LLMに触発された事前学習と微調整による小規模データ・大規模最適化手法の提案
本研究は、少数のデータ点しか得られない大規模な意思決定問題に対し、大規模言語モデル(LLM)の成功に触発された「事前学習と微調整(Pretrain-then-Finetune)」という新しい枠組みを提案している。
TL;DR(結論)
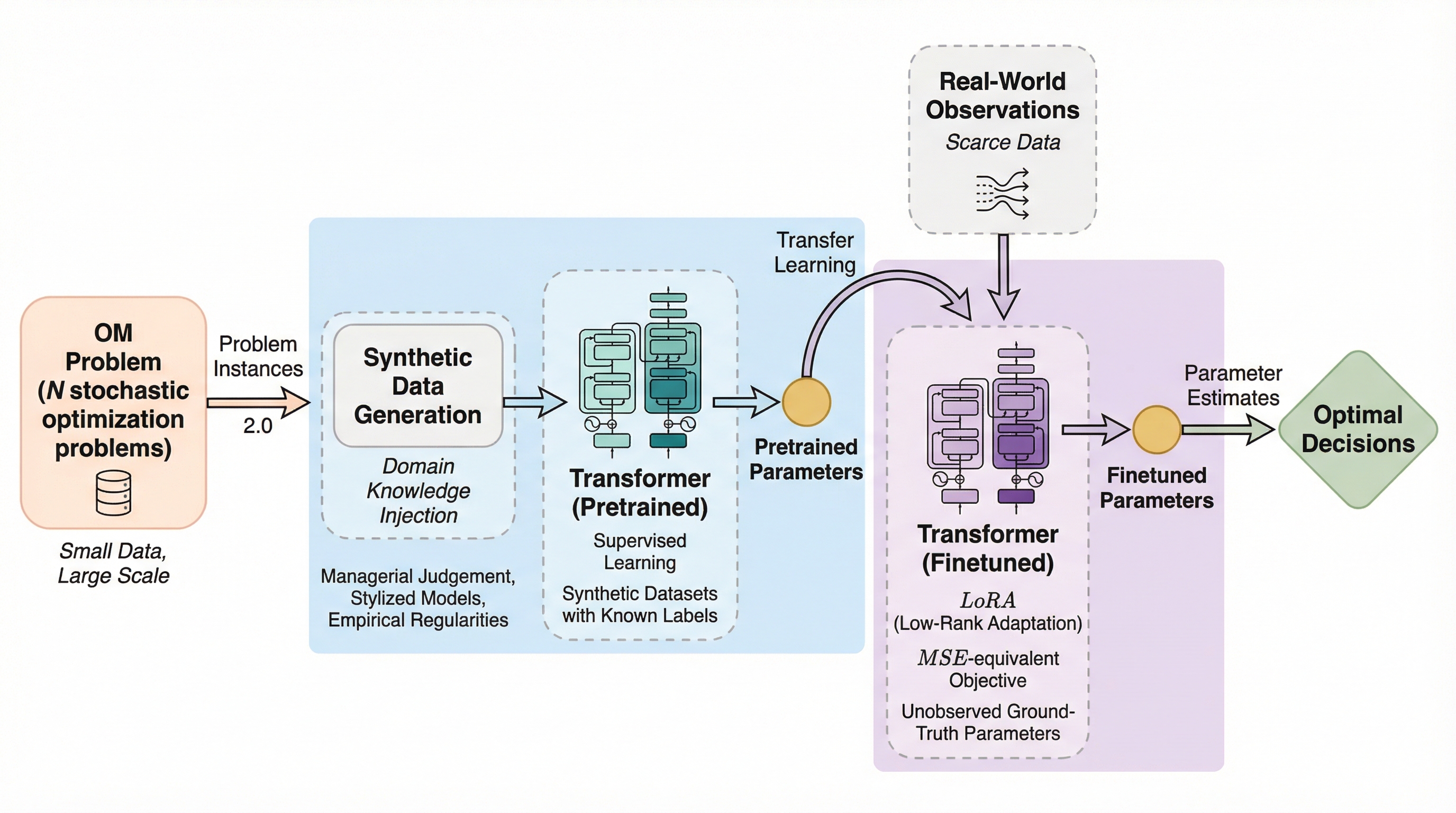
本研究は、少数のデータ点しか得られない大規模な意思決定問題に対し、大規模言語モデル(LLM)の成功に触発された「事前学習と微調整(Pretrain-then-Finetune)」という新しい枠組みを提案している。具体的には、ドメイン知識を反映した合成データでTransformerモデルを事前学習し、その後に限られた実データで微調整を行うことで、データの希少性と意思決定の複雑さを同時に解決する手法を開発した。理論的な誤差分析により、事前学習によるドメイン知識の注入と微調整による環境適応が相互に補完し合い、問題の規模が大きくなるほど転移学習の効果が高まる「規模の経済」が働くことを数学的に証明している。
なぜこの問題か
現代のビジネス環境、特にオペレーションズ・マネジメント(OM)の分野では、企業は膨大な数の製品ポートフォリオに対して同時に多くの運用上の意思決定を下す必要がある。しかし、個々の製品や事例に注目すると、得られるデータは非常に少なく、ノイズが多いという「小規模データ・大規模問題(Small-data, Large-scale Problem)」に直面することが多い。例えば、中国のECプラットフォームであるTmallのデータによれば、2018年5月から7月の間に掲載された75,000点以上の製品のうち、21.6%以上は1日あたりのユニークビジター数が平均10人未満であり、14.3%以上は1人以下であったという報告がある。また、ファストファッション大手のSheinでは、1日に最大10,000点もの新しい最小管理単位(SKU)を投入するが、初期バッチは100ユニット程度と小さく、製品のライフサイクルも約40日と極めて短い。 このような環境では、十分な販売データが蓄積される前に意思決定を下さなければならず、従来のサンプル平均近似(SAA)のようなデータ駆動型の手法を直接適用することは困難である。…
核心:何を提案したのか
本研究の核心は、Transformerアーキテクチャを基盤とし、ドメイン知識を活用した「事前学習」と、実データへの「微調整」を組み合わせた新しい意思決定パイプラインの提案である。この手法は、まず管理上の知見や理論的なモデル、あるいは過去の経験から得られた経験則に基づいて生成された大規模な「合成データ」を用いてモデルを事前学習する。この事前学習プロセスにより、意思決定環境の構造的特徴やドメイン知識をモデルに注入することが可能になる。 次に、この事前学習済みモデルを、実際に得られた少量の実データを用いて微調整する。この二段階のアプローチには、相補的な二つの利点がある。第一に、事前学習によって、実データが不足している状況でも表現力の高い現代的なAIモデルの訓練が可能になることである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related