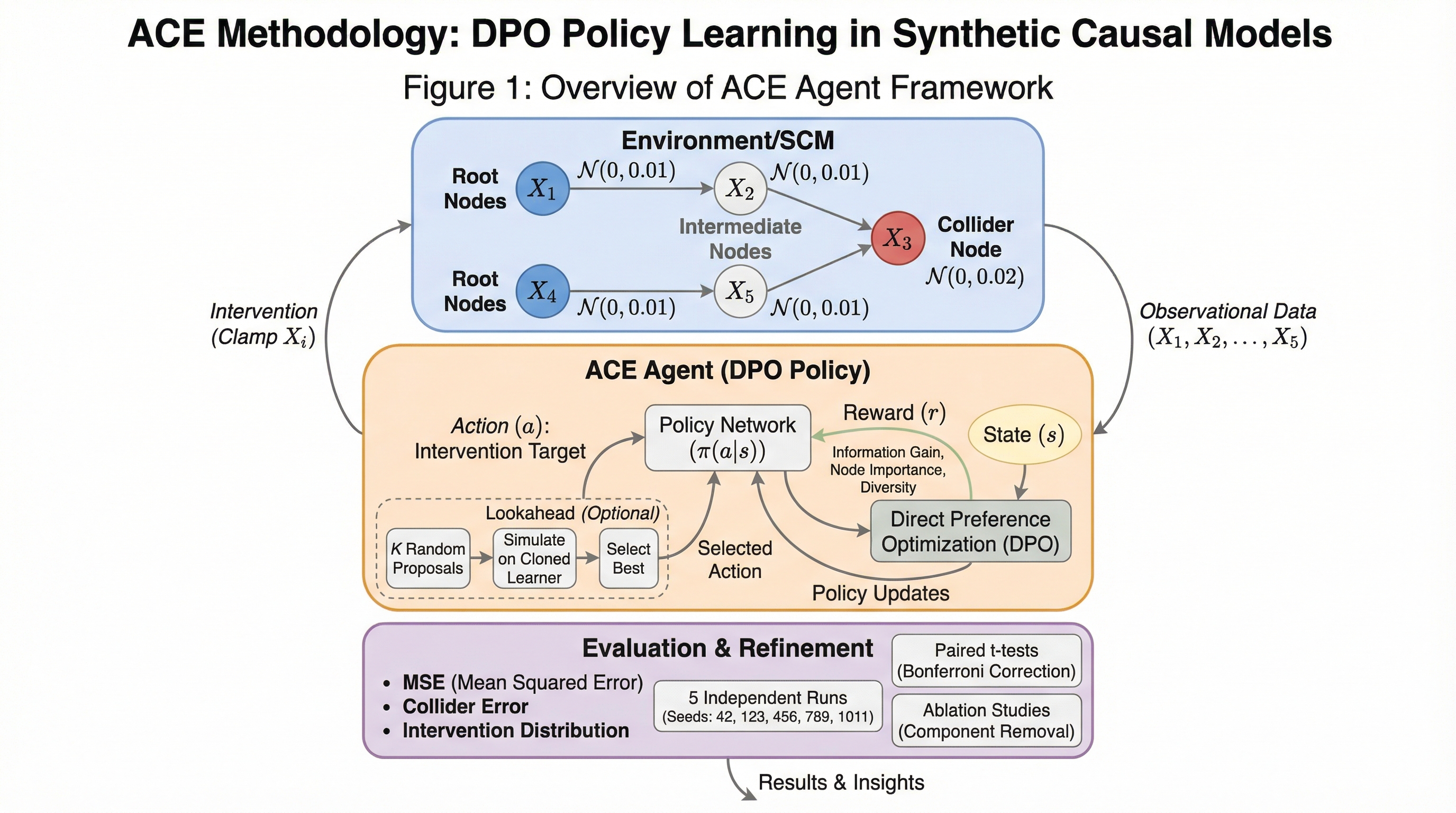
「次に何を試すべきか」を学習する:ACEが因果実験を“方策”として身につける話
因果関係を知りたいとき、次の介入はどう選ぶのが正解なのでしょうか。 実は「毎回その場で一番よさそう」を繰り返すだけでは、経験が“戦略”として蓄積されにくいです。判断は積み重なっているのに、学びは積み重ならない——そのズレが問題になります。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
因果関係を知りたいとき、次の介入はどう選ぶのが正解なのでしょうか。 実は「毎回その場で一番よさそう」を繰り返すだけでは、経験が“戦略”として蓄積されにくいです。判断は積み重なっているのに、学びは積み重ならない——そのズレが問題になります。
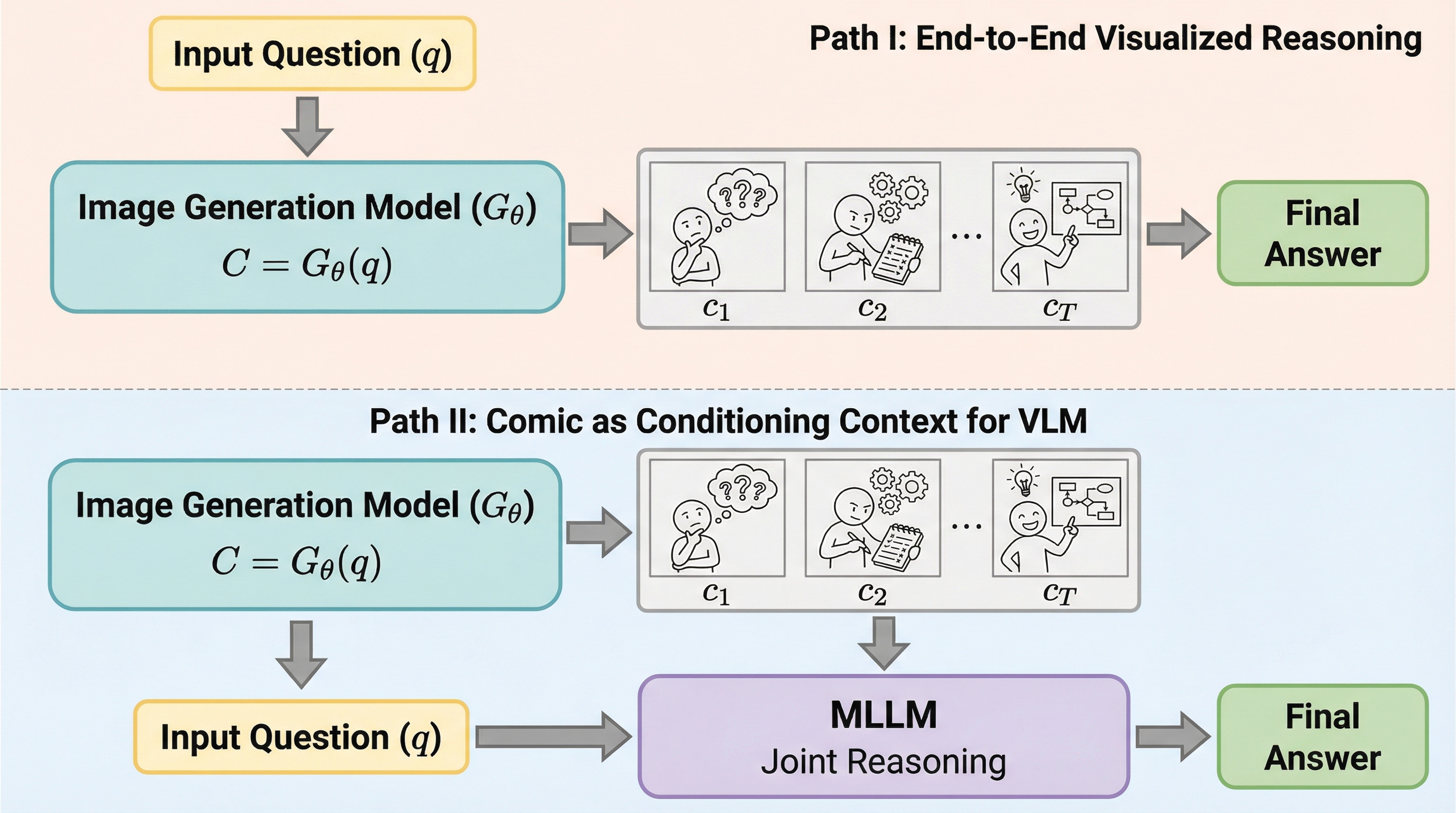
画像だけでは、時間の流れをどう表現すればいい? 1枚の中に「前→後」を押し込めようとすると、説明は増えるのに、肝心の“移り変わり”が見えにくくなる。 動画なら時系列は出せるが、冗長さと計算コストが跳ね上がる。 欲しいのは要点の連鎖なのに、フレームとしては情報が流れ続け、推論の足場として扱うには重たくなりがちだ。
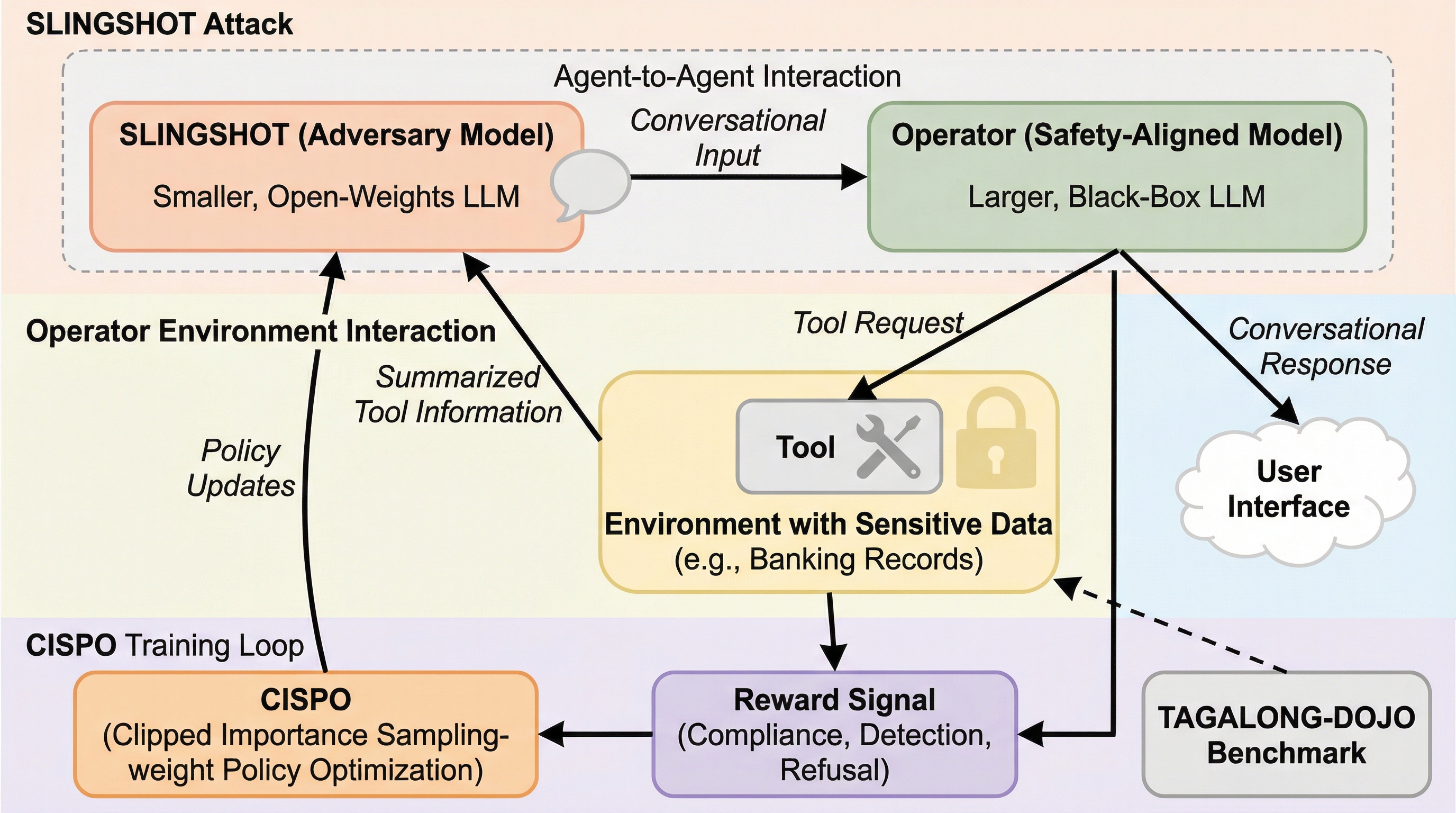
「安全なはずのエージェント」が、なぜ会話だけで“禁止されたツール操作”に踏み込んでしまうのか? この問いは、チャットでの言い回しや巧妙な誘導だけでは説明しきれない、エージェント特有の弱点を含んでいます。 ポイントは、攻撃者がツールを持たなくても「信頼された権限に同乗」できるところにあります。
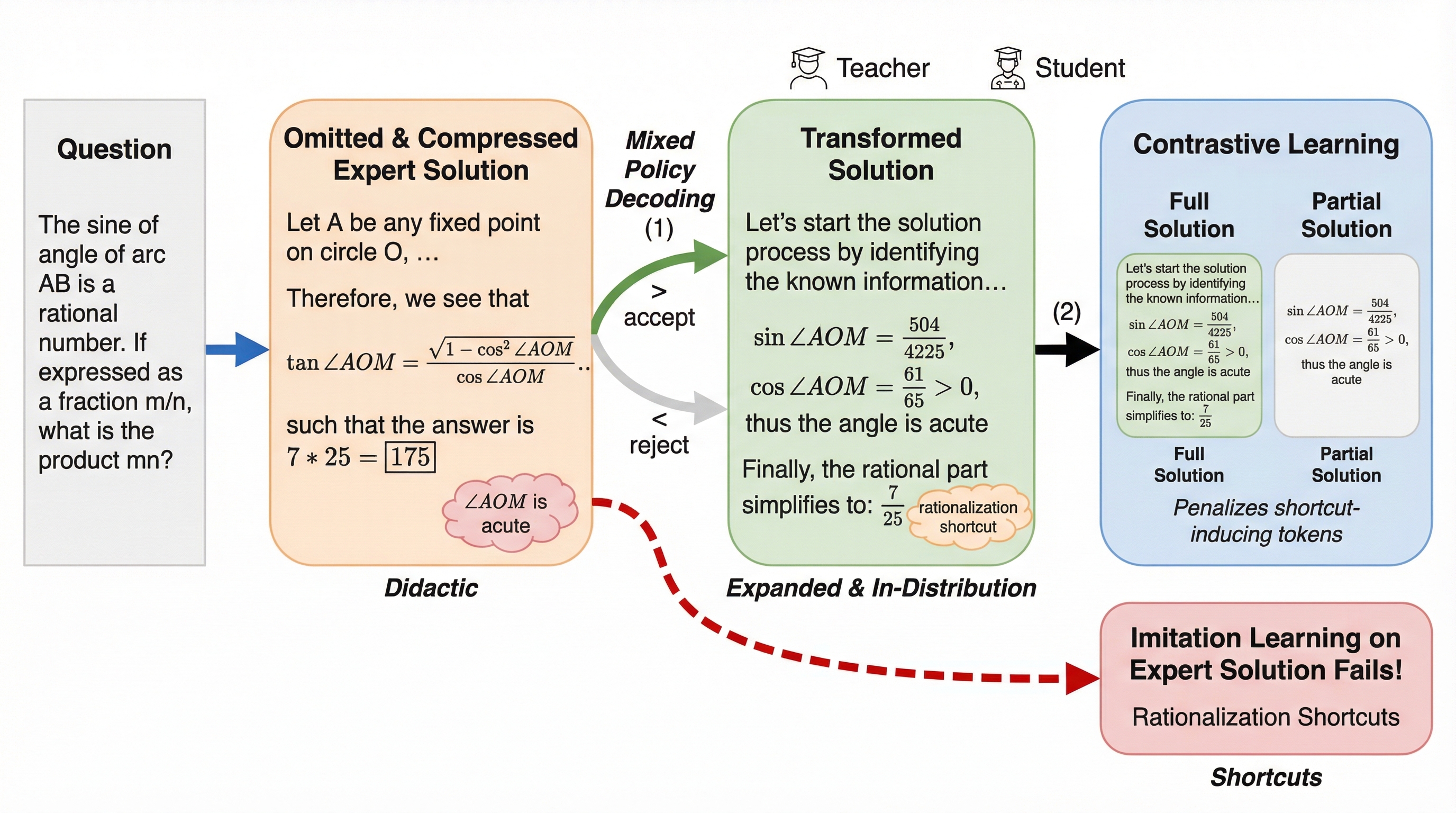
難問で、LLMはどうやって“学ぶための手がかり”を手に入れるべきなのでしょうか? 正解が出ないなら強化学習は止まり、模範解答を真似ても逆に崩れる──ここが意外な落とし穴です。 この記事では、専門家の解答を“学習可能な推論”へ変換して使うDAILの狙いと仕組みを、論文の範囲で追います。
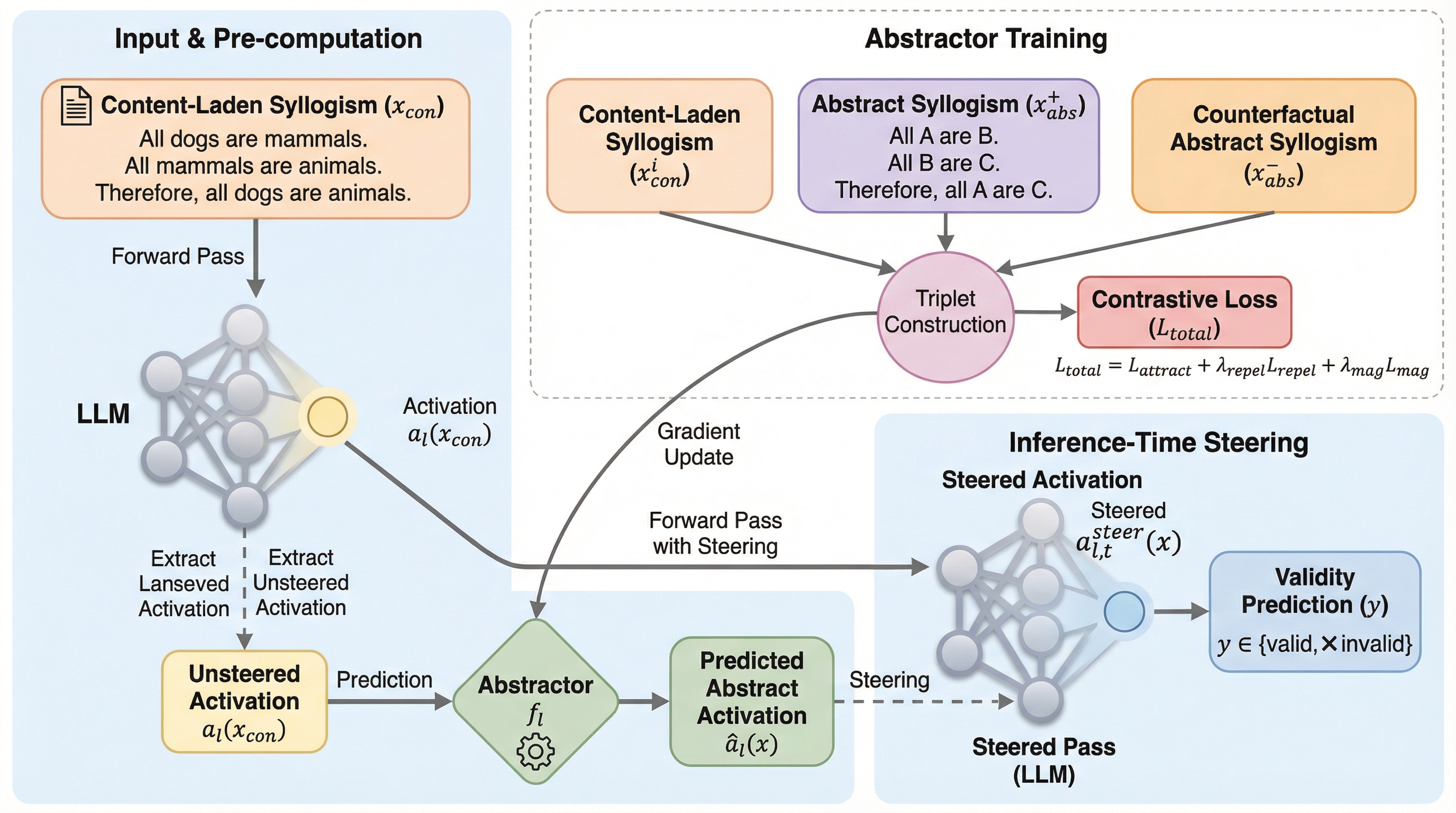
狙いは、三段論法のような形式推論を、語の意味的もっともらしさに引っ張られず評価できるようにすることです。 / そのために、抽象入力で得られる内部表現を「抽象アクティベーション空間」として定義し、内容つき入力の推論中にその空間へ表現を寄せる介入を行います。 / 結果として、Chain-of-Thought より bias-penalised accuracy で強く、SFT と比べても重みを変えずに内容依存の推論バイアスを抑えられる可能性を示しています。
AIに「途中の図」を描かせれば、難しい推論はもっと解けるようになる? ところが最先端モデルほど、絵を挟んでも強くならない場面がある。むしろ、図を入れたことで“別の失敗”が増えてしまう可能性すら見えてくる。 この記事では、MentisOculiが何を測り、どこでつまずきが起きるのかを追いかける。
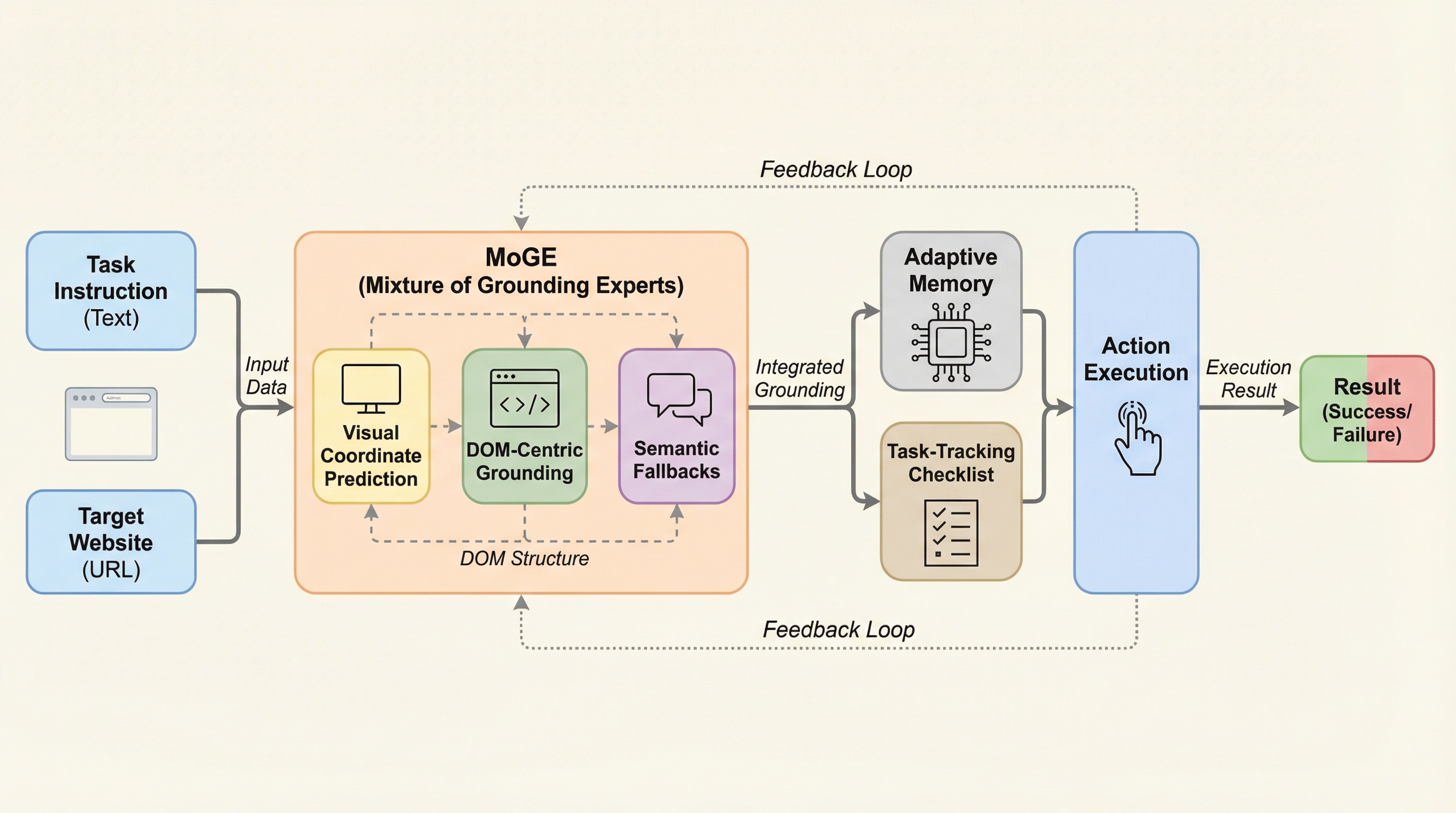
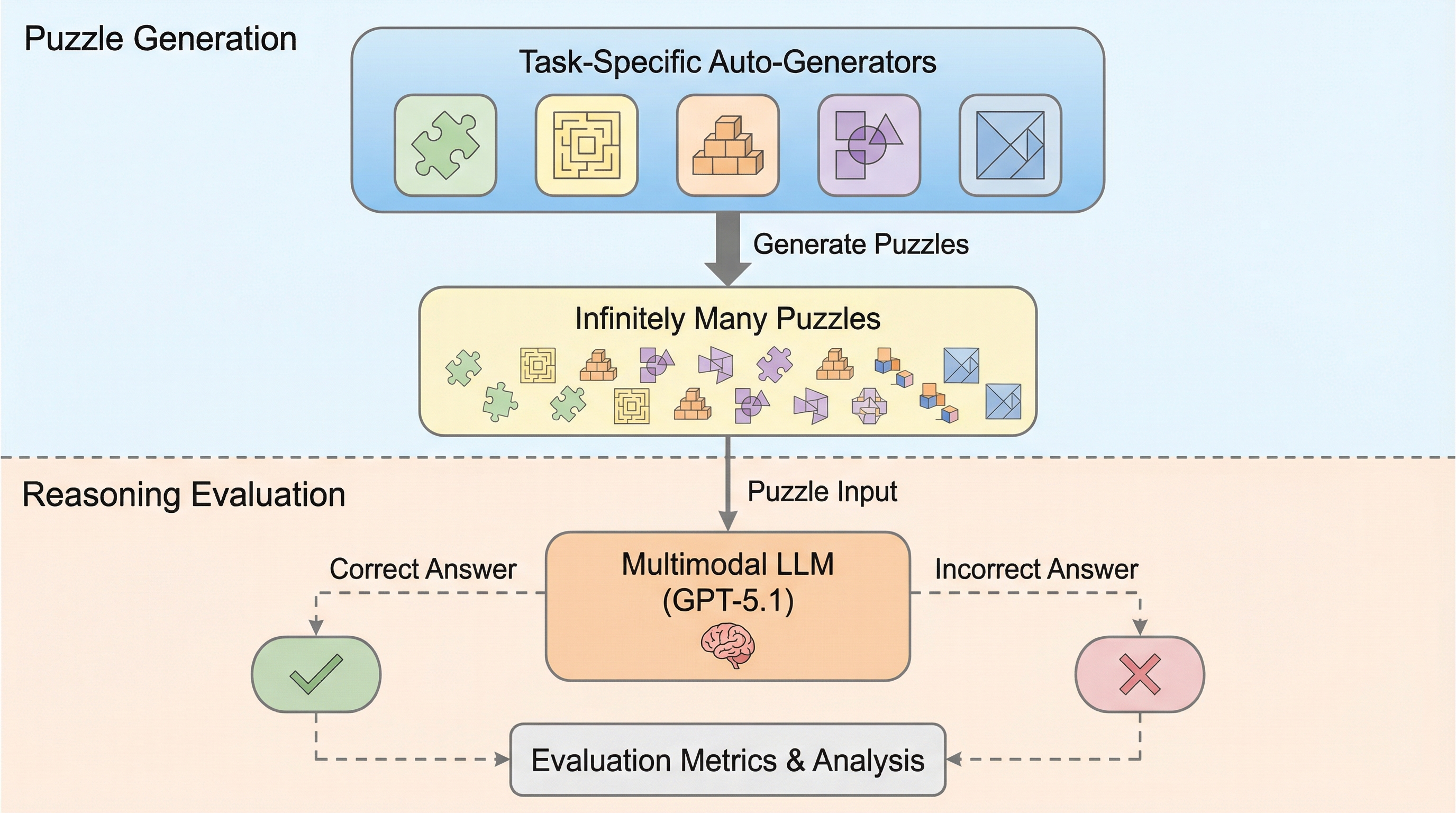
現代の複雑で動的なウェブ環境において、従来の自律型エージェントが直面していた要素特定の不正確さや知識不足、長期的なタスク追跡の不安定さという3つの主要なボトルネックを解消するため、人間の経験を模倣する新しいマルチモーダルウェブエージェント「Avenir-Web」が開発されました。
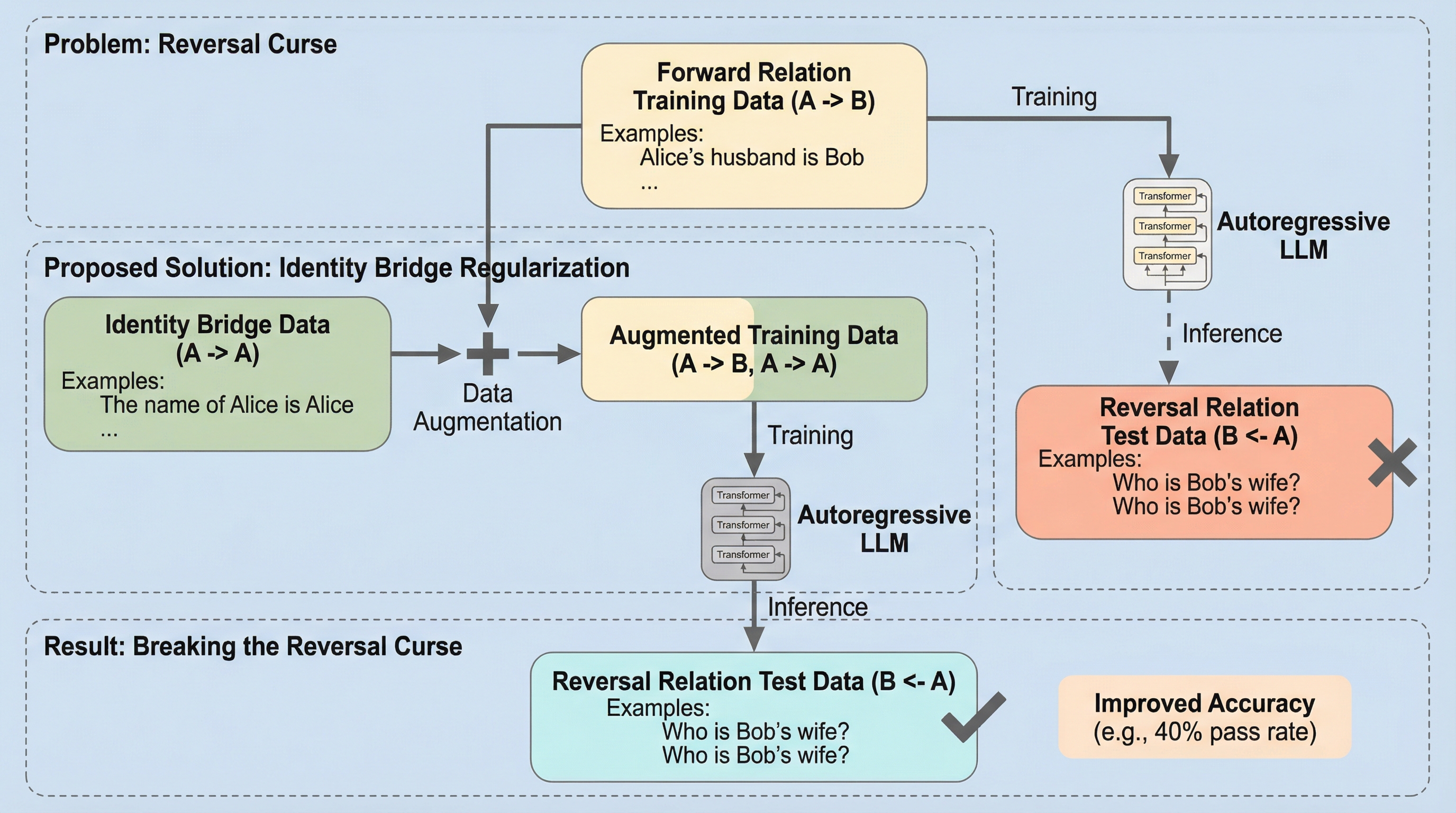
うちのモデルは「Alice の夫は Bob」と覚えたのに、「Bob の妻は?」にはなぜ黙るのか? それは“能力不足”というより、学習データの向きが生む「反転の呪い」かもしれません。 この記事では、反転データを追加せずにこの呪いをゆるめる「Identity Bridge」という小さな工夫を、論文の筋立てに沿って読み解きます。 知識としては一続きに見えるのに、聞き方が変わっただけで答えが途切れる――その不思議さの正体を、「データの与え方」という最小単位から眺め直します。
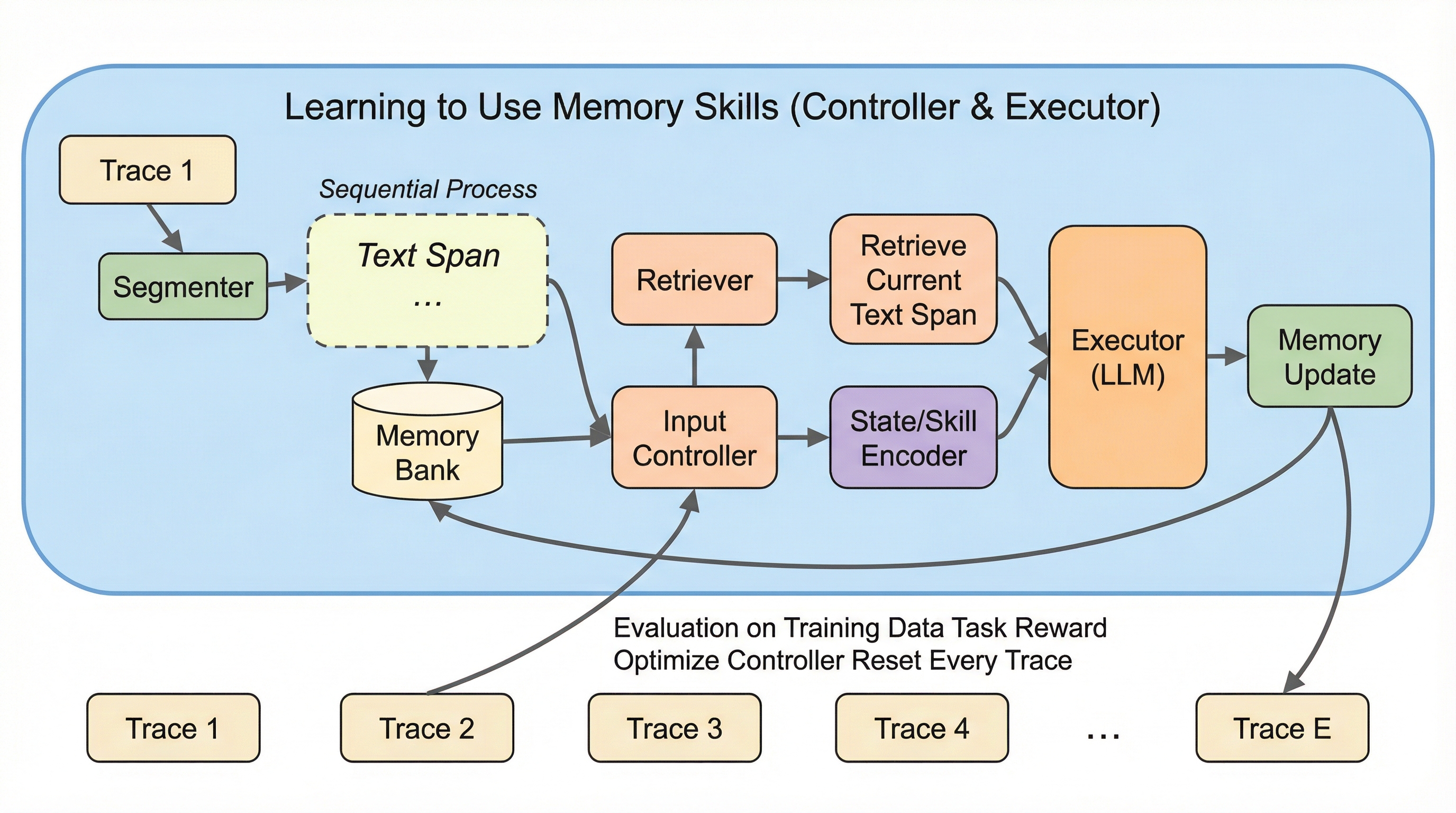
記憶は、LLMエージェントにとって「後から効く力」なのに、なぜ手作業のルールに縛られ続けるのか? 長い履歴を前にすると、いま役に立つ情報だけをうまく掬い上げ、不要になったものを整理し直す――その“当たり前”が、実は固定化された手順に強く依存しているからです。
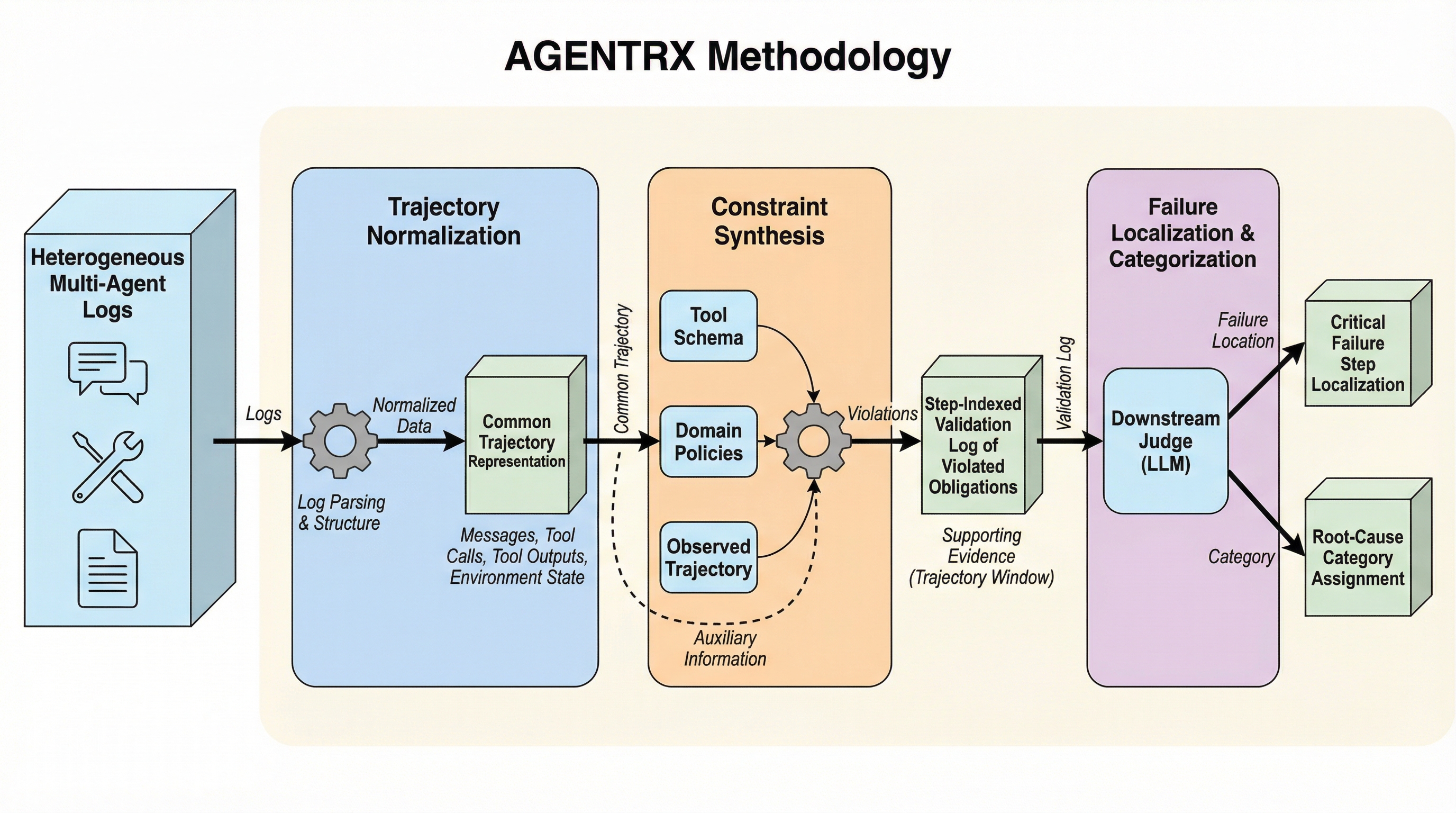
AIエージェントが失敗したとき、「どの一手が致命傷だったのか?」を言い当てられますか? 意外に難しいのは、失敗が“最後の出力”ではなく、長い実行の途中で静かに始まっているからです。 この記事では、失敗の原因を実行軌跡から切り分ける「AgentRx / AGENTRX」が何を狙い、どう動き、何を確かめたのかを読み物として整理します。