MXNorm:正規化のための集計を使い回して LLM 学習を軽くする
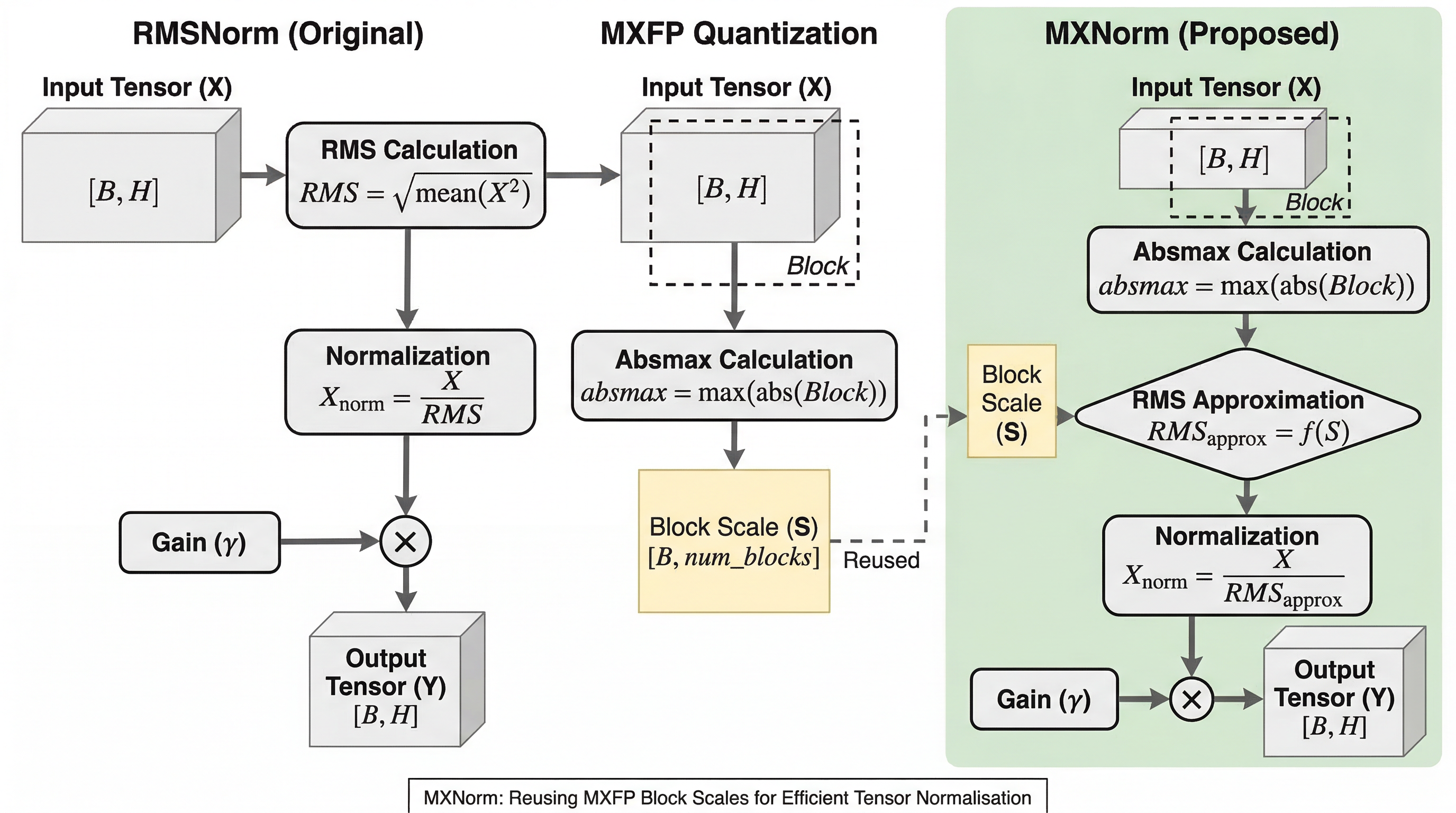
低精度化で行列積だけが速くなる一方、正規化のような縮約と要素演算は相対的に重くなっており、学習全体の新しいボトルネックになっています。 MXNormは、MXFP量子化の際にすでに計算しているブロックスケールを再利用して RMSNorm を近似し、正規化のための縮約サイズを32分の1に減らす設計です。 Llama 3 系の125M、1B、8B事前学習では RMSNorm とほぼ同等の損失と下流性能を保ちながら、単体カーネルで最大2.4倍、8Bブロック全体で1.3%、NVFP4では2.6%の速度向上を示しました。
TL;DR(結論)
- 低精度化で行列積だけが速くなる一方、正規化のような縮約と要素演算は相対的に重くなっており、学習全体の新しいボトルネックになっています。
- MXNormは、MXFP量子化の際にすでに計算しているブロックスケールを再利用して RMSNorm を近似し、正規化のための縮約サイズを32分の1に減らす設計です。
- Llama 3 系の125M、1B、8B事前学習では RMSNorm とほぼ同等の損失と下流性能を保ちながら、単体カーネルで最大2.4倍、8Bブロック全体で1.3%、NVFP4では2.6%の速度向上を示しました。
なぜこの問題か
AIアクセラレータはここ数年で行列積を極端に速くしてきました。論文は、V100からGB200世代までで低精度行列積性能が80倍規模で伸びた一方、CUDAコアやメモリ帯域の伸びはそれよりかなり小さいと整理しています。すると、かつては目立たなかった正規化や要素演算が、相対的に無視できない比率を占めるようになります。特に大規模言語モデルでは、各残差ブロックの入口にあるRMSNormがほぼ必ず実行されるため、行列積の高速化が進むほど、ここが目につき始めます。
核心:何を提案したのか
提案の中心はMXNormです。RMSNormを完全に捨てるのではなく、MXFP量子化で既に得られるブロックスケールを使ってRMSを近似し、Normと量子化を一体化してしまう正規化方式です。論文では、特に Pre-Norm Transformer における「RMSNormの直後に線形層、その前後でMX形式への変換が入る」というパターンに注目しています。この並びでは、正規化と量子化が hidden dimension に沿って別々に統計を取るため、そこをまとめる余地があります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related