教師なし組合せ最適化のためのテスト時適応
従来の教師なしニューラル組合せ最適化(NCO)には、推論が高速な「汎用型モデル」と、個別の問題に特化して最適化を行う「インスタンス特化型モデル」という、互いに相容れない二つの手法が存在していました。
TL;DR(結論)
従来の教師なしニューラル組合せ最適化(NCO)には、推論が高速な「汎用型モデル」と、個別の問題に特化して最適化を行う「インスタンス特化型モデル」という、互いに相容れない二つの手法が存在していました。本研究では、学習済みの汎用モデルを単純に微調整するだけでは、ランダムな初期状態から最適化を始めるよりも性能が低下する場合があるという「不整合」の問題を特定し、これを解決するための新しいフレームワーク「TACO」を提案しています。提案手法は、学習済みの重みを適切に縮小・攪乱して初期化する戦略的なウォームスタートを導入することで、既習の知識を保持しつつ、個別の問題に対する柔軟な適応を可能にし、計算コストを抑えながら解の質を大幅に向上させることに成功しました。
なぜこの問題か
組合せ最適化(CO)問題は、物流のスケジューリング、ネットワークのルーティング、資源配分など、現代社会の多岐にわたる重要なアプリケーションにおいて中心的な役割を果たしています。しかし、これらの問題は本質的に離散的かつ非凸な構造を持っており、問題の規模が大きくなるにつれて、厳密な最適解を求めるための計算コストが爆発的に増大するという課題があります。近年、この困難な課題に対して、ニューラルネットワークを用いて解法(ヒューリスティック)を直接学習するニューラル組合せ最適化(NCO)が、伝統的なソルバーに代わる有望な選択肢として注目を集めてきました。特に、正解ラベルを必要としない教師なし学習の枠組みは、未知の問題に対しても柔軟に適用できるため、活発に研究が進められています。 しかし、既存の教師なしNCOには、大きく分けて二つの対立するアプローチが存在し、それぞれが解決困難な弱点を抱えていました。一つは、多様な問題インスタンスを通じて共通の構造を学習する「汎用性重視」のモデルです。…
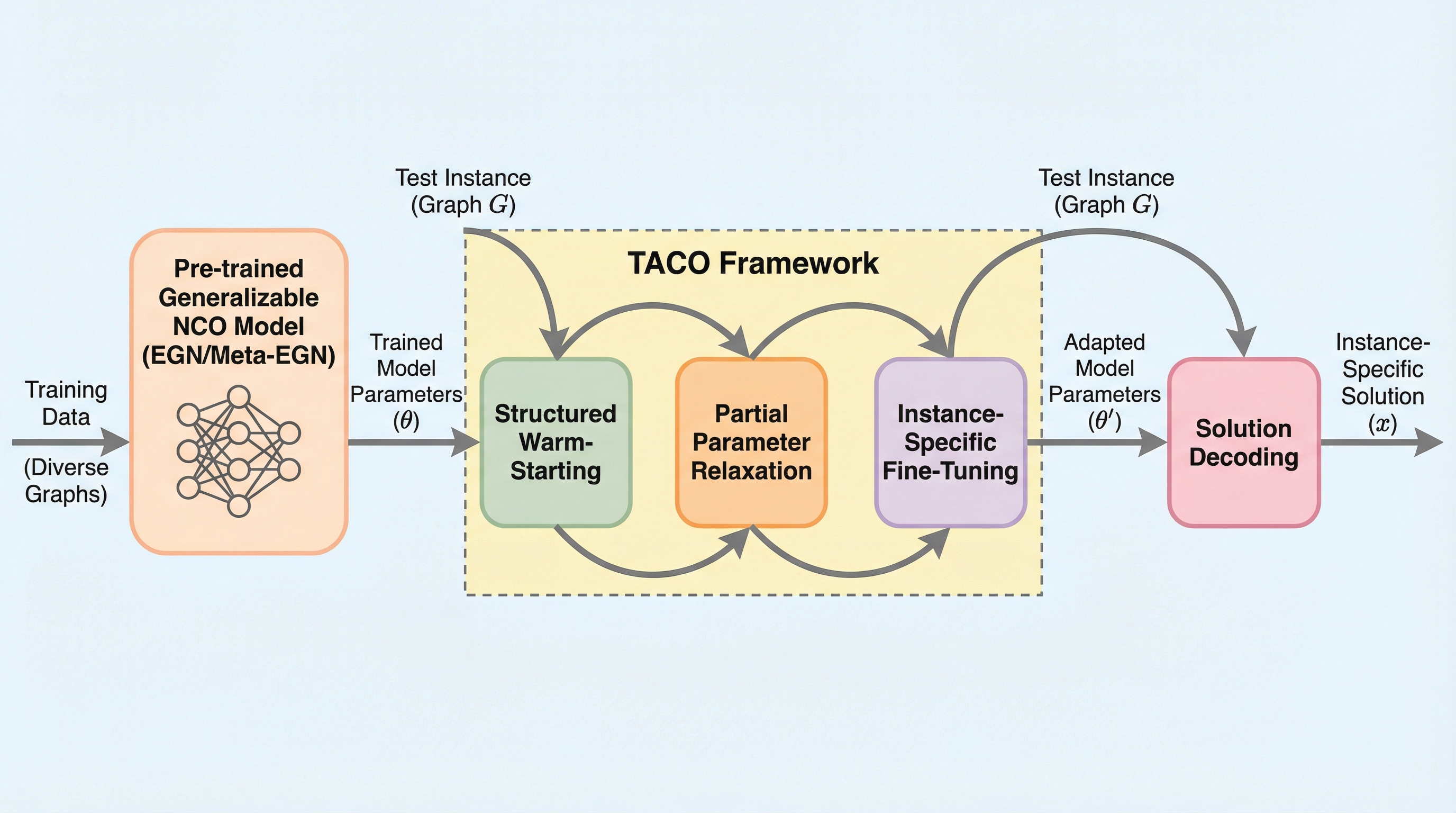
核心:何を提案したのか
本論文では、上述した二つのパラダイムを統合し、既存の教師なしNCOの限界を打破するためのモデルに依存しないテスト時適応フレームワーク「TACO(Test-time Adaptation for unsupervised Combinatorial Optimization)」を提案しています。TACOの核心的なアイデアは、学習済みの汎用NCOモデルを出発点としつつ、それを単純に微調整するのではなく、原理に基づいた「戦略的なウォームスタート」の手順を経て各テストインスタンスに適応させることにあります。これにより、モデルが学習過程で獲得した有益な「帰納バイアス(学習済みの知識)」を維持しながら、個別のインスタンスに対して柔軟に探索を行うための「適応の余地」を解放することに成功しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related