OmniRAG-Agent: 低リソースな長時間音声・動画QAのためのエージェント型全方位モダリティ推論
長時間の音声と動画を統合して理解するタスクにおいて、計算資源の制約を克服しながら高精度な回答を実現する「OmniRAG-Agent」が提案されました。 この手法は、動画全体を一度に処理するのではなく、外部の画像・音声バンクから必要な情報を動的に取得するRAGと、自律的に思考とツール呼び出しを繰り返すエージェント機能を組み合わせています。 強化学習手法であるGRPOを用いることで、ツールの適切な使用方法と最終的な回答の質を同時に最適化し、15GBのVRAMという低リソース環境で既存の大型モデルを凌駕する性能を達成しました。
TL;DR(結論)
長時間の音声と動画を統合して理解するタスクにおいて、計算資源の制約を克服しながら高精度な回答を実現する「OmniRAG-Agent」が提案されました。 この手法は、動画全体を一度に処理するのではなく、外部の画像・音声バンクから必要な情報を動的に取得するRAGと、自律的に思考とツール呼び出しを繰り返すエージェント機能を組み合わせています。 強化学習手法であるGRPOを用いることで、ツールの適切な使用方法と最終的な回答の質を同時に最適化し、15GBのVRAMという低リソース環境で既存の大型モデルを凌駕する性能を達成しました。
なぜこの問題か
現代のAI研究において、テキスト、画像、音声、動画を統合的に処理する全方位モダリティ(Omnimodal)モデルは、パーソナルアシスタントやロボット制御などの分野で不可欠な技術となっています。しかし、数分から数十分に及ぶ長時間の動画や音声を扱う場合、すべての情報を密にエンコードしようとすると計算コストやメモリ消費が指数関数的に増大し、一般的なハードウェアでは処理が不可能になるという深刻な課題があります。特に、限られた計算資源しか持たない環境において、長時間のマルチモーダルデータを効率的に推論する手法は確立されていませんでした。既存のアプローチには、主に3つの大きな技術的障壁が存在します。 第一に、予算やリソースが限られた状況では、動画内の膨大なフレームや音声データの中から、質問の回答に直結する微細な証拠を特定するための検索能力が不足しています。第二に、単一のモデルによる推論では、広範な情報の中から必要な箇所を能動的に選択し、探索を継続する計画能力が限られており、複雑な問いに対して情報の欠落が生じやすくなります。…
核心:何を提案したのか
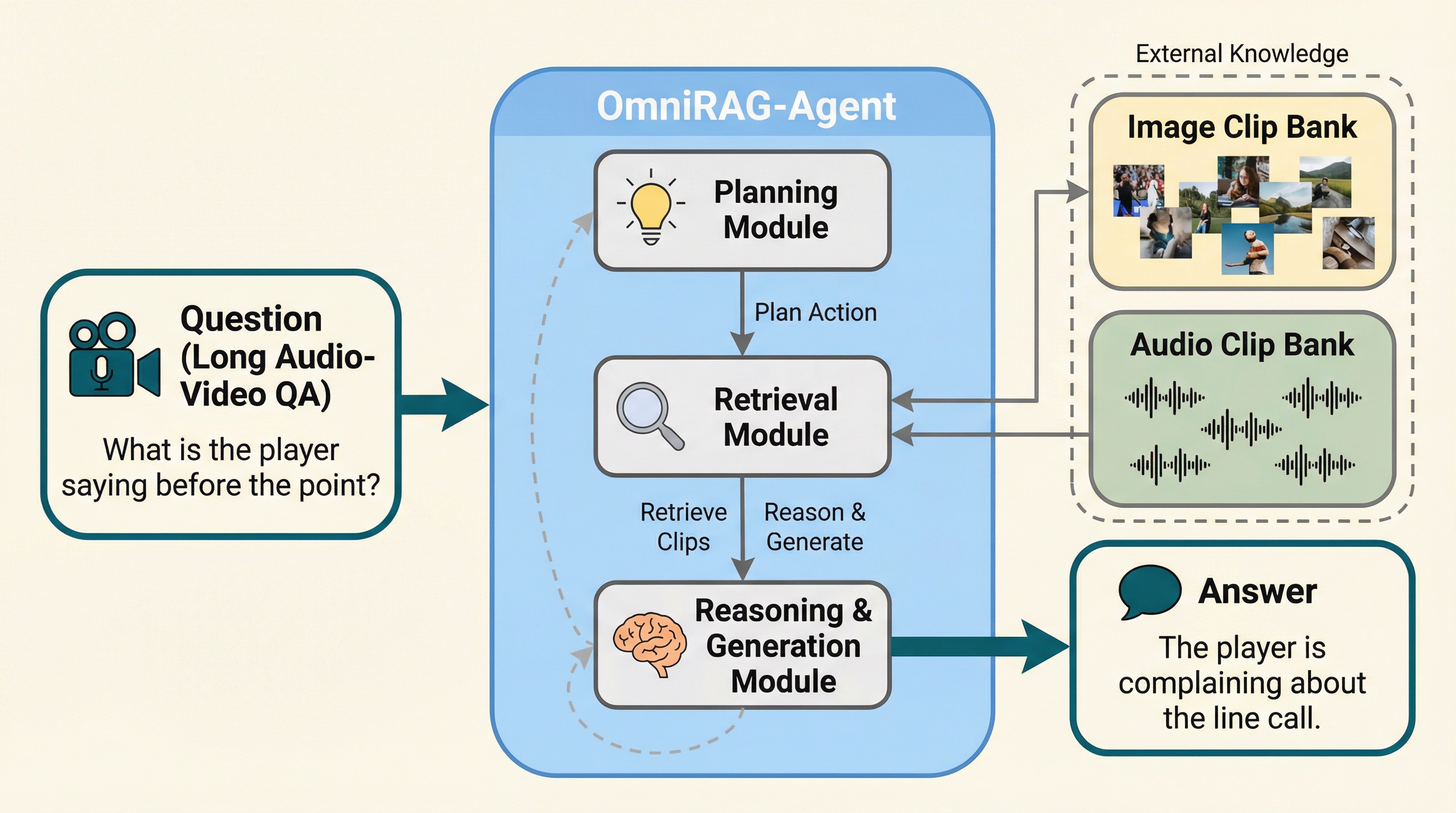
本論文では、低リソース環境下での長時間音声・動画QA(質疑応答)を解決するために、エージェント型の全方位モダリティ推論フレームワーク「OmniRAG-Agent」を提案しています。この手法の核心は、全方位モダリティLLM(OmniLLM)を自律的なエージェントとして定義し、外部に構築した画像・音声の検索拡張生成(RAG)モジュールと対話させることで、必要な情報だけをオンデマンドで取得させる点にあります。これにより、動画全体をメモリに読み込む必要がなくなり、計算負荷を劇的に軽減しながら詳細な推論が可能になります。 具体的には、まず入力された動画から画像フレームと音声の文字起こし(ASR)データを抽出し、それぞれをインデックス化された外部バンクとして保持します。モデルはこのバンクに対して「画像検索ツール」や「音声検索ツール」を介してアクセスします。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related