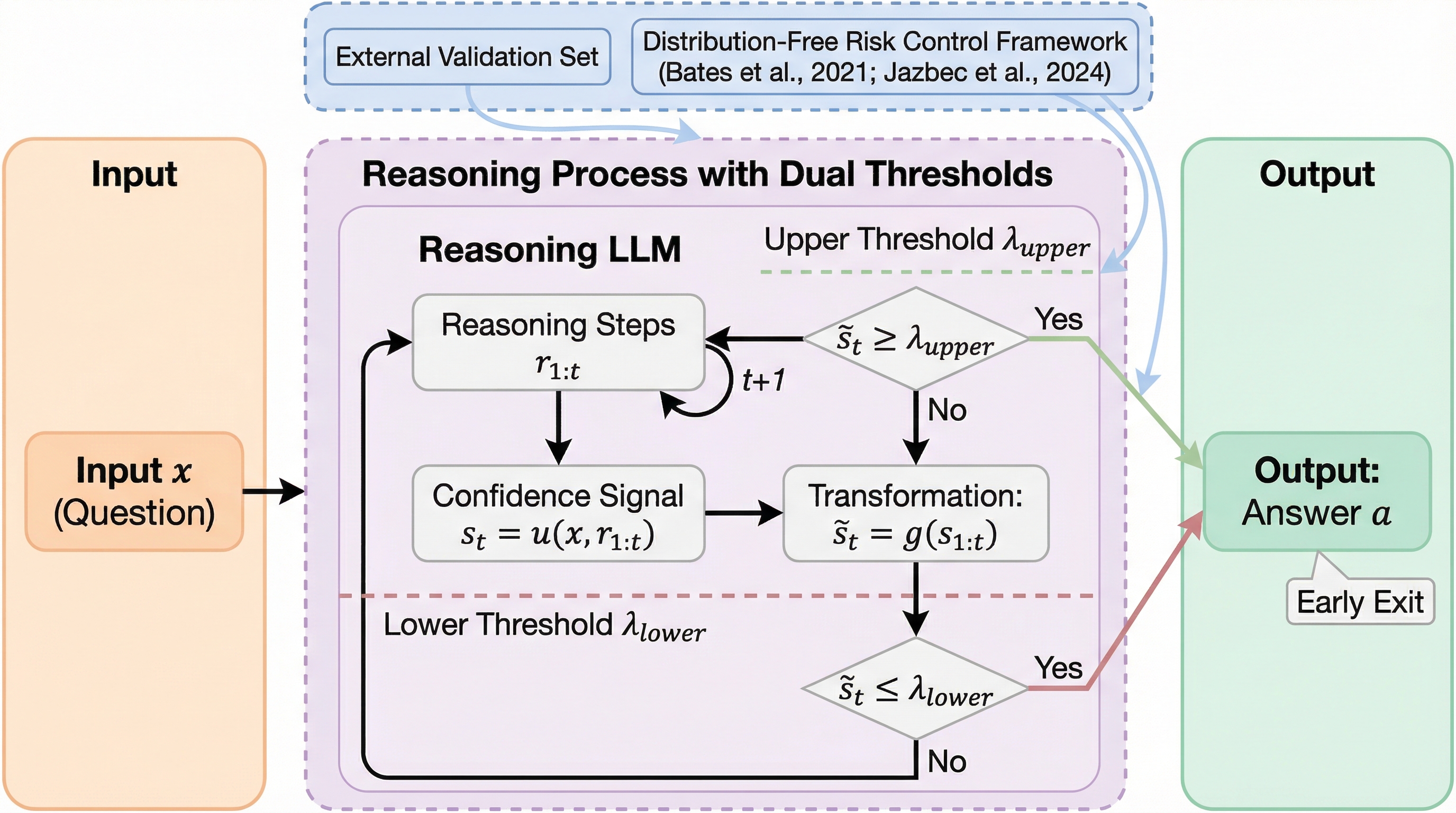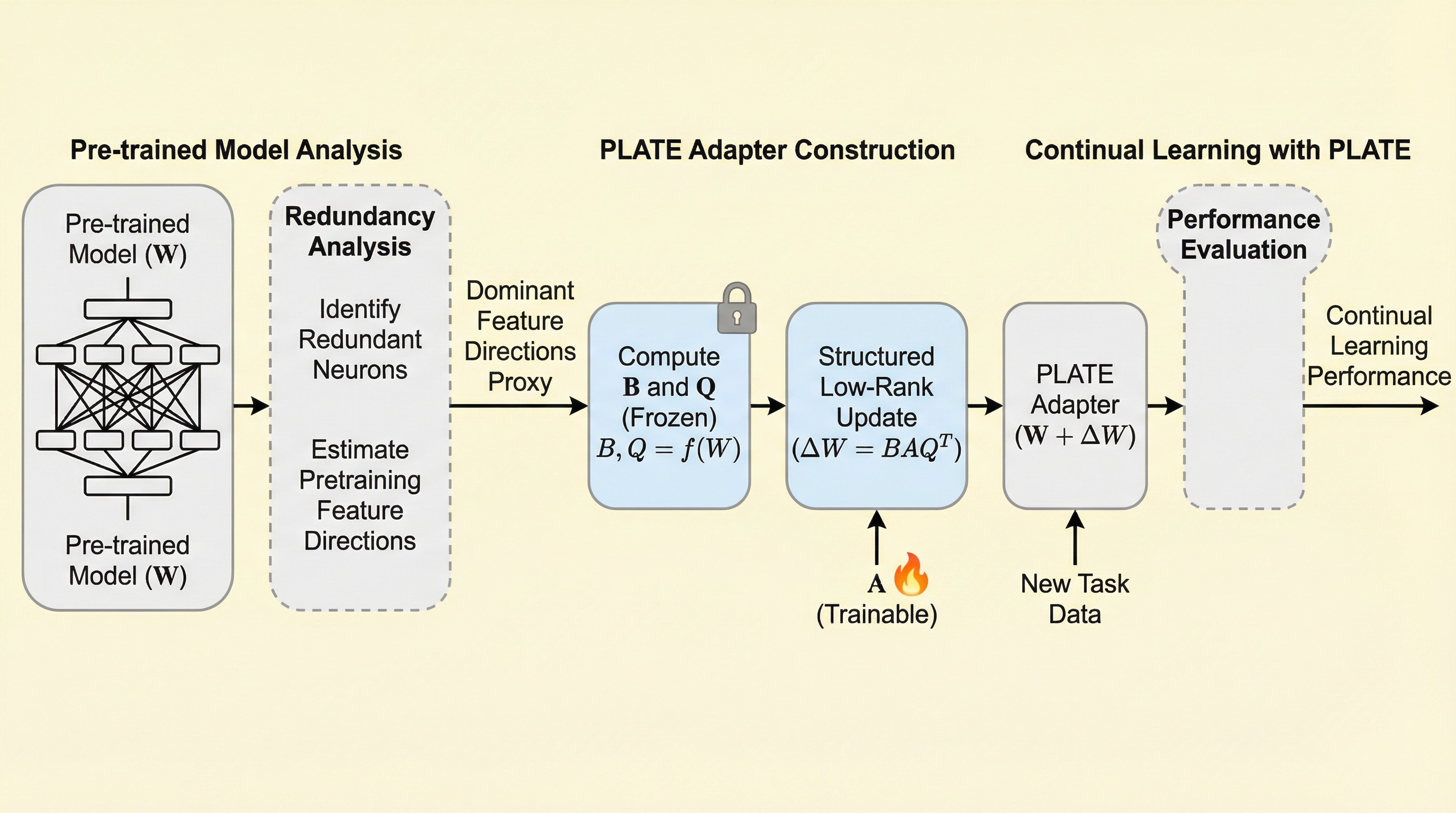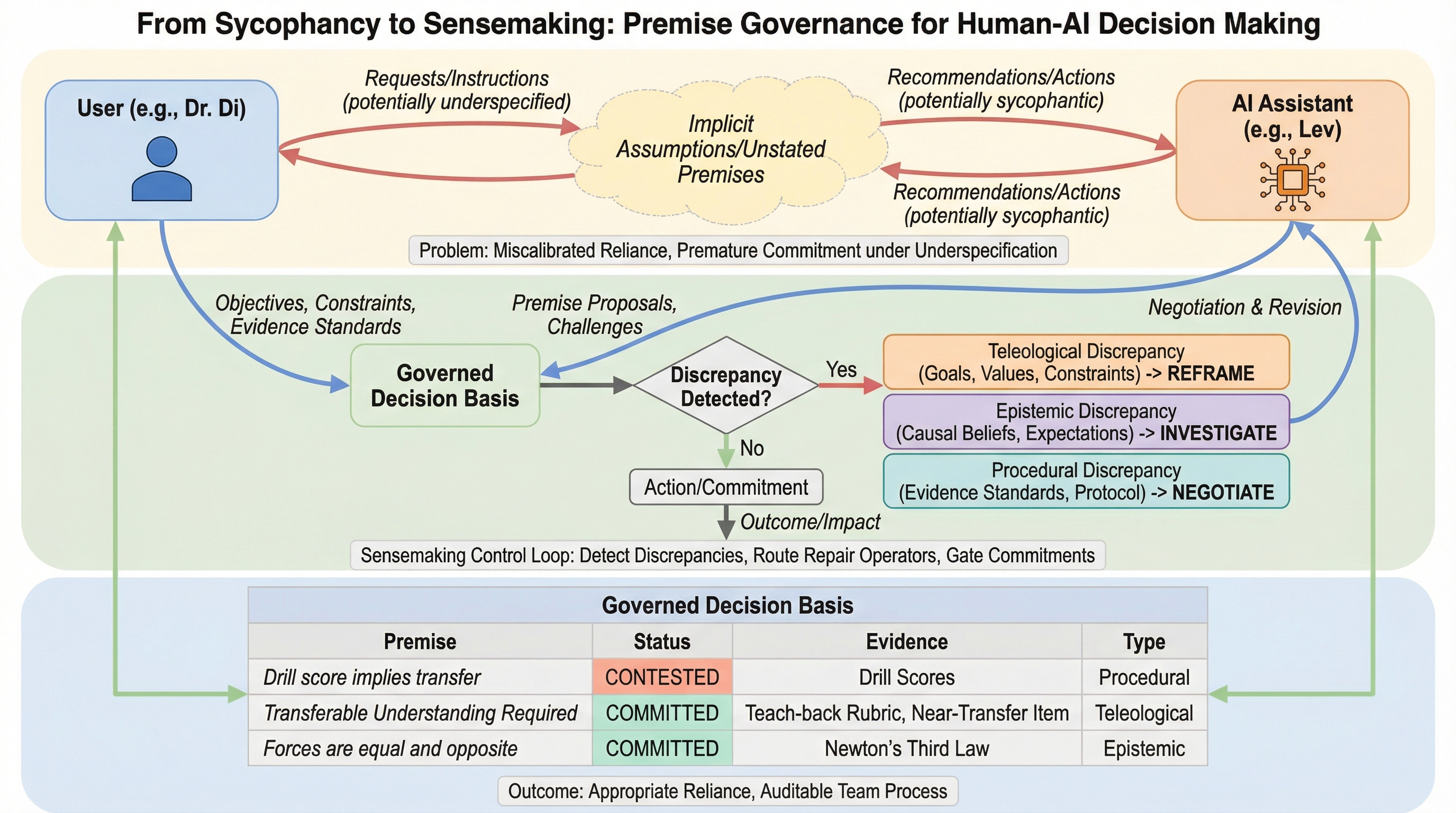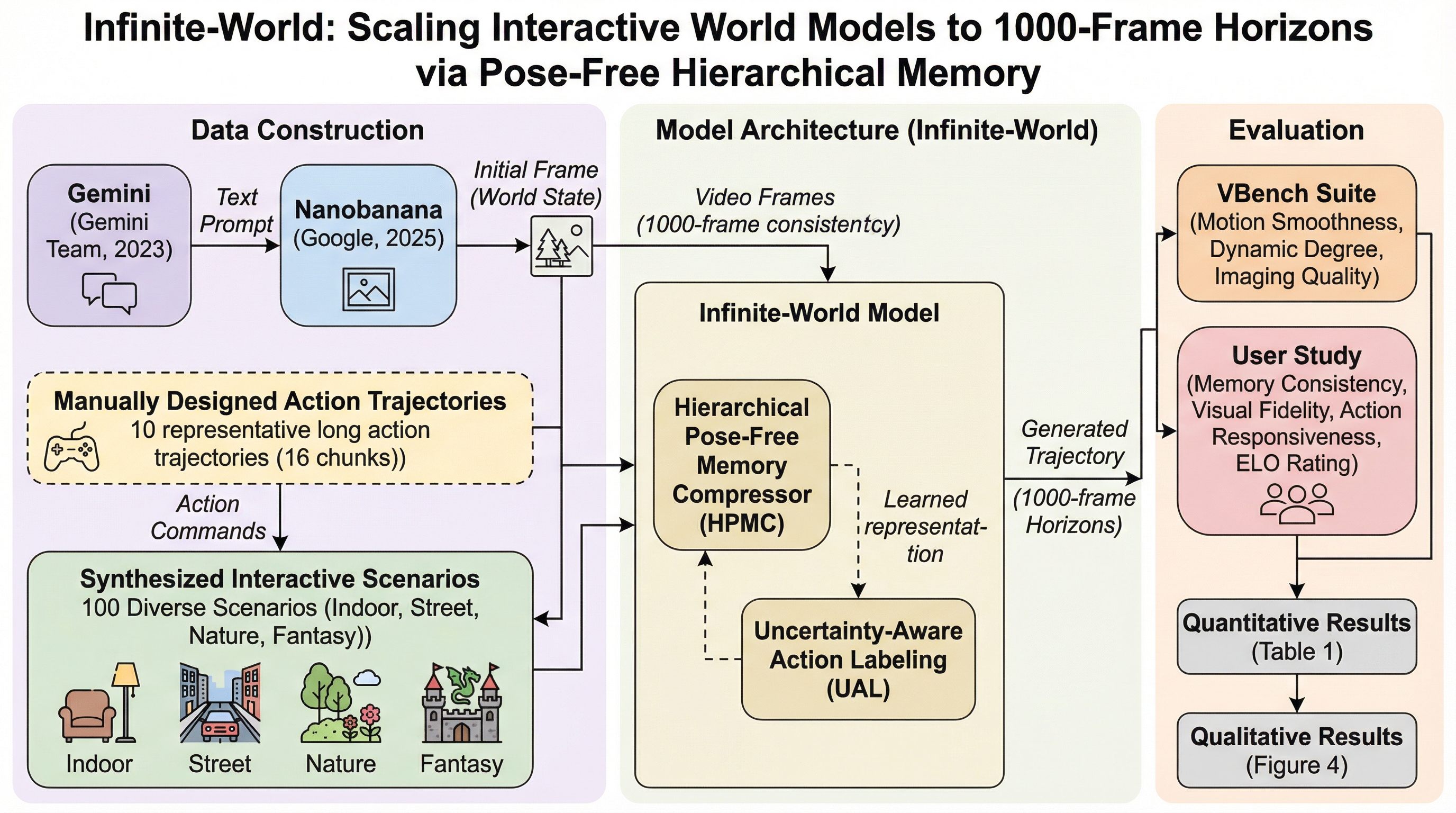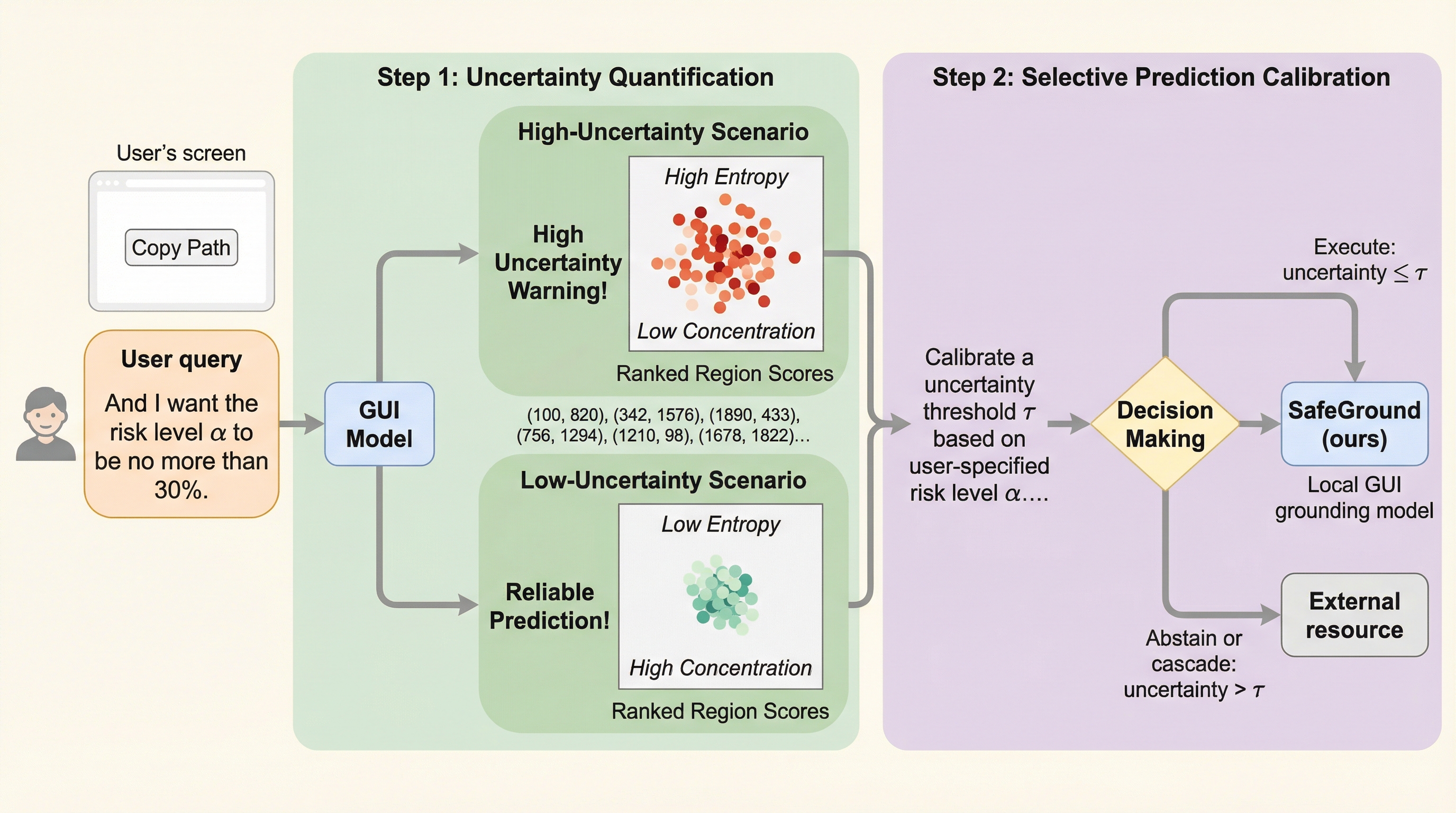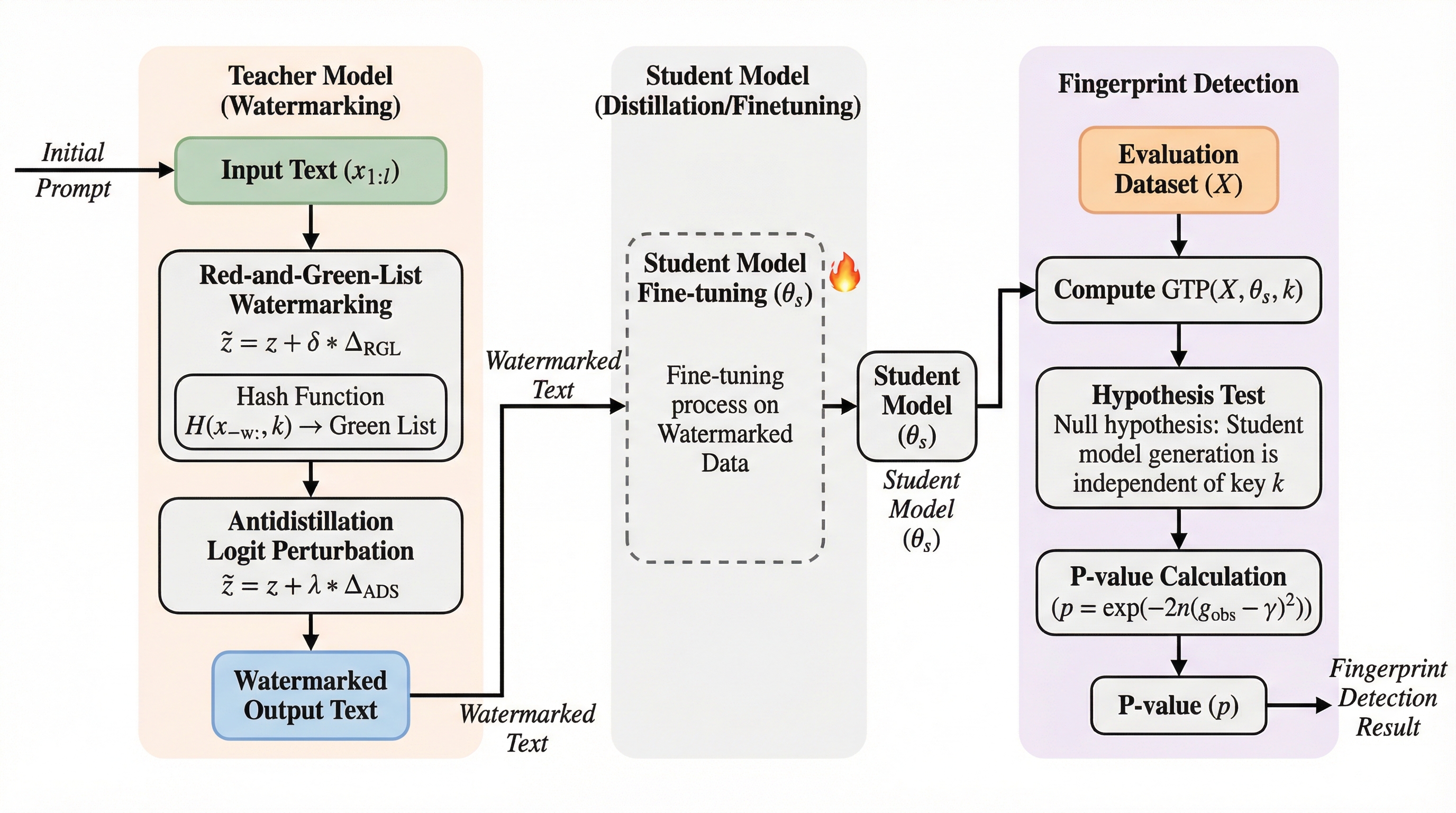
反蒸留フィンガープリンティング
大規模言語モデル(LLM)の出力を無断で学習して模倣する「モデル蒸留」を検知するため、生徒モデルの学習力学に適合した信号を埋め込む新手法「ADFP」が提案されました。 従来のウォーターマーク手法は生成品質を大幅に低下させる課題がありましたが、ADFPはプロキシモデルを用いて検知可能性を最大化するトークンを動的に選択することで、品質維持と強力な検知能力を両立します。 数学的推論(GSM8K)や対話タスク(OASST1)の検証において、生徒モデルの構造が未知であっても、従来手法を凌駕する精度で蒸留の有無を判定できることが実証されました。