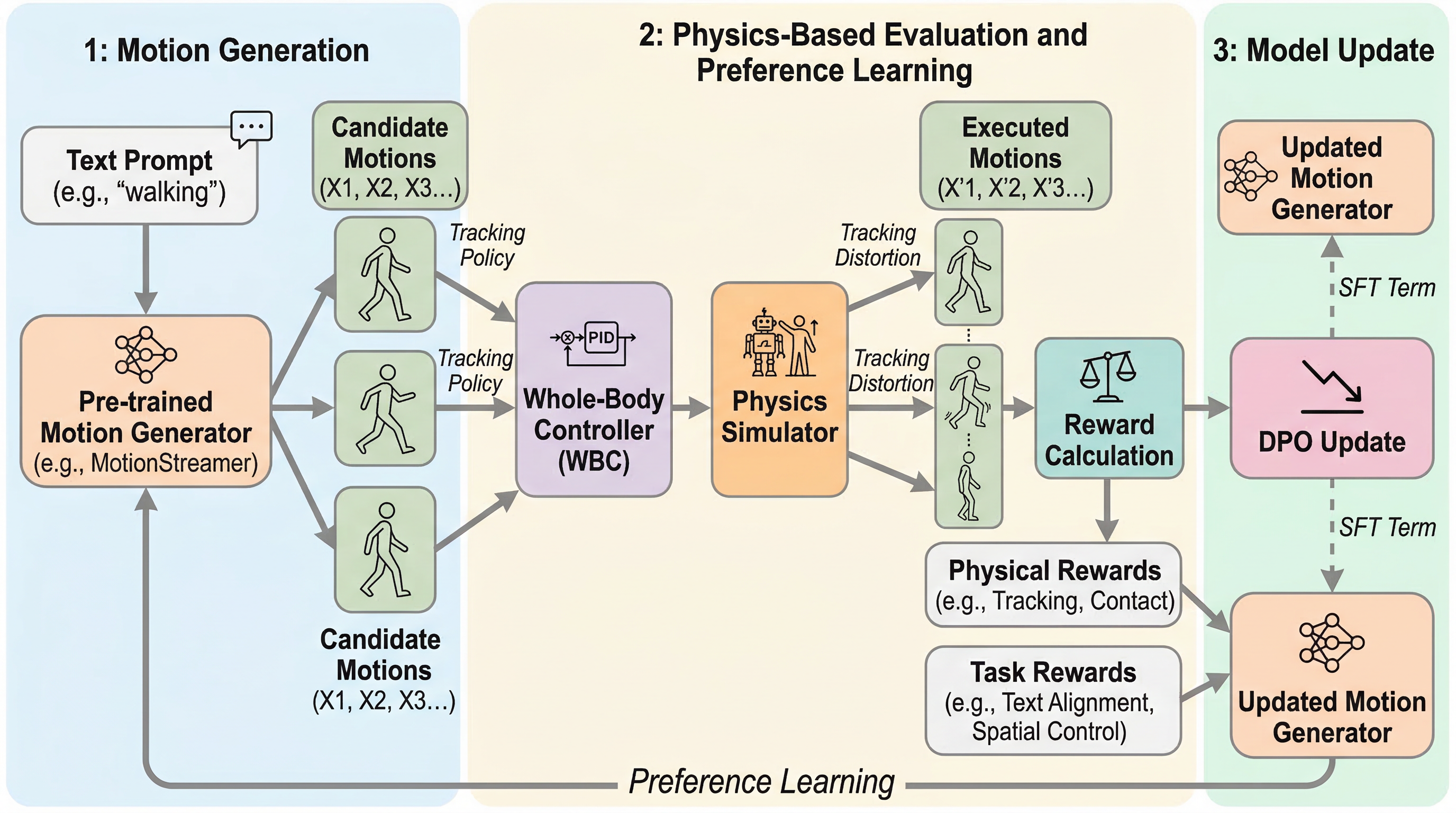
PhysMoDPO:物理的にもっともらしく、指示にも忠実なヒューマノイド動作を選好最適化で鍛え直す
テキストから人の動きを作る拡散モデルは見た目の自然さでは強くなっていますが、実機や物理シミュレータへ移すと、足滑りやバランス崩れ、指示との不整合が露呈しやすいのが弱点でした。 PhysMoDPOは、Whole-Body Controller を訓練ループに直接組み込み、追従可能性や接触の自然さなどの物理報酬と、追従後もテキストや空間条件に合っているかというタスク報酬を使って、DPOで動作生成器を後学習する手法です。 HumanML3DやOMOMOではFIDやJerk、制御誤差が改善し、Unitree G1へのゼロショット転移でも、単純なSFTや既存手法より一貫して高い整合性と滑らかさを示しました。