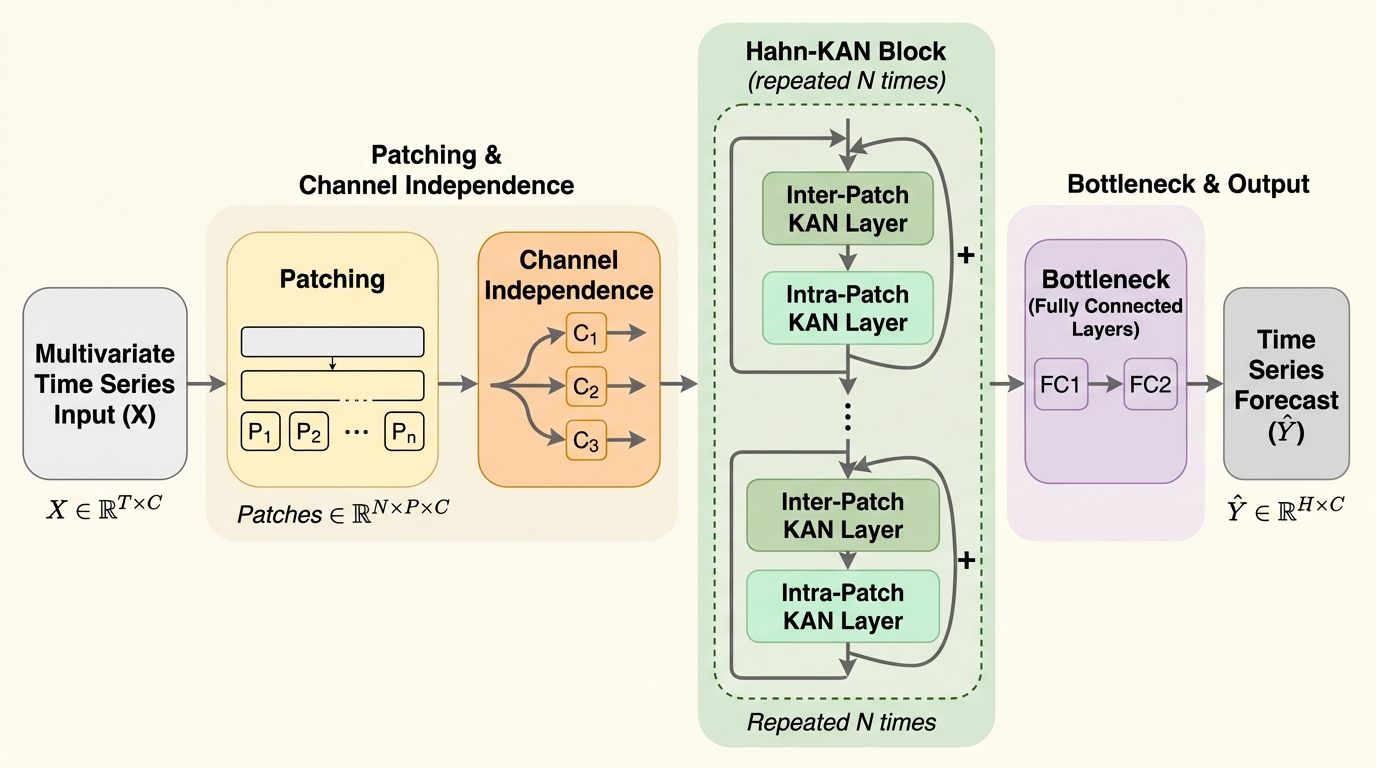
ハーン・コルモゴロフ・アーノルド・ネットワークを用いた時系列予測
従来の時系列予測で主流だったTransformerの計算量の多さや、MLPが抱える高周波成分の学習の苦手さ(スペクトルバイアス)を解決するため、Hahn多項式を学習可能な活性化関数として組み込んだ新しいネットワーク構造「HaKAN」が開発されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の時系列予測で主流だったTransformerの計算量の多さや、MLPが抱える高周波成分の学習の苦手さ(スペクトルバイアス)を解決するため、Hahn多項式を学習可能な活性化関数として組み込んだ新しいネットワーク構造「HaKAN」が開発されました。
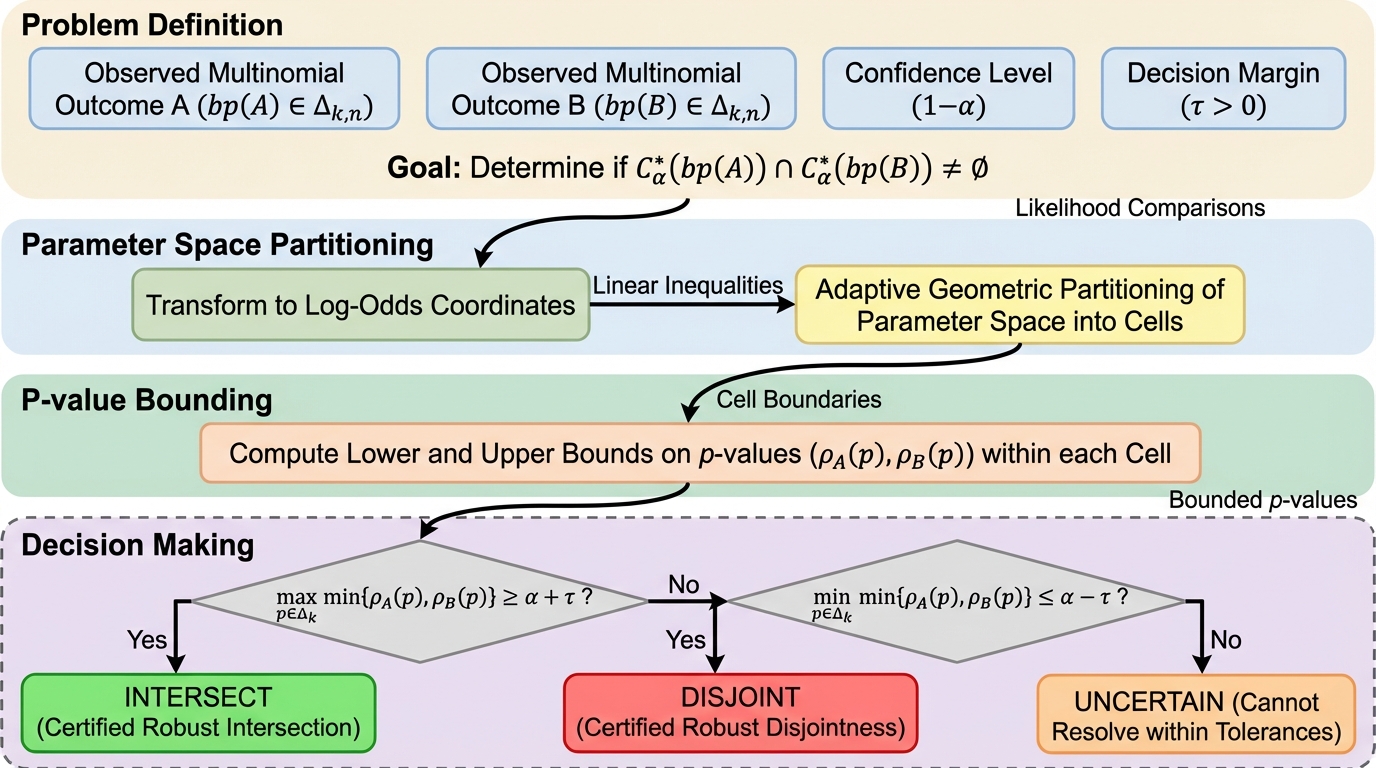
多項分布のパラメータ推定において、統計的に最適な最小体積信頼集合(MVC)は、その幾何学的形状が複雑で不連続であるため、実用的な計算が困難という課題がありました。 本研究は、対数オッズ座標系を用いることで尤度の順序関係を半空間の制約として捉え、適応的な幾何学的分割によって二つの観測結果の信頼集合が交差するかを厳密に判定するアルゴリズムを提案しました。 この手法は、従来の漸近近似では誤った結論を導きやすい小標本環境においても、交差、分離、または判定不能のいずれかを保証付きで出力し、A/Bテストや強化学習の精度向上に寄与します。
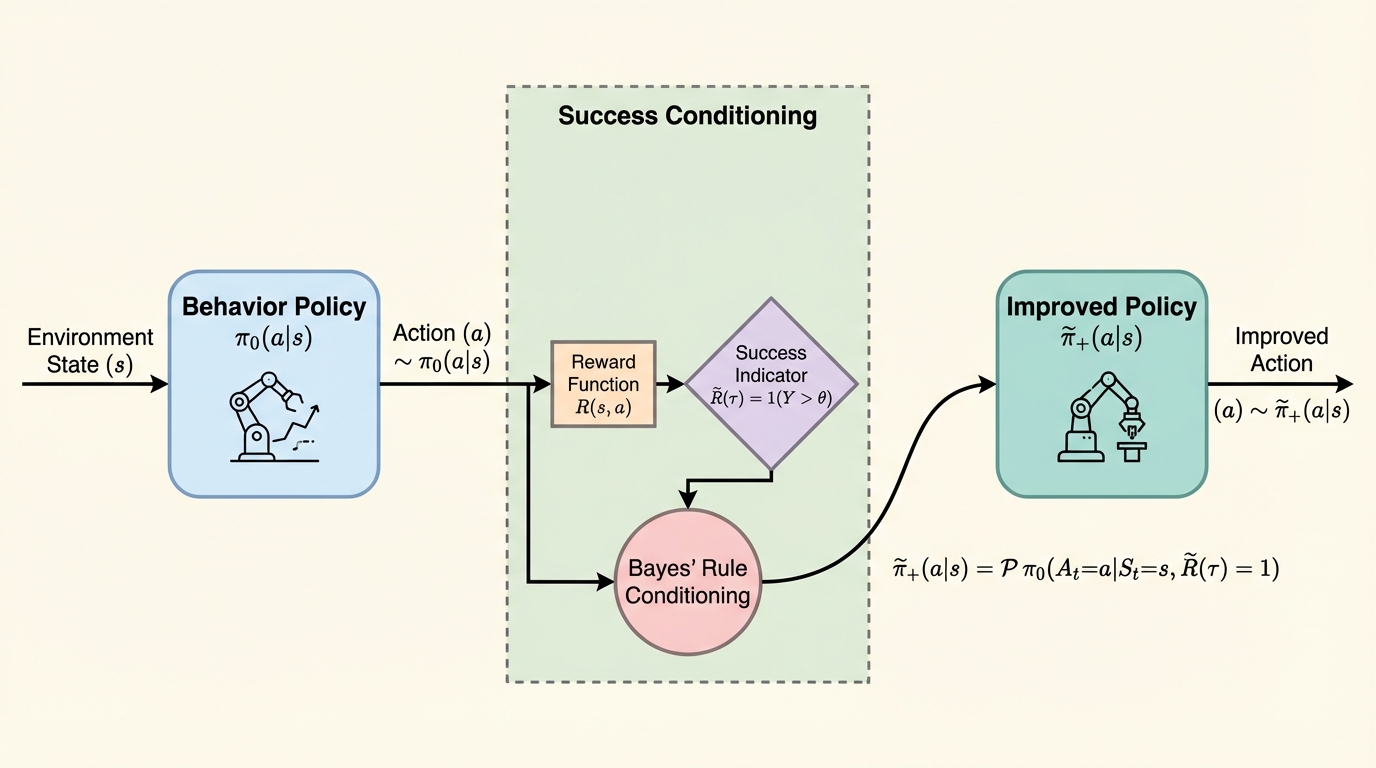
成功条件付け(成功した軌跡を模倣する手法)は、LLMの調整や強化学習で広く使われていますが、その理論的な最適化対象は不明でした。本論文は、この手法が$\chi^2$ダイバージェンスを制約とした信頼領域最適化問題を正確に解いていることを証明しました。
深層強化学習における自然方策勾配法(NPG)は、学習の収束が早く幾何学的に適切な更新が可能である一方、フィッシャー情報行列(FIM)の逆行列計算にパラメータ数の3乗という膨大な計算コストがかかる点が実用上の大きな障壁となっていました。
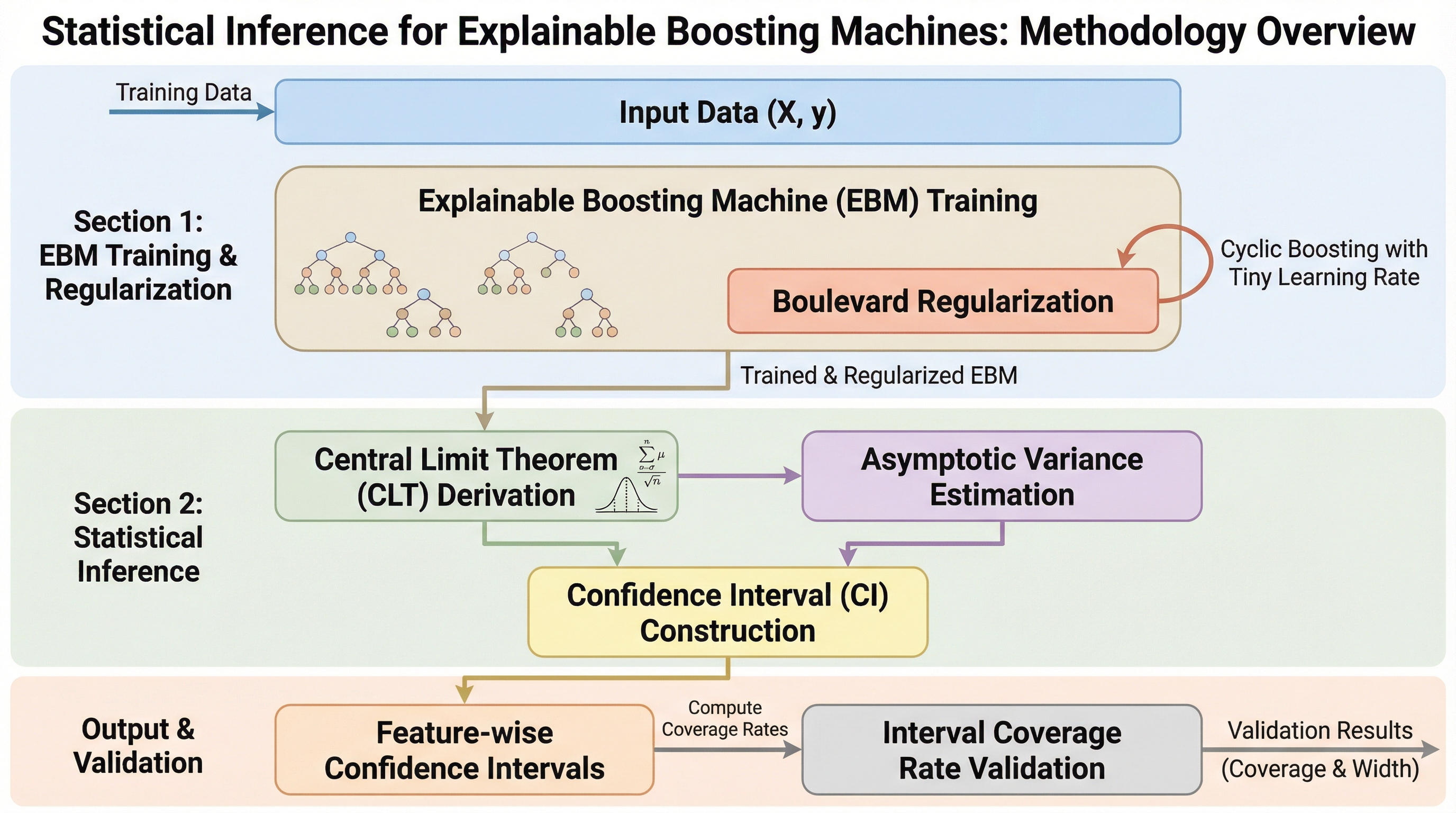
本研究は、解釈性の高い「グラスボックス」モデルである説明可能なブースティングマシン(EBM)に、移動平均を用いたブールバード正則化を導入することで、学習プロセスを特徴量ごとのカーネルリッジ回帰へと収束させる理論的枠組みを構築しました。
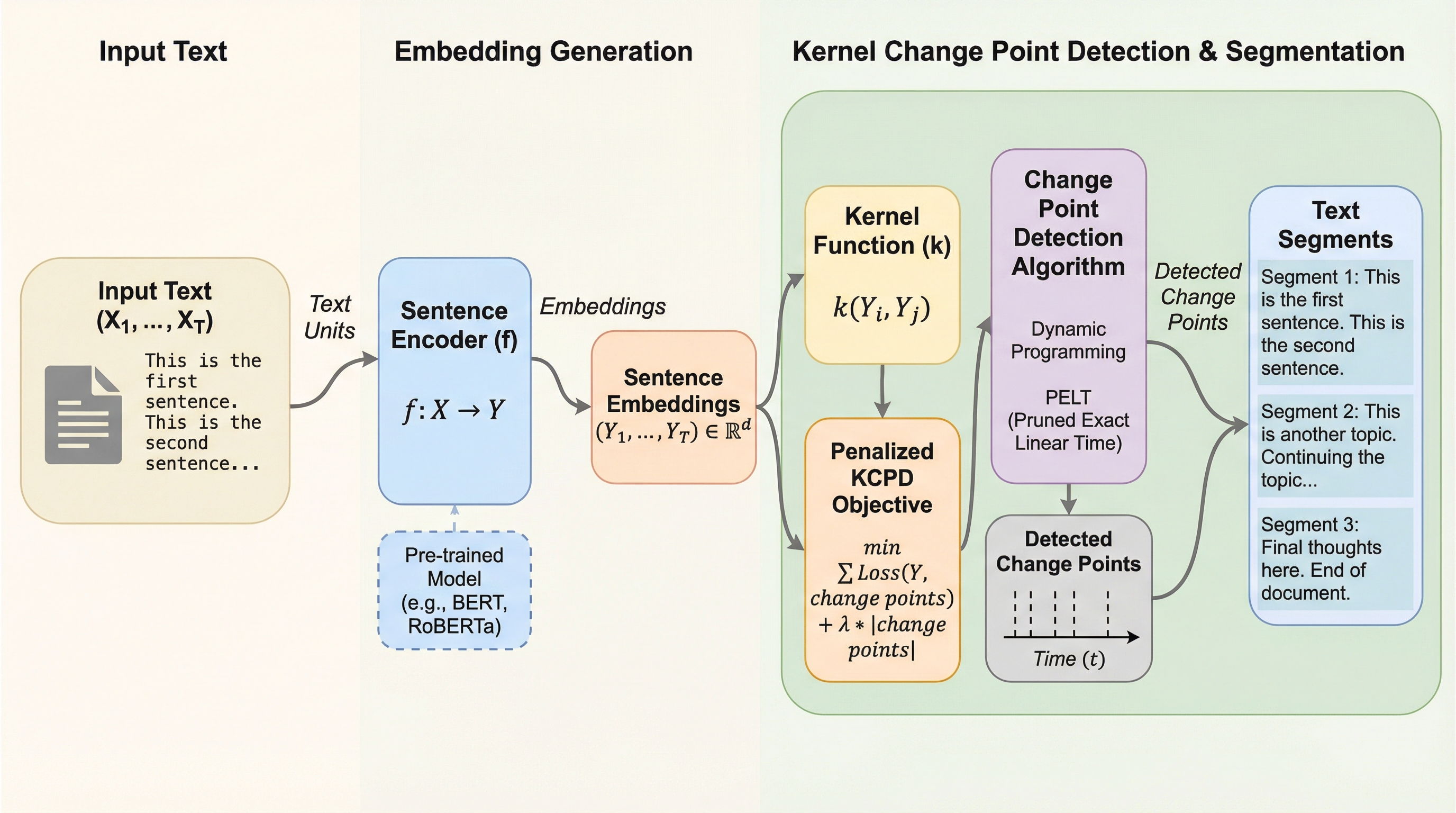
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。
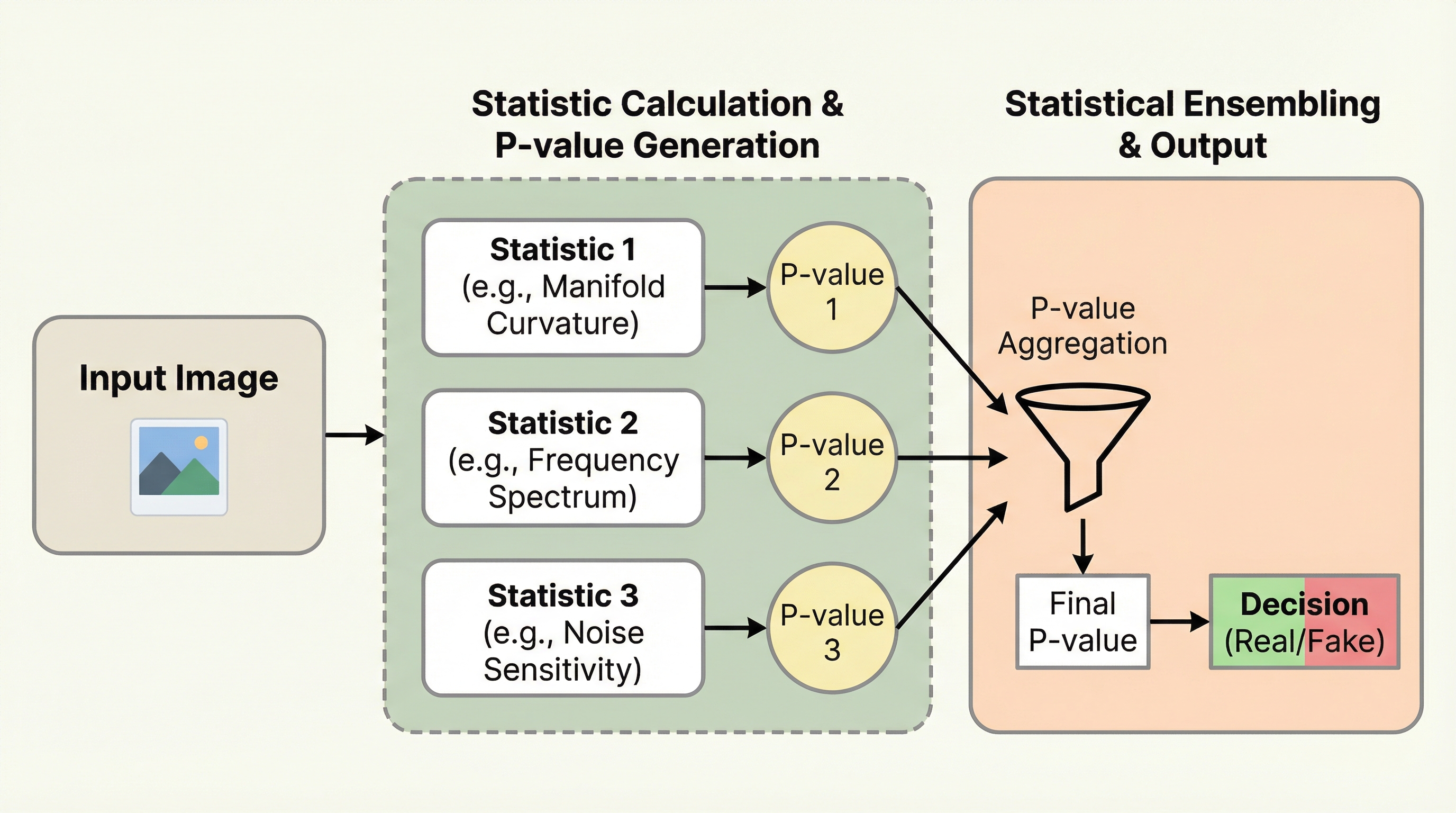
生成AIによる偽画像検出において、未知の生成モデルへの適応性と判定結果の解釈性を両立させるため、実画像のみを利用する統計的枠組み「RealStats」が提案されました。 この手法は、複数の既存検出器から得られる統計量を実画像の分布に基づいた「p値」へと変換し、それらを厳密な統計的手法で統合することで、対象画像が実画像の分布からどれだけ逸脱しているかを確率的に評価します。 学習に偽画像を一切必要としないため、進化し続ける新しい生成モデルに対しても頑健であり、出力されるスコアは「その画像が実画像である確率」として統計的に明確な意味を持つため、信頼性の高い判定を実現しています。
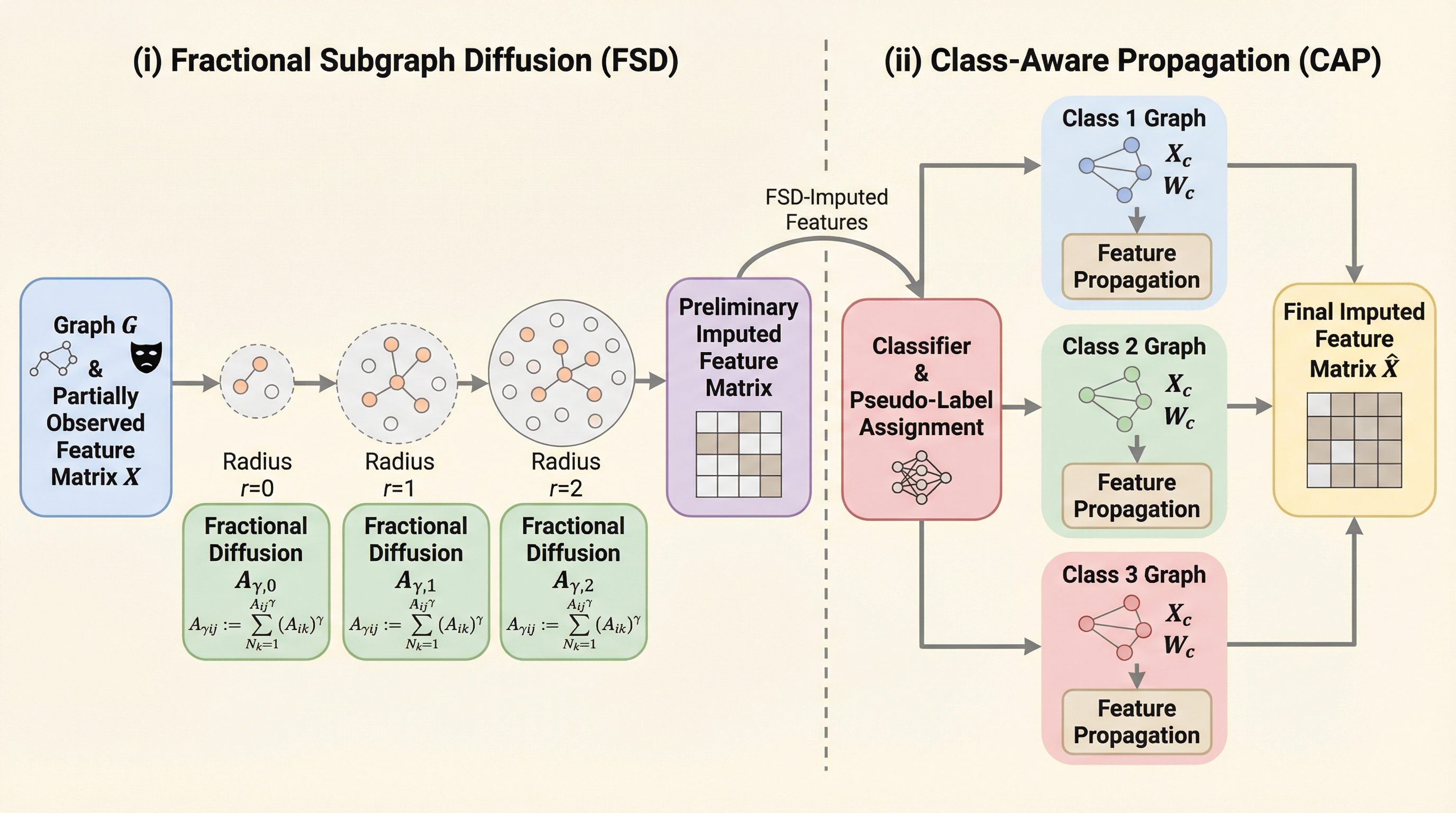
FSD-CAPは、ノード特徴量の99.5%が欠損しているという極限状態のグラフデータにおいて、全データが揃っている状態に匹敵する精度で特徴量を復元・補完する新しい学習フレームワークである。 局所的なグラフ構造に応じて情報の伝播強度を調整する「分数拡散オペレータ」と、観測済みノードから段階的に探索範囲を広げる「部分的サブグラフ拡張」を組み合わせることで、広域拡散による誤差の蓄積を抑えつつ、安定した特徴量推定を可能にしている。 さらに、推定された特徴量から得られる疑似ラベルと近傍のラベル一貫性(エントロピー)を利用した「クラス認識型伝播」を導入することで、クラス内の整合性を高め、ノード分類やリンク予測といった下流タスクにおいて既存手法を圧倒する性能を達成した。
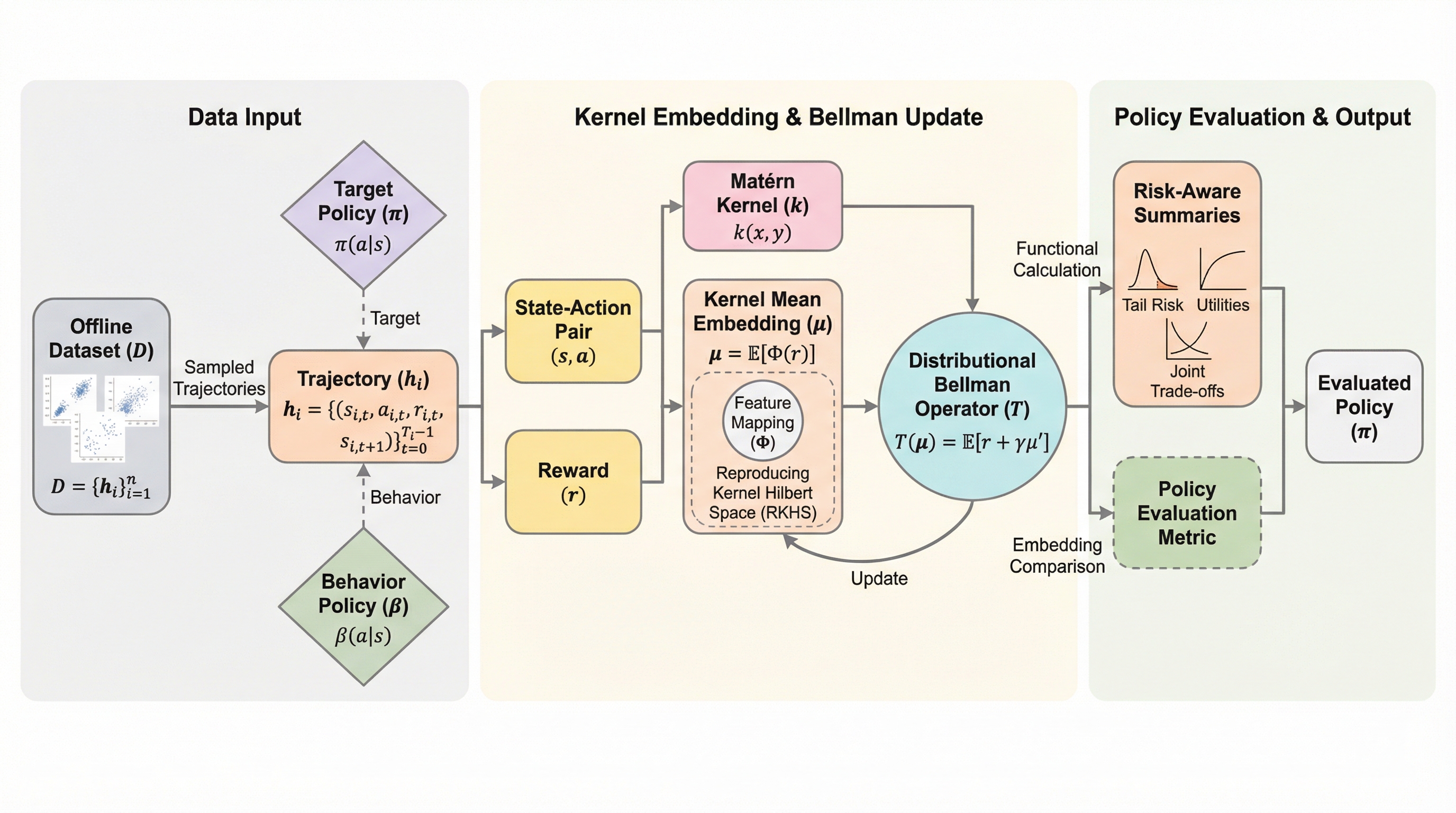
本研究は、多次元の報酬指標と連続的な状態行動空間を扱うオフライン強化学習において、将来的なリターン分布を精度高く推定する新フレームワーク「KE-DRL」を提案している。 従来の分布型強化学習で主流だったワッサースタイン距離は、高次元空間での計算コスト増大と統計的不安定性が課題であったが、再生核ヒルベルト空間への埋め込みとマテルン核を用いた積分確率指標を導入することで、この問題を理論的かつ計算的に解決した。 数学的な解析により分布型ベルマン作用素の縮小性と一様収束性を証明するとともに、エクスペディアのホテル検索データを用いた実証実験を通じて、テールリスクの評価や複数報酬間の複雑なトレードオフを考慮した意思決定における実用的な有効性を明らかにした。
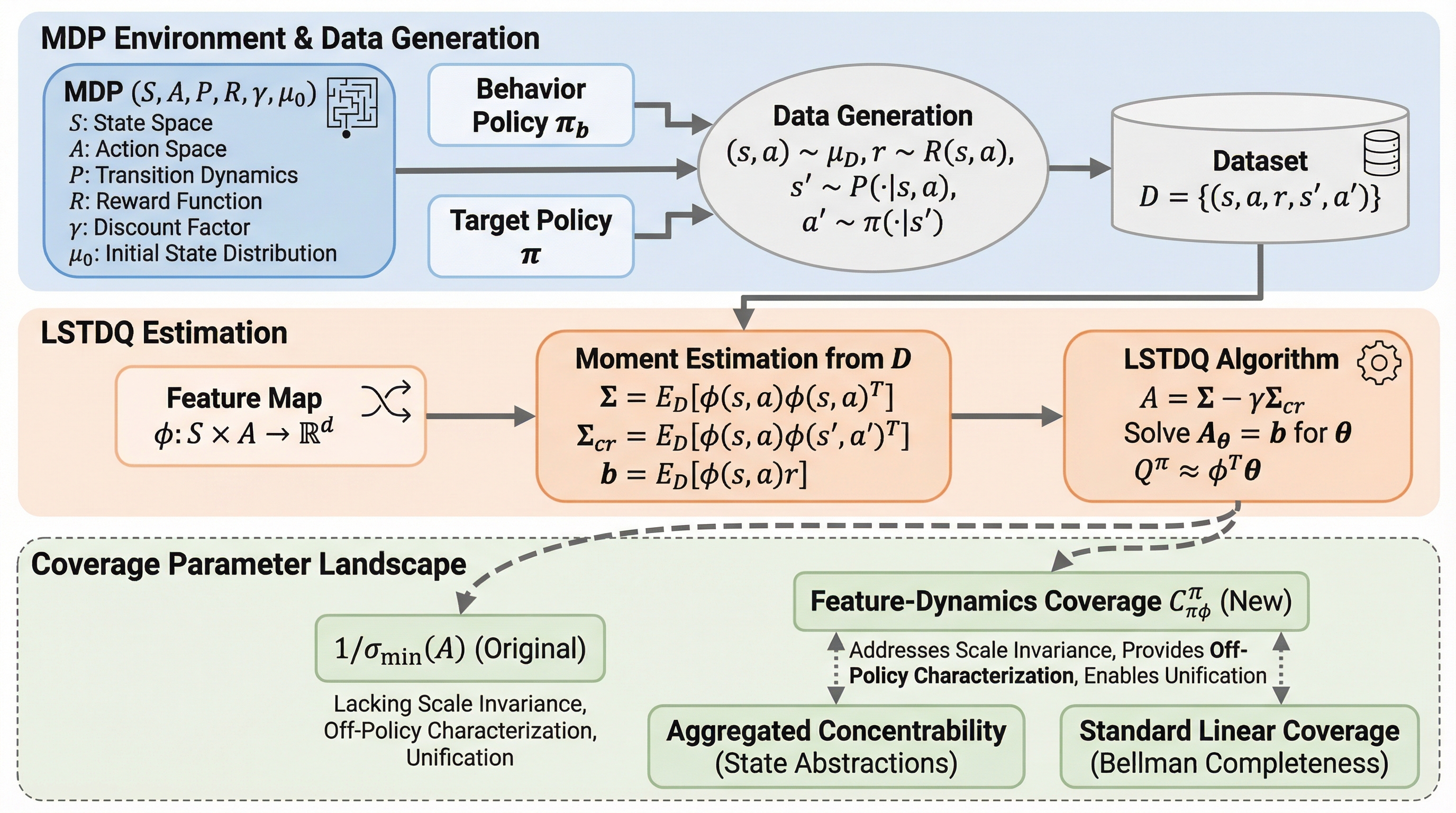
強化学習のオフポリシー評価(OPE)において、データの質を規定する「カバレッジ」の概念は、線形関数近似の設定では定義が断片的であり、従来の最小特異値に基づく指標は尺度不変性の欠如やオフポリシー設定での解釈の難しさといった課題を抱えていたが、本研究は統計学の操作変数法の視点から「特徴量ダイナミクス・カバレッジ」という新指標を提案した。 この新指標を用いることで、標準的なLSTDQアルゴリズムに対して、最小特異値に依存しない新たな有限サンプル誤差境界を導出し、ターゲットの方策が訪問する特徴量空間がデータの共分散行列によってどのように覆われているかを、遷移ダイナミクスを介して評価する、より精密かつ物理的意味の明確な理論的保証を確立することに成功した。 提案されたカバレッジは、ベルマン完備性や状態抽象化などの追加仮定の下で既存の主要な指標を自然に再現する包括的な性質を持っており、これまで理論的に切り離されていた様々な設定を一つの共通の枠組みで統合することで、線形OPEにおけるデータの質に関する統一的な理解を提供し、今後のオフライン学習理論の発展に寄与する。