Identity Bridgeによる自己回帰言語モデルのリバーサル・カースの打破
うちのモデルは「Alice の夫は Bob」と覚えたのに、「Bob の妻は?」にはなぜ黙るのか? それは“能力不足”というより、学習データの向きが生む「反転の呪い」かもしれません。 この記事では、反転データを追加せずにこの呪いをゆるめる「Identity Bridge」という小さな工夫を、論文の筋立てに沿って読み解きます。 知識としては一続きに見えるのに、聞き方が変わっただけで答えが途切れる――その不思議さの正体を、「データの与え方」という最小単位から眺め直します。
論文図解
TL;DR(結論)
- 論文の提案は、派手な新アーキテクチャではありません。
- 学習データの“ちょい足し”です。
- 論文は、Identity Bridge がなぜ効きうるのかを、理論と見取り図で説明します。
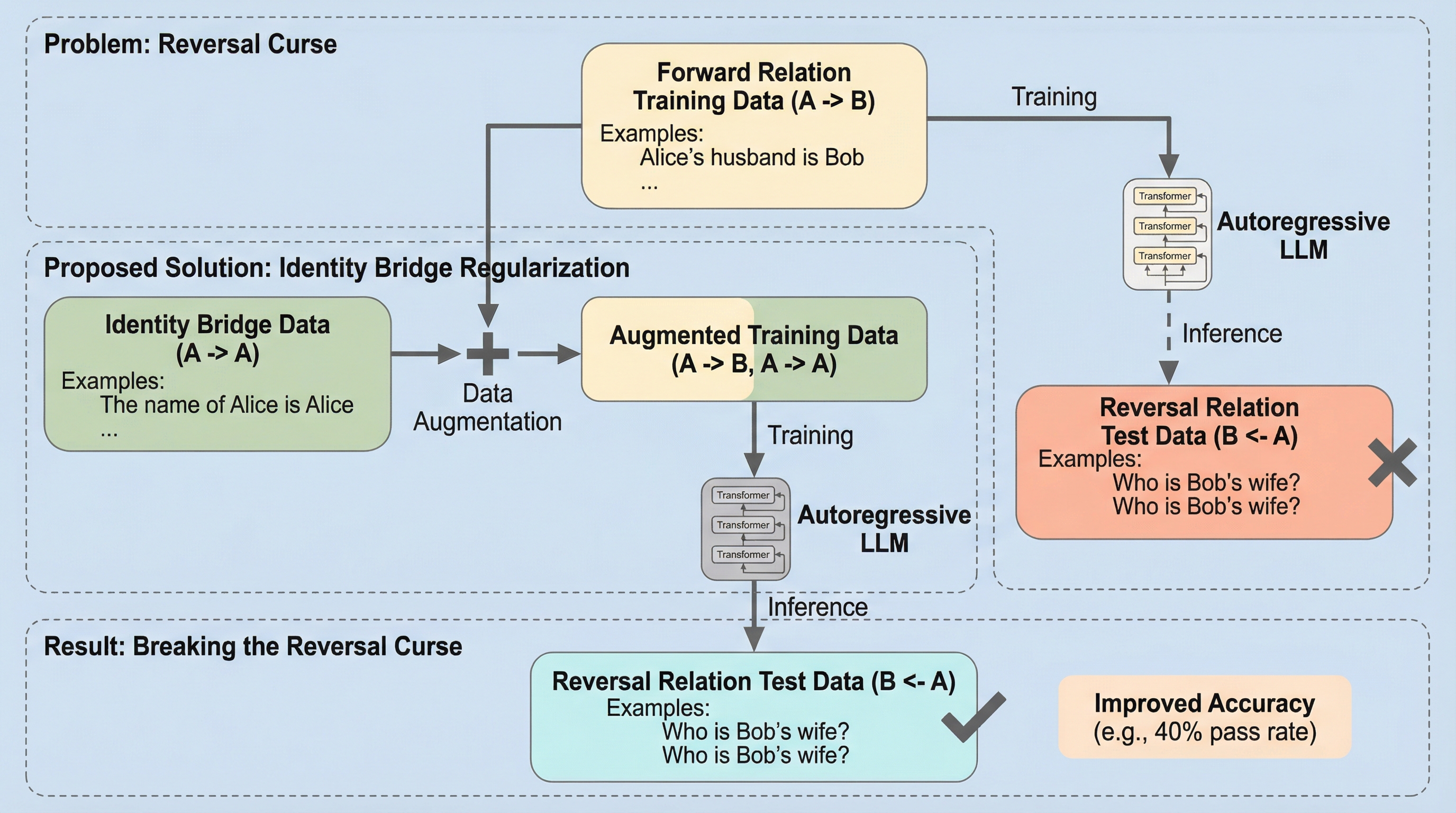
なぜこの問題か
自己回帰型の大規模言語モデル(LLM)は、複雑なタスクで目覚ましい成功を収めてきました。ところが、驚くほど単純な論理でつまずくことがある。論文が取り上げる代表例が「reversal curse(反転の呪い)」です。派手な難問ではなく、むしろ「知っているなら当然ひっくり返せるはず」という種類の問いで止まるところに、痛さがあります。
核心:何を提案したのか
論文の提案は、派手な新アーキテクチャではありません。学習データの“ちょい足し”です。ここがまず重要で、モデルの外側(構造や学習手続き)ではなく、モデルに渡す例の形そのものに働きかけています。しかも“ちょい足し”は、反転例の追加ではなく、もっと素朴な同一性の例です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related