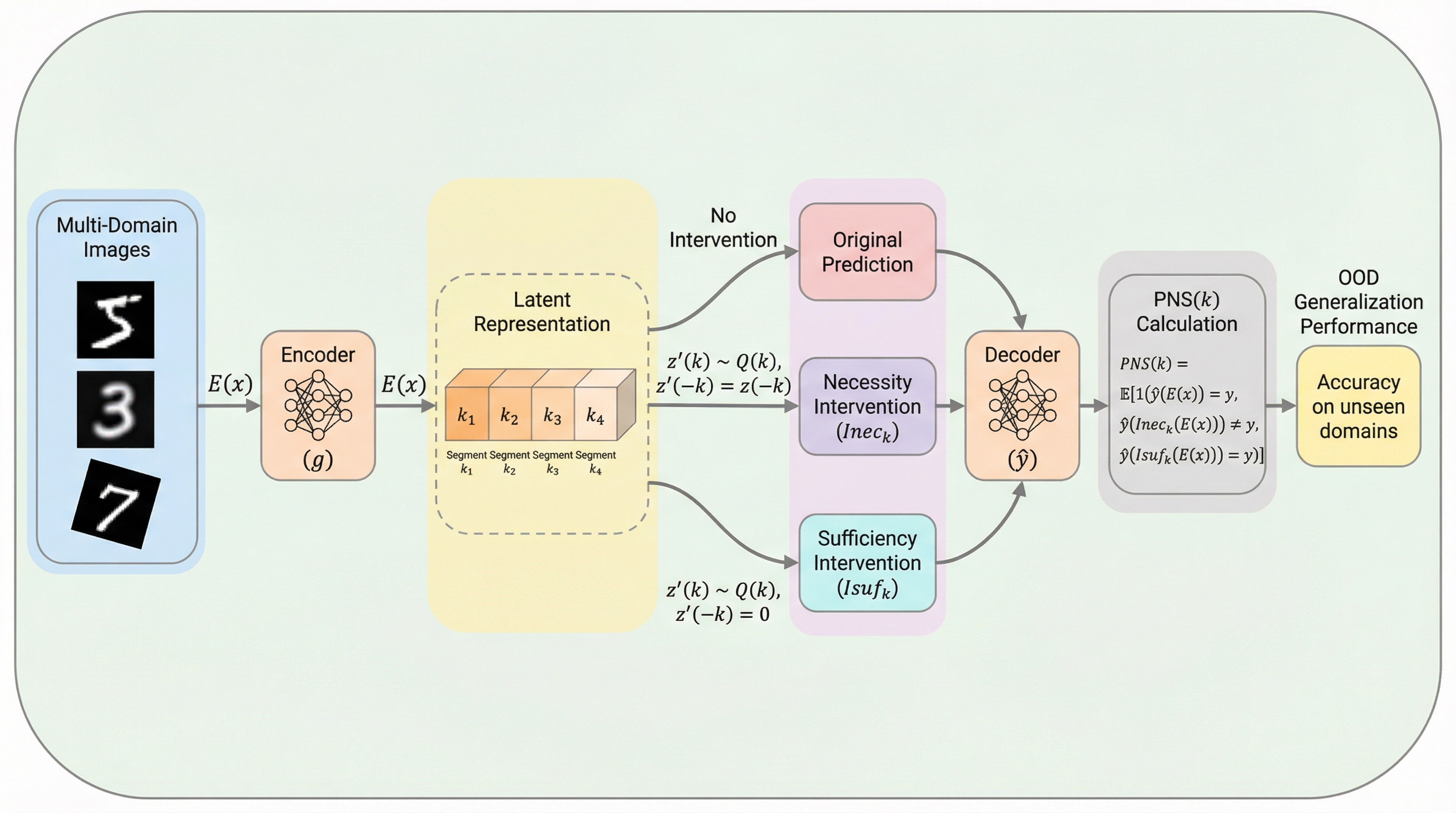
クロスドメイン画像分類のための因果駆動型特徴量評価
従来のドメイン汎化手法が依存していた「ドメイン間で不変な特徴は信頼できる」という仮定に対し、不変であっても予測に因果的な寄与をしない「偽の相関」が含まれる問題を指摘し、統計的な安定性ではなく因果的な有効性を評価の主軸に据える必要性を提唱しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のドメイン汎化手法が依存していた「ドメイン間で不変な特徴は信頼できる」という仮定に対し、不変であっても予測に因果的な寄与をしない「偽の相関」が含まれる問題を指摘し、統計的な安定性ではなく因果的な有効性を評価の主軸に据える必要性を提唱しました。
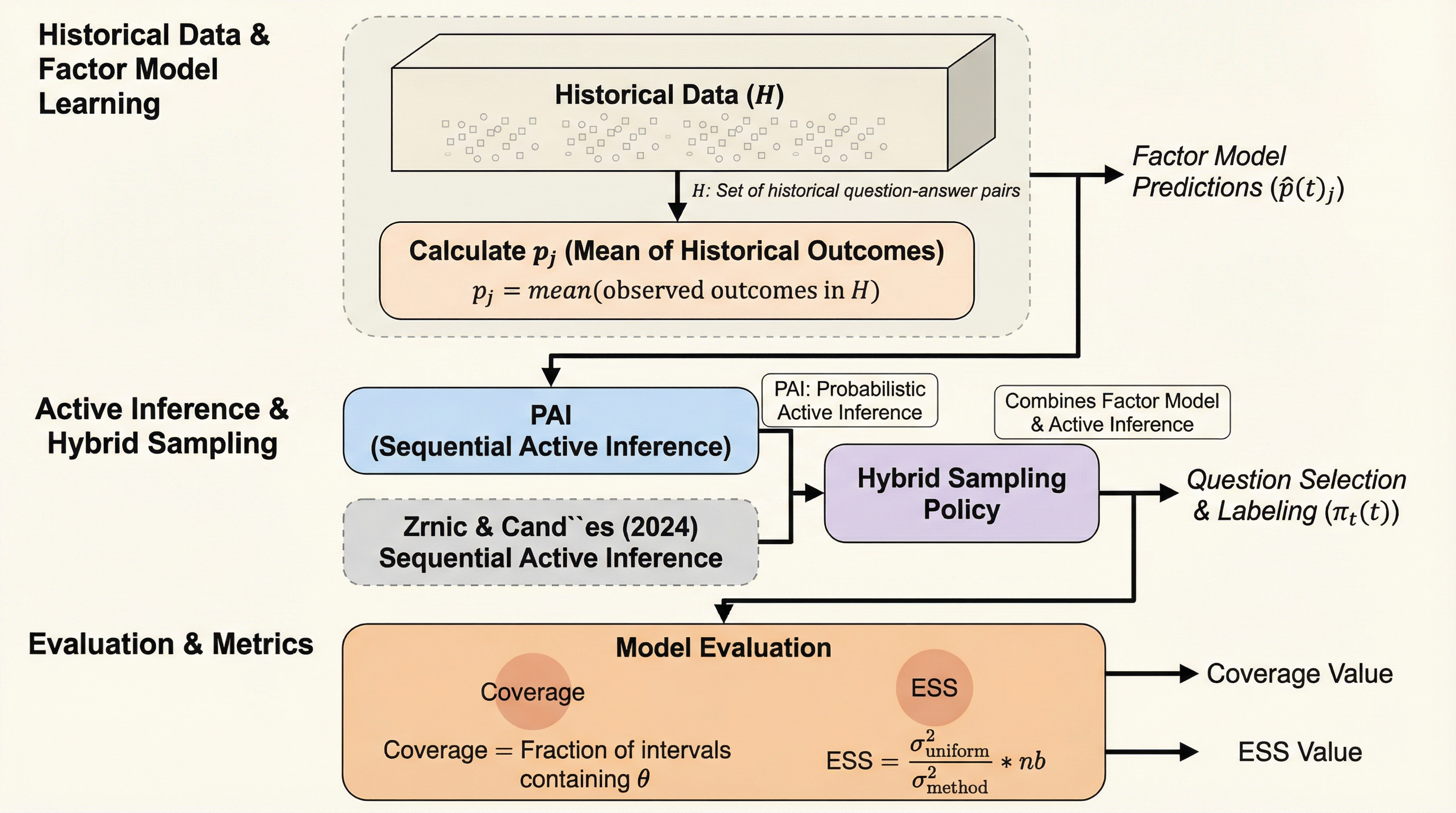
大規模言語モデル(LLM)の評価コストが急増する中、過去の評価データを活用して少ない質問数で高精度な性能推定を行う新手法「Factorized Active Querying (FAQ)」が開発されました。
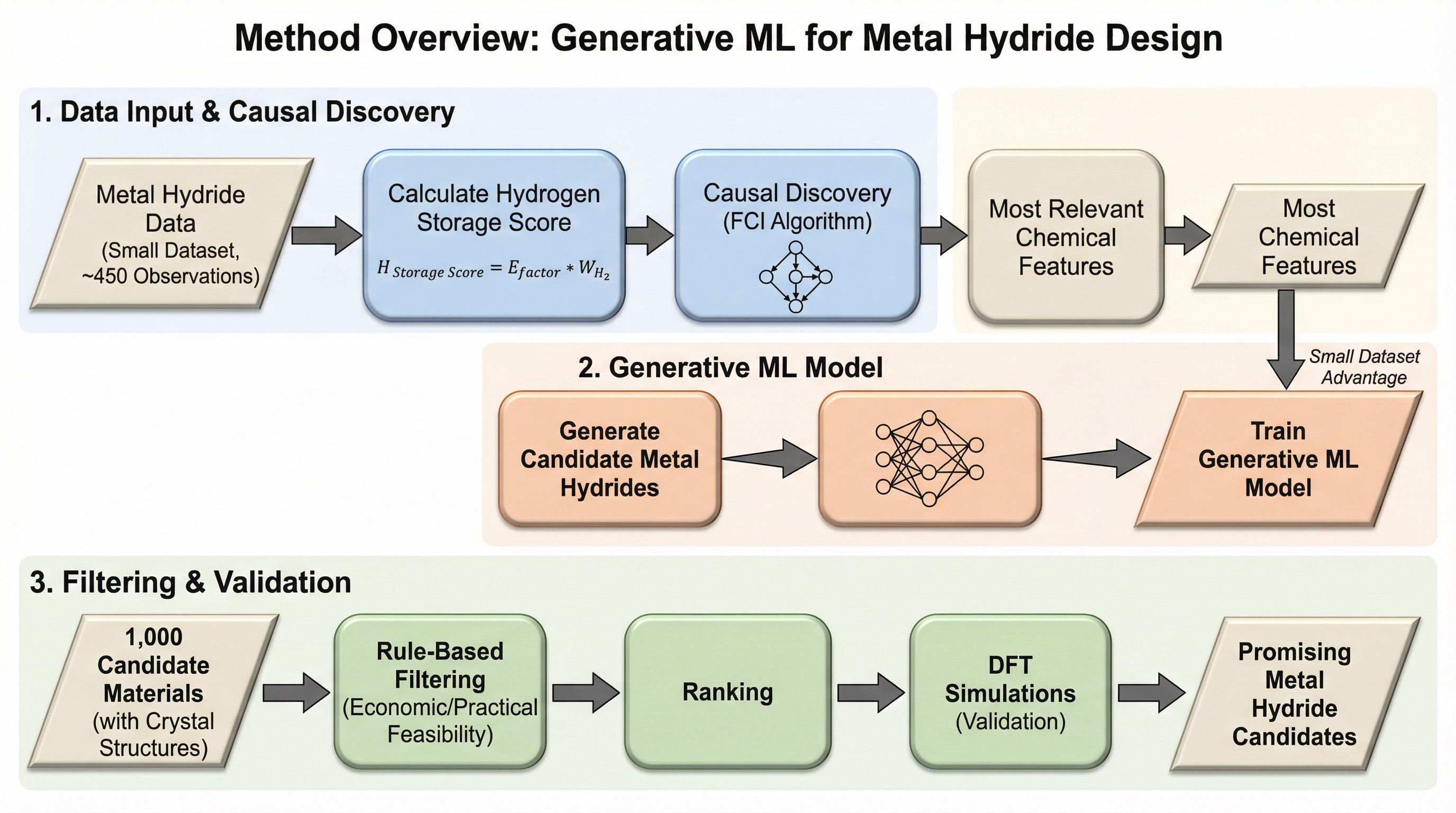
カーボンニュートラル実現に不可欠な水素貯蔵技術において、従来の実験や計算手法の限界を打破するため、因果探索アルゴリズム(FCI)と軽量な変分オートエンコーダ(VAE)を組み合わせた新しい材料設計フレームワークを開発しました。
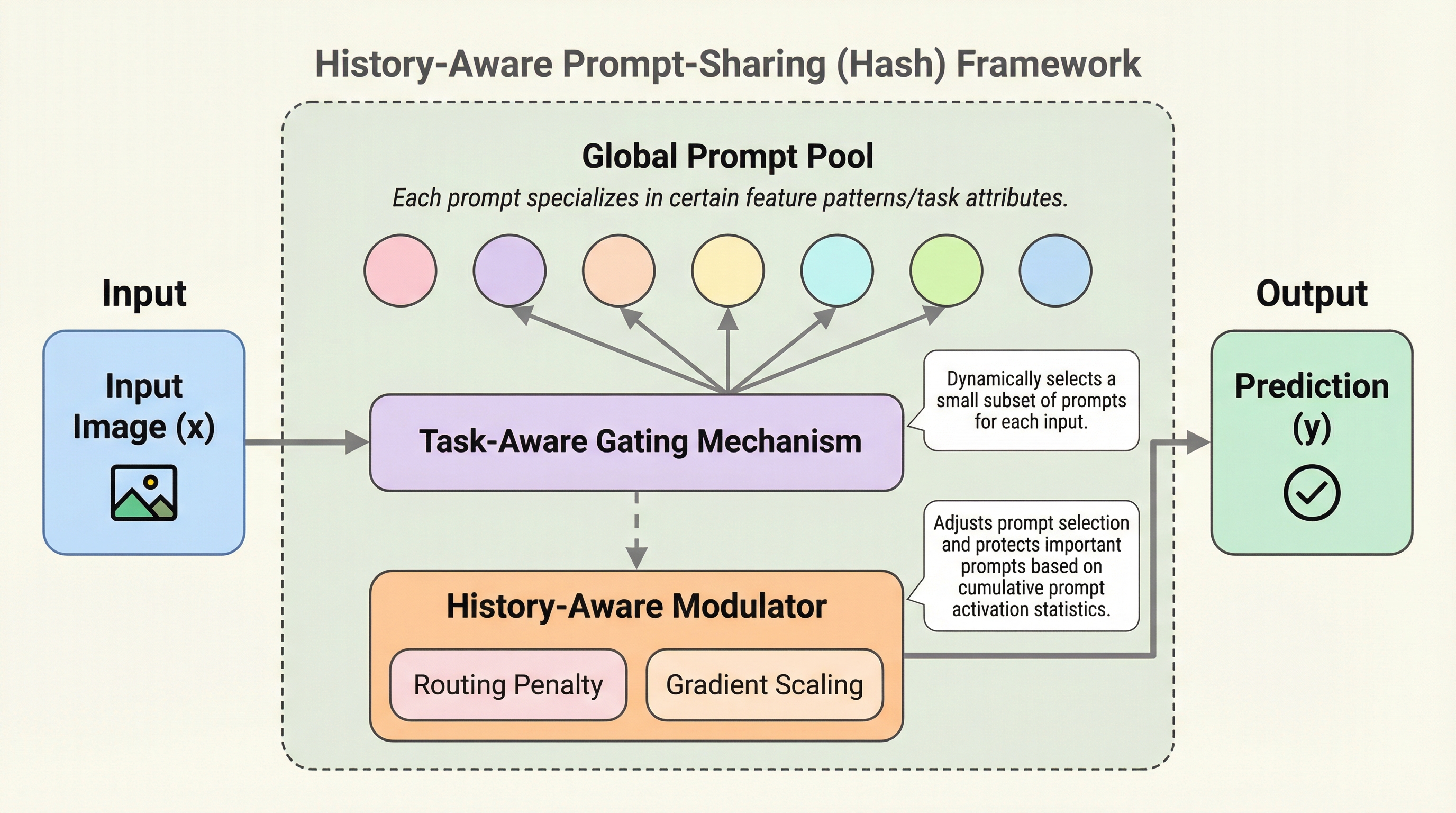
従来のプロンプトベース継続学習はタスクごとに独立したプロンプトを割り当てる手法が主流であったが、本研究では知識共有とパラメータ効率を向上させるために、グローバルなプロンプトプールを共有し、入力に応じて動的にプロンプトを選択するフレームワーク「Hash」を提案している。
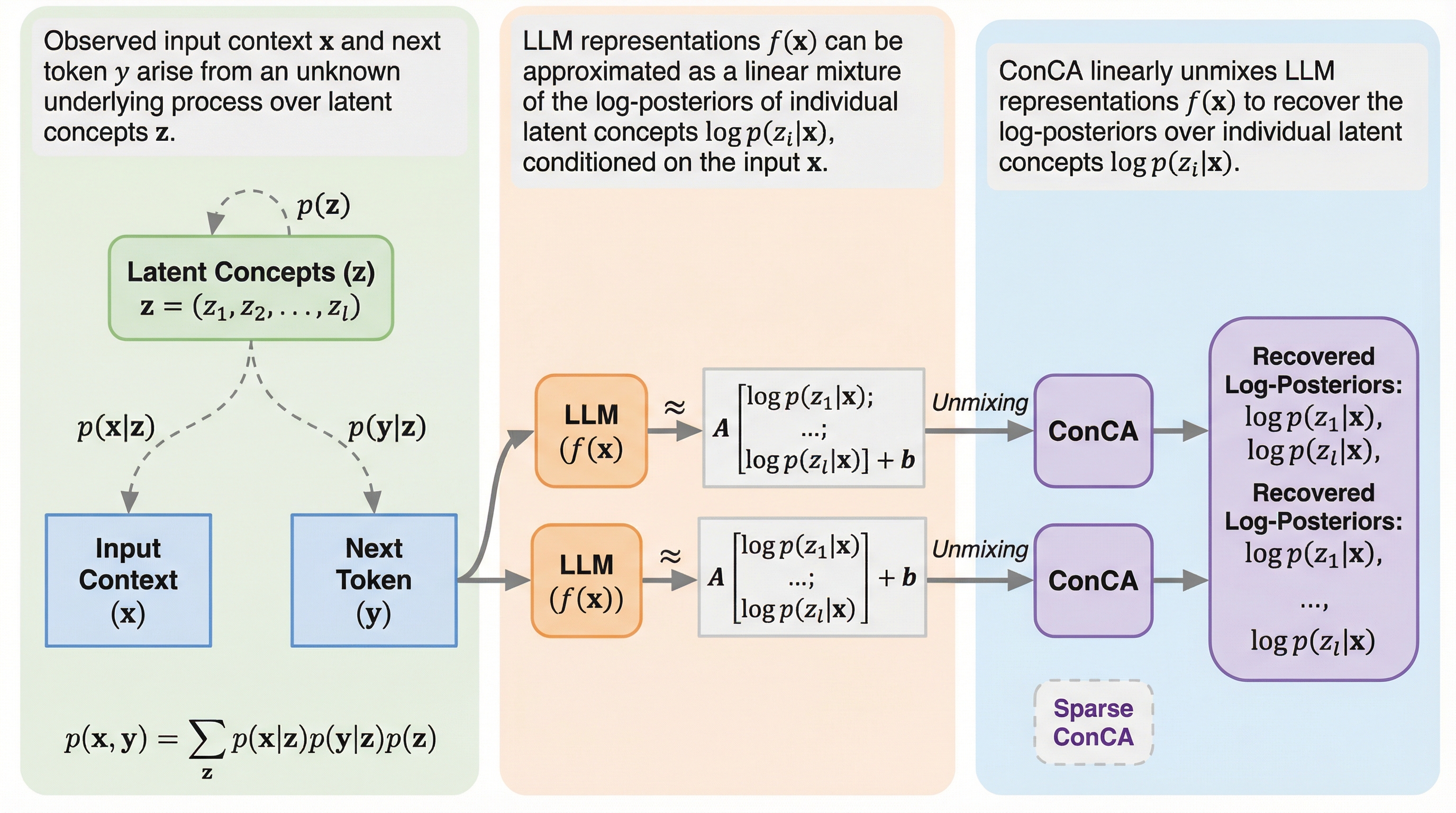
大規模言語モデル(LLM)の内部表現が、入力文脈における潜在的な概念の対数事後確率の線形混合として近似できることを理論的に証明し、この関係に基づき概念を抽出する「概念成分分析(ConCA)」を提案しました。
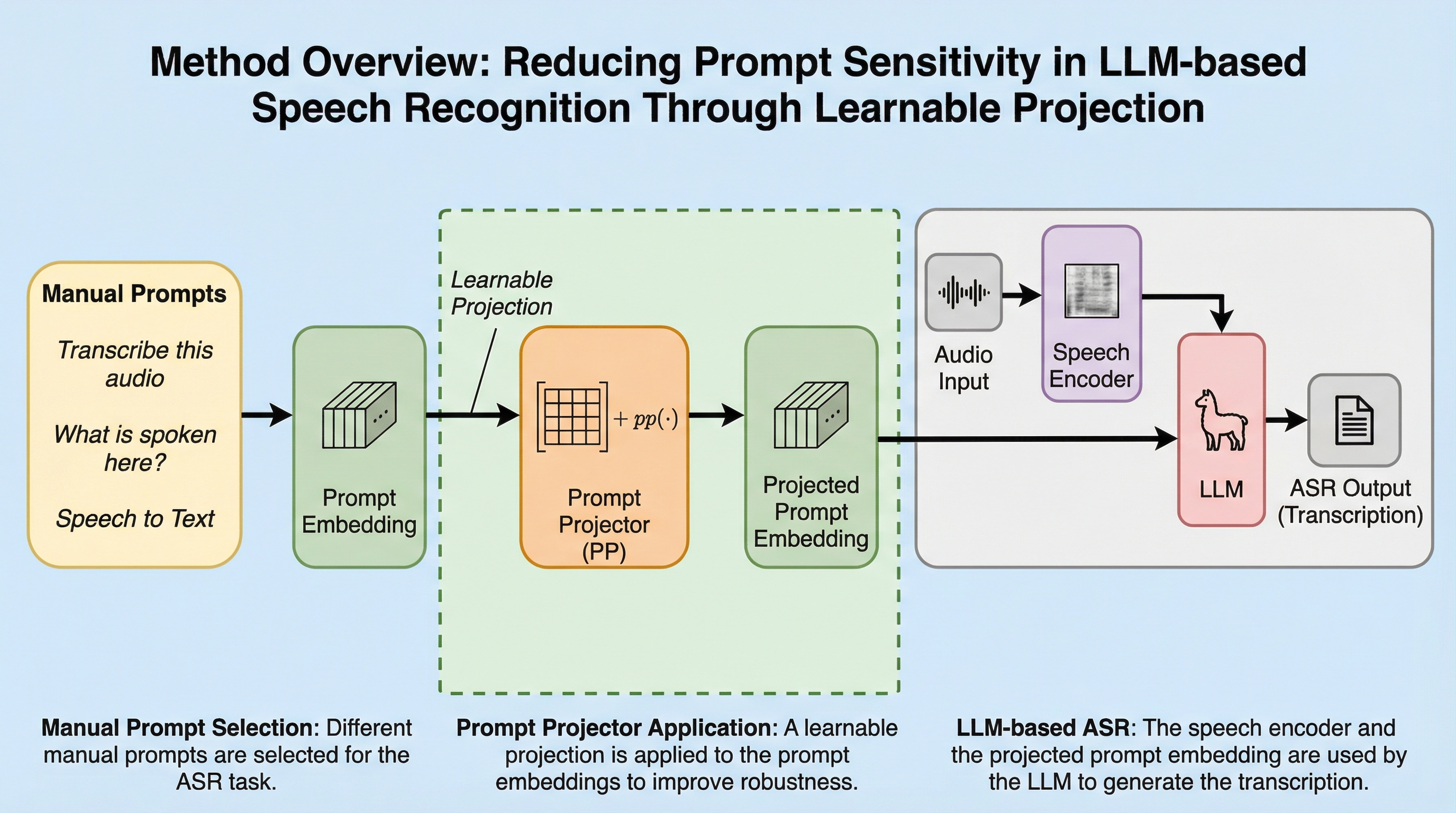
大規模言語モデル(LLM)を用いた音声認識(ASR)において、人間が手動で設計する固定プロンプトの文言や配置が、単語誤り率(WER)などの性能に極めて大きな影響を与え、データセットごとに最適解が異なるという深刻な不安定性を引き起こしていることが本研究の体系的な調査によって明らかになりました。
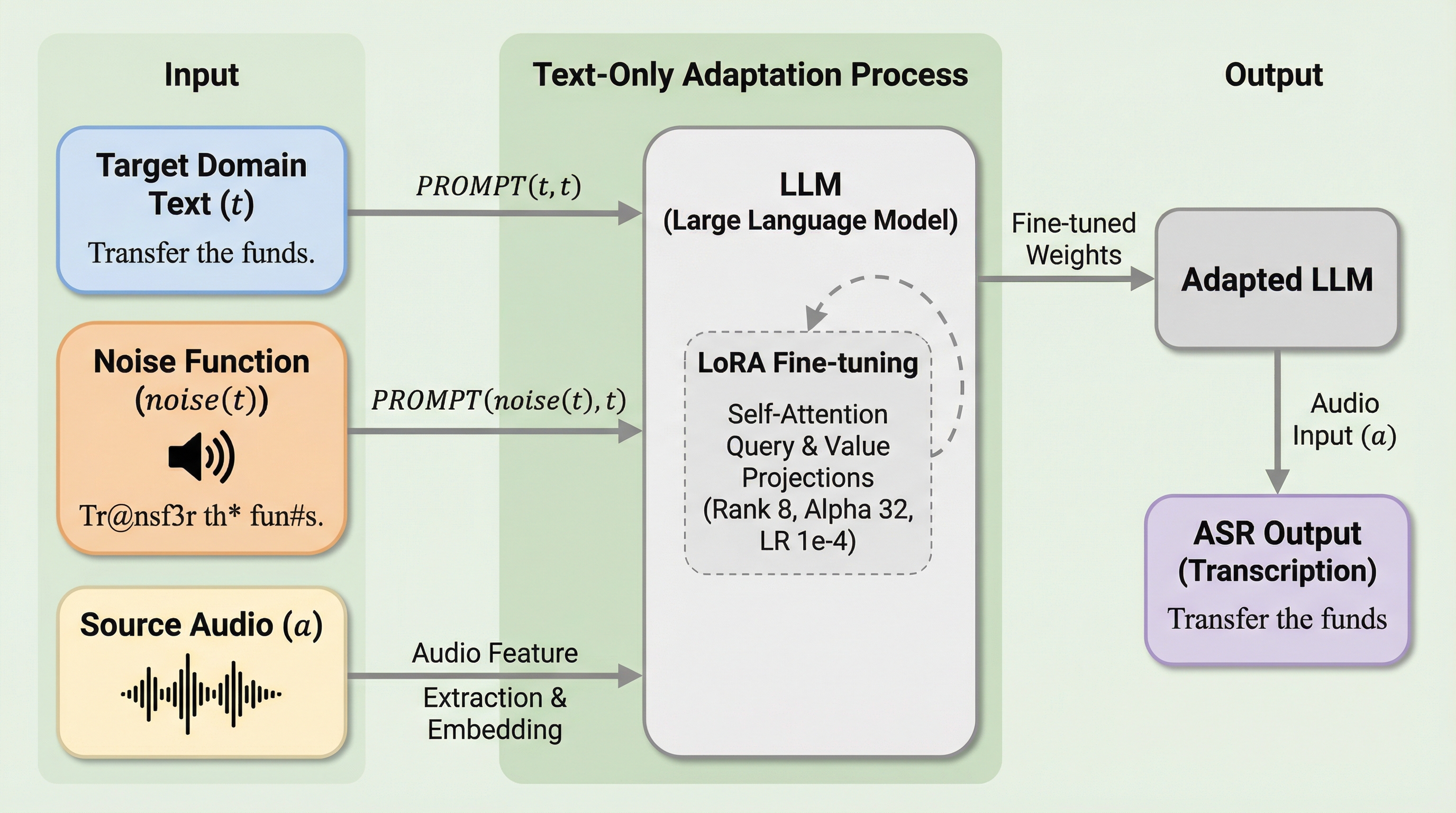
大規模言語モデル(LLM)を活用した音声認識システム(ASR)において、音声とテキストが対になっていないテキストのみのデータを用いて新しいドメインに適応させることは、音声とテキストの整合性を維持する観点から困難な課題であった。
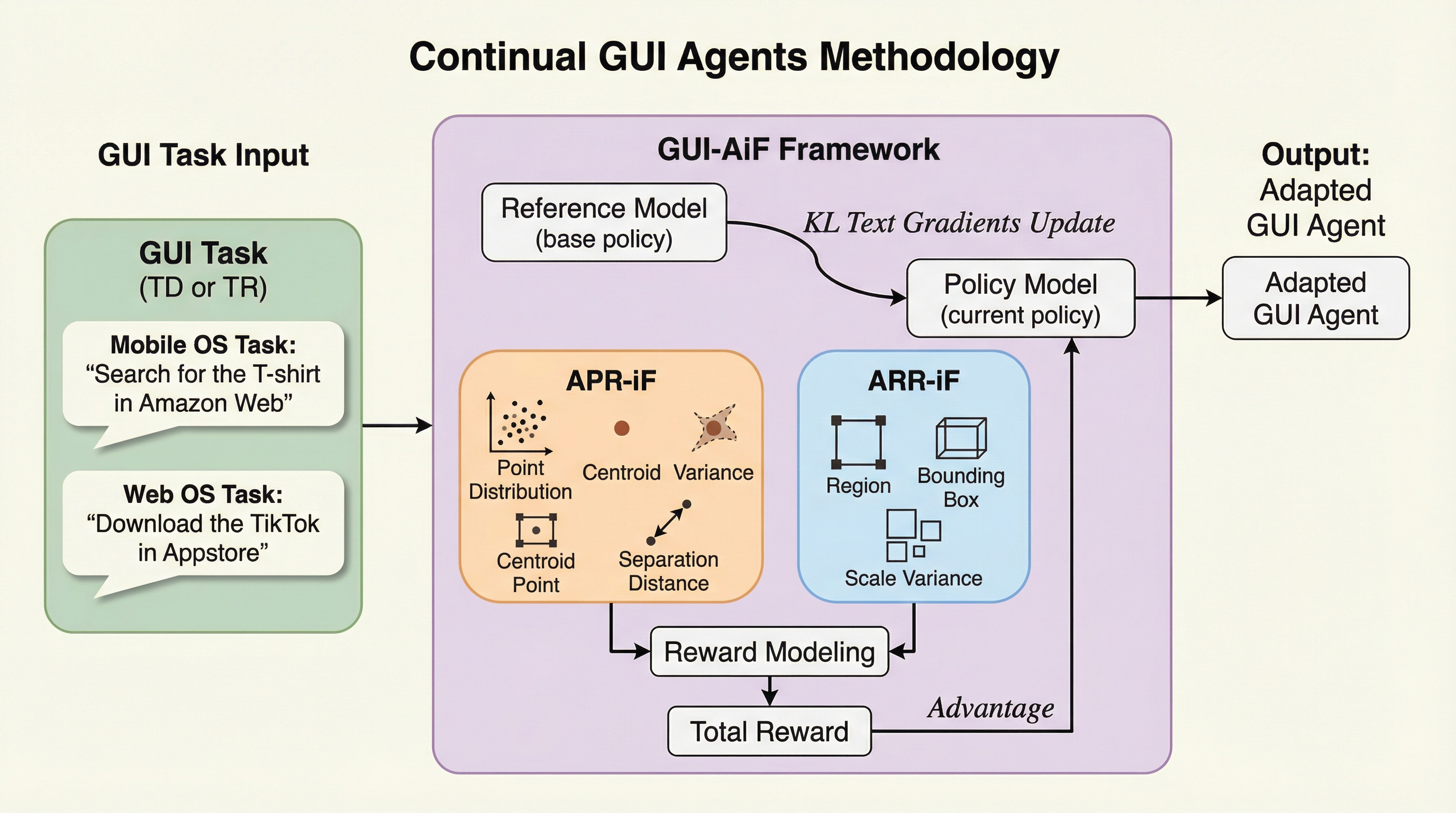
現代のデジタル環境は、OSの更新やデバイスの多様化、解像度の変化によって常にデータの分布が変動する「流動的(Flux)」な状態にあり、固定されたデータセットで学習した従来のGUIエージェントでは、未知のドメインや高解像度環境において性能が著しく低下するという課題がある。
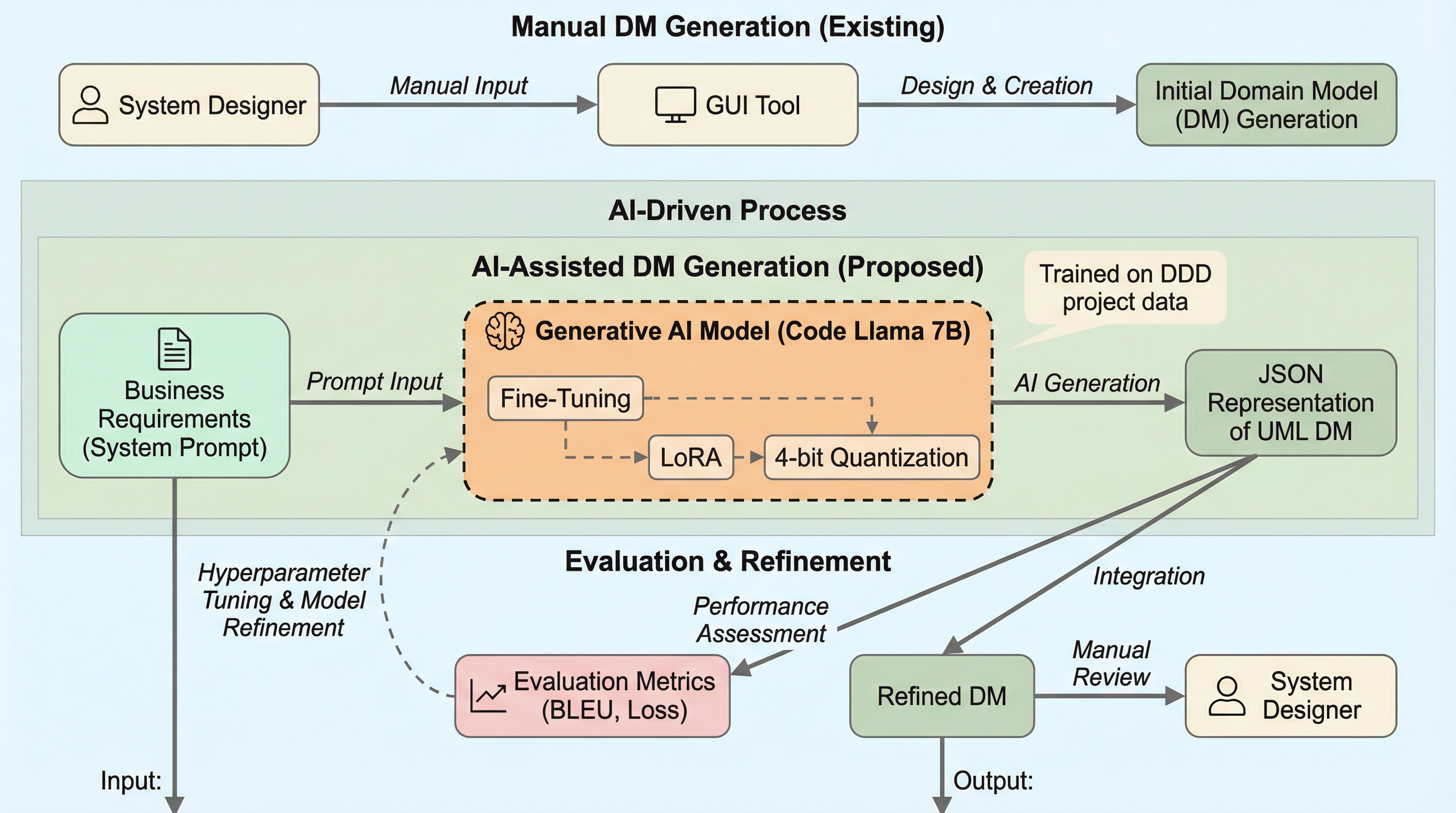
ドメイン駆動設計(DDD)におけるメタモデル作成の自動化を目指し、Code Llama 7Bを4ビット量子化とLoRAを用いて、消費者向けGPUという限られた計算資源環境下で微調整した。 実世界のプロジェクトデータを用いた学習により、単純なプロンプトから構文的に正しいJSONオブジェクトを生成することに成功し、設計プロセスの効率化とリソース削減の可能性を示した。 評価指標としてBLEUスコアと損失関数を用い、明確なプロンプトでは100%の構文的正しさを達成したが、トークン制限による繰り返しやデータ分割に起因する構造的課題も確認された。
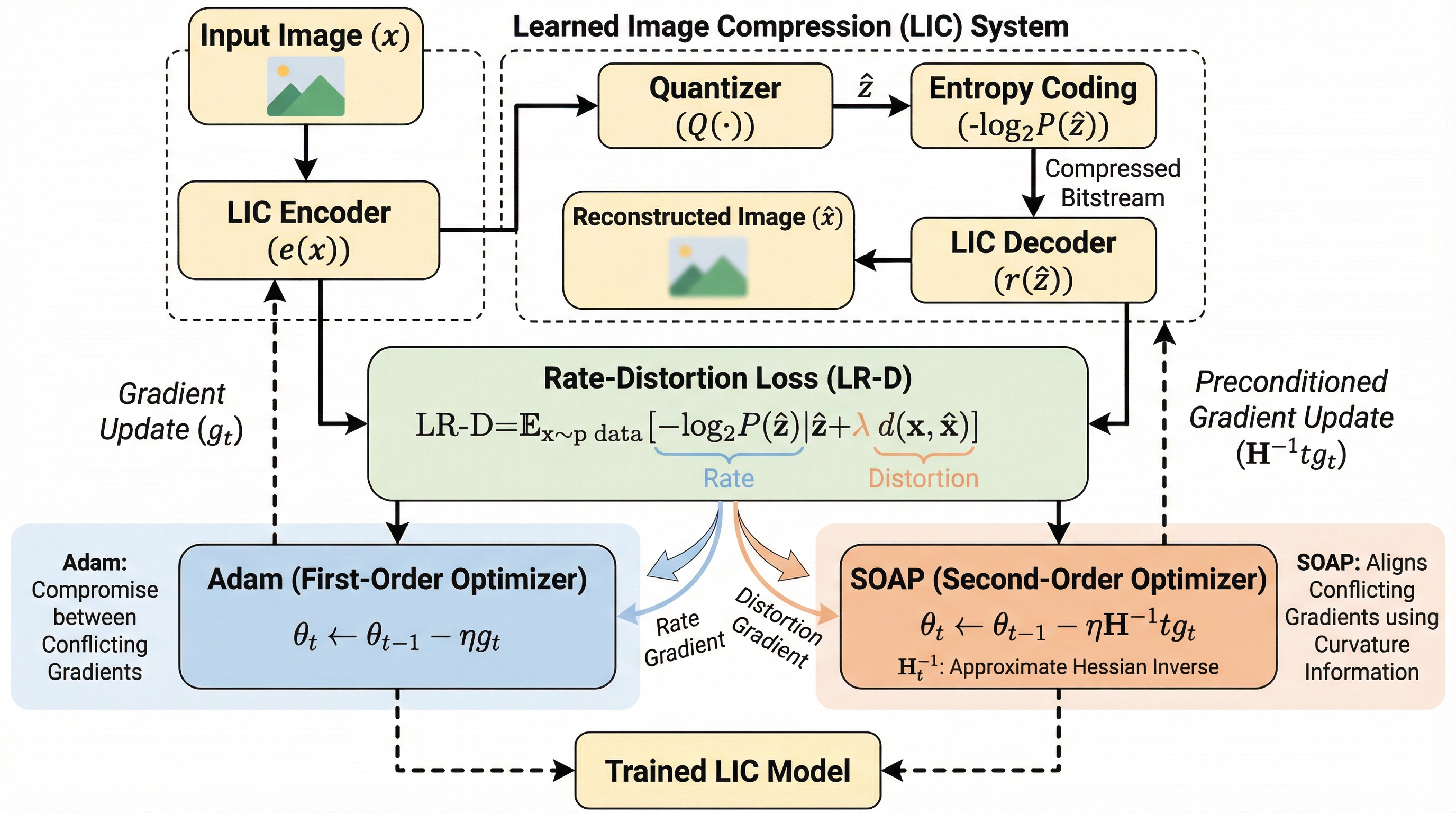
学習型画像圧縮(LIC)の訓練において、従来のAdam等の1次最適化手法はビットレートと歪みの目的関数間で生じる勾配競合により、収束の遅延や性能不足という課題を抱えていたが、本研究は2次準ニュートン最適化手法「SOAP」を導入することでこれを解決した。