線形化注意はなぜ「効く」と同時に「危うい」のか:Influence Malleability が示す二面性
線形化した注意機構は、幅を十分に大きくしても無限幅NTKへ素直に近づかず、ReLU系のような「固定カーネルに近い学習」へ入らないことが、理論と実験の両方から示されます。 その理由は、注意変換が Gram 行列の条件数を三乗で増幅し、NTK 収束に必要な幅を実用外の大きさまで押し上げるためで、その非収束性が訓練データへの依存の変わりやすさ、すなわち influence malleability として観測されます。 この性質は、データ構造に合うと近似誤差を下げる源泉である一方、訓練データを少し細工されただけで reliance が大きく変わる脆さの源泉でもあり、注意の強みと弱みが同じ場所から生まれていると整理されます。
TL;DR(結論)
- 線形化した注意機構は、幅を十分に大きくしても無限幅NTKへ素直に近づかず、ReLU系のような「固定カーネルに近い学習」へ入らないことが、理論と実験の両方から示されます。
- その理由は、注意変換が Gram 行列の条件数を三乗で増幅し、NTK 収束に必要な幅を実用外の大きさまで押し上げるためで、その非収束性が訓練データへの依存の変わりやすさ、すなわち influence malleability として観測されます。
- この性質は、データ構造に合うと近似誤差を下げる源泉である一方、訓練データを少し細工されただけで reliance が大きく変わる脆さの源泉でもあり、注意の強みと弱みが同じ場所から生まれていると整理されます。
なぜこの問題か
注意機構は現代の深層学習を支える中心技術ですが、その柔軟さが訓練中にどこから来るのか、理論的には意外なほど分かっていません。特に NTK 理論は、幅を無限に広げるとネットワークがほぼ固定カーネルとして振る舞う、いわゆる lazy training の見通しを与えます。二層 ReLU ネットワークではこの見方がよく当たり、幅が増えるほど有限幅モデルと無限幅 NTK 予測の差が縮む、という経験則とも整合します。 ところが注意機構は、入力同士の関係そのものを内部で使いながら特徴を作り直します。このとき、学習が「固定カーネルの近似」ではなく、表現そのものを動かし続ける feature learning 側に残るなら、NTK に依存した理解は大きく外れます。理論上の理解だけでなく、訓練データのどの例をどれだけ頼るか、外乱にどれだけ敏感か、対向摂動にどれだけ弱いか、という実務上の重要点にも影響します。 論文が着目するのは、訓練データへの依存の「変わりやすさ」です。ある訓練例が予測を助けているのか、むしろ邪魔しているのかは、通常のネットワークでも学習につれて変わります。…
核心:何を提案したのか
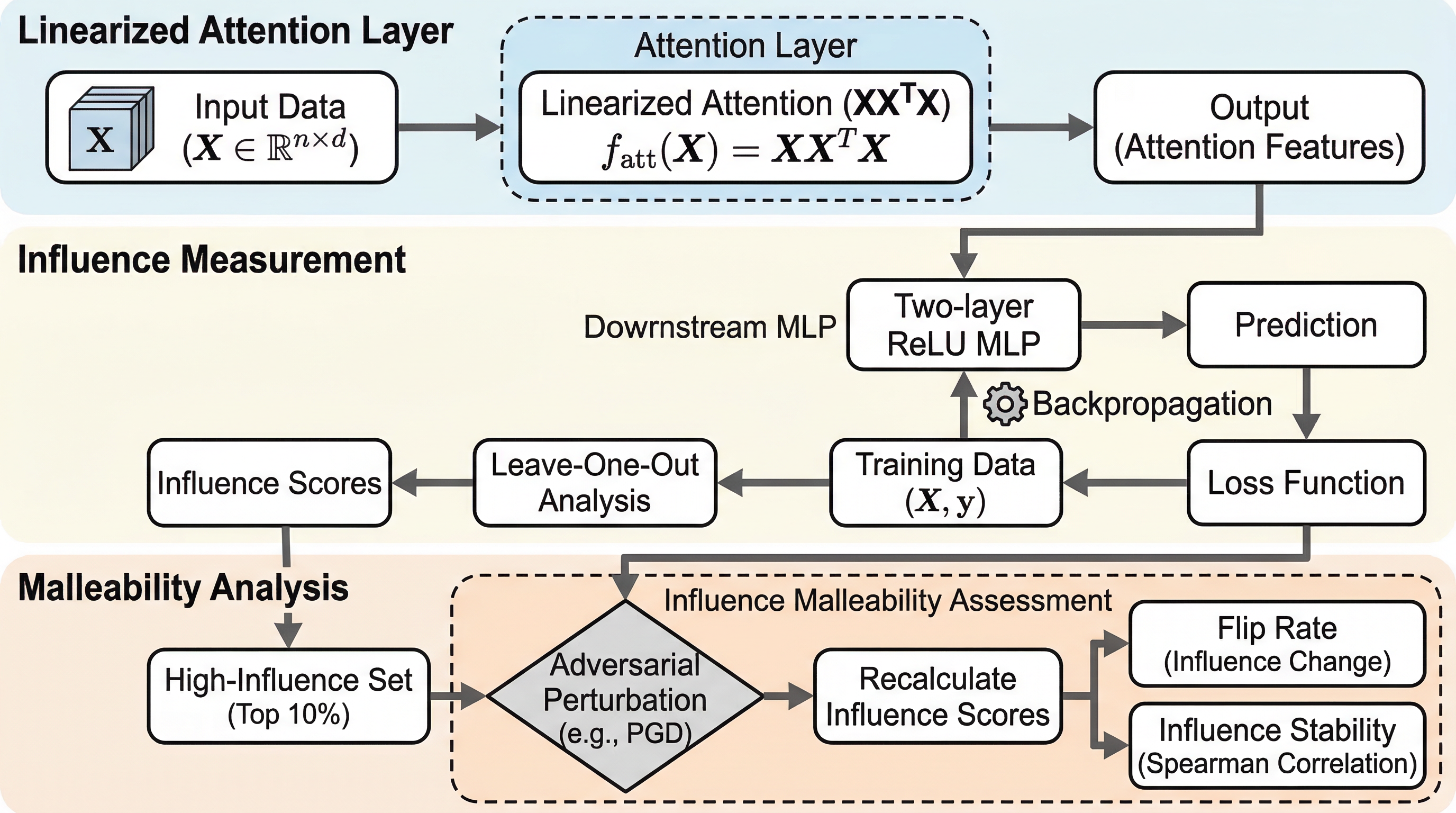
提案の中心は、線形化注意を厳密にカーネルとして書き下し、その非収束性とデータ依存性を influence malleability という量で捉える枠組みです。ここで使う注意機構は、標準的な scaled dot-product attention を単純化した、恒等射影かつ softmax を線形化した形で、入力行列 (X) に対して (f_{\mathrm{att}}(X)=XX^TX) と書かれます。複雑な Transformer 全体ではなく、注意の二次的相互作用だけを抜き出した最小構成で、理論的に追える代表例を作っています。 この構成の重要点は、注意後のカーネルが単なる入力内積の関数ではなく、訓練集合全体の Gram 行列 (G=XX^T) に依存することです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related