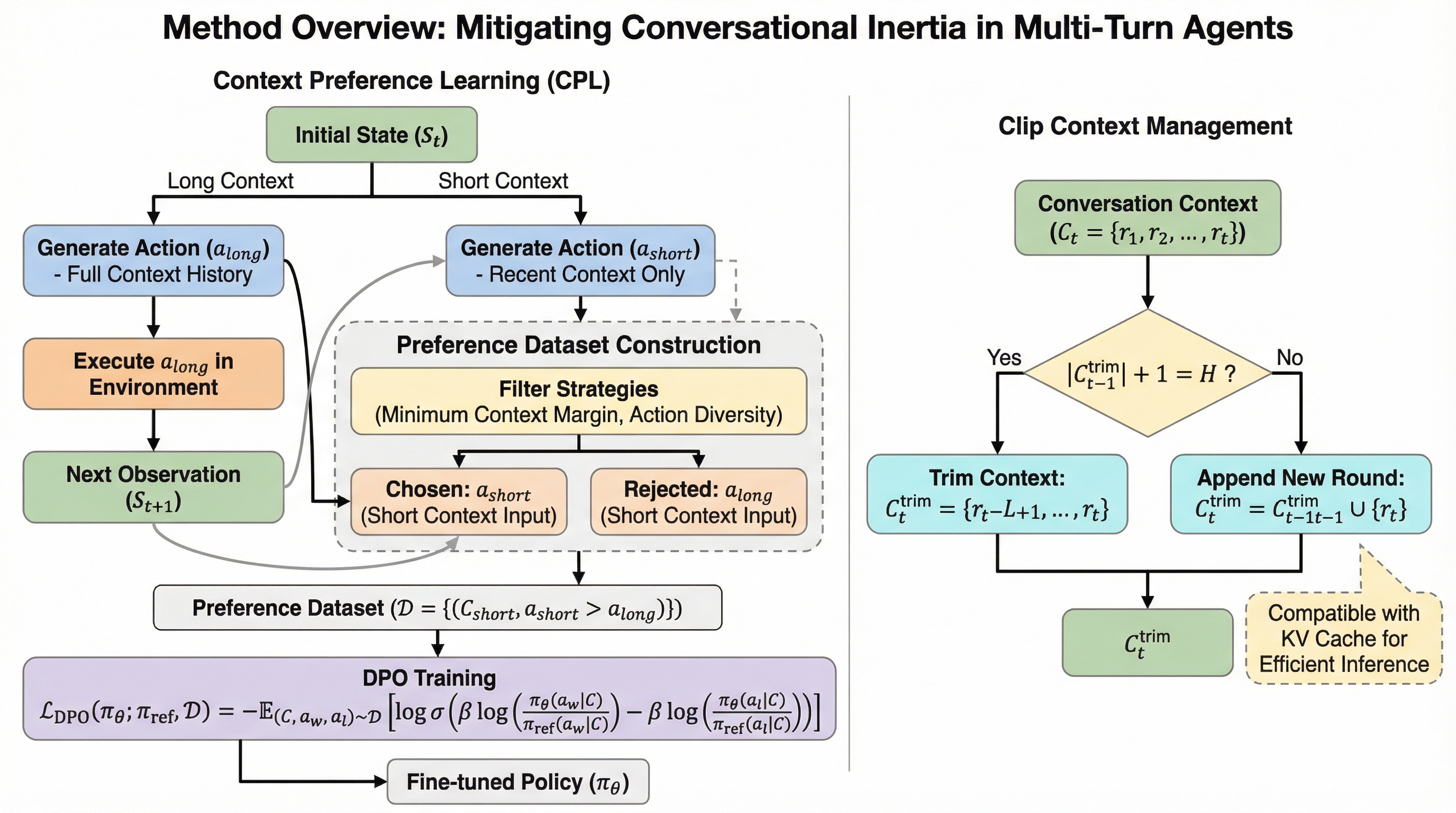
マルチターンエージェントにおける対話の慣性の軽減
大規模言語モデル(LLM)をマルチターンエージェントとして利用する際、過去の自身の回答を過度に模倣して探索を阻害する「会話の慣性(Conversational Inertia)」という現象が特定されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)をマルチターンエージェントとして利用する際、過去の自身の回答を過度に模倣して探索を阻害する「会話の慣性(Conversational Inertia)」という現象が特定されました。
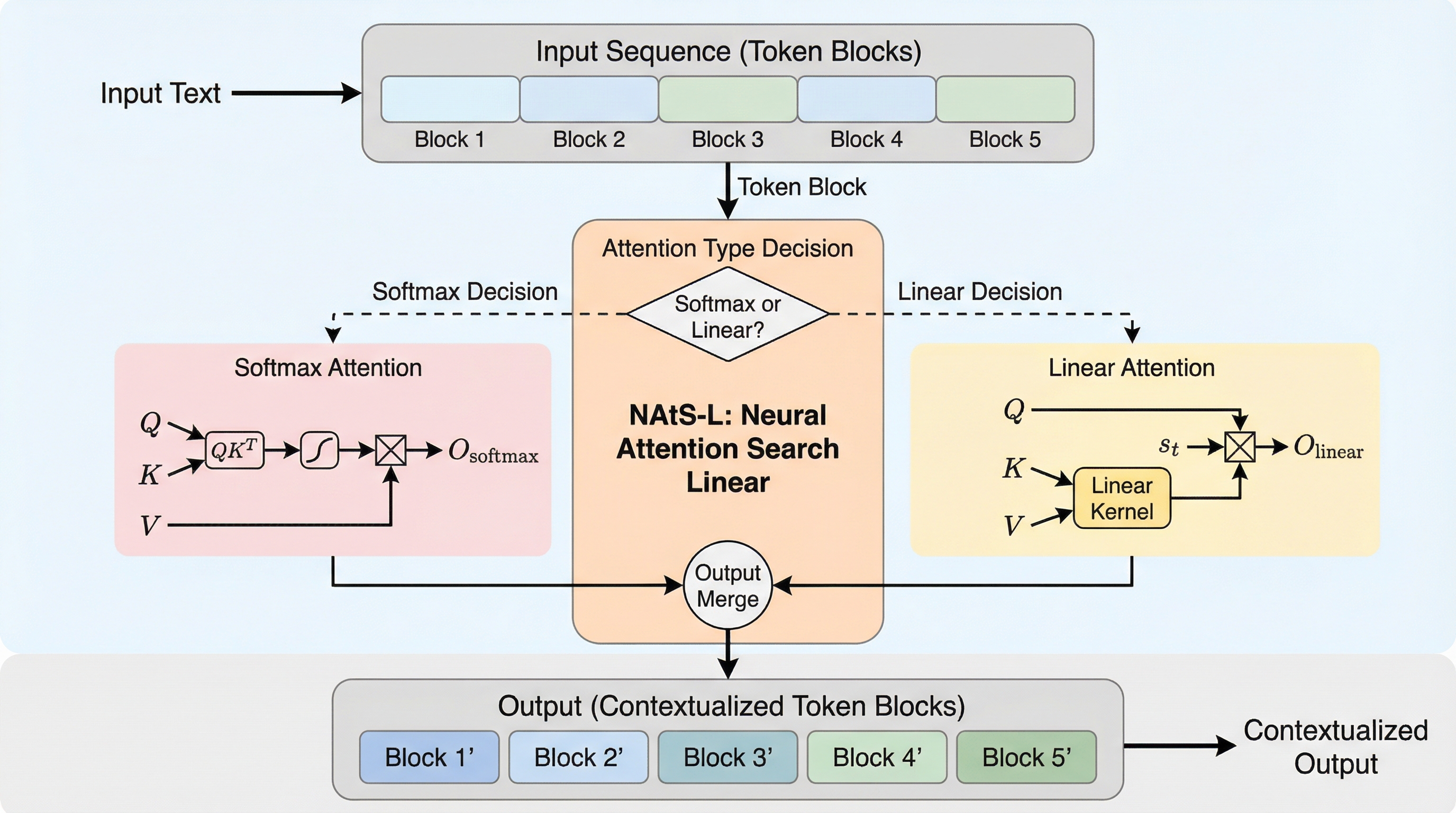
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。
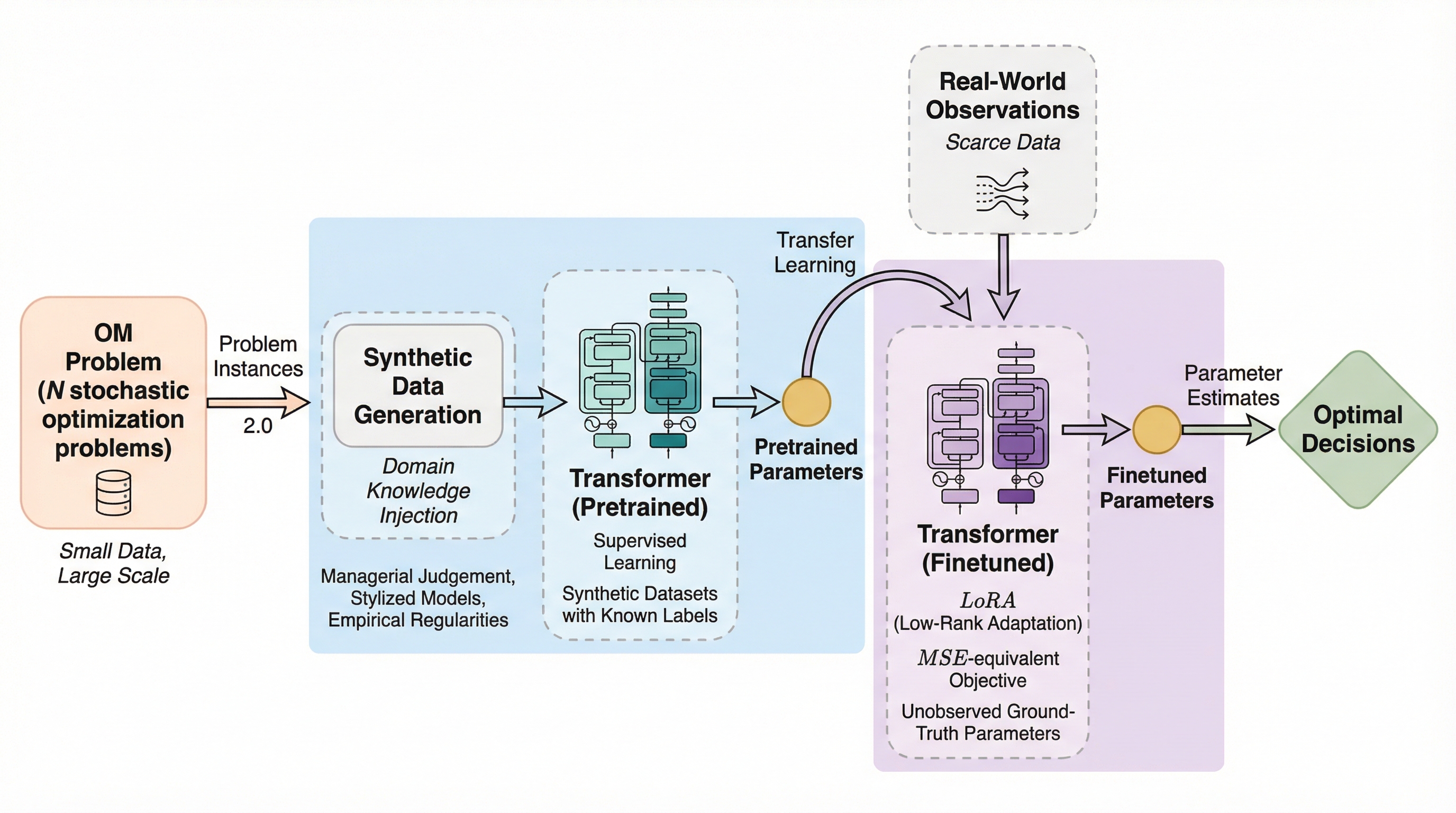
本研究は、少数のデータ点しか得られない大規模な意思決定問題に対し、大規模言語モデル(LLM)の成功に触発された「事前学習と微調整(Pretrain-then-Finetune)」という新しい枠組みを提案している。
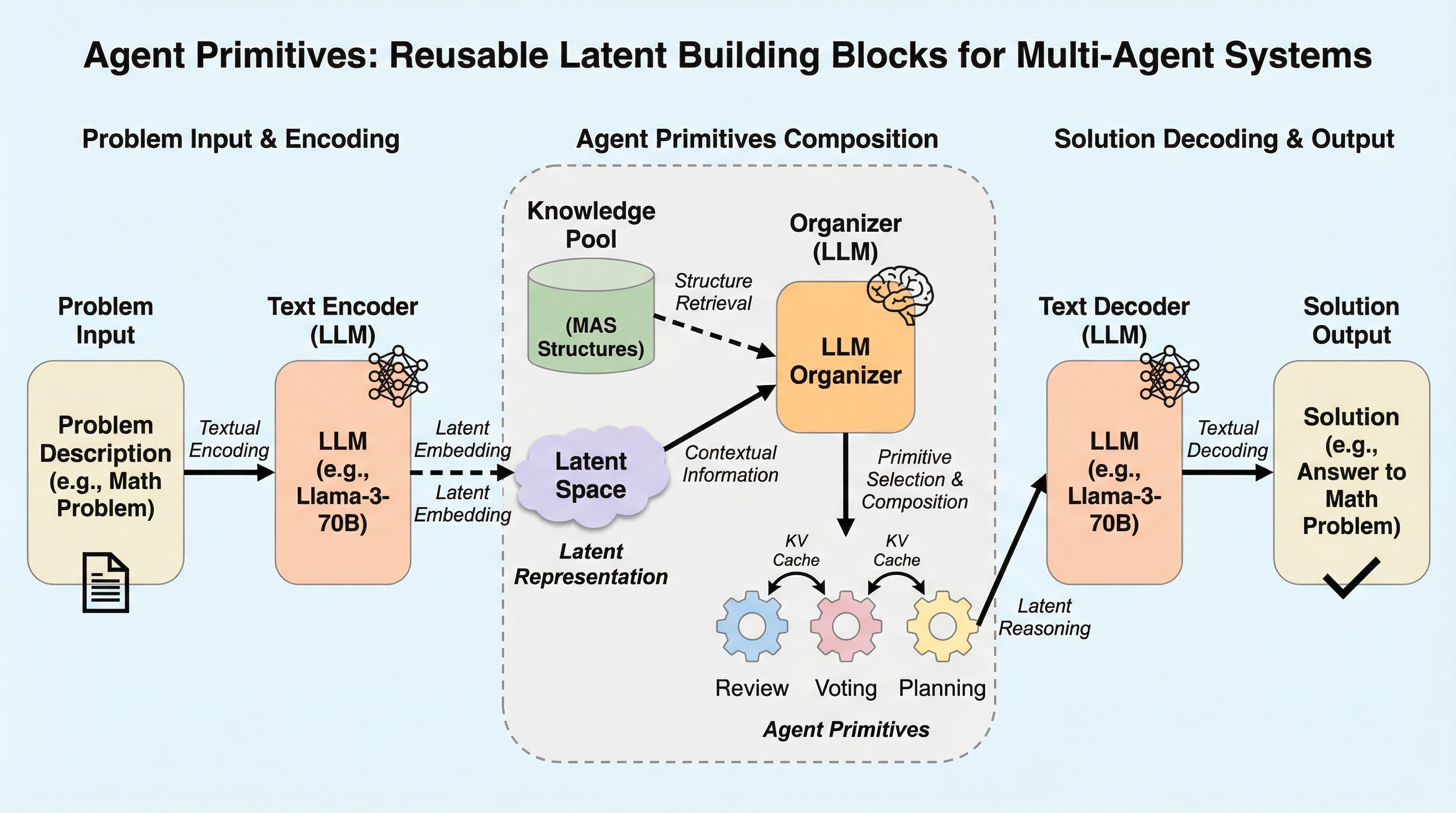
従来のマルチエージェントシステム(MAS)が抱えていた、タスクごとに手動でプロンプトや役割を設計しなければならない構築コストの高さと、自然言語による通信が長文コンテキストやノイズによって劣化するという二つの根本的な課題を解決するため、ニューラルネットワークの構成要素に着想を得た「Agent Primitives」という再利用可能な潜在的構成ブロックが提案されました。 これは、Review(推敲)、Voting and Selection(投票と選択)、Planning and Execution(計画と実行)という、多くのシステムで共通して見られる計算パターンを抽象化したものであり、エージェント間の通信にテキストではなくキー・バリュー(KV)キャッシュを直接受け渡す潜在的通信を採用することで、情報の劣化を防ぎつつ処理の高速化を実現しています。 数学的推論やコード生成などのベンチマークを用いた検証の結果、単一エージェントと比較して平均精度が12.0〜16.5%向上し、従来のテキストベースのシステムよりもトークン使用量と推論遅延を3〜4倍削減することに成功したほか、長文の文脈における指示遵守率が自然言語通信の15.6%から73.3%へと劇的に改善されるなど、高い堅牢性が確認されました。
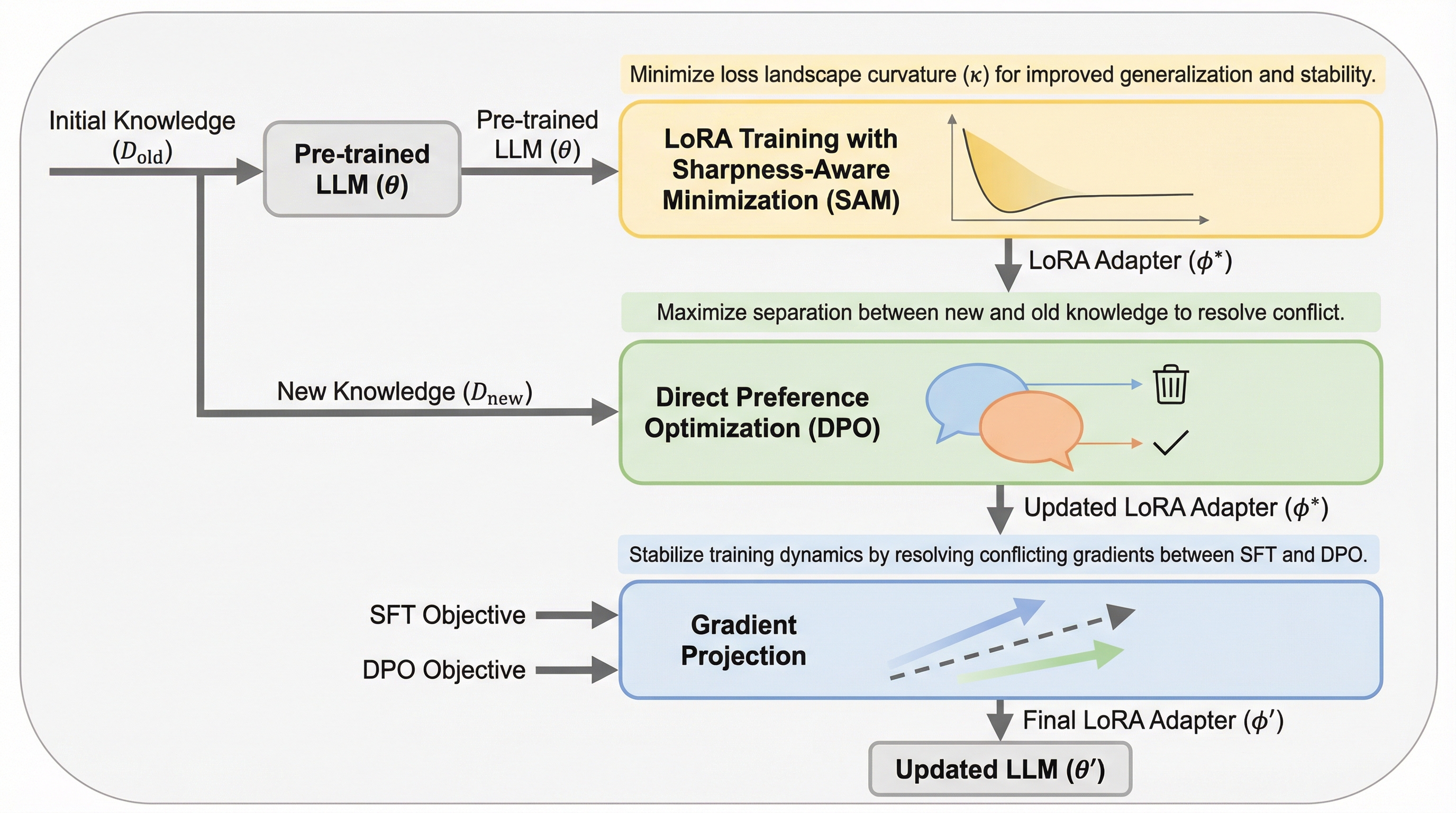
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。
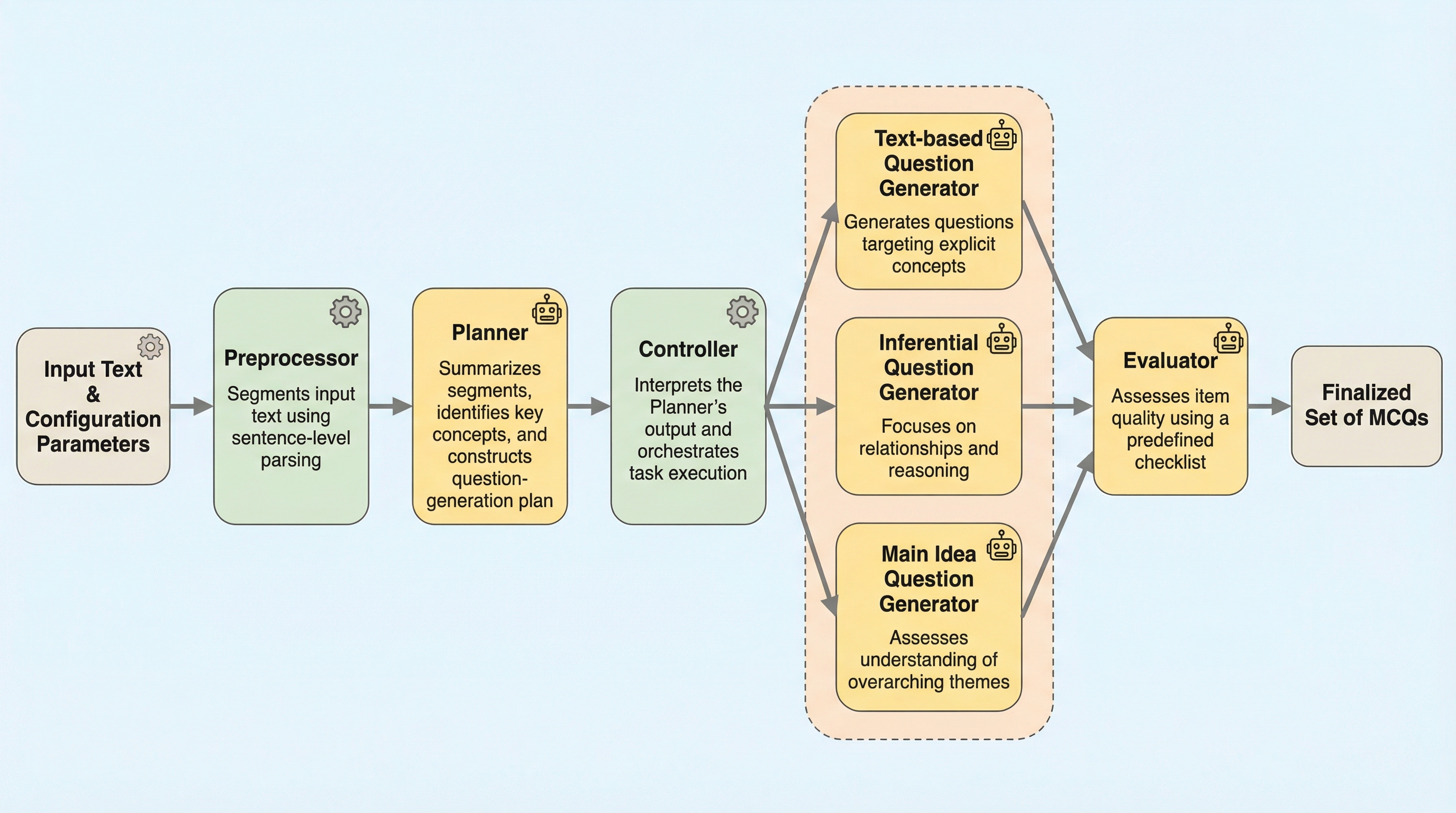
ReQUESTAは、大規模言語モデル(LLM)とルールベースの仕組みを組み合わせたハイブリッドなマルチエージェントフレームワークであり、テキスト想起、推論、主旨把握という異なる認知レベルの多肢選択式問題を系統的に生成します。
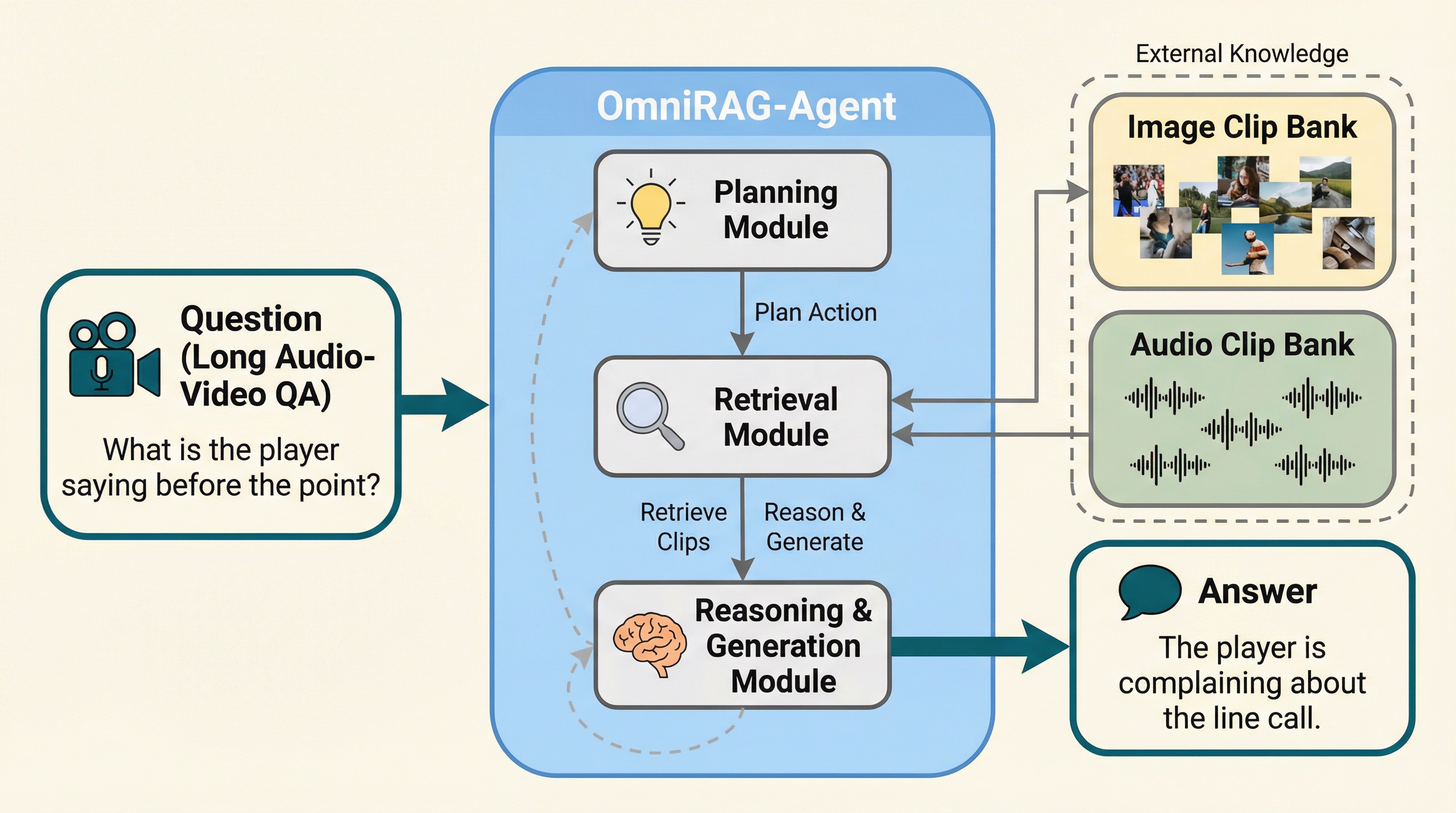
長時間の音声と動画を統合して理解するタスクにおいて、計算資源の制約を克服しながら高精度な回答を実現する「OmniRAG-Agent」が提案されました。 この手法は、動画全体を一度に処理するのではなく、外部の画像・音声バンクから必要な情報を動的に取得するRAGと、自律的に思考とツール呼び出しを繰り返すエージェント機能を組み合わせています。 強化学習手法であるGRPOを用いることで、ツールの適切な使用方法と最終的な回答の質を同時に最適化し、15GBのVRAMという低リソース環境で既存の大型モデルを凌駕する性能を達成しました。
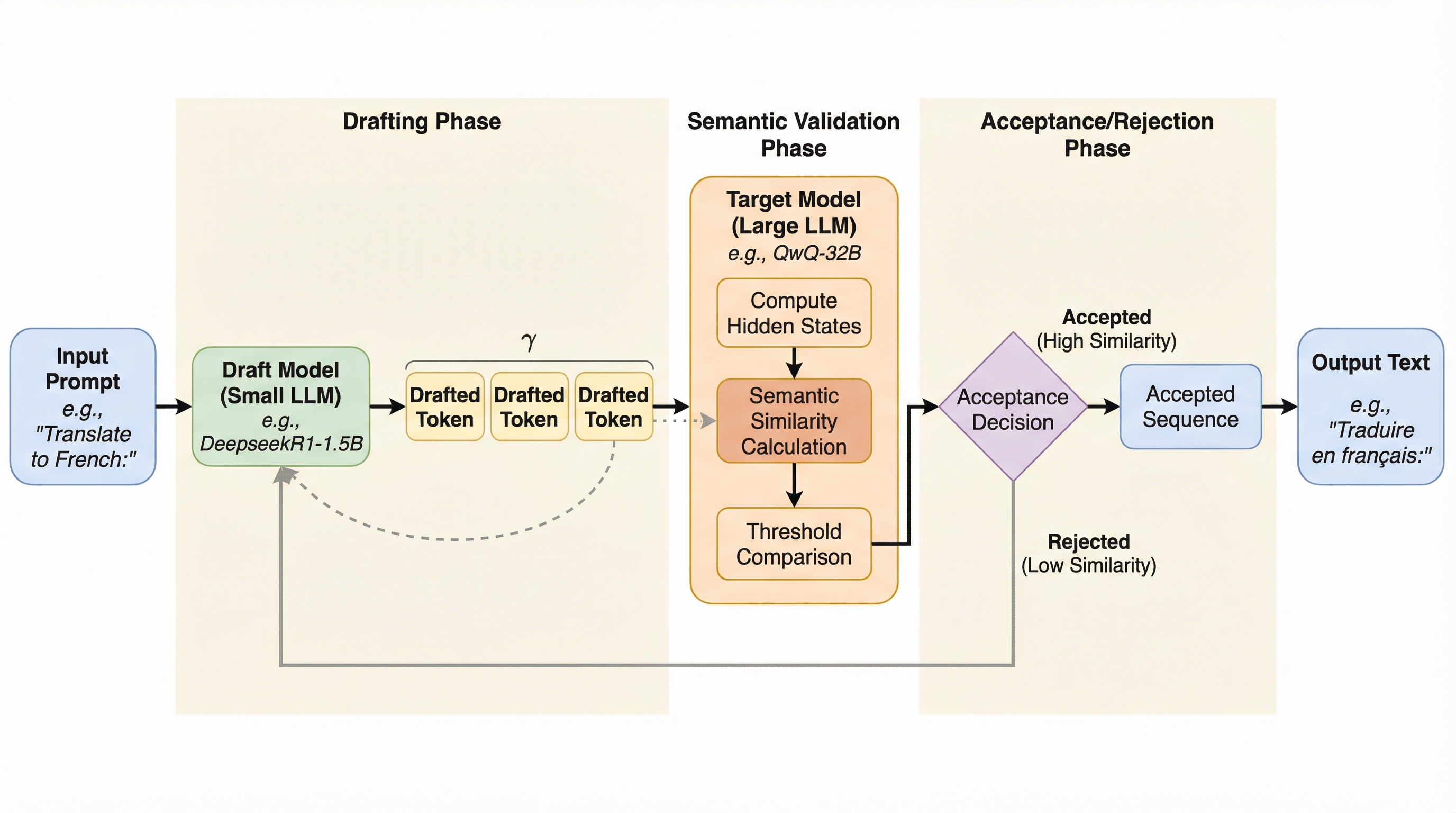
大規模言語モデルの推論を高速化する投機的デコーディングにおいて、従来のトークン単位の厳密な一致ではなく、文章全体の意味的な等価性を検証する新しいフレームワーク「SemanticSpec」が提案されました。
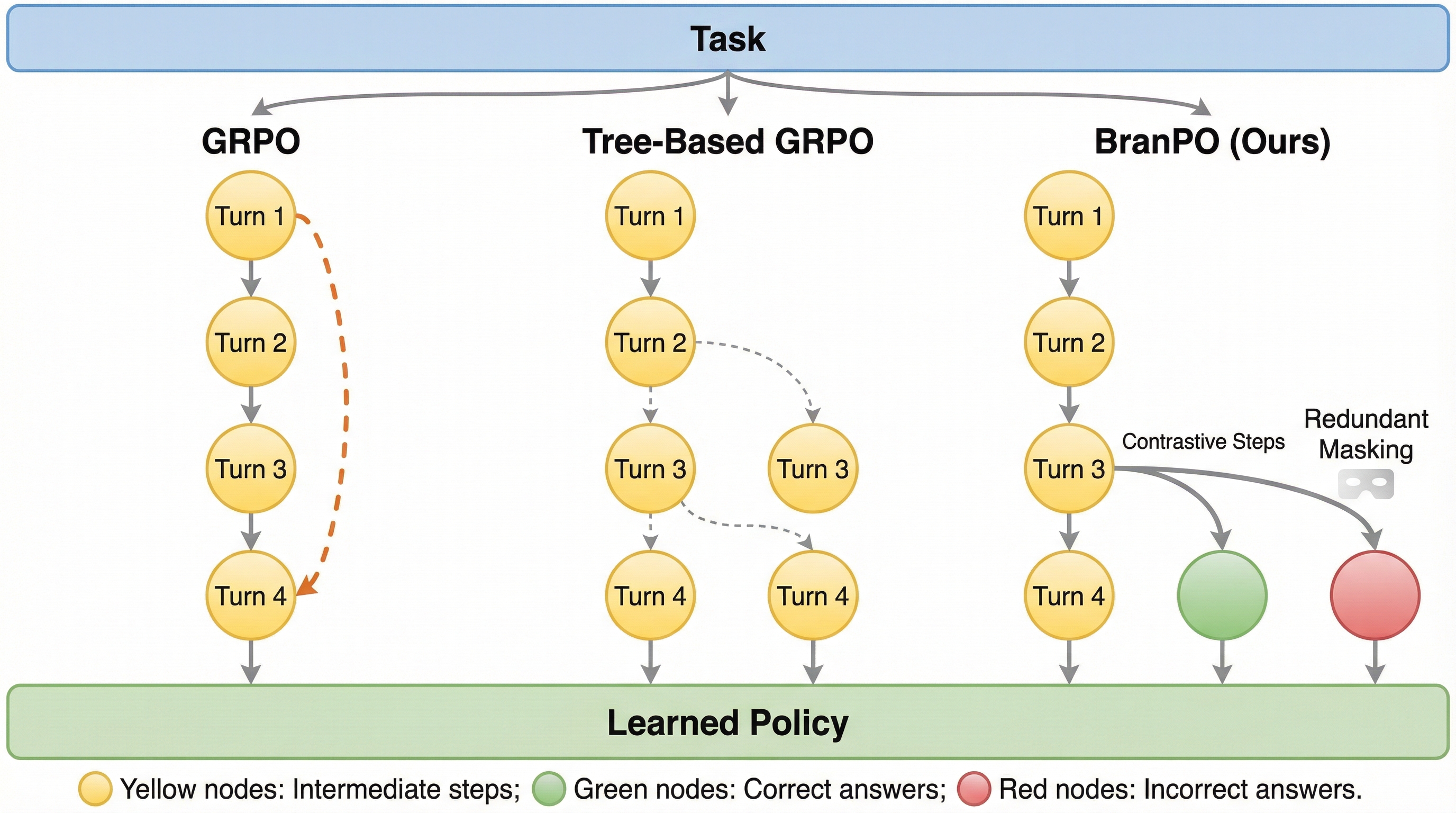
大規模言語モデルを用いた多段階検索エージェントの学習において、長い工程の最後にのみ与えられる報酬では、途中のどの行動が成功に寄与したかを特定できない「クレジット割り当て」の困難さが大きな課題であった。
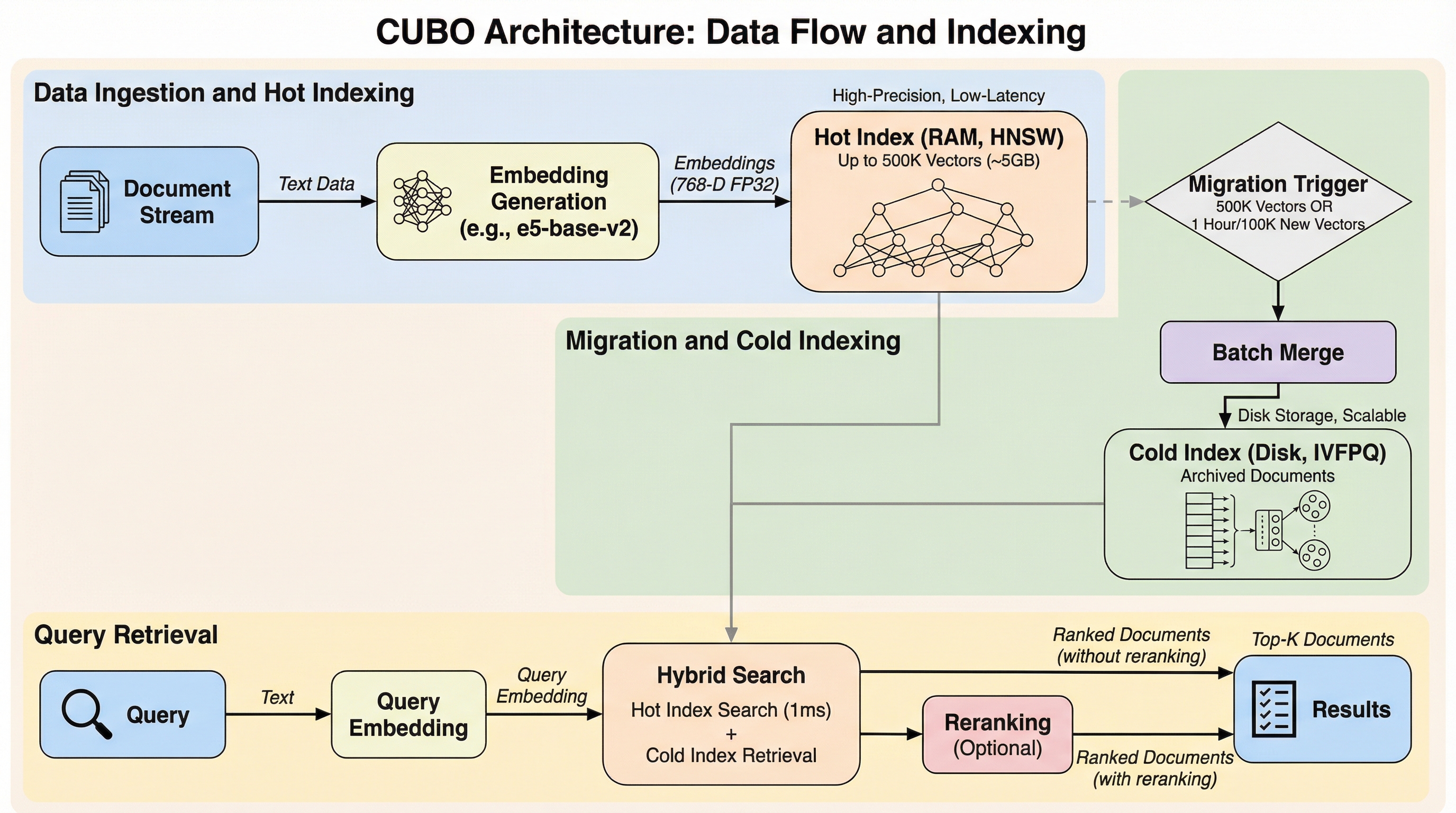
CUBOは、16GBの共有メモリを搭載した一般的なノートPCで動作するように設計された、自己完結型の検索拡張生成(RAG)プラットフォームであり、クラウドベースのAIが抱えるGDPR違反のリスクを回避しつつ、通常は18〜32GBのRAMを必要とするローカルRAGシステムを、15.