トークンを超えて:内部状態のプロービングによる効率的な推論のための意味を考慮した投機的デコーディング
大規模言語モデルの推論を高速化する投機的デコーディングにおいて、従来のトークン単位の厳密な一致ではなく、文章全体の意味的な等価性を検証する新しいフレームワーク「SemanticSpec」が提案されました。
TL;DR(結論)
大規模言語モデルの推論を高速化する投機的デコーディングにおいて、従来のトークン単位の厳密な一致ではなく、文章全体の意味的な等価性を検証する新しいフレームワーク「SemanticSpec」が提案されました。 モデルの内部隠れ状態を探索(プロービング)して特定の意味を持つシーケンスが生成される確率を推定する予測器を導入し、表現が異なっても意味が同じであれば候補を採用することで、不必要な拒絶を大幅に削減しています。 実験ではDeepSeek-R1-32Bで最大2.7倍、QwQ-32Bで最大2.1倍の高速化を達成し、既存のトークン単位やシーケンス単位の手法を一貫して上回る効率性と、ターゲットモデル本来の推論精度を両立させています。
なぜこの問題か
大規模言語モデル(LLM)は多様なタスクで驚異的な性能を示していますが、トークンを一つずつ順番に生成する自己回帰的デコーディングの特性上、推論の遅延が実用化における大きな障壁となっています。この遅延はモデルのパラメータ数や出力される文章の長さに比例して増大するため、特に複雑な問題を解く際にはユーザーの待ち時間が極端に長くなるという課題があります。近年登場したOpenAI o1やDeepSeek R1に代表される大規模推論モデル(LRM)では、最終的な回答を導き出す前に詳細な中間思考プロセスである「思考の連鎖(Chain of Thought)」を生成するため、出力トークン数が膨大になり、この遅延問題はさらに深刻化しています。この問題を解決するために、軽量なドラフトモデルで候補を作成し、それを強力なターゲットモデルで並列に検証する投機的デコーディングという手法が広く研究されてきました。 しかし、既存の投機的デコーディング手法の多くは、トークン単位での厳密な一致を検証の基準としており、意味的な等価性を考慮できていないという根本的な欠点があります。…
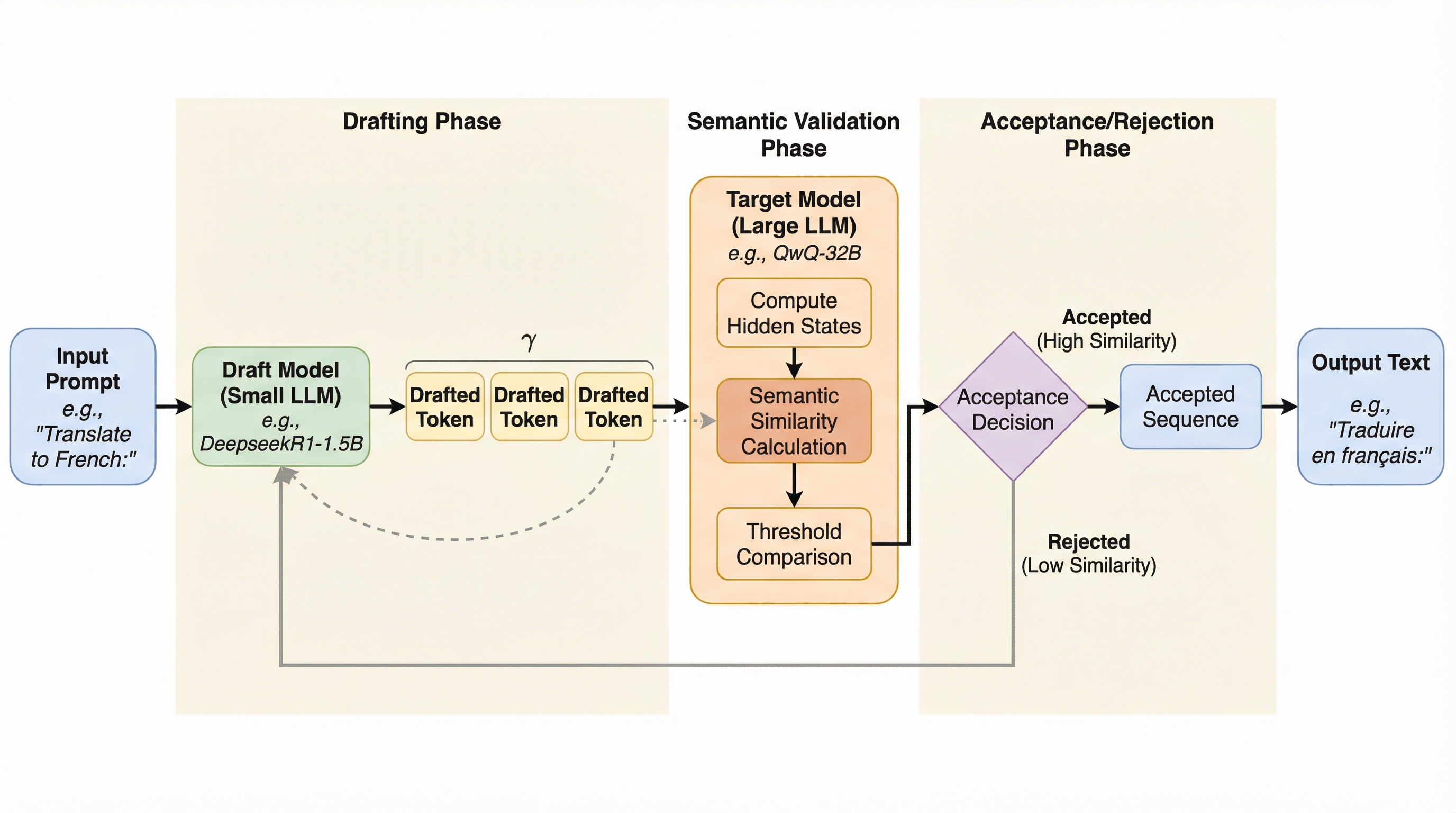
核心:何を提案したのか
本研究では、投機的デコーディングの検証単位をトークンレベルから意味レベルへと引き上げ、意味的な等価性を柔軟に扱うことができる新しいフレームワーク「SemanticSpec」を提案しています。SemanticSpecの最大の特徴は、個々のトークンを逐一確認するのではなく、意味のまとまりを持つシーケンス全体を検証の単位として動作させる点にあります。このアプローチを実現するための核心的な技術は、ある特定の意味を持つ文章が生成される確率、すなわち「意味確率(Semantic Probability)」を正確に推定するメカニズムの導入です。従来のLLMからは、特定のトークンが次に出現する確率は直接取得できますが、ある特定の意味内容を表現する文章全体が生成される確率を直接算出する機能は備わっていません。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related