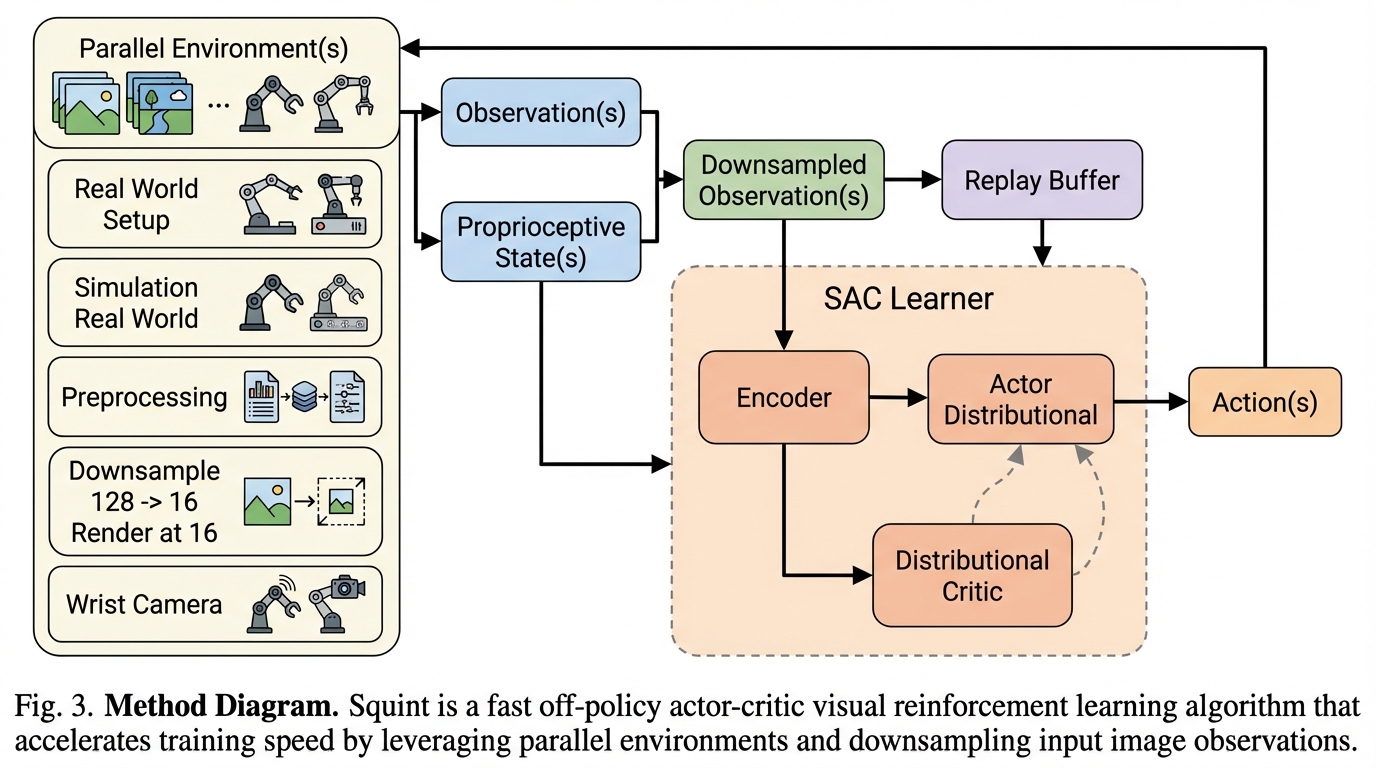
Squint:視覚強化学習を「分」で回し、15分学習の方策をSim-to-RealでSO-101へゼロショット展開する高速SAC
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
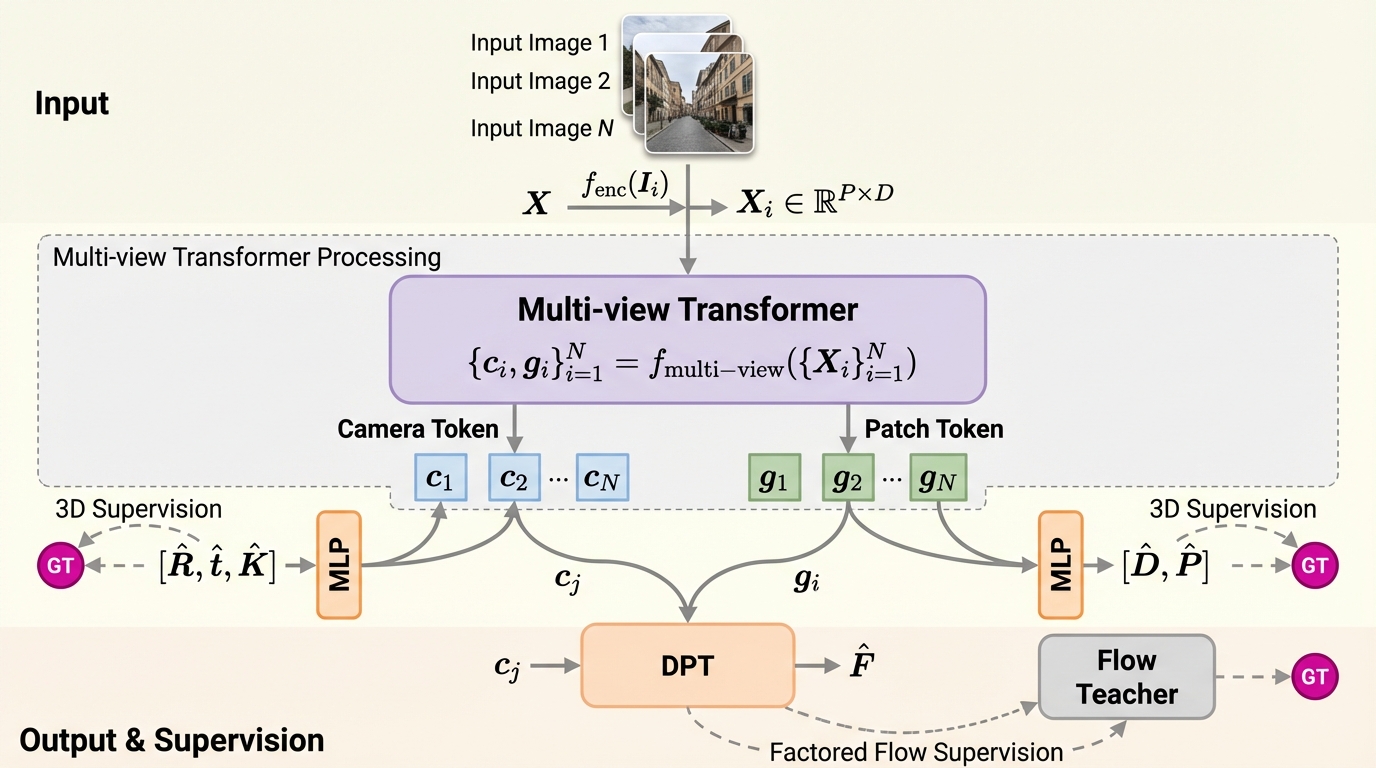
Flow3rは、密な3D形状やカメラ姿勢の教師信号に強く依存してきた3D/4D復元を、画像間の密な対応関係(フロー)を監督信号として使うことで、未ラベルの単眼動画へ学習を広げる枠組みです。 / 2枚の画像のフローを、片方の画像から得る幾何の潜在表現と、もう片方の画像から得る姿勢(カメラ)の潜在表現を組み合わせて非対称に予測する設計を中核にし、既存の視覚幾何アーキテクチャへ統合して約80万本規模の未ラベル動画も学習に利用します。 / 制御実験では代替のフロー設計より良い結果が示され、未ラベル動画を増やすほど一貫して性能が伸び、静的・動的にまたがる8つのベンチマークで最先端の結果を達成し、特に野外の動的動画のようにラベルが乏しい条件で改善が大きいと報告されています。
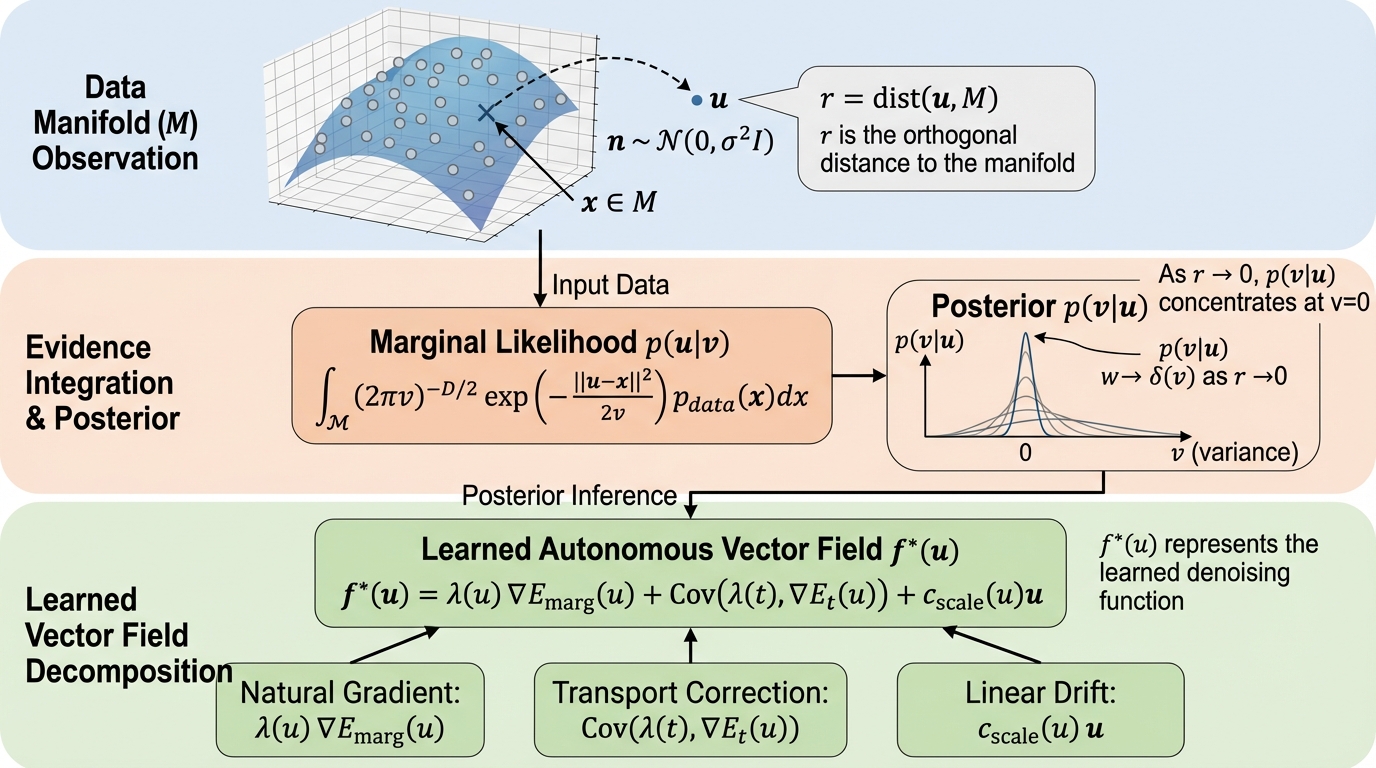
ノイズレベルを入力しない自律(ノイズ非依存)生成モデルでも、学習された単一の時間不変ベクトル場は「闇雲なデノイズ」ではなく、未知ノイズを周辺化した周辺密度 \(p(\mathbf{u})=\int p(\mathbf{u}\mid t)p(t)\,dt\) に対応する周辺エネルギー \(E_{\text{marg}}(\mathbf{u})=-\log p(\mathbf{u})\) の幾何と結び付いています。 / ただし周辺エネルギーの生の勾配はデータ多様体の法線方向に \(1/t^p\) 型の特異性を持ち、通常の勾配降下では不安定になり得ますが、論文は相対エネルギー分解により、学習場が局所的な共形計量(実効ゲイン)を暗黙に含むリーマン勾配流として振る舞い、特異性を前処理して打ち消す構図を示します。 / さらに自律サンプリングの構造安定性条件を与え、ノイズ予測パラメータ化には推定誤差を増幅し得る「Jensen Gap」がある一方、速度ベースのパラメータ化は有界ゲイン条件により後部分布の不確実性を滑らかな幾何学的ドリフトへ吸収できる、という含意を導きます。
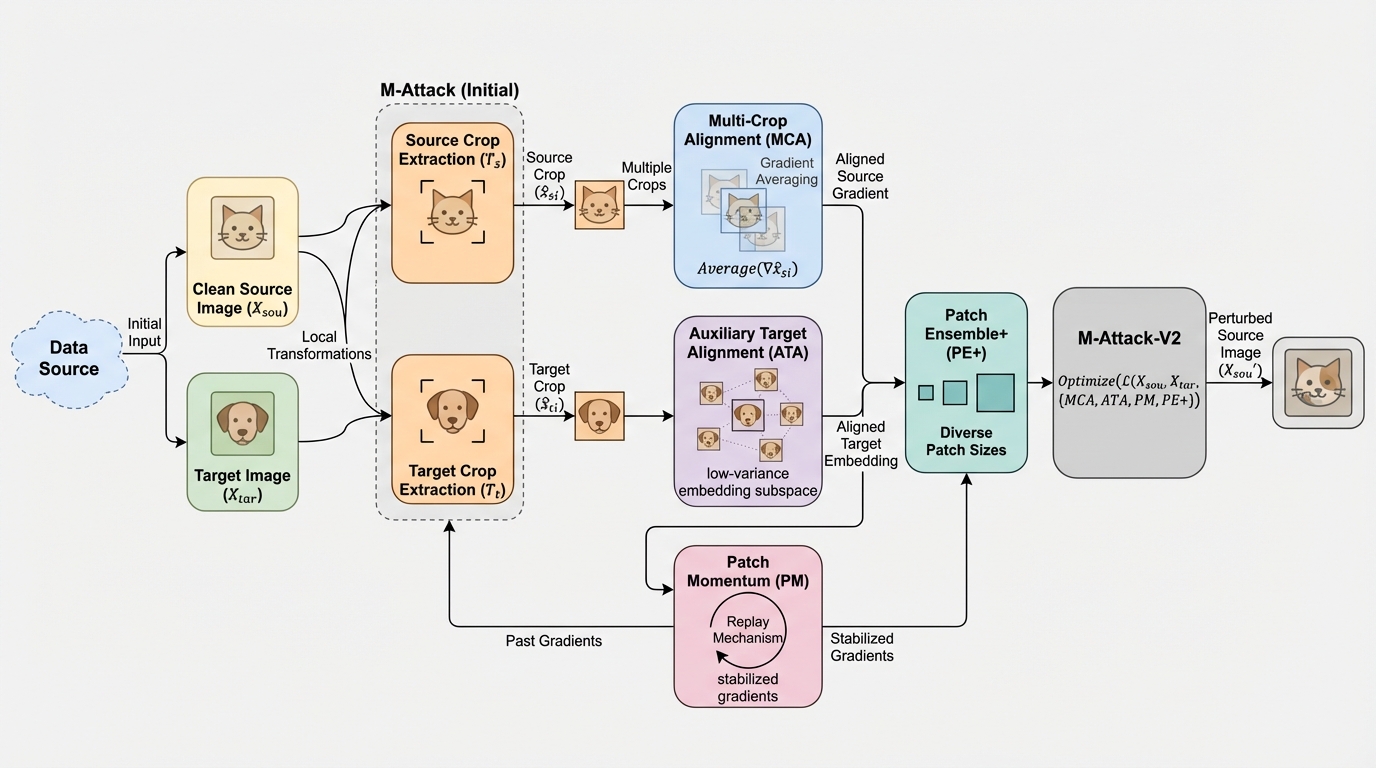
転送型ブラックボックス攻撃で強力だったM-Attackは、局所クロップ同士の一致という設計の裏側で、反復ごとに勾配が高分散になりほぼ直交して最適化が不安定になる問題があり、M-Attack-V2はこの不安定さを「勾配のデノイジング」として正面から抑える改良です。
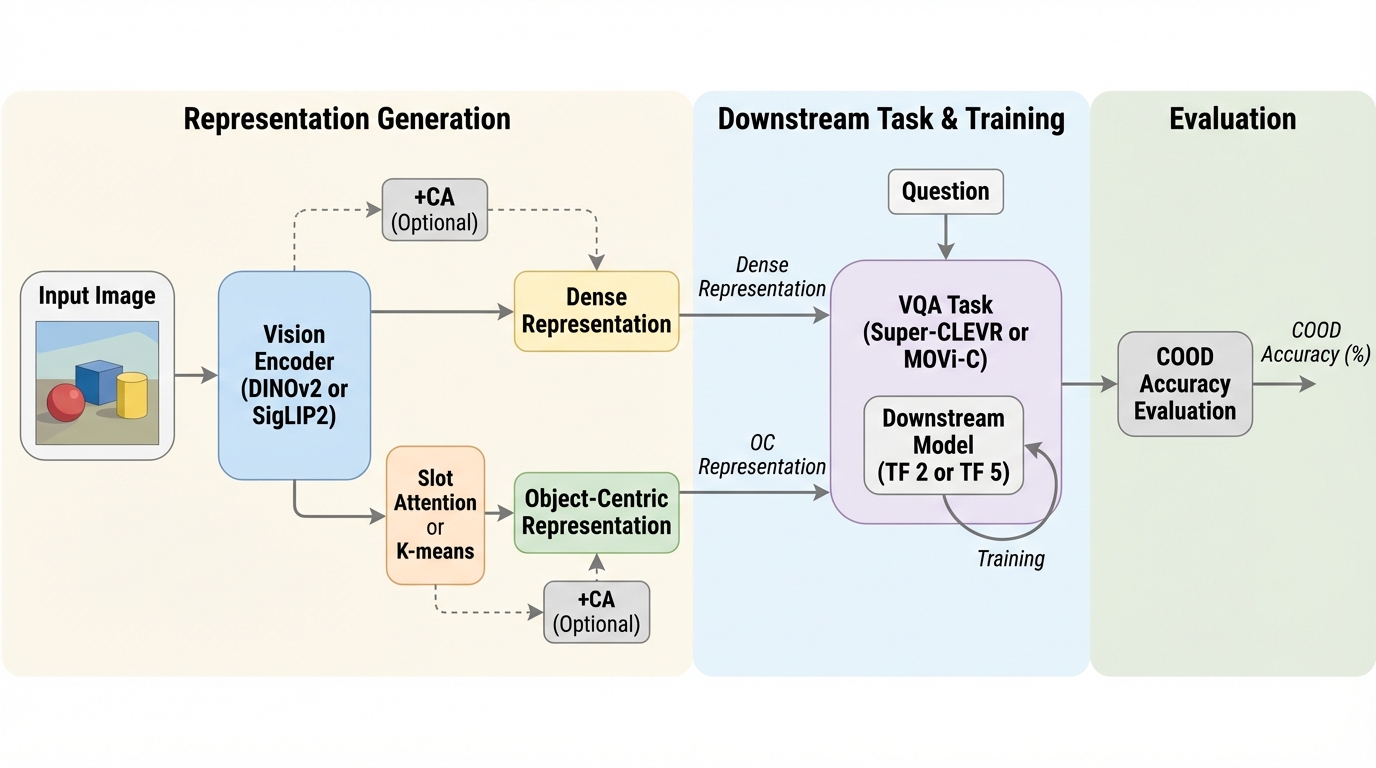
見慣れた属性を材料に「未学習の組み合わせ」を扱う合成的一般化では、物体中心(OC)表現がとくに難しい条件で優位になりやすく、データ量・多様性・下流計算量のいずれかが制約されると強みが出やすいです。
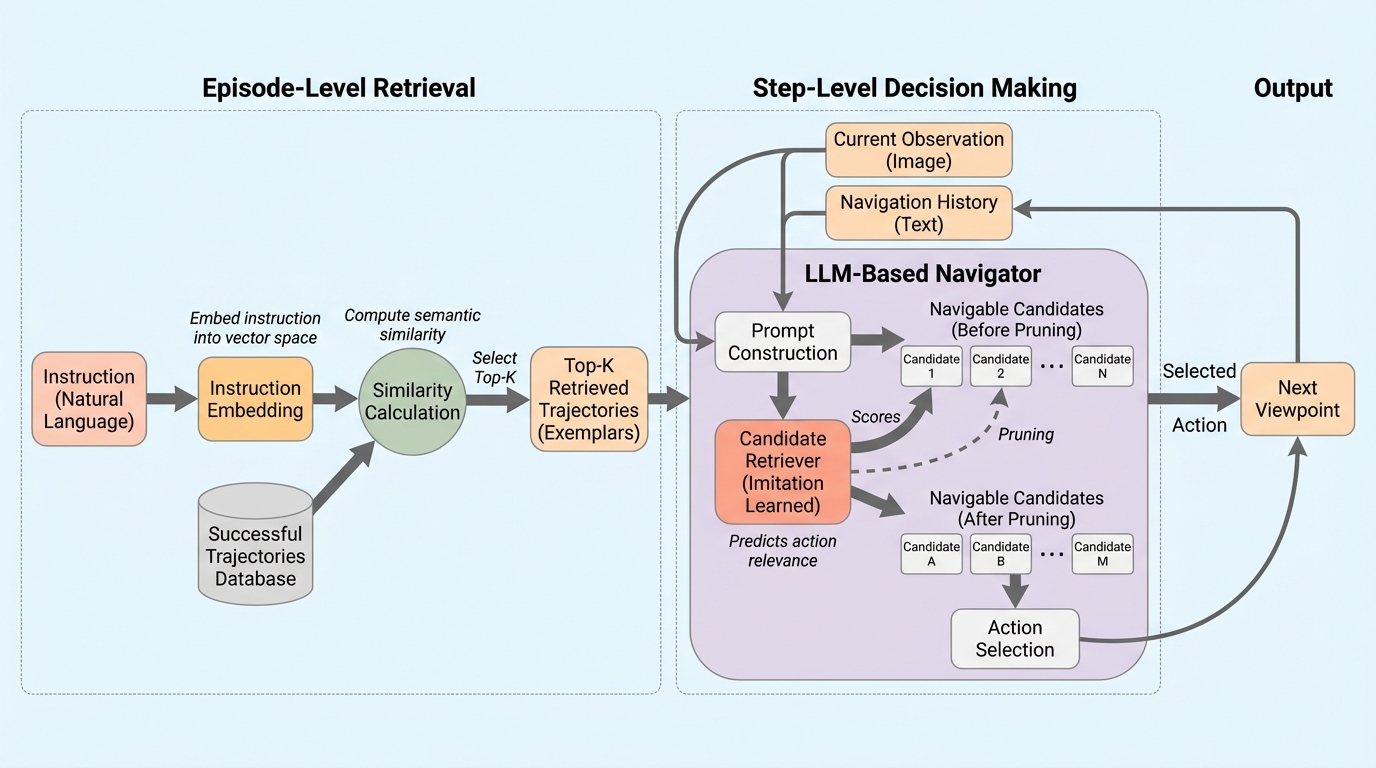
大規模言語モデルをナビゲータとして用いる視覚と言語ナビゲーションでは、毎回の指示解釈を最初からやり直し、各ステップで冗長な移動候補すべてを読み比べる必要があるため、意思決定が非効率かつ不安定になりやすいと整理されています。
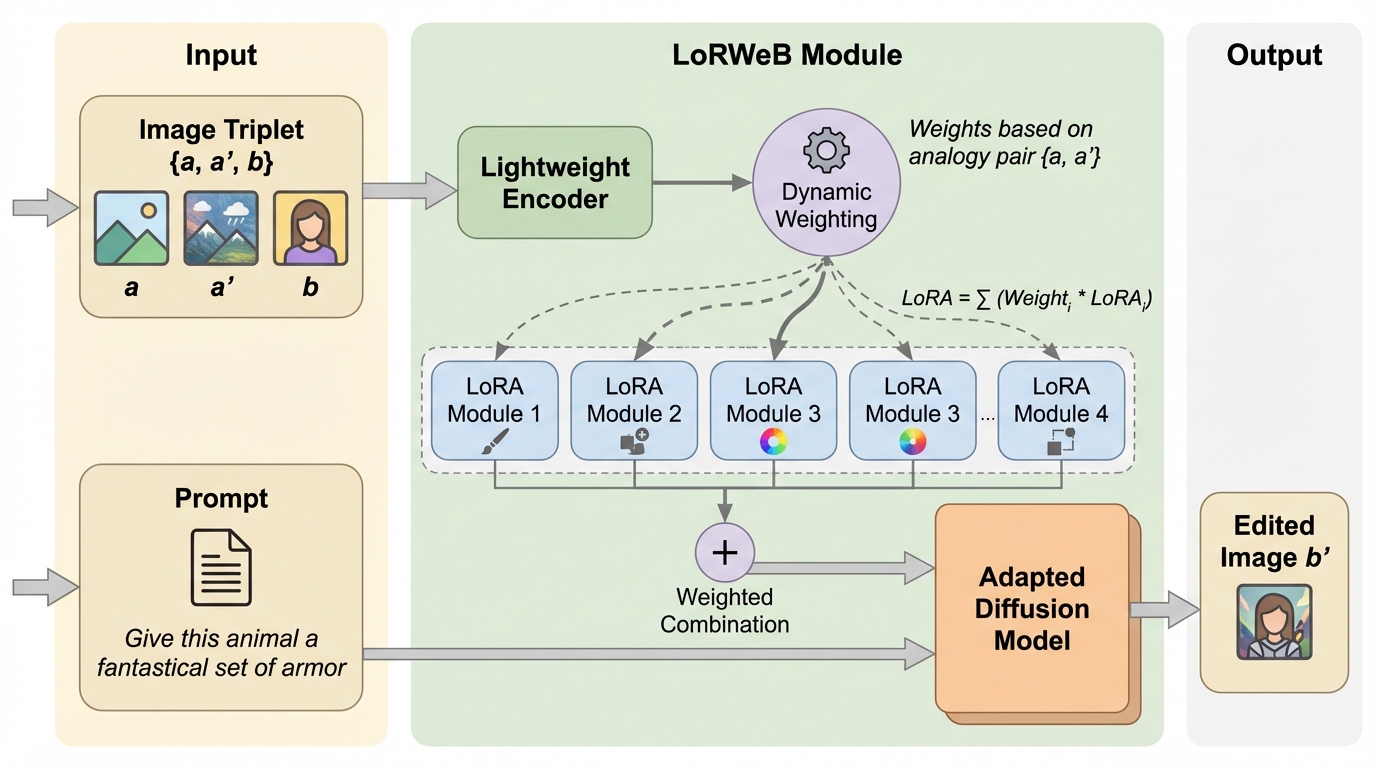
言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。 / LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。 / 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。
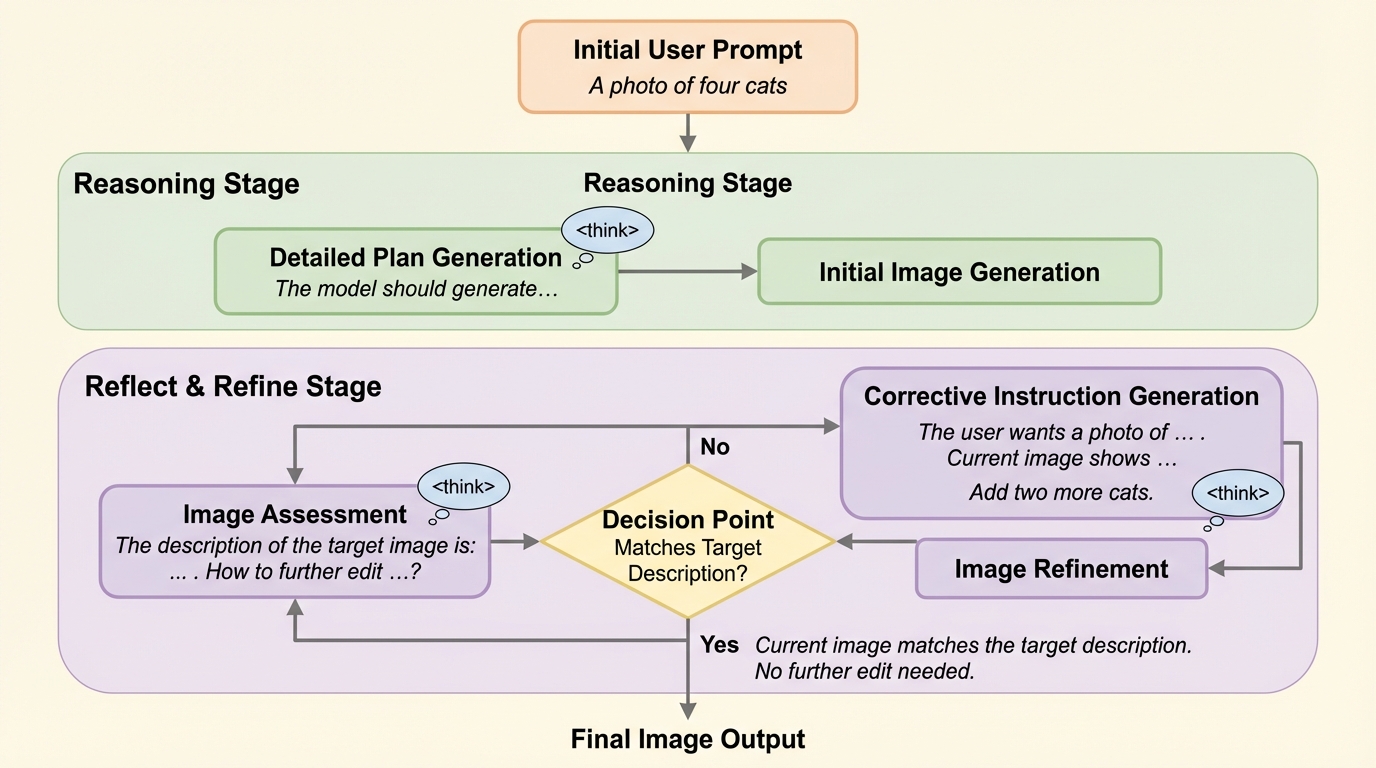
マルチモーダルモデルは、画像の「生成」を伸ばすと「理解」が落ちたり、その逆が起きたりする同時改善の難しさがあり、原因として学習目標の違いがモデル容量の競合を生みうる点が整理されています。 / この論文は単発の画像生成を、意図を推論して下書きを作り、出来栄えを自己評価し、修正指示で編集していく多段の手続きへ組み替えるReason-Reflect-Refine(R3)を提案しています。 / 最終画像の品質に基づく結果志向の報酬で一連のループを学習させ、GenEval++で生成指示追従を強化しつつ、生成内容に結び付いた理解評価(例としてカウントなど)も改善したと報告されています。
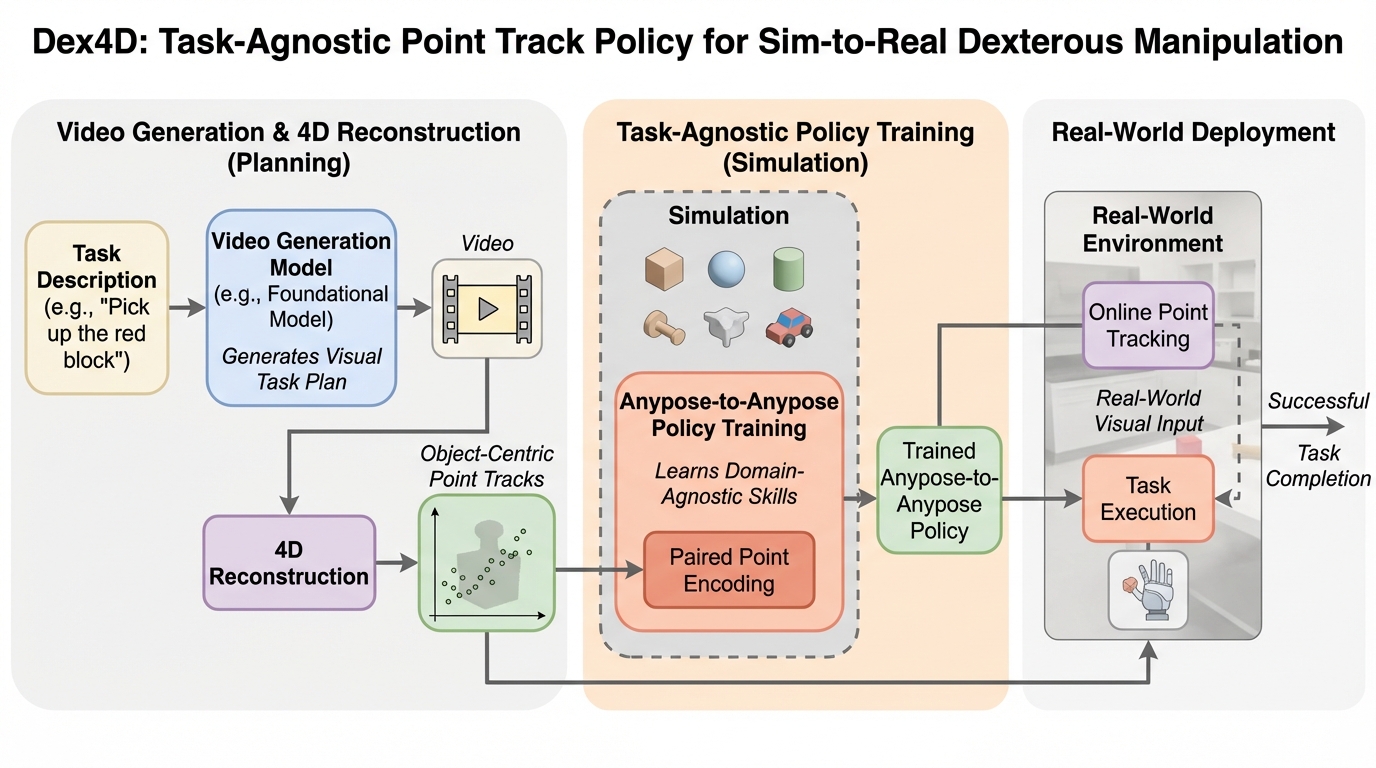
Dex4Dは、個別タスクごとの環境設計や報酬設計を増やすのではなく、「物体を現在姿勢から目標姿勢へ動かす」という共通能力をシミュレーションで学び、実機の多様な巧緻操作へつなげる枠組みです。 / 目標は言語そのものではなく、生成動画と4D再構成から得る物体中心の3D点トラックで与え、実行中はオンライン点追跡で現在の点を更新しながら、点トラック条件付きポリシーで閉ループ制御します。 / シミュレーションと実機の広範な実験により、ファインチューニングなしのゼロショット展開、先行ベースラインに対する成功率・タスク進捗・頑健性の一貫した改善、そして新規物体や背景などへの強い汎化が報告されています。
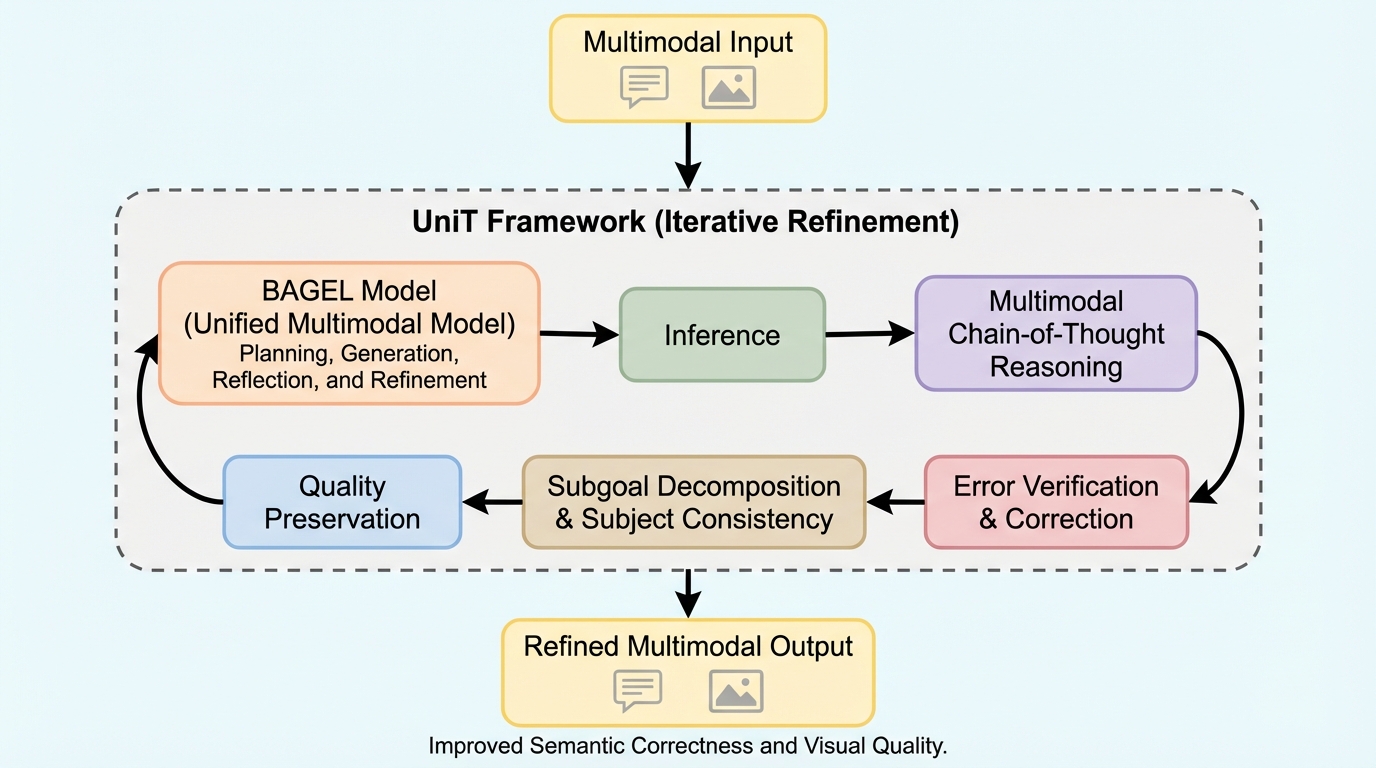
UniTは、理解と生成を同じモデルでこなしつつ、1回で答えを出すのではなく、画像を作り、確かめ、直し、また確かめるという反復をテスト時に回す枠組みです。 / 重要なのは、候補を並列にたくさん出して選ぶよりも、逐次的に考えて直していく方が、同じ計算量あたりで強い点です。画像生成、編集、視覚推論の複数ベンチで一貫して優位が出ています。 / 成功の鍵は、検証、サブゴール分解、内容記憶という三つの認知的ふるまいを学習データに埋め込んだことにあります。逆に言うと、単に推論回数を増やすだけでは足りず、何を確認し、何を覚え、どう分けて直すかまで設計しないと伸びません。