世界的な子どもの発達のための事前学習済みエンコーダ:転移学習がデータ不足の環境における展開を可能にする
毎年2億5000万人もの子どもが予防可能な発達の遅れに直面していますが、新しい国で機械学習モデルを導入する際には、数千規模のデータが必要になるという「データのボトルネック」が大きな障壁となっていました。
TL;DR(結論)
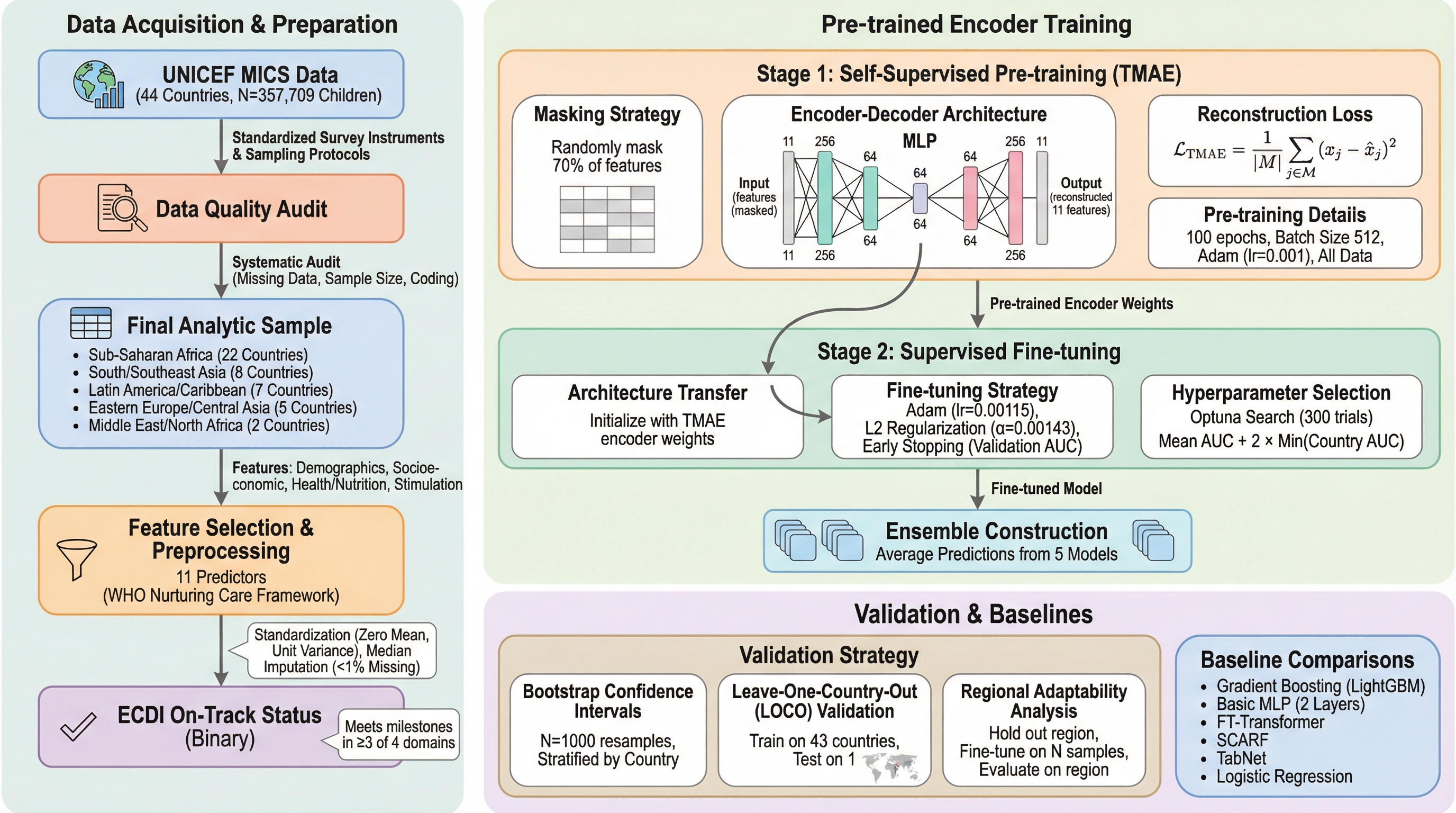
毎年2億5000万人もの子どもが予防可能な発達の遅れに直面していますが、新しい国で機械学習モデルを導入する際には、数千規模のデータが必要になるという「データのボトルネック」が大きな障壁となっていました。 本研究では、44カ国35万7709人の子どもを対象とした世界初の子どもの発達のための事前学習済みエンコーダを開発し、わずか50サンプルの学習データで平均AUC0.65を達成し、既存の勾配ブースティング手法を8〜12%上回る性能を示しました。 この技術により、リソースが限られた地域でも、50人から500人程度の小規模なパイロット調査から高精度な発達モニタリングを開始することが可能になり、持続可能な開発目標(SDG)4.2.1の達成に向けた大きな転換点となることが期待されます。
なぜこの問題か
世界では毎年、約2億5000万人の子どもたちが、本来であれば防ぐことが可能な発達の遅れを経験しています。子どもの脳の可塑性は5歳未満でピークに達するため、この時期の早期介入が極めて重要ですが、多くの中低所得国では3年から5年おきに実施される世帯調査でしか発達状況を把握できていません。調査結果が出る頃には、その世代の子どもたちはすでに重要な発達段階を過ぎてしまっているという深刻なタイムラグが存在します。機械学習はこのギャップを埋めるための「仮想的な監視」手段として期待されており、日常的な健康データや人口統計データから発達状態を予測する試みがなされてきました。 しかし、既存の機械学習モデルには「国をまたいだ転用ができない」という致命的な欠点がありました。例えば、ナイジェリアのデータで学習させた分類器をバングラデシュに適用しようとしても、文化的、経済的、あるいは医療体制の違いによるデータの分布のずれ(ドメインシフト)が発生し、予測精度が著しく低下してしまいます。このため、新しい国でモデルを導入するたびに、現地で数千人規模の信頼性の高いサンプルを収集し直す必要がありました。…
核心:何を提案したのか
本研究の核心は、世界の子どもの発達に関する「普遍的な知識」を学習した、世界初の子どもの発達専用の事前学習済みエンコーダの提案です。このモデルは、ユニセフ(UNICEF)が実施した第6回複数指標クラスター調査(MICS)のデータを利用し、44カ国にわたる35万7,709人の子どもの情報を学習しています。この膨大なデータセットには、サハラ以南のアフリカ、南・東南アジア、ラテンアメリカ・カリブ海諸国、東欧・中央アジア、中東・北アフリカといった多様な地域が含まれており、世界規模での子どもの発達の傾向を網羅しています。 提案された手法は、表形式データのための「マスク自己符号化器(Tabular Masked Autoencoder, TMAE)」というアーキテクチャを採用しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related