PhysMoDPO:物理的にもっともらしく、指示にも忠実なヒューマノイド動作を選好最適化で鍛え直す
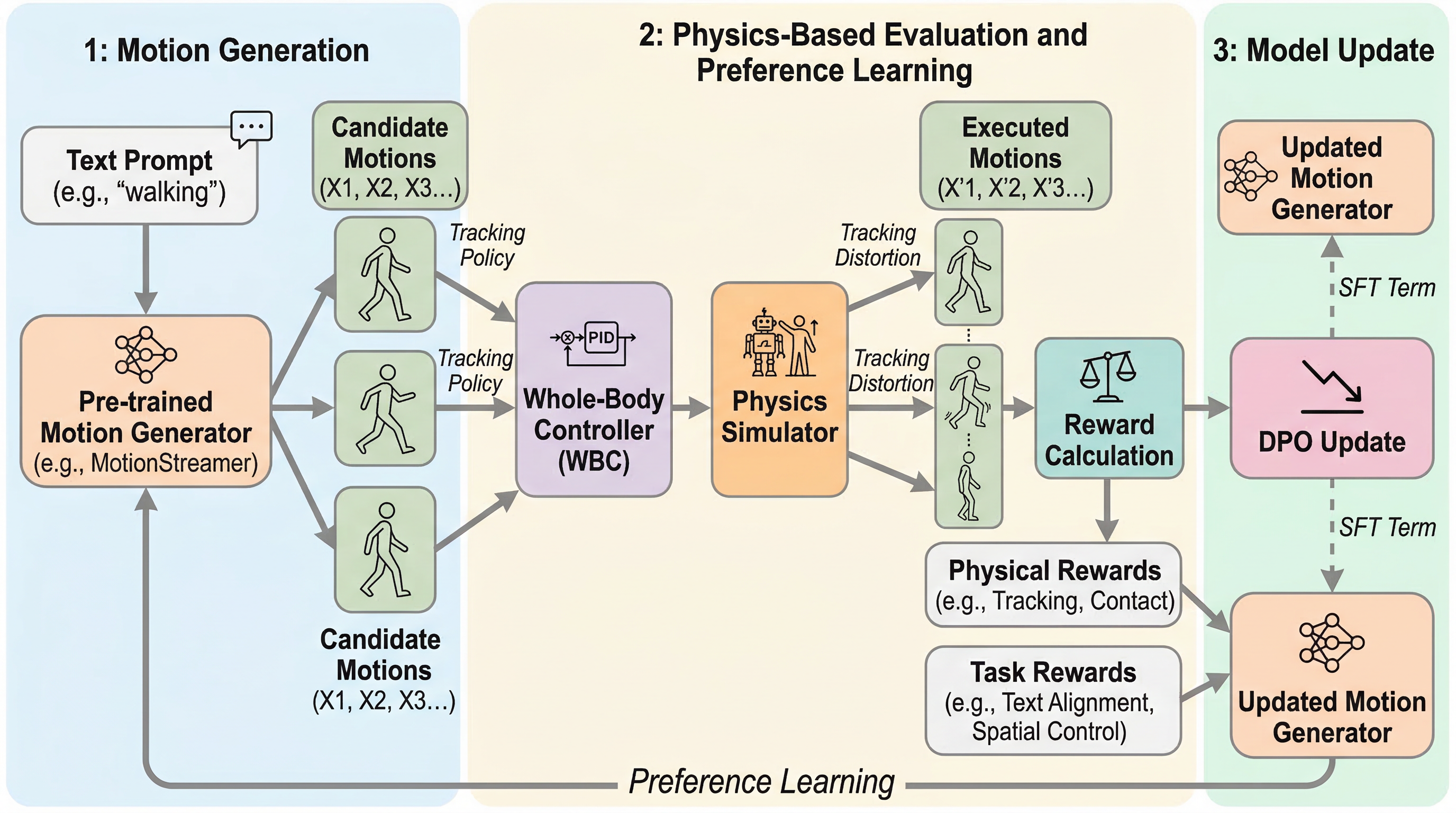
テキストから人の動きを作る拡散モデルは見た目の自然さでは強くなっていますが、実機や物理シミュレータへ移すと、足滑りやバランス崩れ、指示との不整合が露呈しやすいのが弱点でした。 PhysMoDPOは、Whole-Body Controller を訓練ループに直接組み込み、追従可能性や接触の自然さなどの物理報酬と、追従後もテキストや空間条件に合っているかというタスク報酬を使って、DPOで動作生成器を後学習する手法です。 HumanML3DやOMOMOではFIDやJerk、制御誤差が改善し、Unitree G1へのゼロショット転移でも、単純なSFTや既存手法より一貫して高い整合性と滑らかさを示しました。
TL;DR(結論)
- テキストから人の動きを作る拡散モデルは見た目の自然さでは強くなっていますが、実機や物理シミュレータへ移すと、足滑りやバランス崩れ、指示との不整合が露呈しやすいのが弱点でした。
- PhysMoDPOは、Whole-Body Controller を訓練ループに直接組み込み、追従可能性や接触の自然さなどの物理報酬と、追従後もテキストや空間条件に合っているかというタスク報酬を使って、DPOで動作生成器を後学習する手法です。
- HumanML3DやOMOMOではFIDやJerk、制御誤差が改善し、Unitree G1へのゼロショット転移でも、単純なSFTや既存手法より一貫して高い整合性と滑らかさを示しました。
なぜこの問題か
近年のテキスト条件付き人間動作生成は、HumanML3D のような大規模データセットと拡散モデルの組み合わせで大きく伸びました。しかし、そこで評価されるのは主にキネマティックな空間、つまり関節軌道としてどれだけ自然か、テキストにどれだけ合っているかです。ロボット側が必要とするのは、そこに接触、重心、摩擦、駆動制約が入った「物理的に実行可能か」という条件です。ここがずれると、生成器が良いと判定した動きが、実際にはコントローラに大きく修正されてしまいます。
核心:何を提案したのか
中心提案は PhysMoDPO です。拡散型のモーション生成器から複数の候補動作をサンプルし、それぞれを固定の Whole-Body Controller で物理シミュレータ上の実行可能軌道へ写像し、その結果に対して選好を付けてDPOで後学習します。ここで選好を決めるのは、追従のしやすさや接触の自然さのような物理報酬と、追従後にもテキストや空間条件を満たしているかを見るタスク報酬の組み合わせです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related