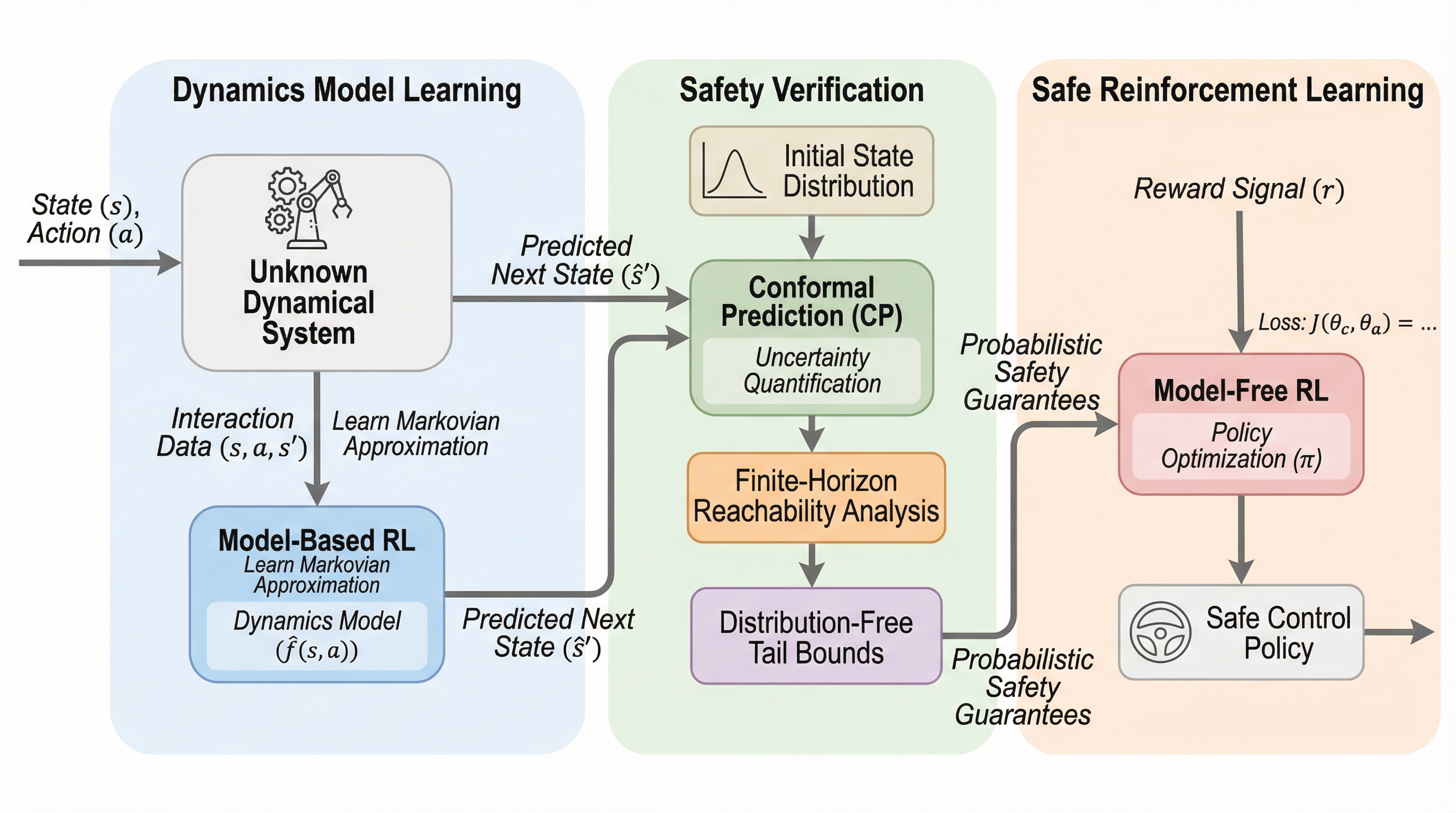
未知環境における安全な制御のためのコンフォーマル到達可能性
未知の力学系や確率的な環境下において、システムダイナミクスの完全な知識がなくても、数学的に厳密な「証明可能な安全性」を保証しながら制御を行う新しいフレームワーク「ReCORS」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
未知の力学系や確率的な環境下において、システムダイナミクスの完全な知識がなくても、数学的に厳密な「証明可能な安全性」を保証しながら制御を行う新しいフレームワーク「ReCORS」が提案されました。
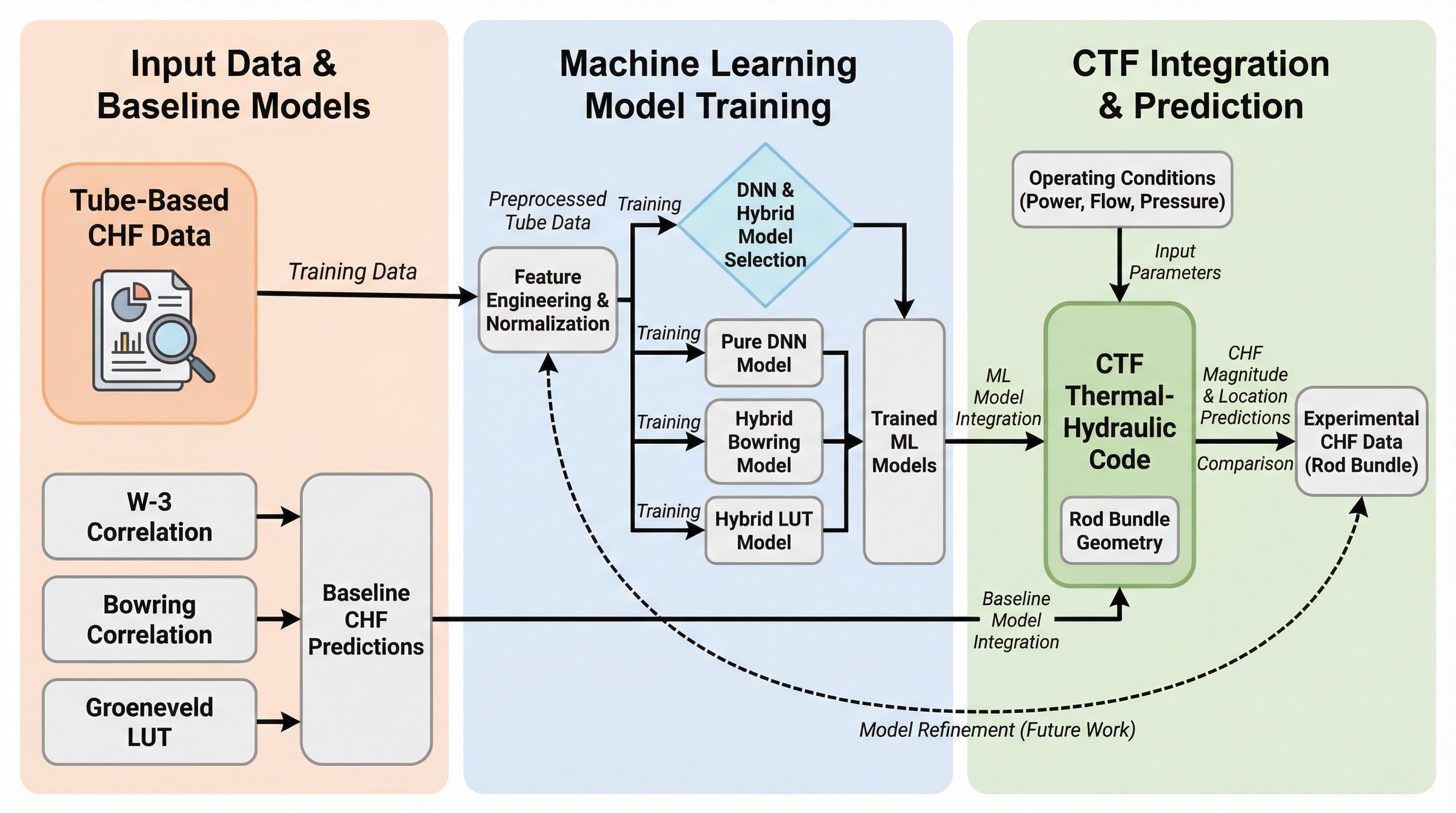
管(チューブ)で学習したモデルは、燃料棒が束になった「ロッドバンドル」でも通用するのか? 意外なのは、複雑さが一気に増えるのに「追加データが足りない」という現実が、手法の選び方だけでなく、“勝ち筋の描き方”そのものを変えさせる点です。
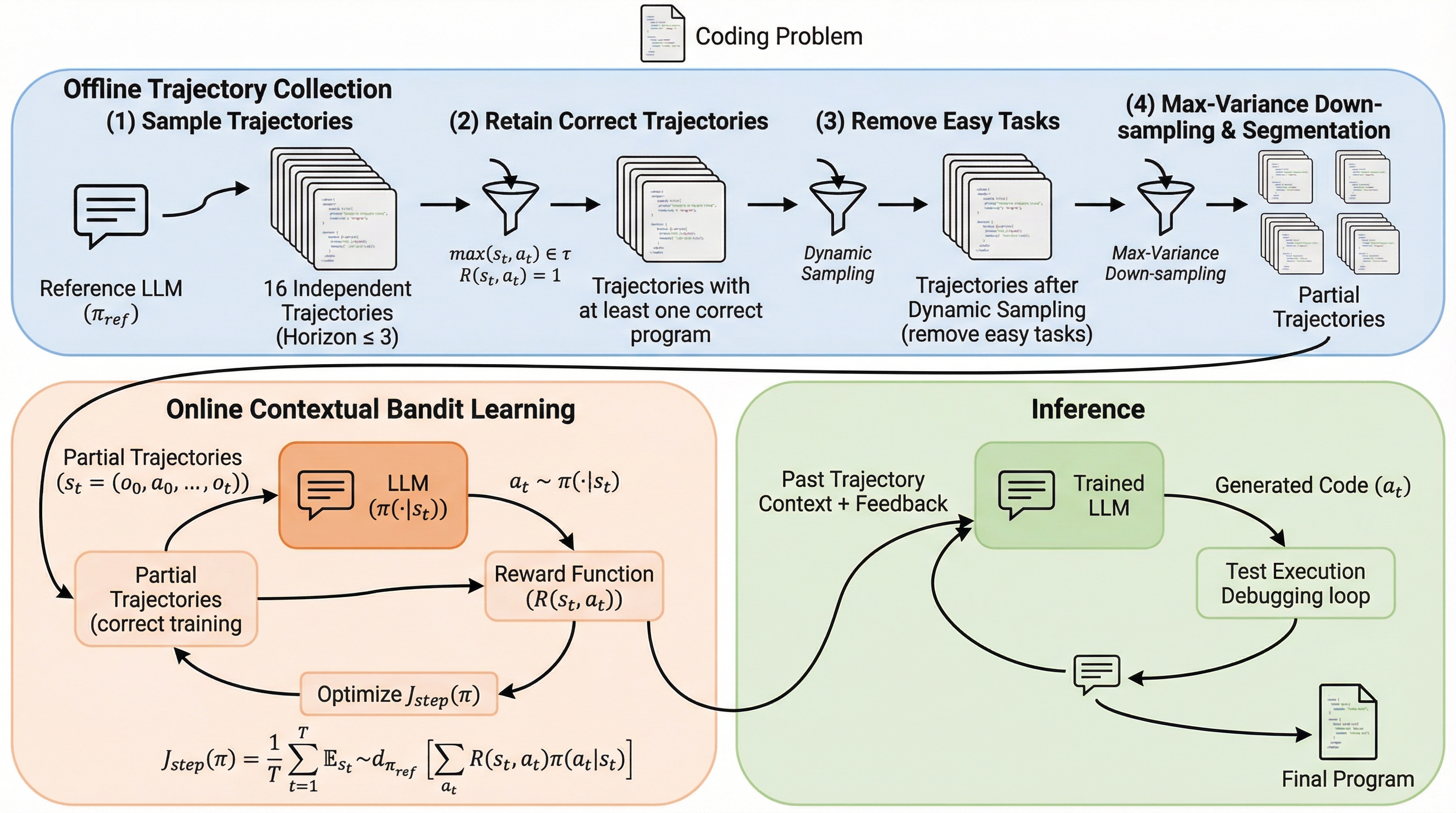
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。
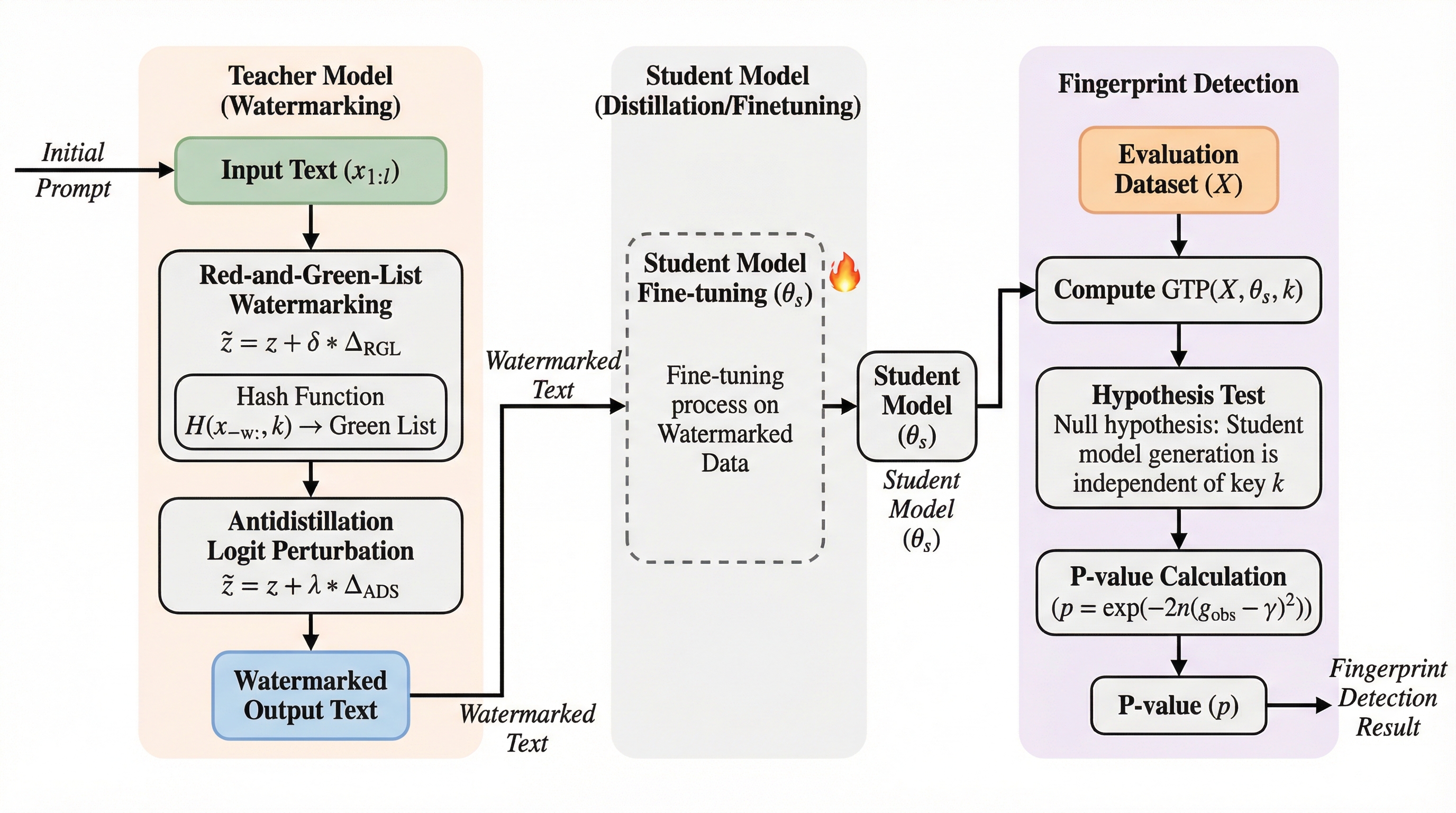
大規模言語モデル(LLM)の出力を無断で学習して模倣する「モデル蒸留」を検知するため、生徒モデルの学習力学に適合した信号を埋め込む新手法「ADFP」が提案されました。 従来のウォーターマーク手法は生成品質を大幅に低下させる課題がありましたが、ADFPはプロキシモデルを用いて検知可能性を最大化するトークンを動的に選択することで、品質維持と強力な検知能力を両立します。 数学的推論(GSM8K)や対話タスク(OASST1)の検証において、生徒モデルの構造が未知であっても、従来手法を凌駕する精度で蒸留の有無を判定できることが実証されました。
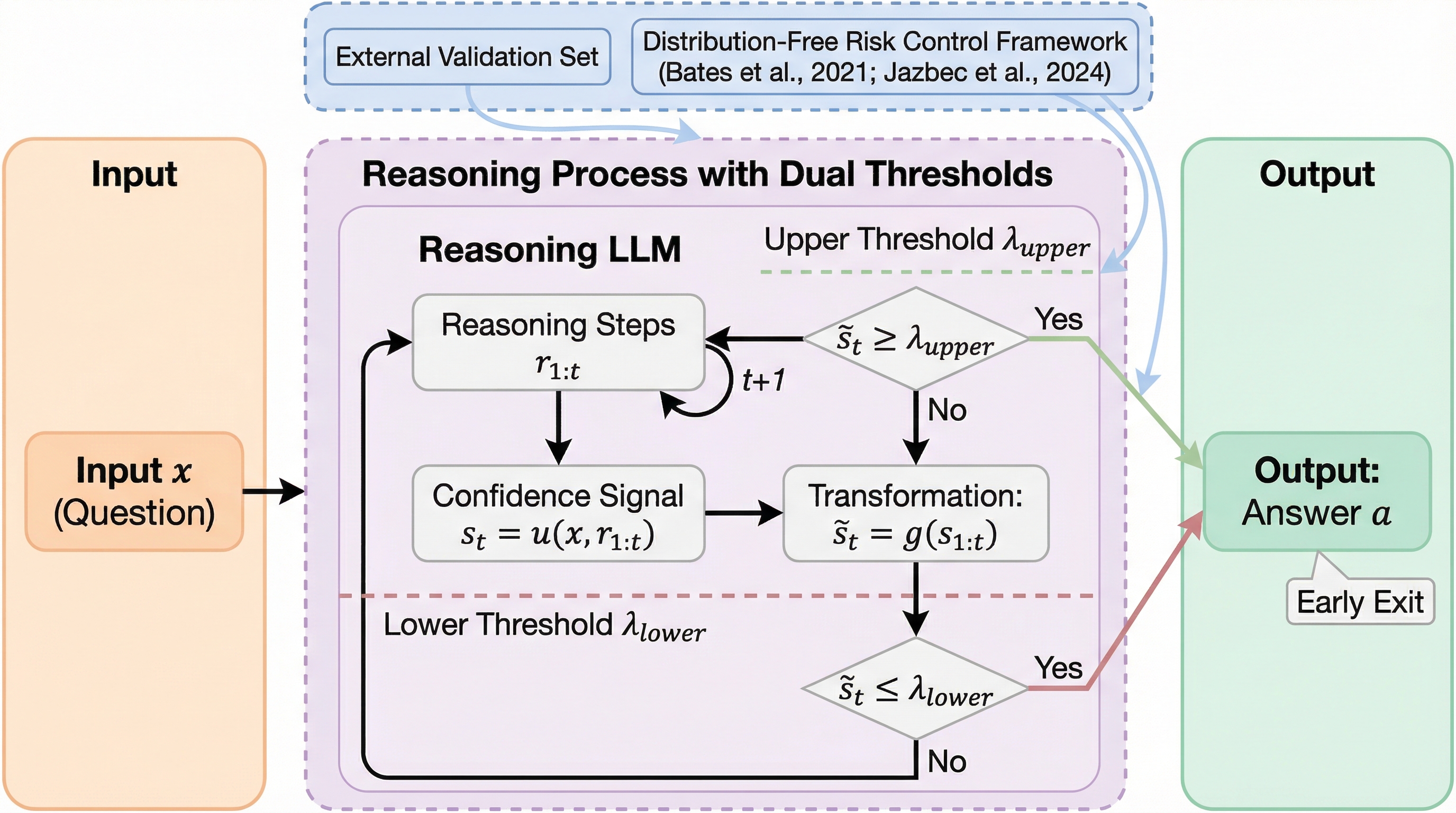
推論LLMは、どこまで考えさせれば“十分”なのでしょうか? 実は「トークン数を決める問題」は、しきい値を決める問題に姿を変えるだけで、悩みは残ります。 この記事では、計算予算の設定を“リスク(誤り率)制御”に言い換える論文の狙いと仕組みを追います。
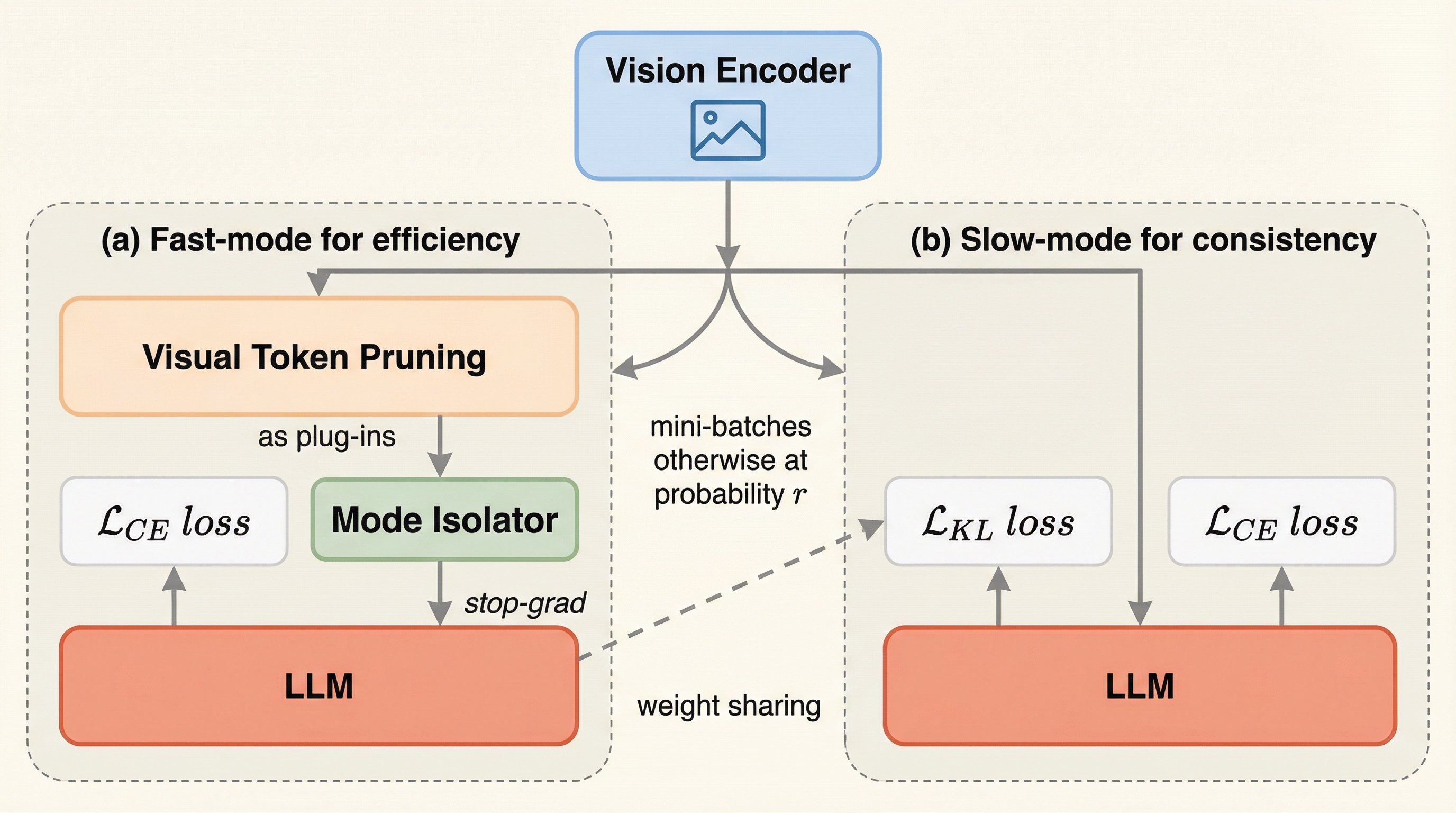
マルチモーダルLLMは、なぜ「学習」だけがこんなに重くなりがちなのでしょうか? 鍵はモデルの巨大さだけでなく、画像が生む“視覚トークンの多さ”にあります。 とはいえ、ただ削れば速くなる一方で、推論の場面で別の問題が噴き出す——そこが話を難しくします。
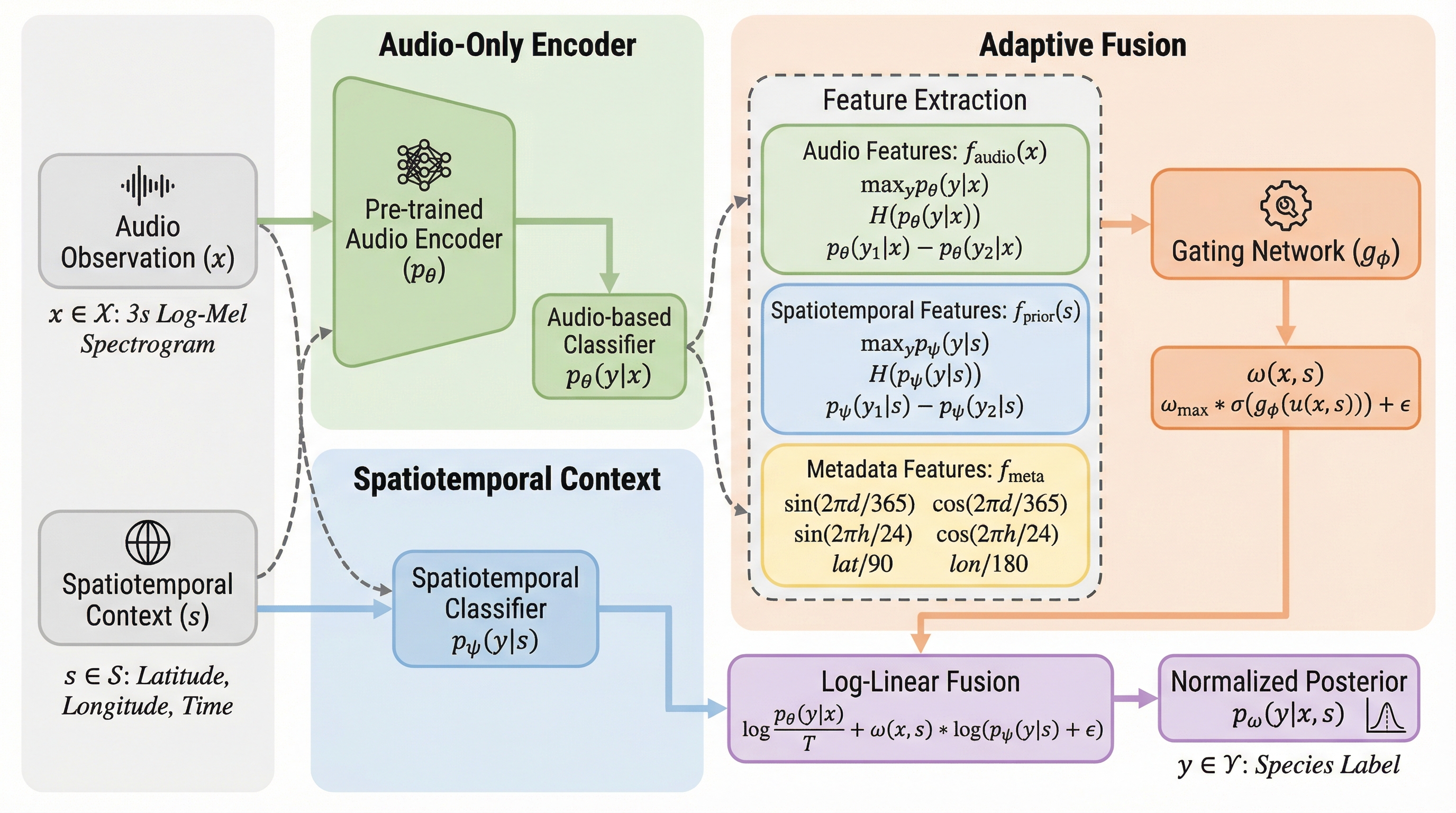
同じ正解にたどり着く手がかりが、複数あるとき——私たちはどう「足し合わせる」のが正解なのでしょうか? 単純に混ぜれば強くなる、とは限りません。状況によっては、弱い手がかりが全体を壊してしまうからです。
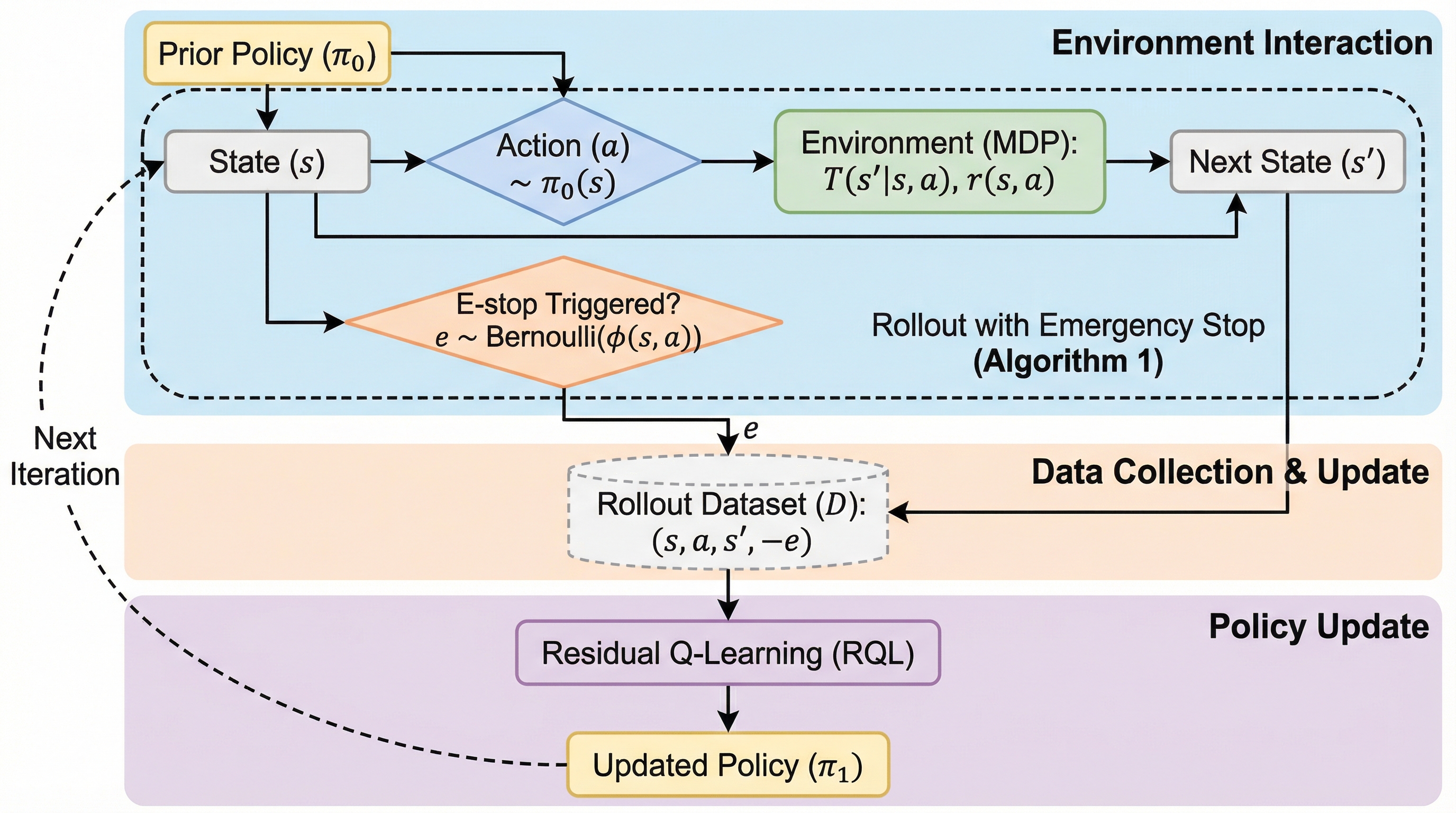
「危ない!」という緊急停止(e-stop)しか手がかりがないとき、ロボットは本当に上達できる? しかも現場で起きるのは、丁寧な指示や正解例ではなく、とっさの停止や介入であることが多いはずです。 実は、“止められないようにする”だけでは、うまくいくとは限りません。
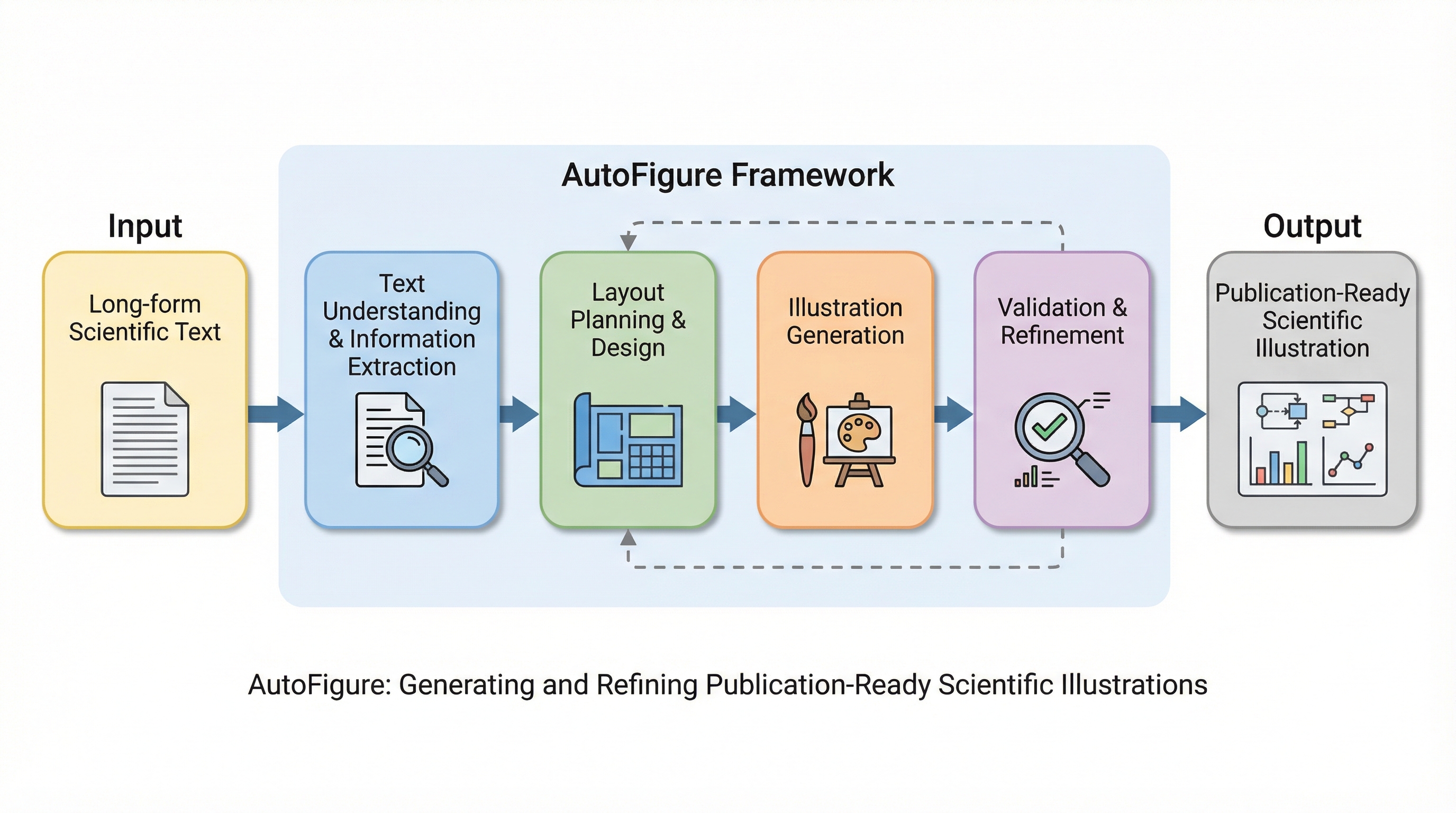
科学の図は、なぜ作るのにこんなに時間がかかるのでしょうか? ボトルネックは「描く」だけでなく、「構造」と「見栄え」を両立する設計にあります。単に要素を並べるのではなく、読み手が迷わず理解できる流れと、ぱっと見て受け入れられる整い方を同時に満たす必要があるからです。
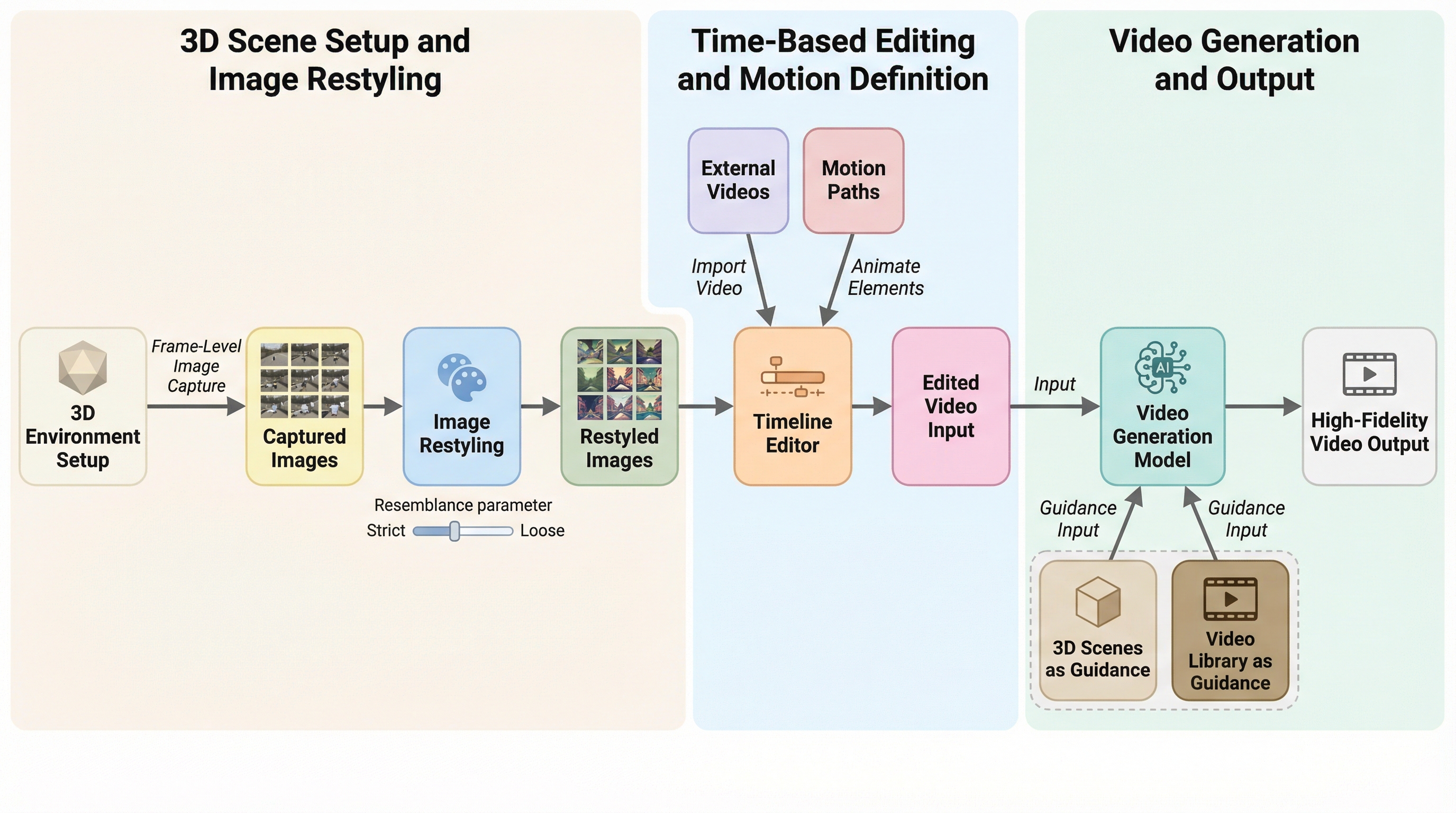
プリプロで「このカット、成立する?」を最短で確かめるにはどうすればいいのでしょうか。 頭の中では見えているのに、チームに伝えた瞬間に“別の映像”へ変換されてしまう――そんなズレを減らす手段は、いつも不足しています。そこには、アイデアの鮮度が高いほど言葉や静止画だけではこぼれ落ちやすい、という制作のジレンマがあります。