対照的な動的分岐サンプリングによる多段階検索エージェントの学習
大規模言語モデルを用いた多段階検索エージェントの学習において、長い工程の最後にのみ与えられる報酬では、途中のどの行動が成功に寄与したかを特定できない「クレジット割り当て」の困難さが大きな課題であった。
TL;DR(結論)
大規模言語モデルを用いた多段階検索エージェントの学習において、長い工程の最後にのみ与えられる報酬では、途中のどの行動が成功に寄与したかを特定できない「クレジット割り当て」の困難さが大きな課題であった。本研究では、エージェントの失敗が主に工程の終盤(末尾)における推論や要約の段階で発生するという詳細な分析に基づき、軌跡の末尾付近で動的に枝分かれさせて正誤の対照的なデータを生成する手法「BranPO」を提案した。この手法は、タスクの難易度に応じた適応的なサンプリングと、冗長な手順を削減するマスク処理を組み合わせることで、追加の計算コストを抑えつつ、複雑なマルチホップ検索タスクにおいて従来の強化学習手法を大幅に上回る精度と学習効率を実現している。
なぜこの問題か
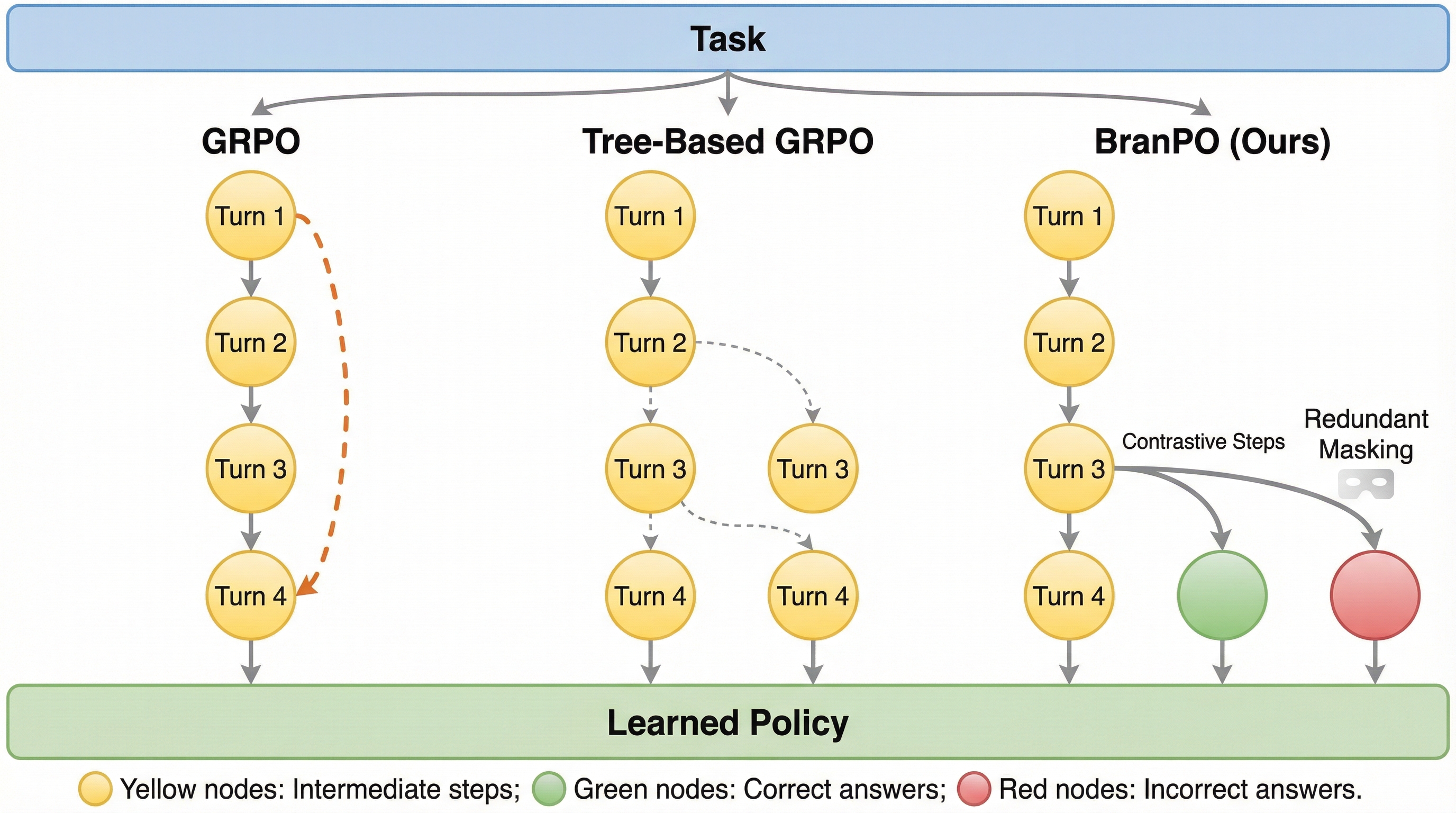
大規模言語モデル(LLM)を自律的なエージェントとして活用し、外部ツールや検索エンジンを多段階で操作させる試みが活発化しているが、このような長期的なタスクにおいて強化学習を行う際、学習信号が軌跡全体の最後に出力される「正解か不正解か」という疎な報酬のみに依存していることが、学習を極めて困難にしている。一連の複雑な行動の中で、どの特定の決定が最終的な成功や失敗に直結したのかを特定することが難しく、これが学習の不安定さや高い分散を引き起こす原因となっている。既存の研究では、中間状態から枝分かれして探索を行う木構造ベースの手法が提案されているが、これらは計算効率が悪く、ノイズの多い学習信号を生む傾向があるため、実用的なスケーラビリティに欠けていた。 本研究では、検索エージェントの挙動を詳細に分析した結果、重要な発見を得た。それは、初期の段階での行動(検索クエリの生成や計画立案など)は多くの試行で共通しており、性能の差は主に工程の終盤における決定で生じているという事実である。…
核心:何を提案したのか
本論文では、価値関数を必要としない新しい方策最適化手法である「Branching Relative Policy Optimization(BranPO)」を提案している。この手法の核心は、軌跡の末尾付近で再サンプリングを行い、共通の接頭辞(プリフィックス)に対して異なる結末(サフィックス)を持つ対照的な分岐を構築することにある。これにより、密な報酬を人手で設定することなく、ステップレベルでの対照的な教師信号を提供することが可能になる。BranPOは、計算コストの高いモンテカルロ推定に頼るのではなく、失敗が発生しやすい決定ポイントを再帰的に切り詰め、結果が異なる分岐のみを抽出して学習に利用する。これにより、エージェントは「何が正解か」だけでなく「何が失敗の原因か」を直接的に比較して学習できるようになる。 また、BranPOは単なるサンプリング手法にとどまらず、学習の効率と安定性を高めるための複数の高度な仕組みを導入している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related