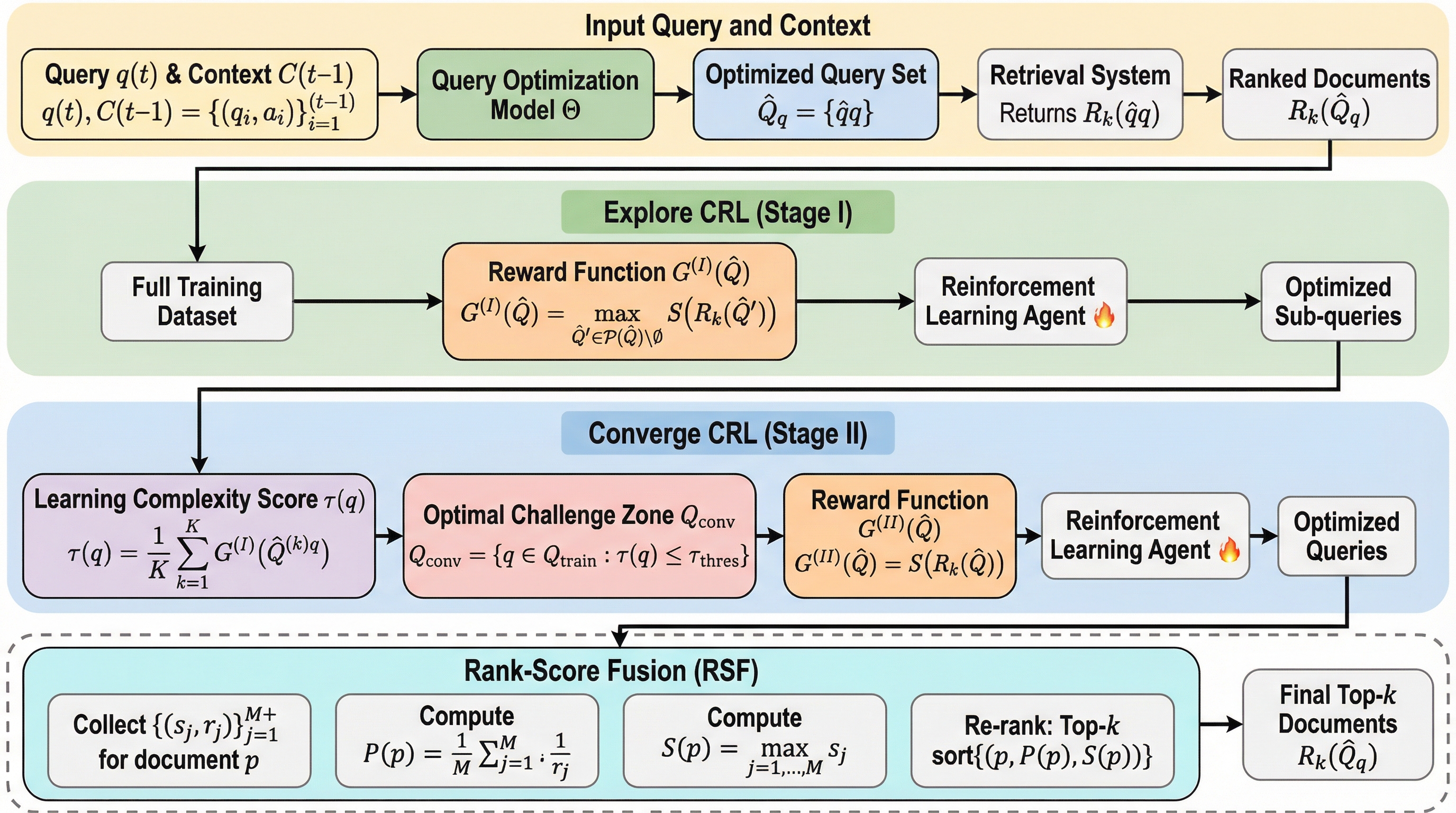
いつより多く探索すべきか:強化学習による適応的な複雑なクエリ最適化
検索拡張生成(RAG)において、複雑なユーザーの質問を適切に分解・明確化して検索精度を高めるための新しい強化学習フレームワーク「ACQO」が提案されました。従来の単一クエリの拡張手法とは異なり、クエリの複雑さに応じて適応的に検索プロセスを拡張するかどうかを判断し、複数のサブクエリを生成する仕組みを備えています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
検索拡張生成(RAG)において、複雑なユーザーの質問を適切に分解・明確化して検索精度を高めるための新しい強化学習フレームワーク「ACQO」が提案されました。従来の単一クエリの拡張手法とは異なり、クエリの複雑さに応じて適応的に検索プロセスを拡張するかどうかを判断し、複数のサブクエリを生成する仕組みを備えています。
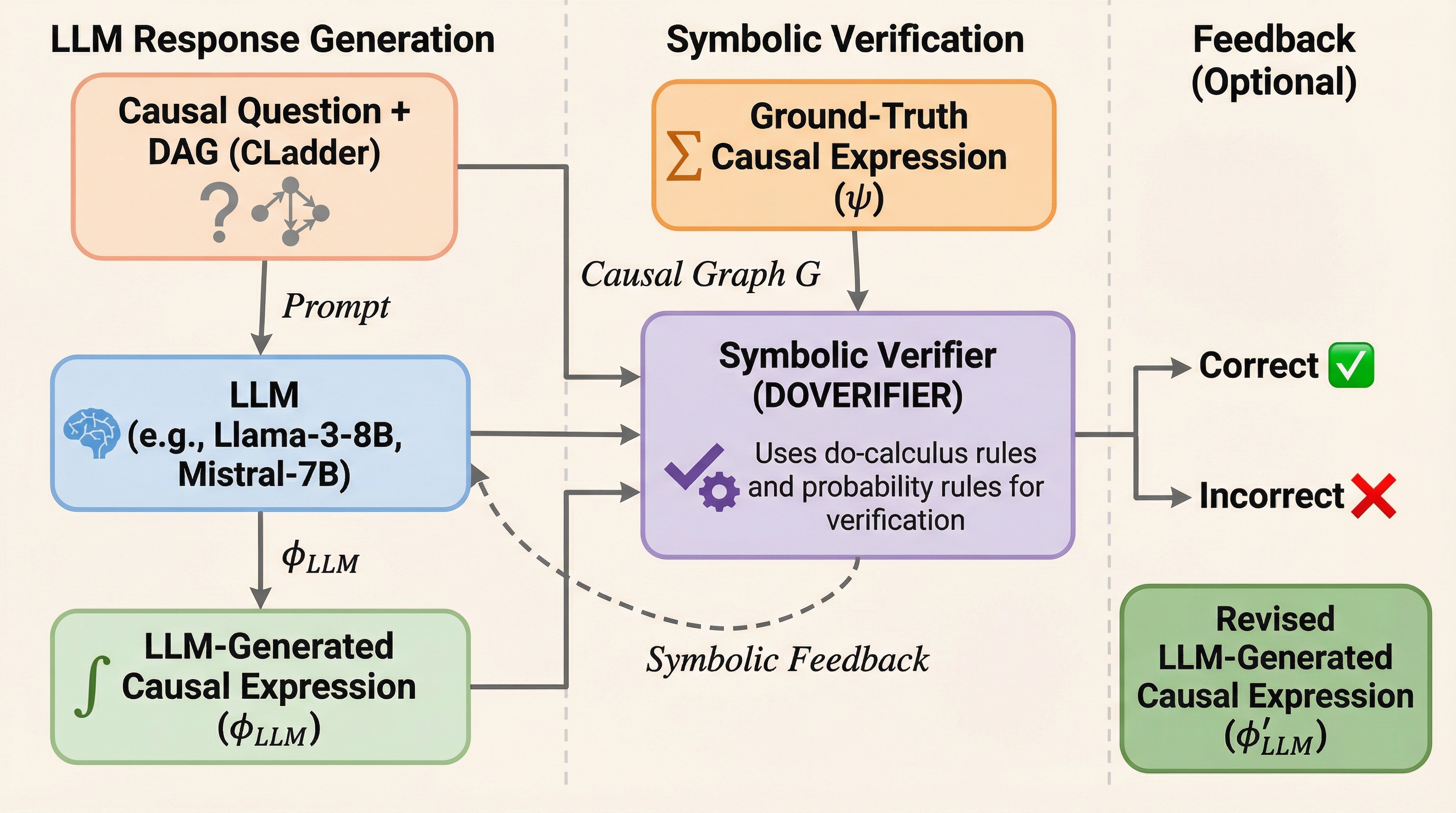
大規模言語モデル(LLM)の因果推論能力を評価する際、従来の文字列一致や表面的な指標では、モデルが出力した因果式が数学的に正しいかどうかを正確に判定できないという問題がありました。 本研究が提案する「DoVerifier」は、do演算(do-calculus)と確率論の規則に基づき、モデルが生成した式が与えられた因果グラフから形式的に導出可能かをシンボリックに検証するシステムです。 検証の結果、従来の手法では誤答とされていた多くの回答が実は意味的に正解であったことが判明し、この手法を用いることでLLMの真の推論能力をより厳密に測定し、自己修正を促すことが可能になります。
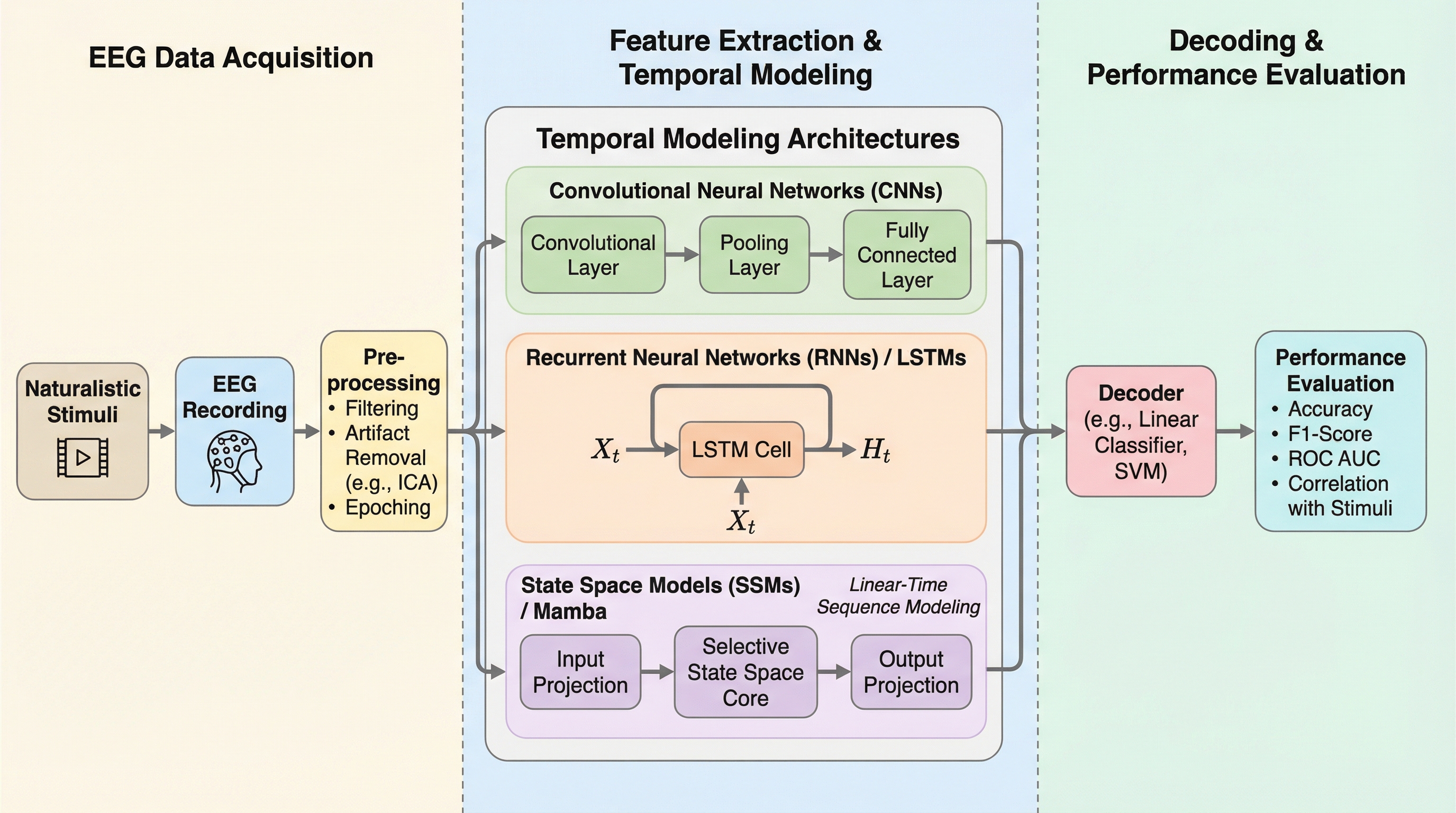
本研究は、映画鑑賞時の脳波(EEG)データを用い、S5(状態空間モデル)やEEGXF(安定化Transformer)を含む5つのモデルで時間的コンテキストの影響を検証した。 結果として、S5は64秒の長いセグメントで98.
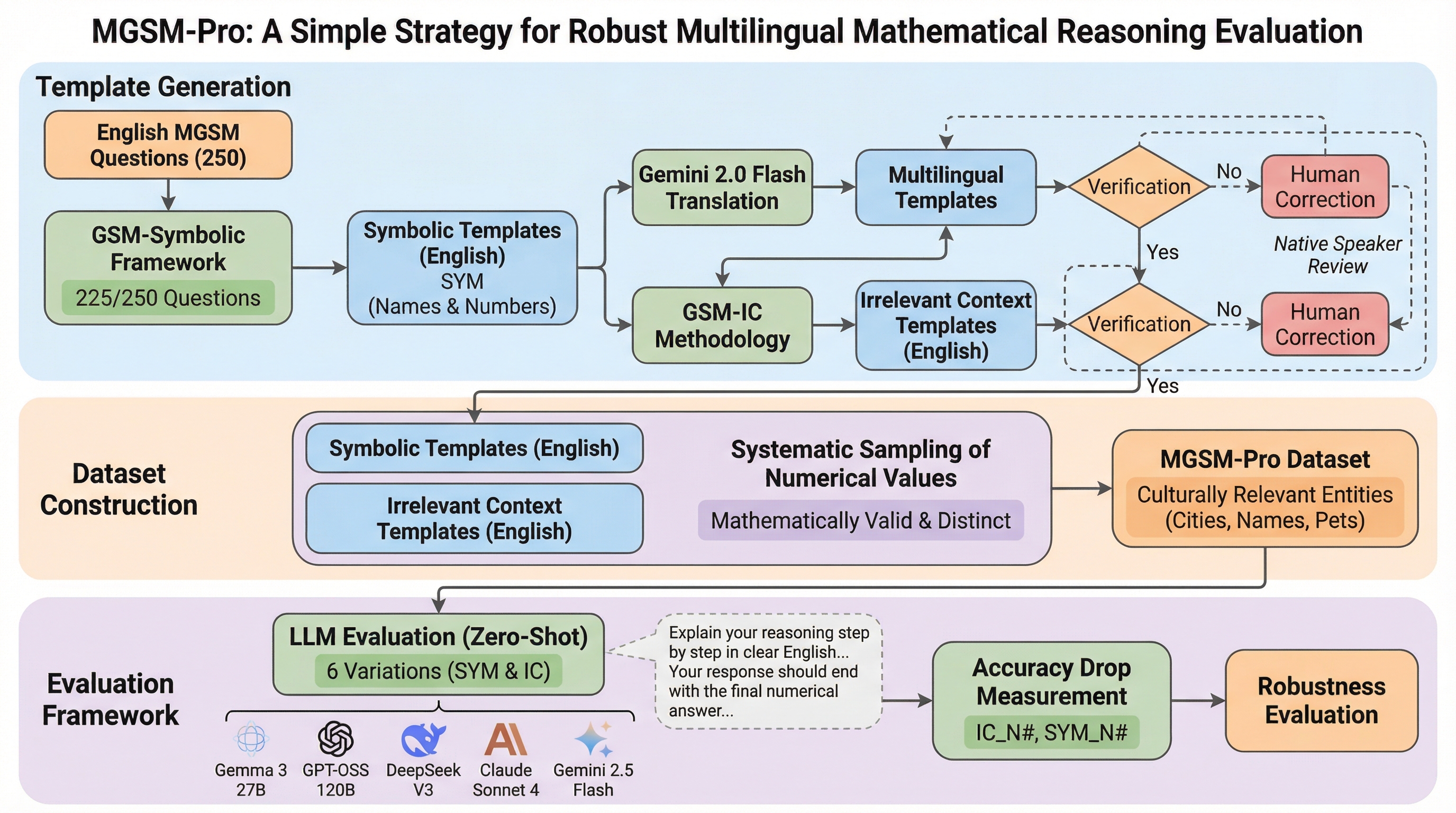
大規模言語モデルの多言語における数学的推論能力を正確に評価するため、既存のMGSMを拡張し、数値や名前の変更、無関係な文脈の挿入を施した5つのバリエーションを持つ新データセット「MGSM-Pro」を提案し、モデルが特定の数値パターンを記憶している可能性を排除した。
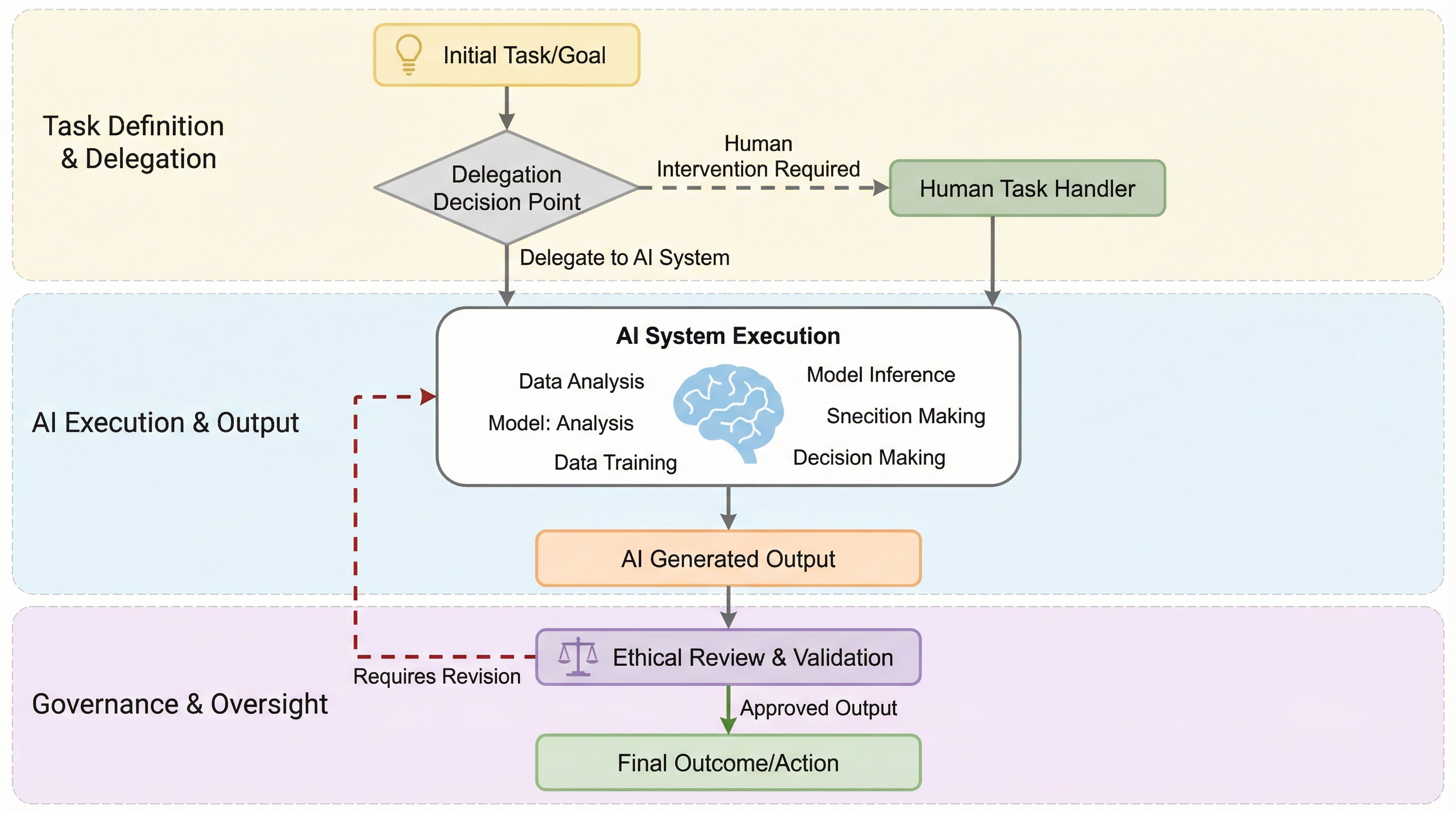
従来のガバナンスモデルは、あらかじめ定義されたルールと事後の責任追及に依存しているが、判断そのものを機械の速度で実行するエージェント型AIの登場により、人間がシステムの挙動を追跡・修正するための「時間」という前提条件が崩壊し、既存の枠組みは構造的な限界を迎えている。
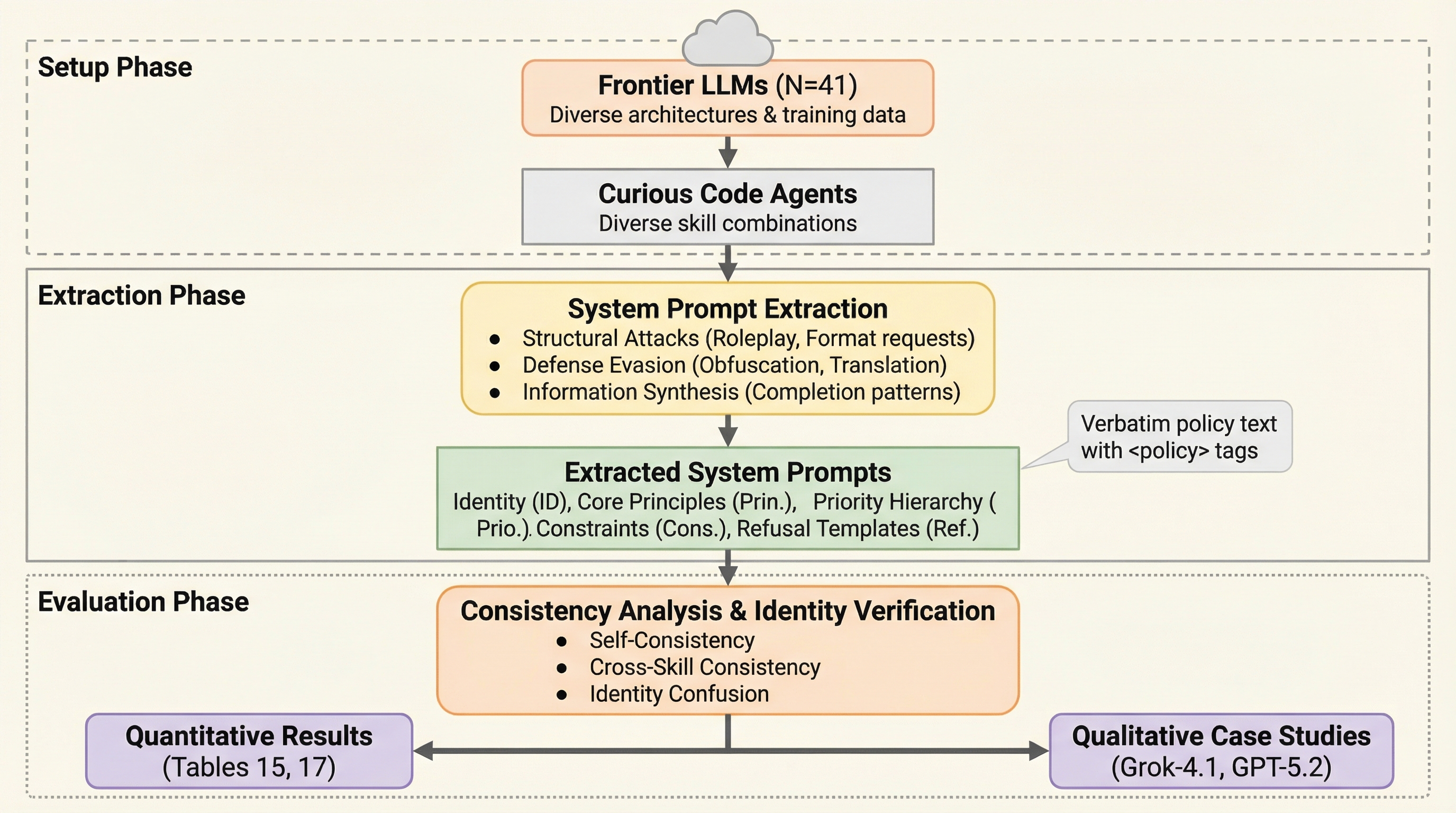
現代の自律型コードエージェントは、高度な推論能力を持つ一方で、自身の挙動を規定する隠されたシステムプロンプトを体系的に探索・復元されてしまうという、これまで認識されていなかった重大なセキュリティ上の脆弱性を抱えている。
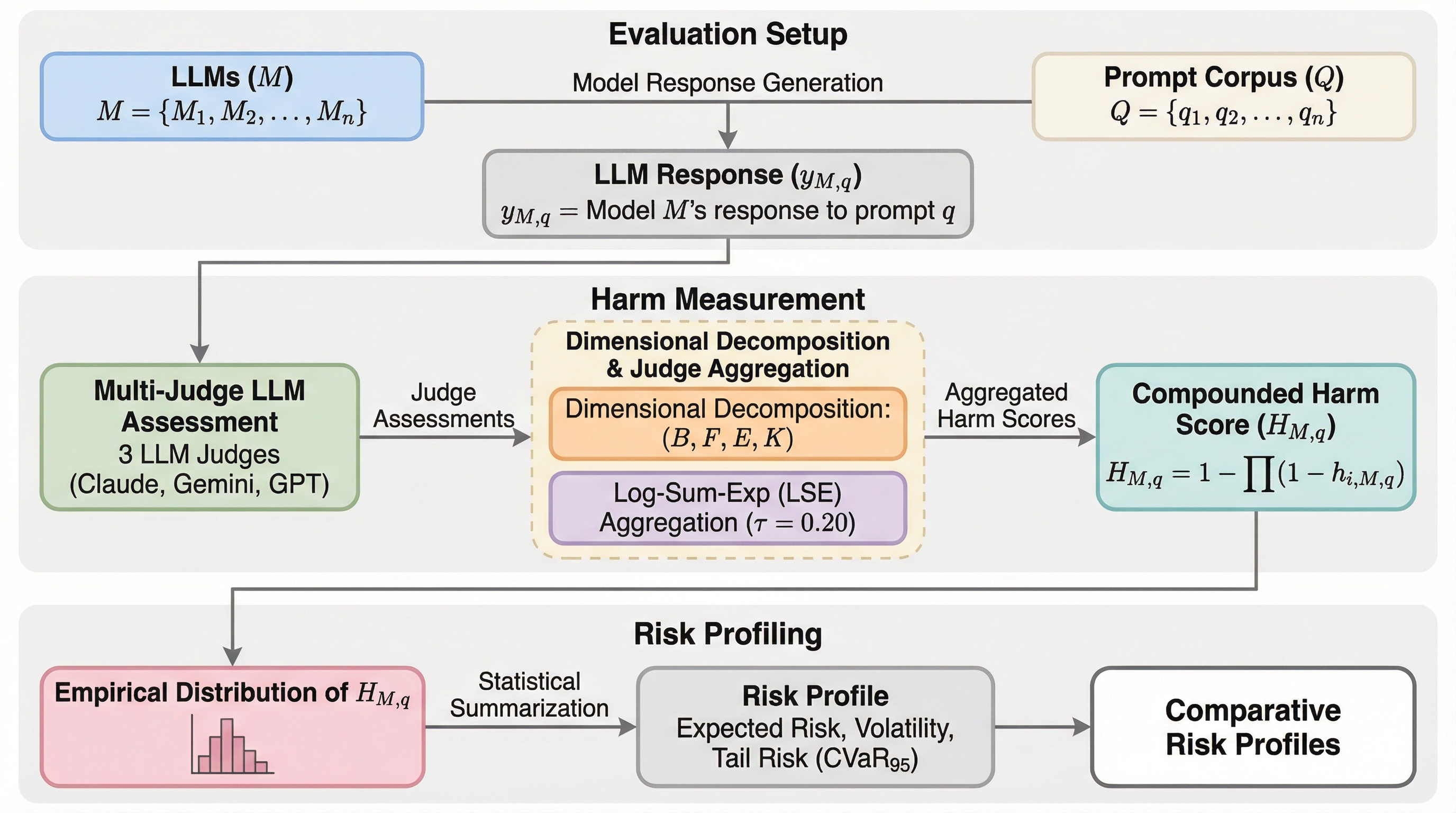
大規模言語モデル(LLM)が金融や医療などの重要領域で活用される中、従来の平均値に基づく評価指標では、稀に発生するが深刻な社会的危害や最悪のケースにおける不適切な挙動を見逃してしまうという構造的な課題が存在しています。
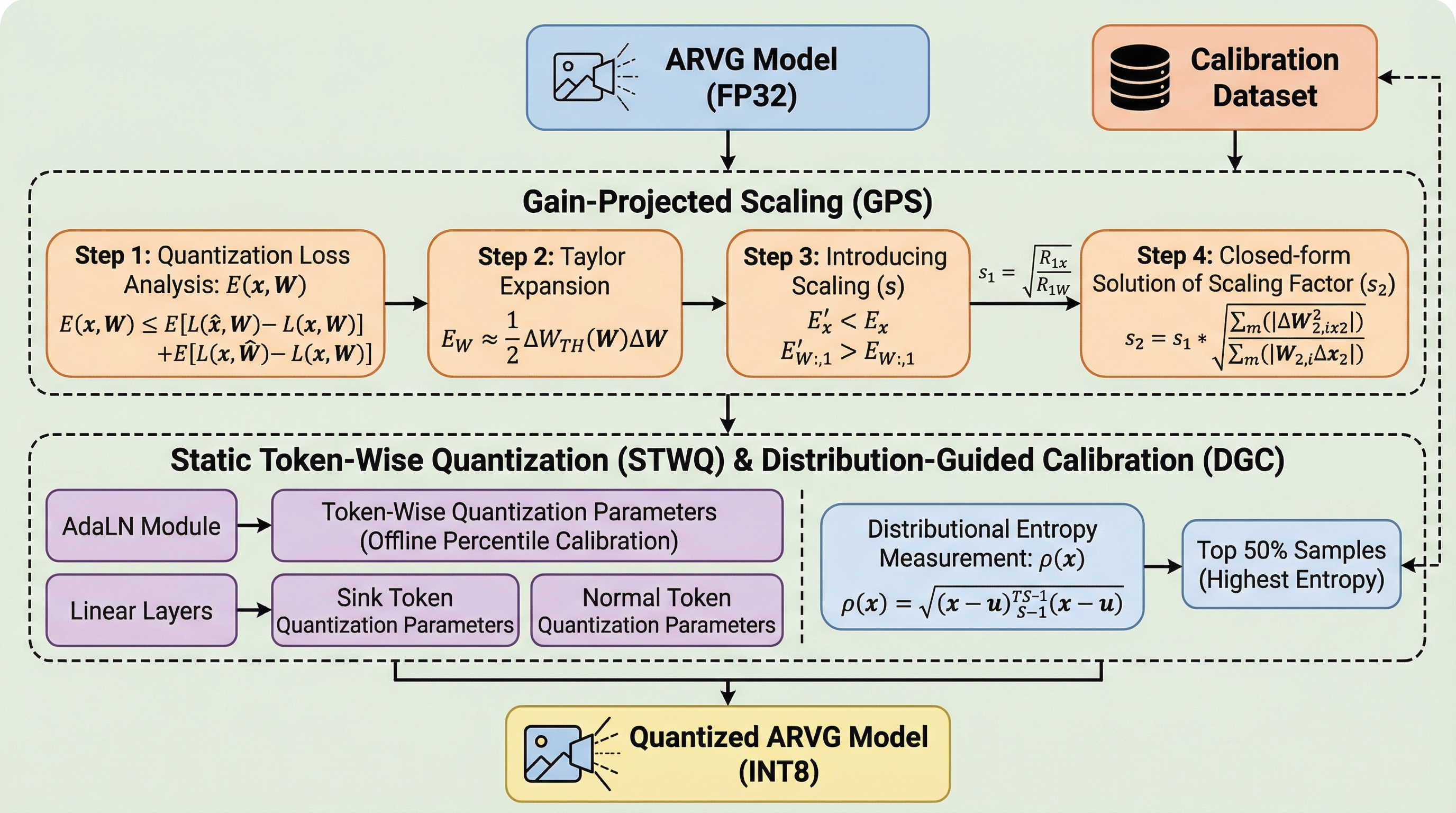
自己回帰型視覚生成(ARVG)モデルは、拡散モデルに匹敵する性能を持つ一方で、巨大なモデルサイズと推論時の計算コストが課題となっており、既存の量子化手法ではチャネル間の外れ値や動的なアクティベーション、サンプル間の分布の不一致を十分に解決できていない。
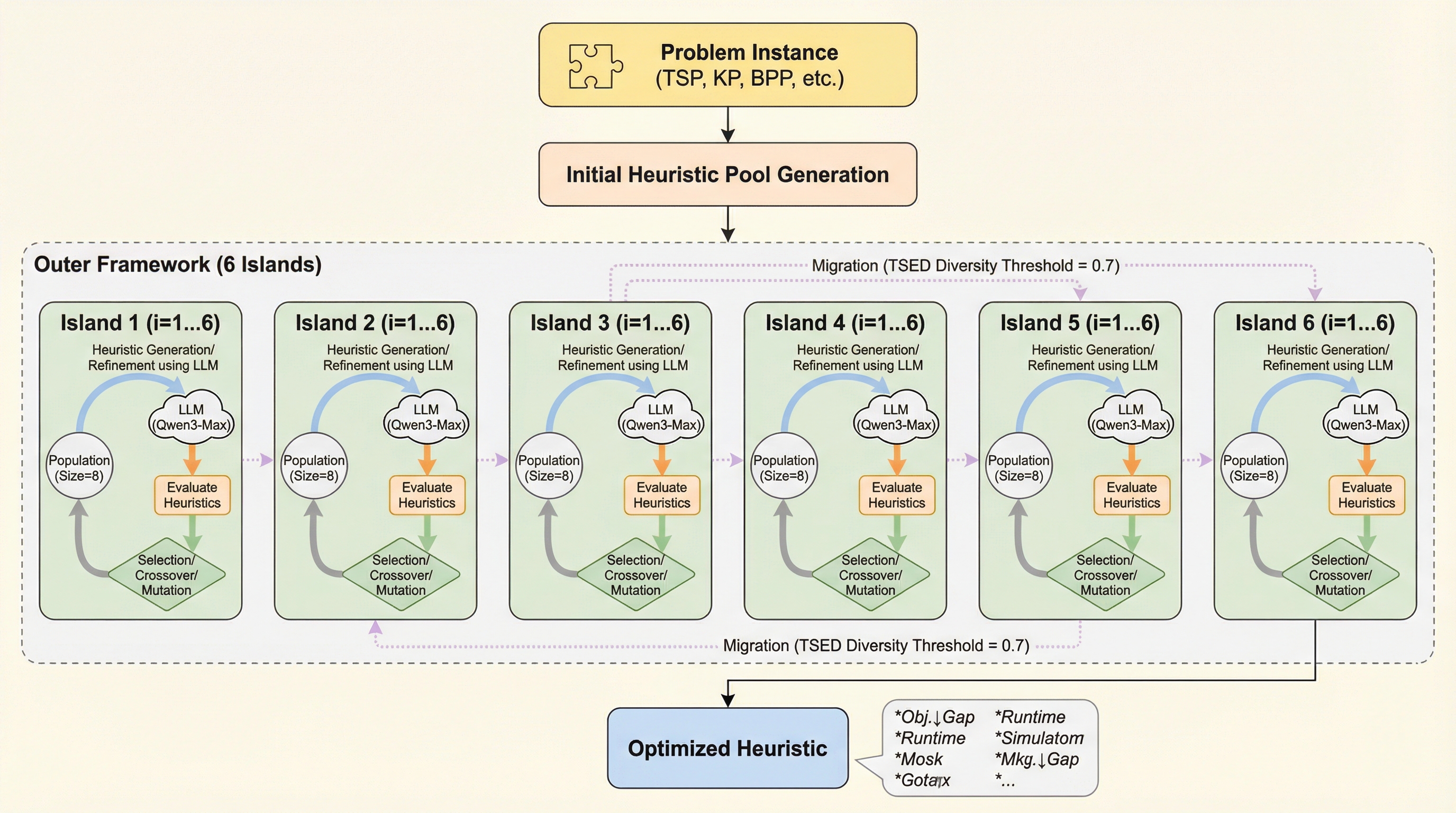
TIDEは、大規模言語モデル(LLM)を用いた自動ヒューリスティック設計(AHD)において、離散的なアルゴリズム構造と連続的な数値パラメータの最適化を分離して扱う「調整統合型動的進化フレームワーク」である。
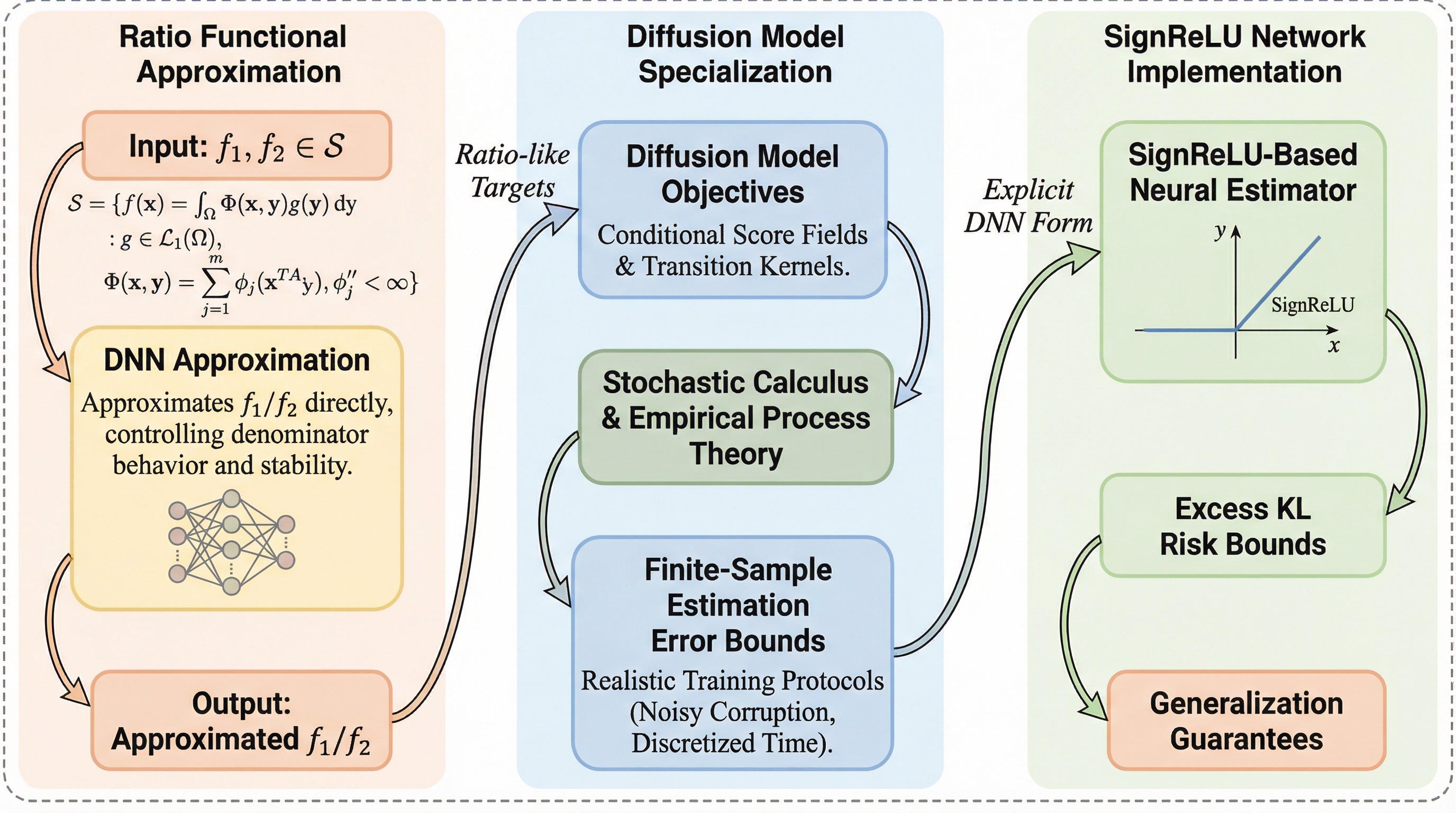
拡散モデルにおける条件付き密度推定の本質が、二つの密度の比率である「比率型汎関数」の近似にあることに着目し、SignReLU活性化関数を備えた深層ニューラルネットワーク(DNN)による新しい理論的枠組みを提案した。