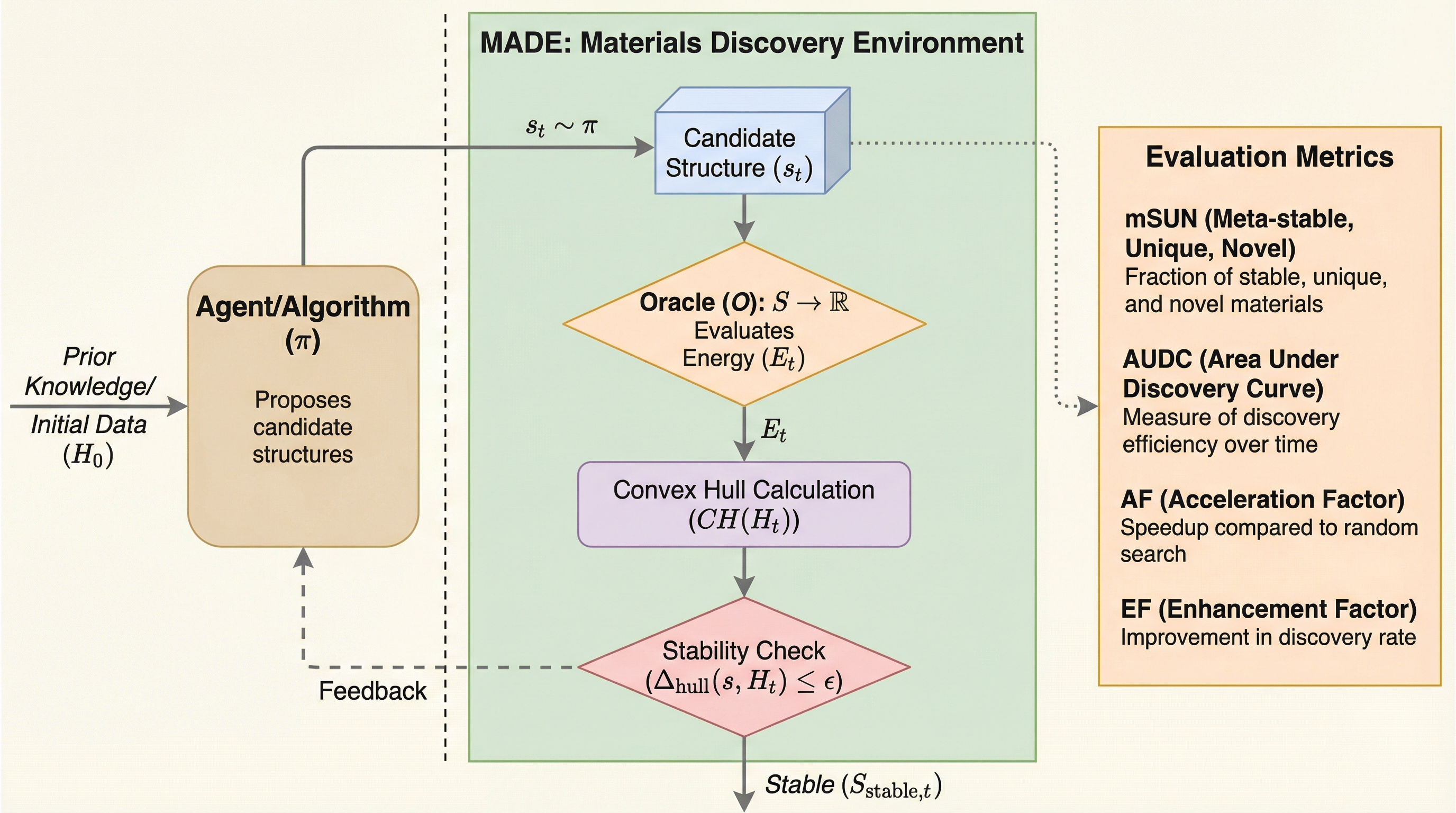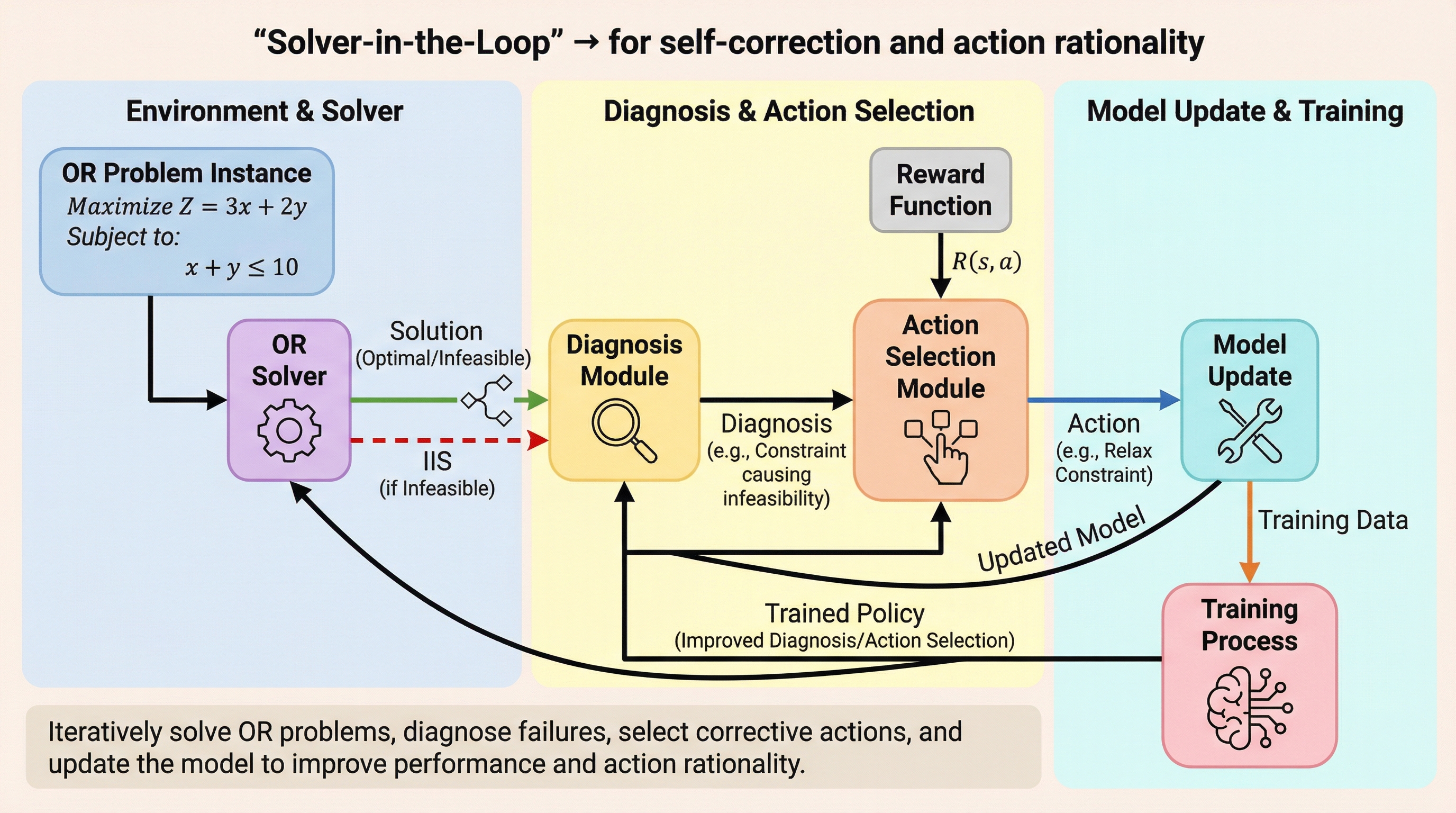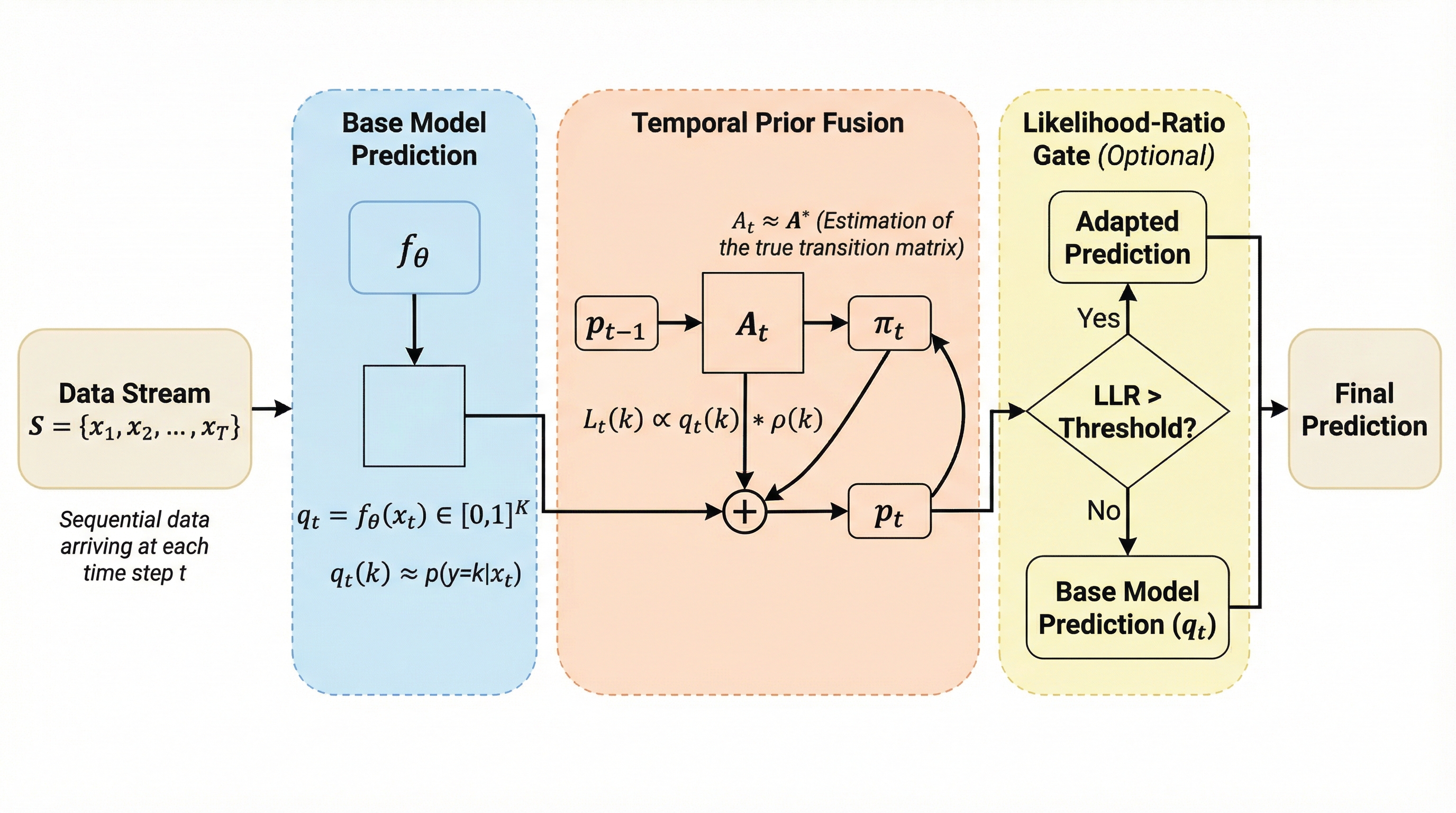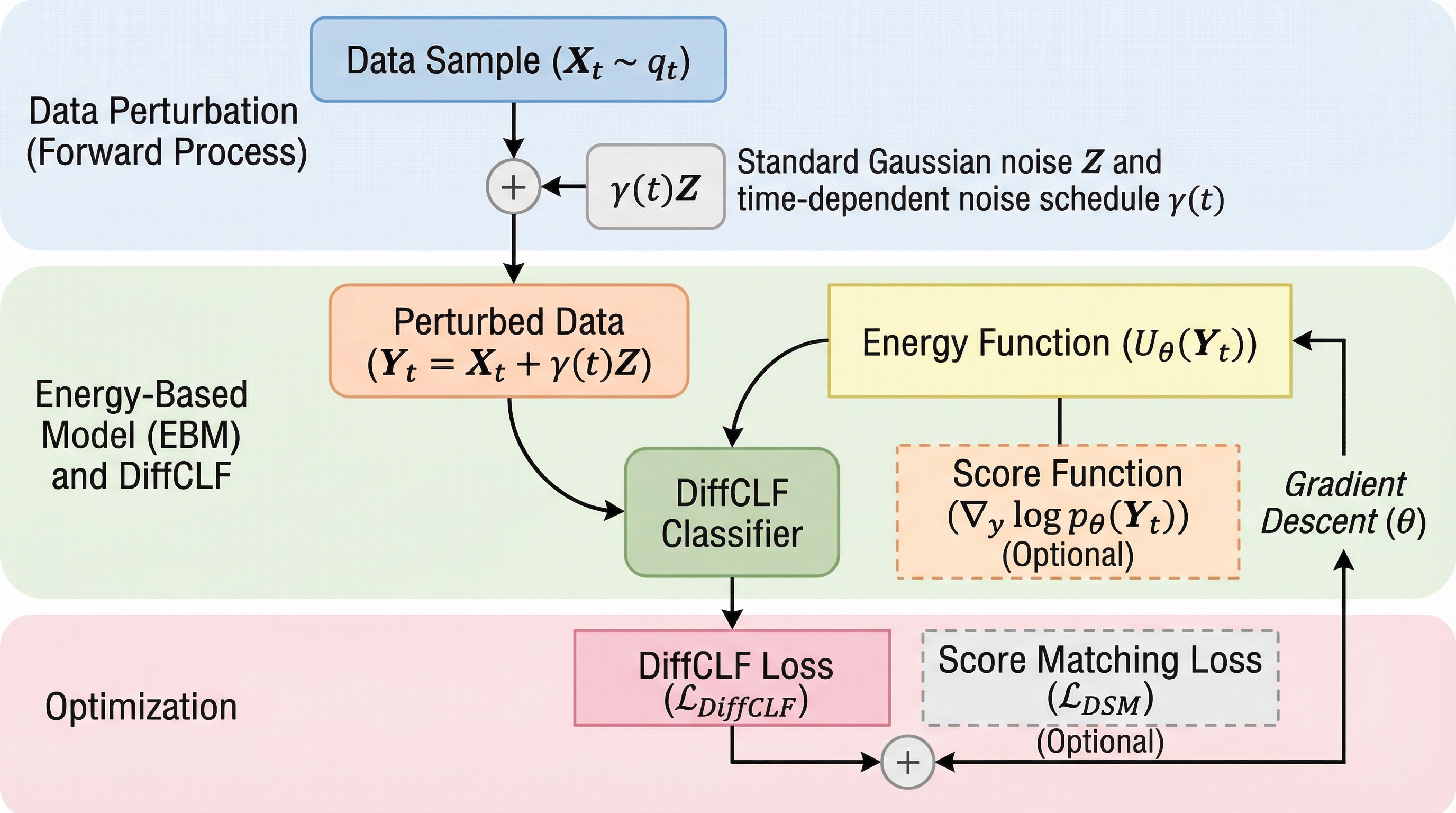
ノイズはあるが有効:不完全な評価者によるLLMの堅牢な統計的評価
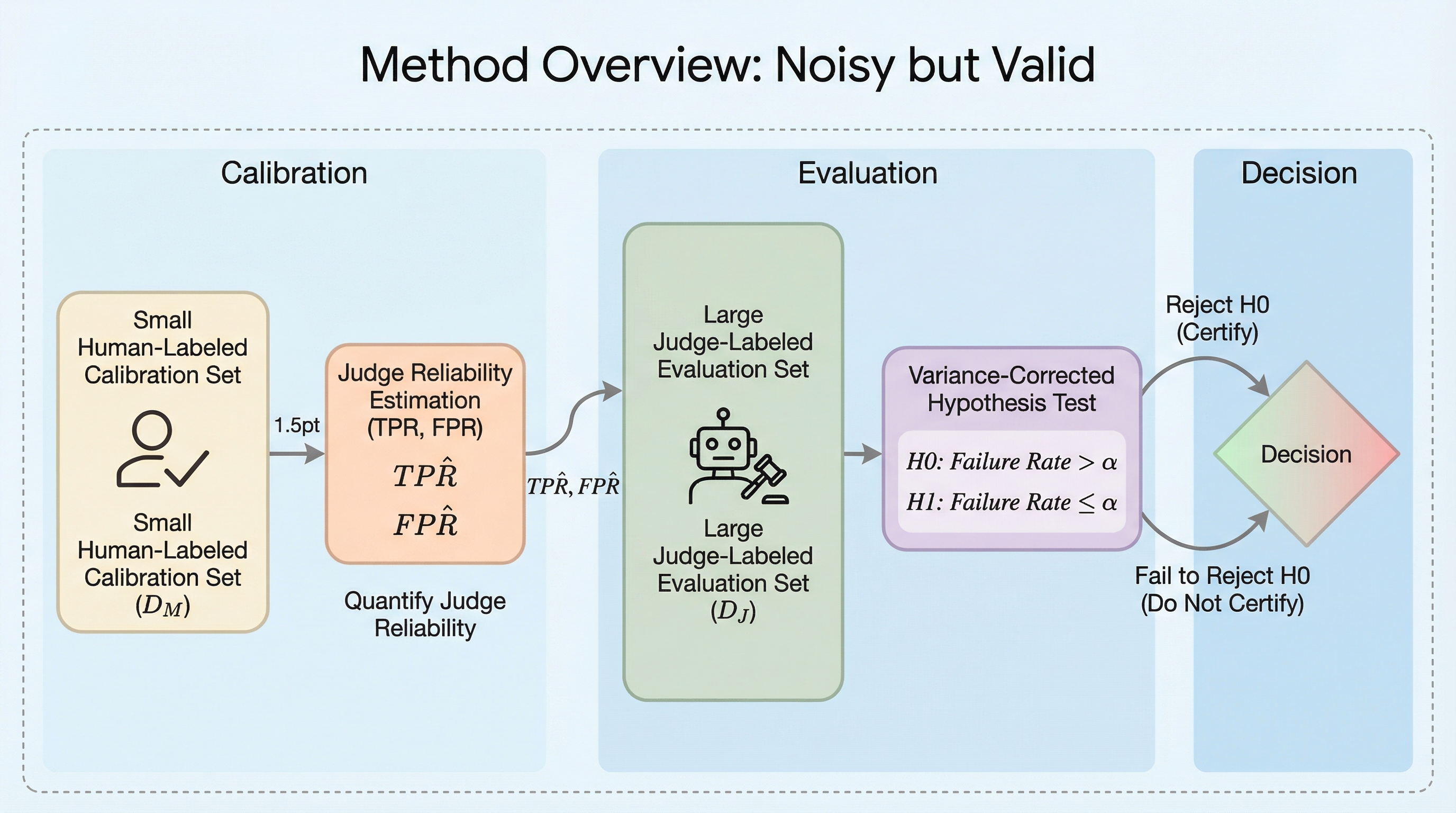
大規模言語モデル(LLM)の安全性を評価する「LLM-as-a-Judge」は、拡張性に優れる一方で評価者の誤りやバイアスが統計的信頼性を損なうという深刻な課題を抱えていたが、本研究は少量の人間によるラベル付きデータを用いて評価者の特性(真陽性率と偽陽性率)を精密に推定し、大規模な自動評価データセットに対して分散補正を適用する新しい統計的枠組み「Noisy but Valid」を提案することで、この問題を根本から解決した。 この枠組みは、評価者が不完全であっても、安全でないモデルを誤って合格させてしまう「第一種過誤」を理論的に有限サンプル内で厳密に制御することを保証しており、従来の人間による直接的な評価手法と比較して、評価者の品質が一定の基準を超えている場合には統計的な検出力を大幅に向上させることが可能であり、評価コストの劇的な削減と信頼性の向上を同時に達成している。 既存の予測駆動型推論(PPI)とは異なり、評価者のエラープロファイルを明示的にモデル化することで、評価プロセスの透明性と診断能力を確保しており、実務者が評価者の信頼性を客観的に判断し、データセットの規模や認定要件に応じた最適な評価プロトコルを設計するための理論的かつ実践的な基盤を提供している点が、本研究の最も重要な貢献である。