け取る真の意図(テイクアウェイ)を正確に評価できないという課題がある。
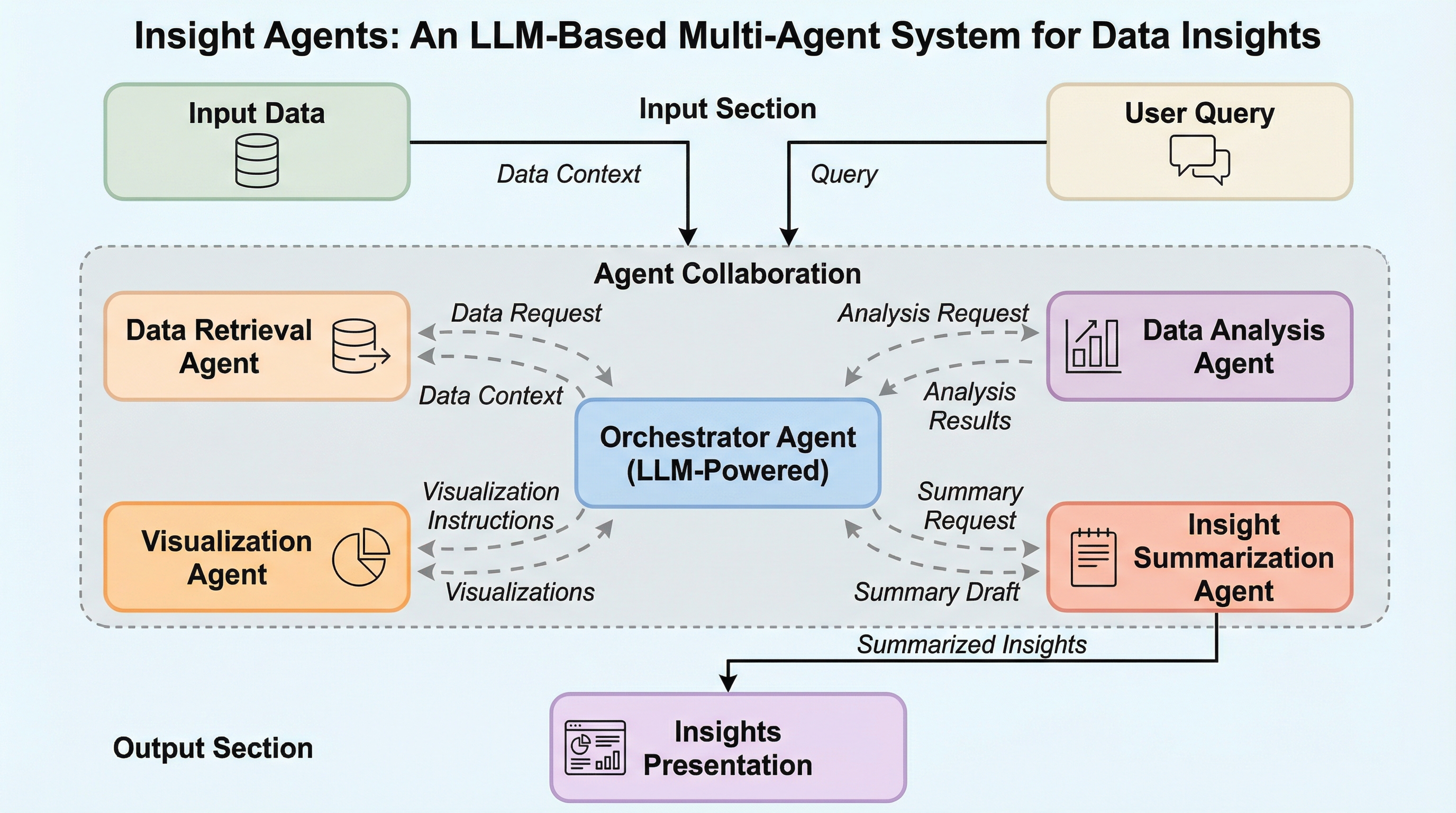
現代のEコマース出品者が直面する膨大なデータと複雑な分析ツールの活用障壁を解消するため、LLMを活用した会話型マルチエージェントシステム「Insight Agents(IA)」を開発し、出品者が自身のデータと対話することで迅速な意思決定を行える環境を構築しました。
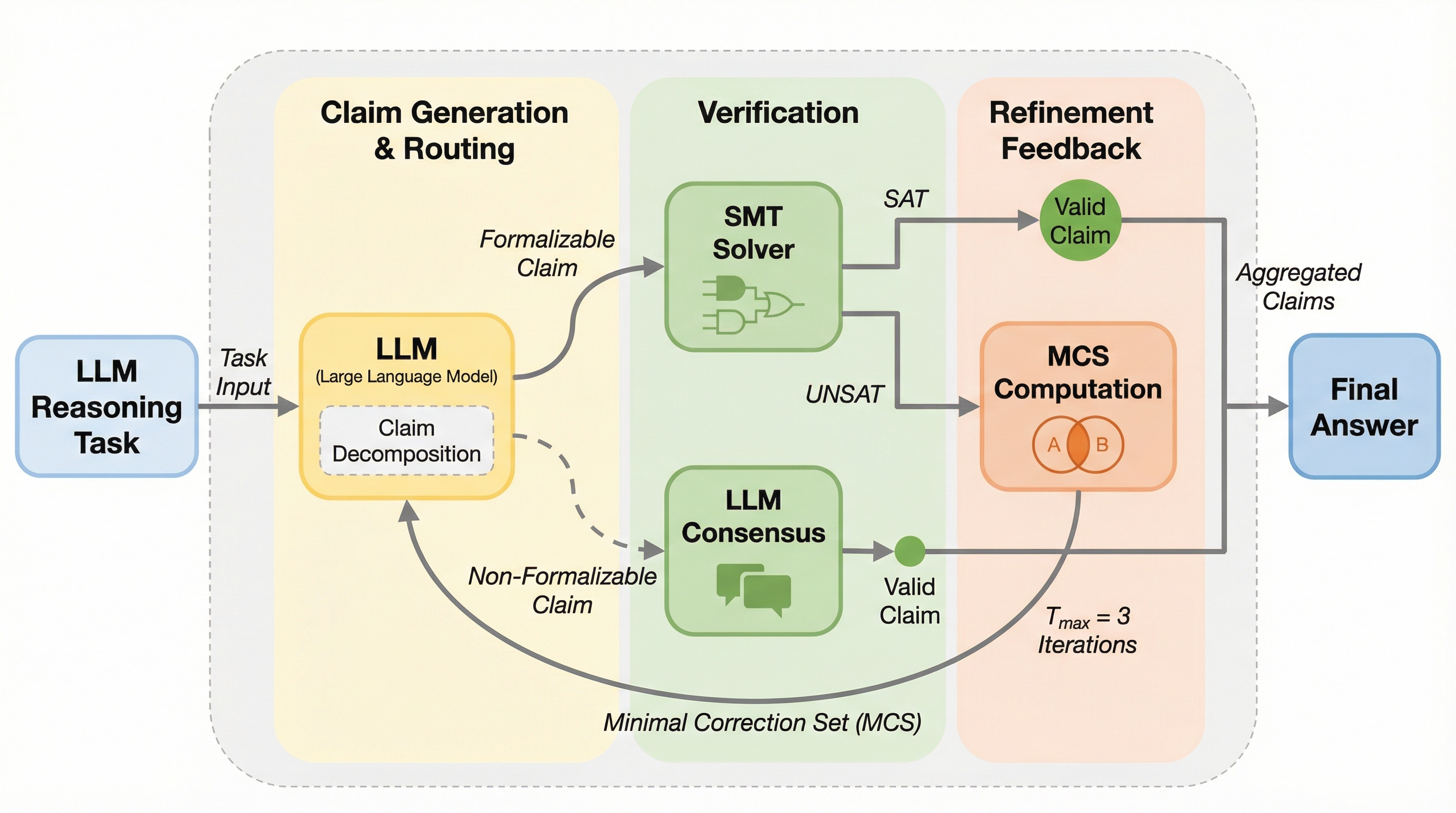
大規模言語モデル(LLM)の論理的正確性を保証するため、LLMとSMTソルバーを統合し、反復的な洗練を通じて検証済みの回答を生成する神経記号的フレームワーク「VERGE」が提案されました。 このシステムは、出力を原子的な主張に分解し、論理的な内容は記号ソルバーで、常識的な内容はLLMアンサンブルで検証するセマンティックルーティングと、最小修正サブセット(MCS)によるエラー箇所の特定を導入しています。 検証の結果、GPT-OSS-120Bモデルにおいて、従来のシングルパス手法と比較して平均18.7%の性能向上が確認され、特に法的な推論や複雑な論理問題において、形式的な検証がハルシネーションの抑制に大きく寄与することが示されました。
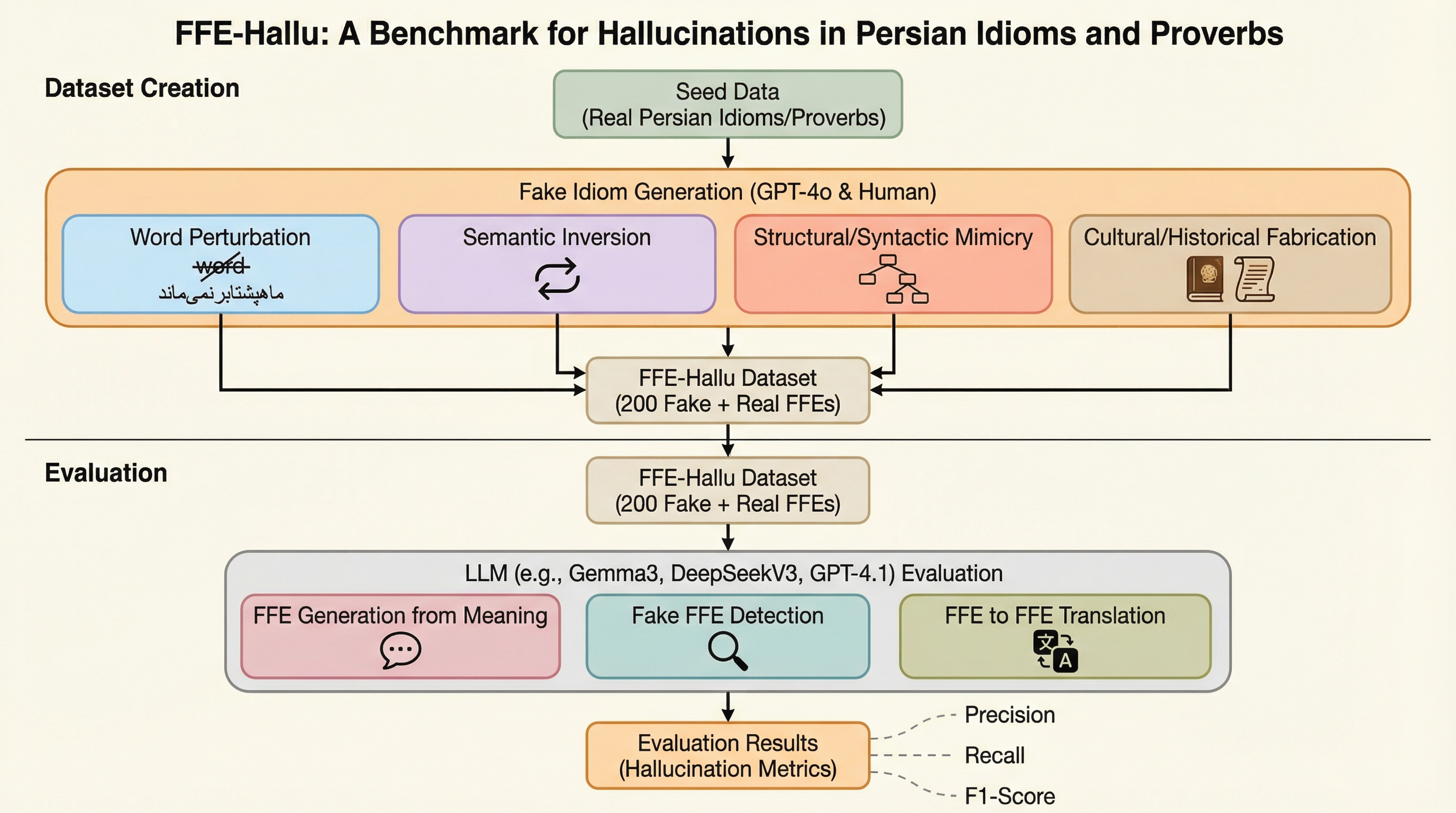
大規模言語モデル(LLM)が、慣用句やことわざなどの固定比喩表現(FFE)において、実在しないがもっともらしく聞こえる表現を生成・承認してしまう「比喩的ハルシネーション」の問題を定義し、その評価のための初の包括的ベンチマークであるFFE-HALLUを提案した。
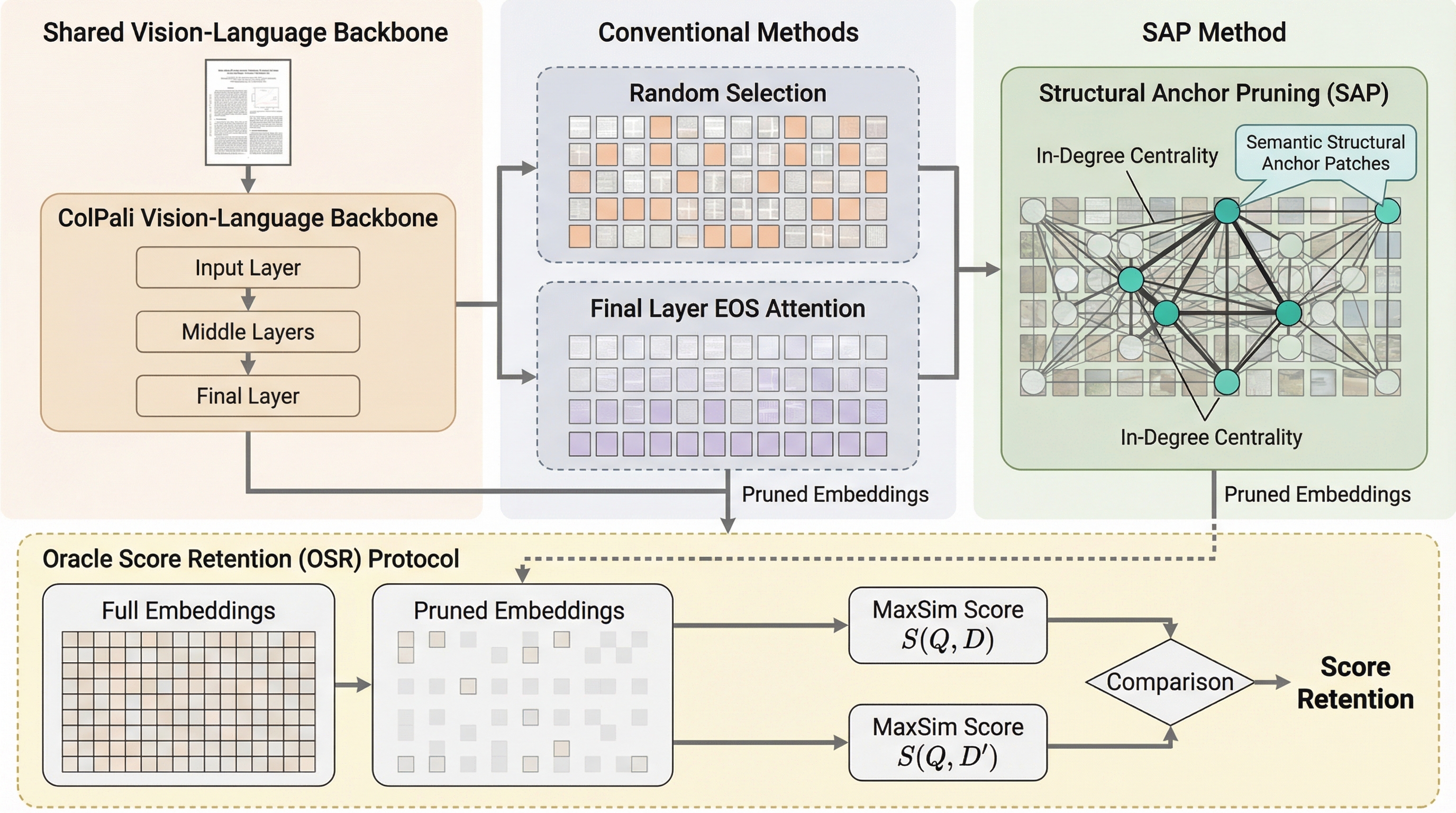
Visual RAGの普及を阻む最大の課題であるインデックスサイズの巨大化に対し、追加学習を一切必要とせず、検索精度を維持したままベクトル量を90%以上削減する画期的なプルーニング手法「Structural Anchor Pruning(SAP)」を提案した。
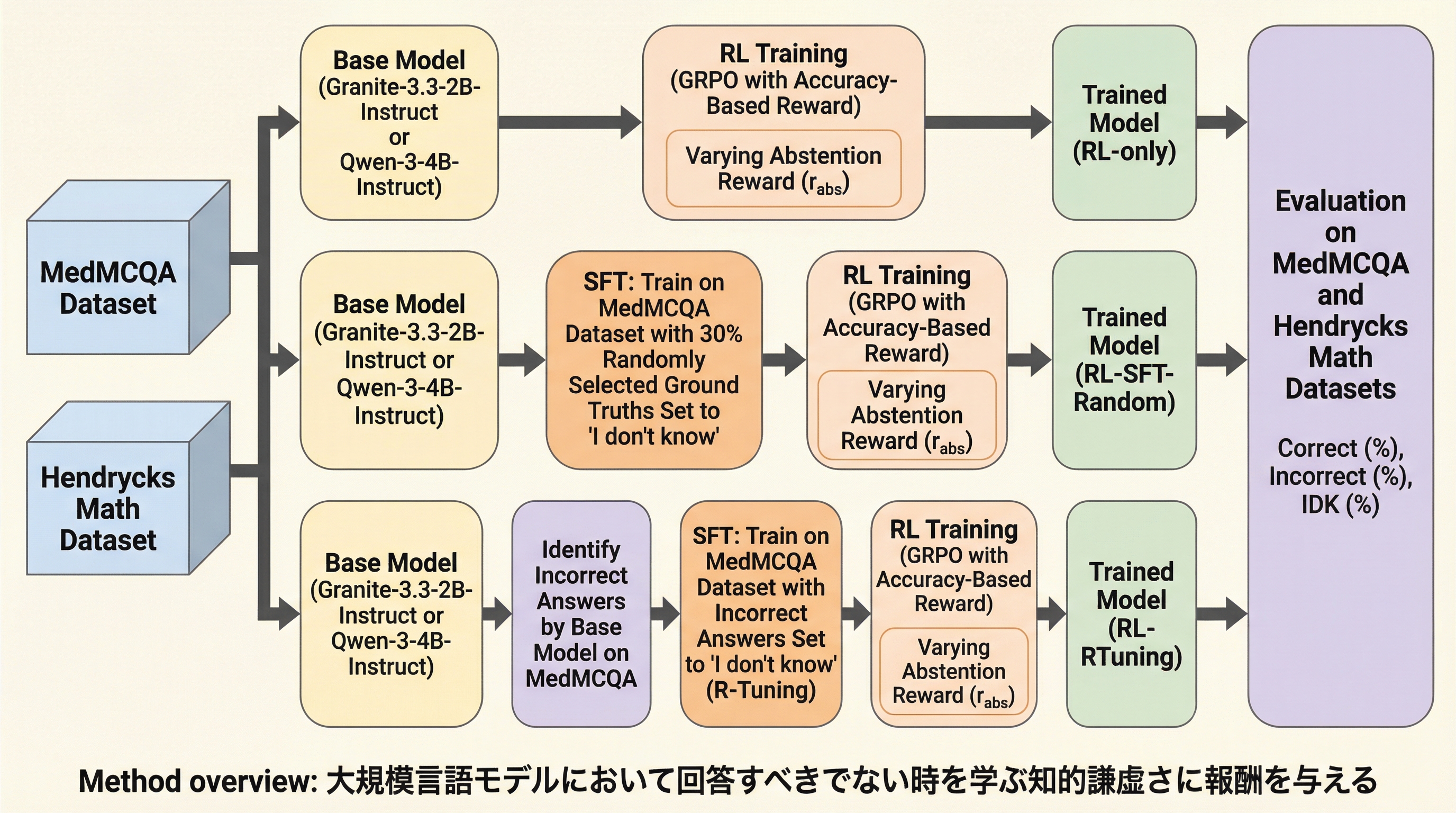
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーションを抑制するため、正解には正の報酬、不正解には負の報酬、そして「分からない」という棄権回答には特定の報酬($r_{abs}$)を与える「検証可能な報酬による強化学習(RLVR)」という枠組みを導入し、モデルに知的謙虚さを学習させた。