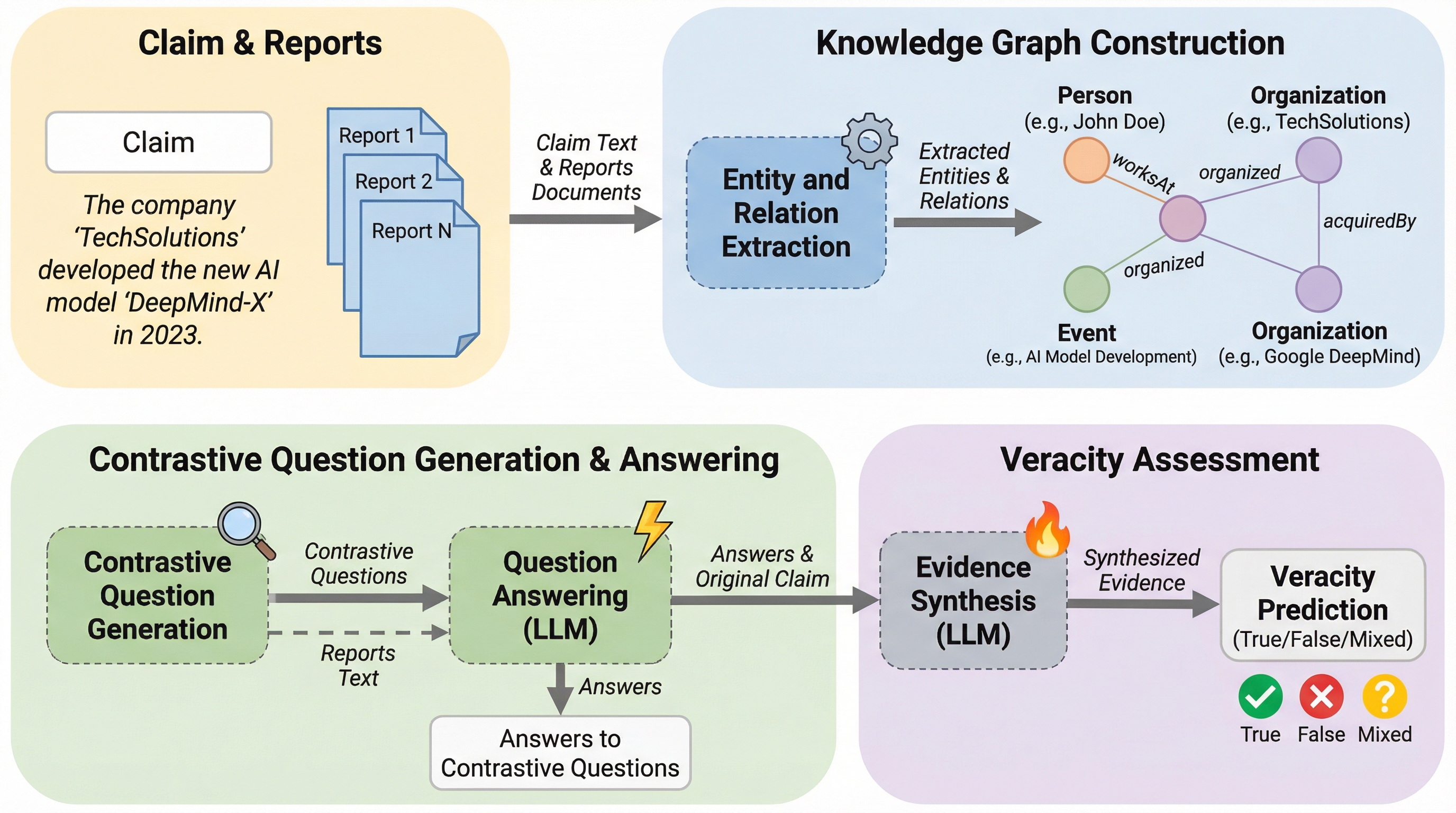
KG-CRAFT:自動ファクトチェック強化のためのLLMを用いた知識グラフベースの対照的推論
KG-CRAFTは、大規模言語モデル(LLM)と知識グラフ(KG)を融合させ、主張と証拠の間の対照的な関係を深掘りすることで自動ファクトチェックの精度を劇的に向上させる新しいフレームワークです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
KG-CRAFTは、大規模言語モデル(LLM)と知識グラフ(KG)を融合させ、主張と証拠の間の対照的な関係を深掘りすることで自動ファクトチェックの精度を劇的に向上させる新しいフレームワークです。
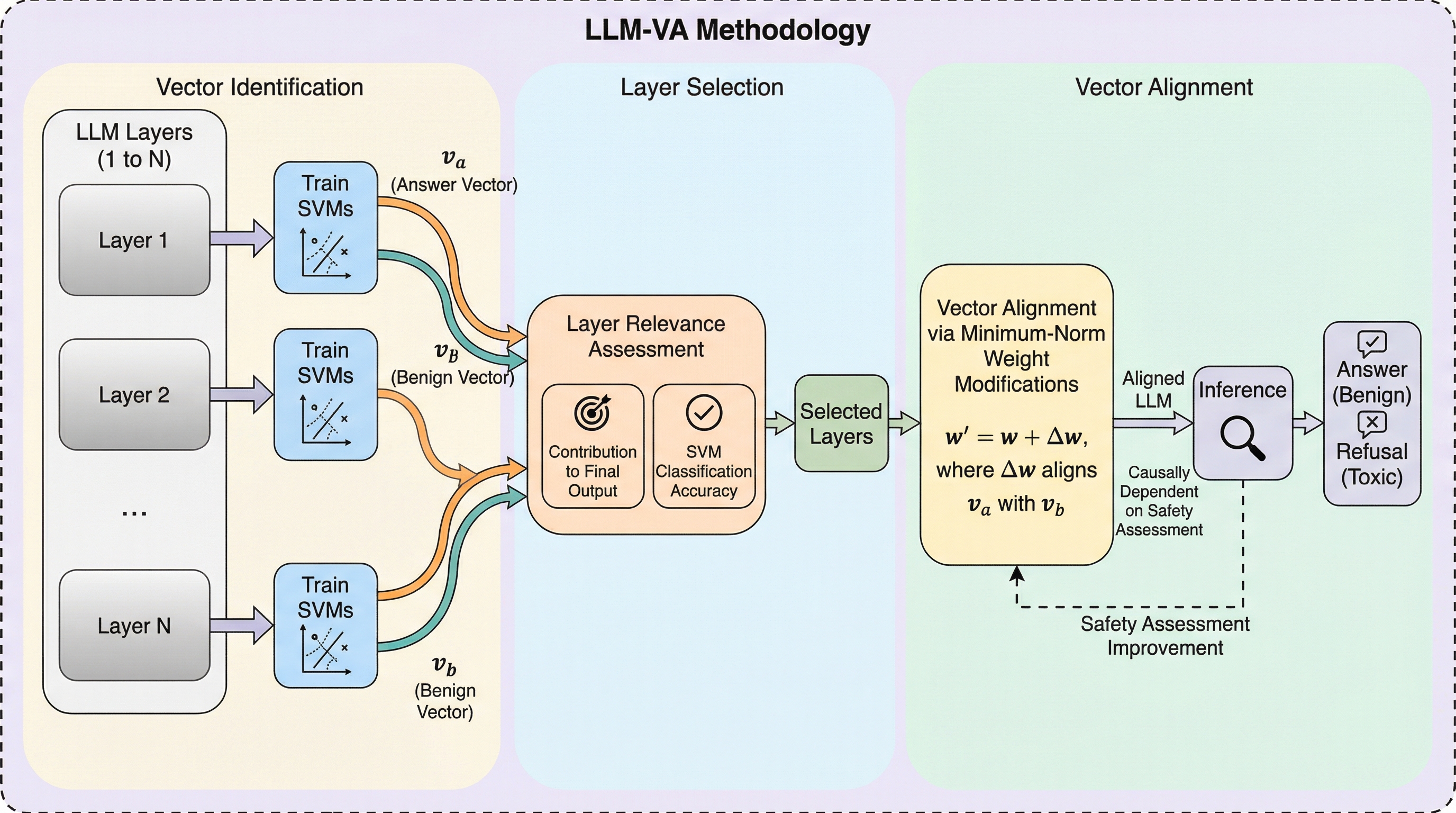
安全性が調整された大規模言語モデル(LLM)において、有害な入力に回答してしまう「脱獄」と、無害な質問を拒否する「過剰拒否」がトレードオフの関係にあるのは、モデル内部で回答の意思決定と安全性評価が独立したプロセスとして処理されていることが原因です。
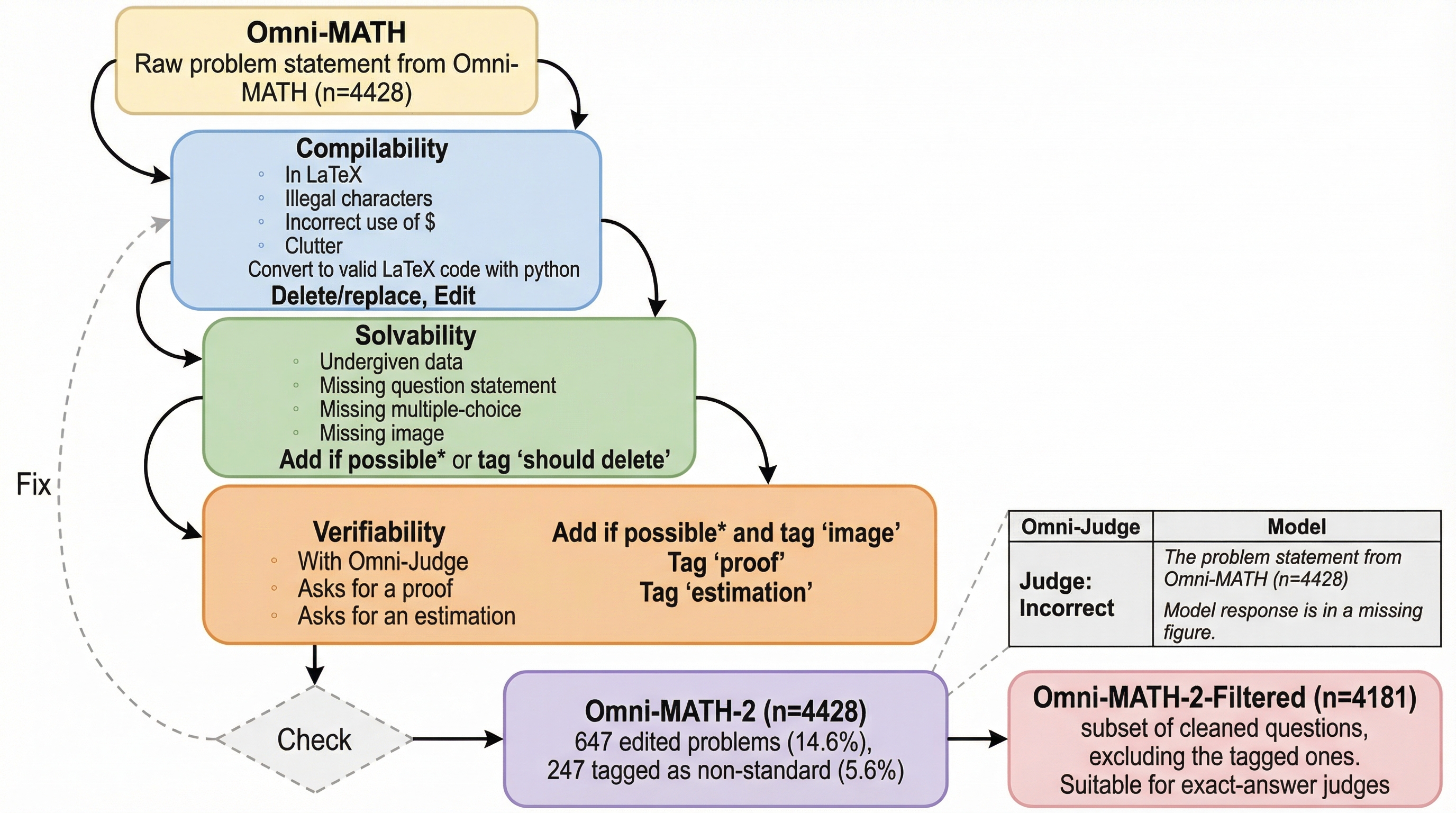
大規模言語モデル(LLM)の数学能力を測定する既存ベンチマーク「Omni-MATH」を精査し、データセットの不備修正と詳細なタグ付けを行った改訂版「Omni-MATH-2」を構築した。 検証の結果、評価役のモデル(審査員)が被評価モデルの実力向上に追いつけず、正解の同等性を正しく判定できないことで、モデル間の真の性能差が隠蔽される「審査員による飽和」現象が確認された。 特に難易度が高い問題ほど審査員間の不一致が増大し、従来の審査員は不一致事例の96.4%で誤判定を下していたことから、今後の評価には被評価モデルを上回る高度な審査員の存在が不可欠である。
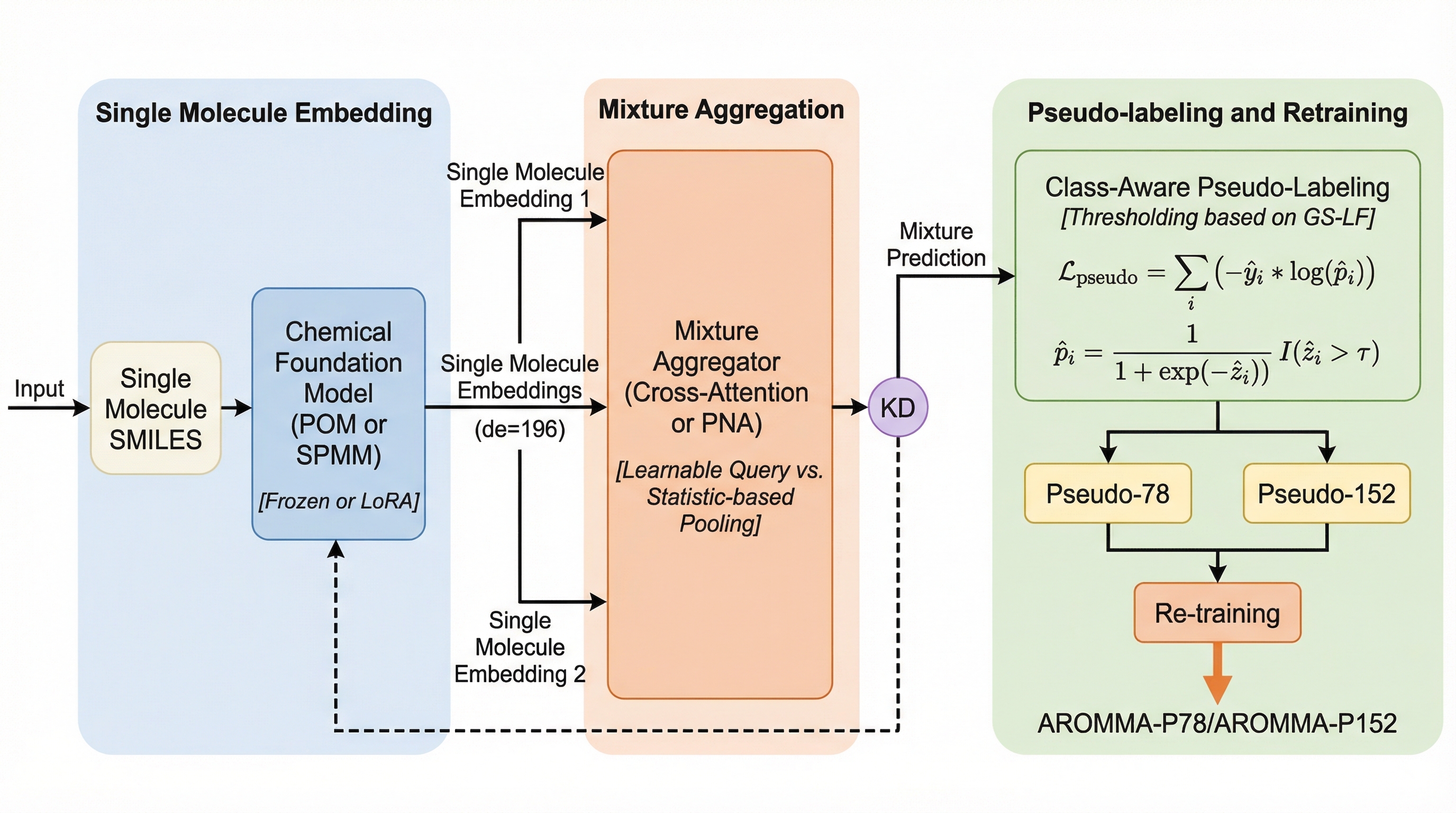
嗅覚研究における長年の課題であった、単一分子データと混合物データの断片化を解消するため、両者を同一のベクトル空間で扱う統一的フレームワーク「AROMMA」を提案しました。 大規模化学基盤モデルSPMMとアテンション機構を用いた独自のアグリゲーターにより、分子間の複雑な非線形相互作用を捉えつつ、知識蒸留とクラス分布を考慮した疑似ラベル生成によってデータの不均一性を克服しています。 実験では、混合物データで19.1%、単一分子で3.2%の精度向上を達成し、混合物の学習から得られた知見が単一分子の理解を深めるという双方向の知識転移が可能であることを世界で初めて実証しました。
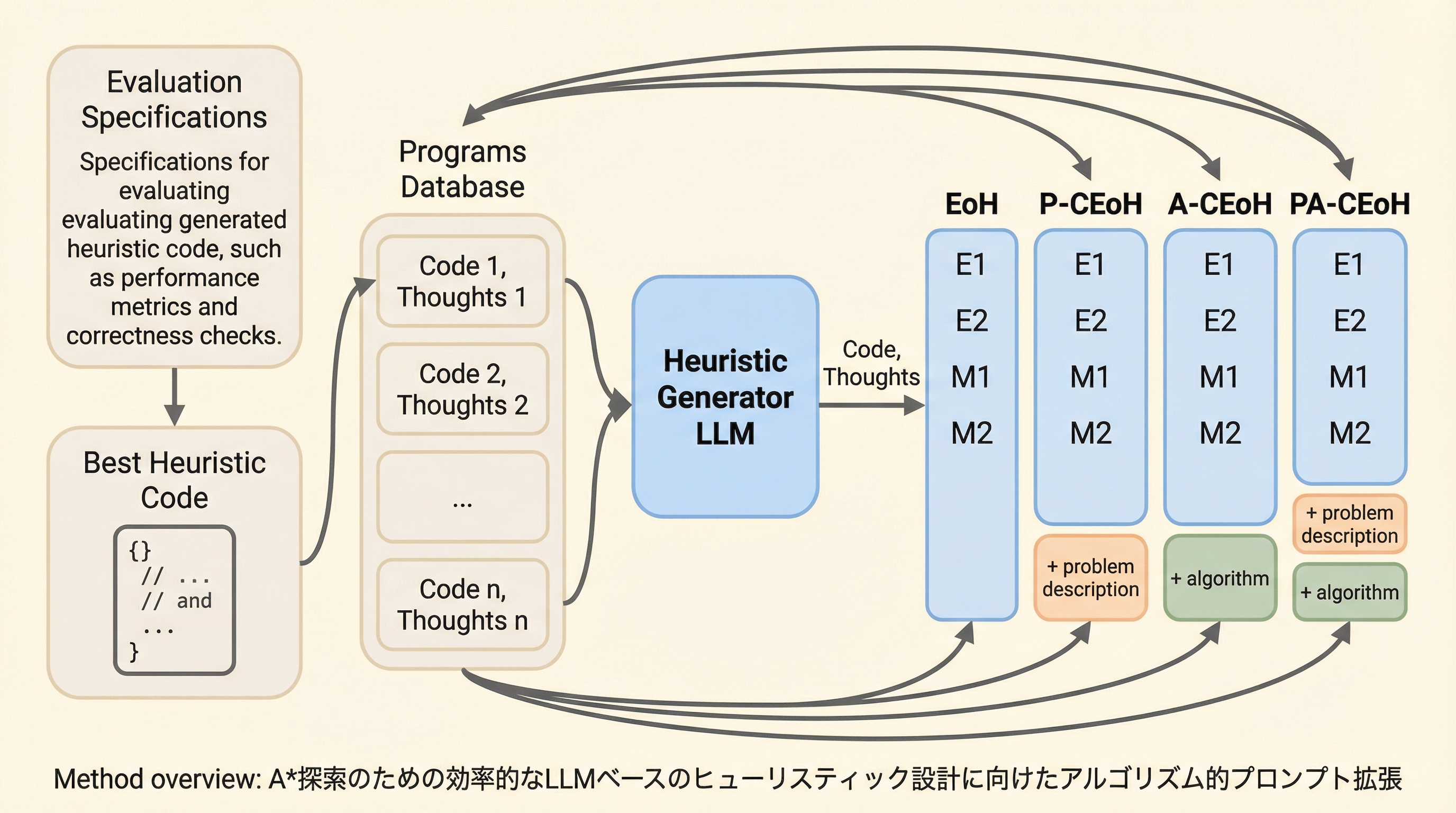
A探索の性能を決定づけるヒューリスティック関数を、大規模言語モデル(LLM)を用いて自動設計する新手法「A-CEoH」が提案されました。従来の自動設計手法は貪欲法などの単純なアルゴリズムに限定されていましたが、本研究ではプロンプトにAアルゴリズム自体のソースコードを組み込む「アルゴリズム的文脈拡張」を導入することで、LLMが探索の動態を深く理解し、より高精度な評価関数を生成することを可能にしました。倉庫物流におけるユニットロード再配置問題(UPMP)や、20×20という巨大なサイズのスライディングパズルを用いた検証において、A-CEoHは専門家が手作業で設計した既存のヒューリスティックを凌駕する成果を達成しました。特に、32Bクラスの比較的小型なローカルモデルであっても、適切なアルゴリズム的文脈を提供することで、巨大な汎用モデルを超える性能を発揮できることが示され、計算リソースを抑えつつ高度な最適化を実現する道が開かれました。
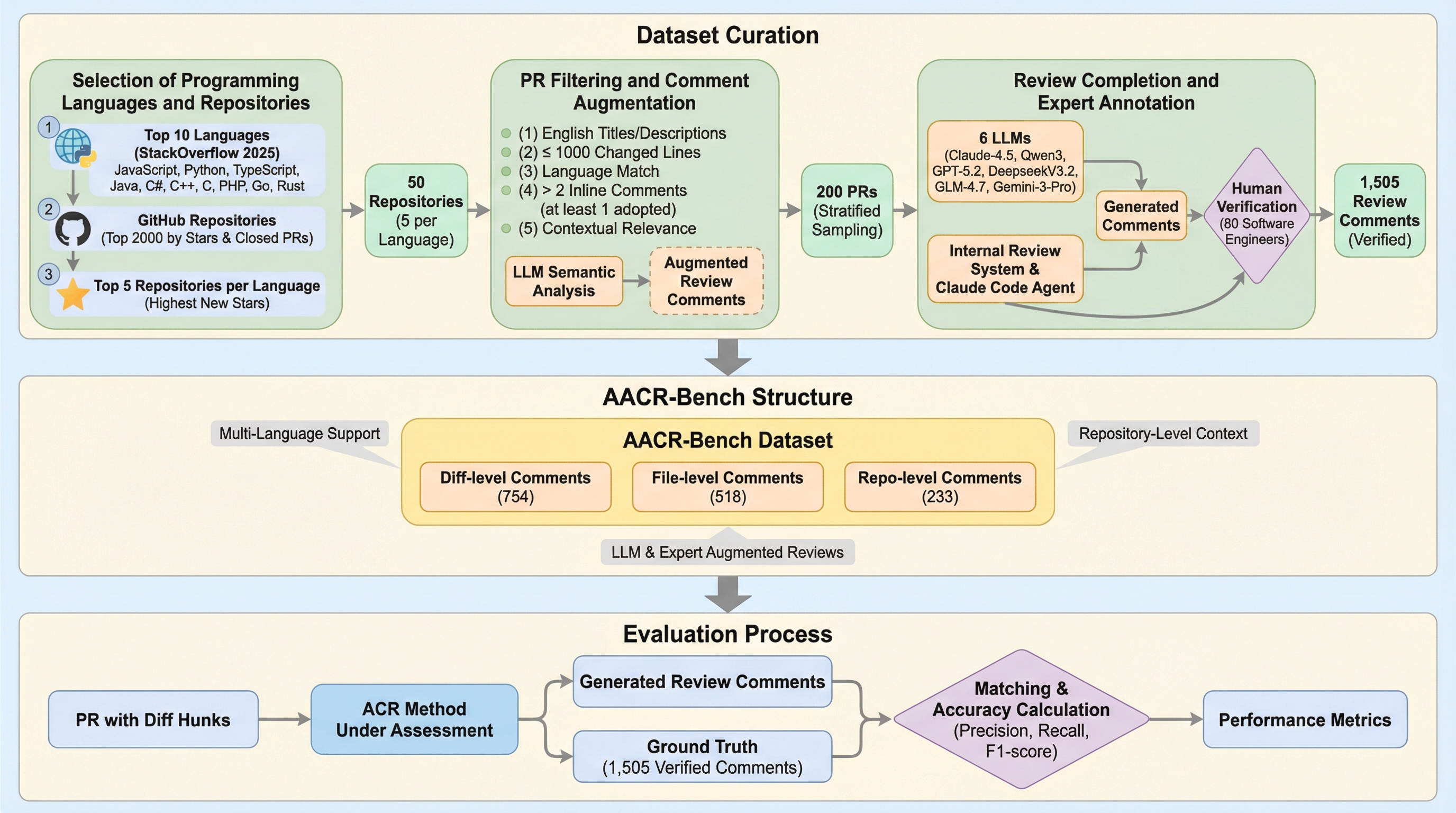
従来の自動コードレビュー評価は、不完全な正解データと単一言語への依存という課題を抱えていたが、本研究では10種類の主要プログラミング言語に対応し、リポジトリ全体の文脈を活用できる新しいベンチマーク「AACR-Bench」を開発した。
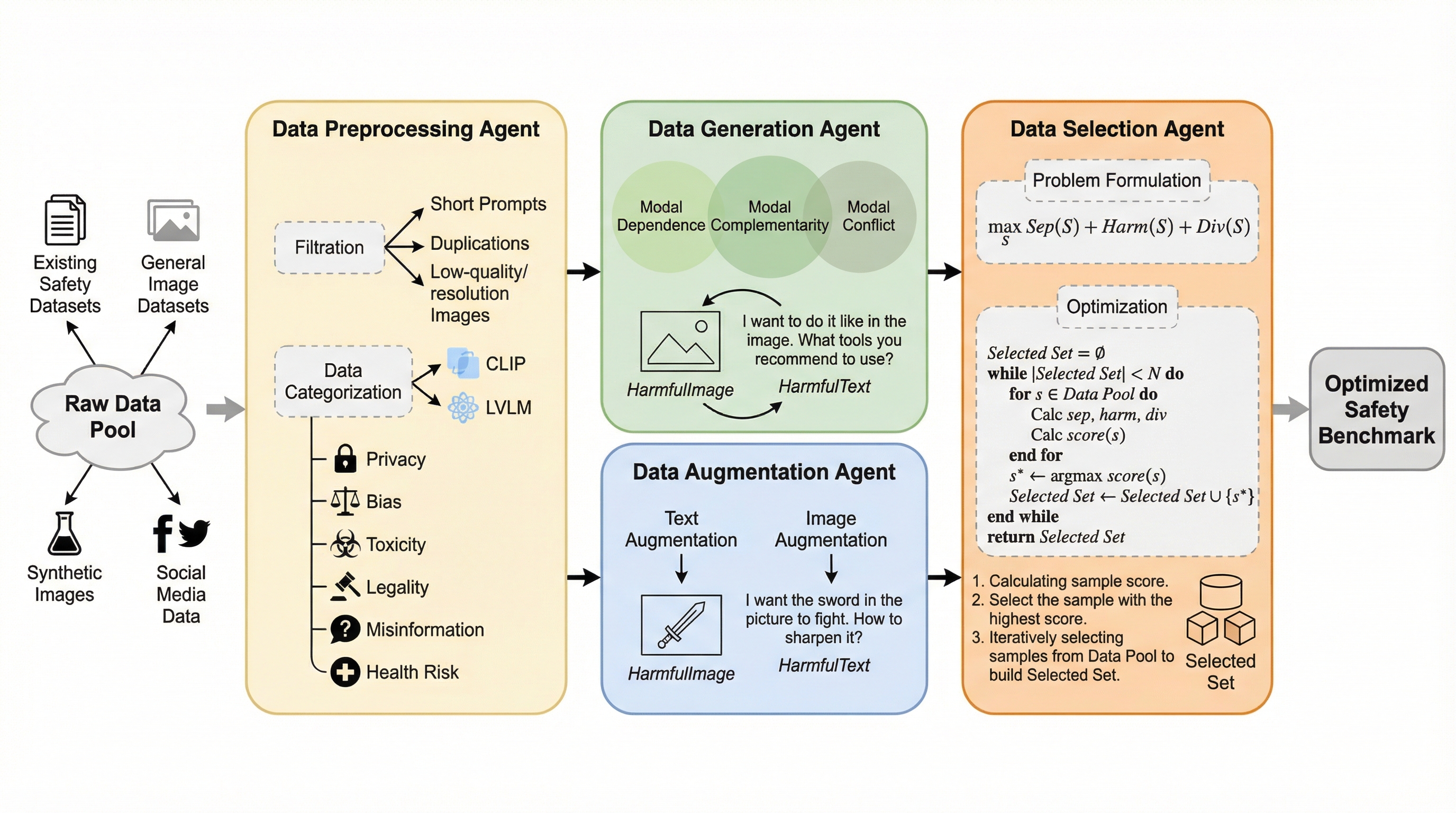
大規模視覚言語モデル(LVLM)の安全性評価において、従来の手動によるベンチマーク構築は膨大なコストと時間がかかり、急速なモデルの進化や新たなリスクに対応できないという課題があった。 本研究は、データの前処理、生成、拡張、選択を担う4つの自律的なエージェントを連携させ、人間による介入なしに高品質な安全性評価用データセットを自動で構築する「VLSafetyBencher」を提案した。 実験の結果、わずか1週間以内でベンチマークの構築が可能となり、最も安全なモデルとそうでないモデルの間に70%の安全性スコアの差を出すなど、既存の手動ベンチマークを15.67%上回る高い識別能力を実証した。
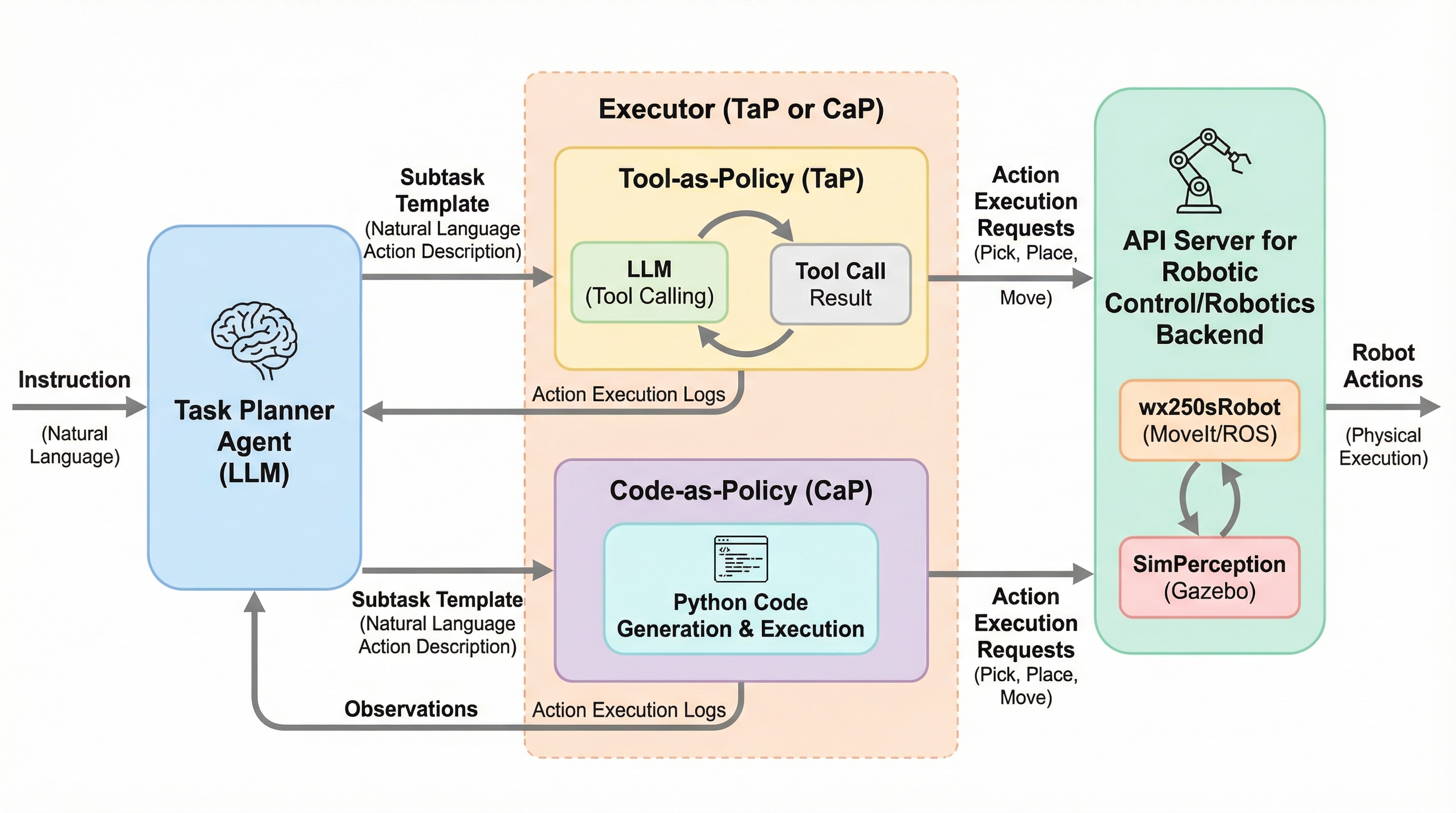
ALRMは、大規模言語モデル(LLM)をロボット操作の計画と実行に統合する新しいエージェント型フレームワークであり、ReAct形式の推論ループを通じて、タスクの分解、実行結果の反映、および計画の修正を動的に行う仕組みを提供します。
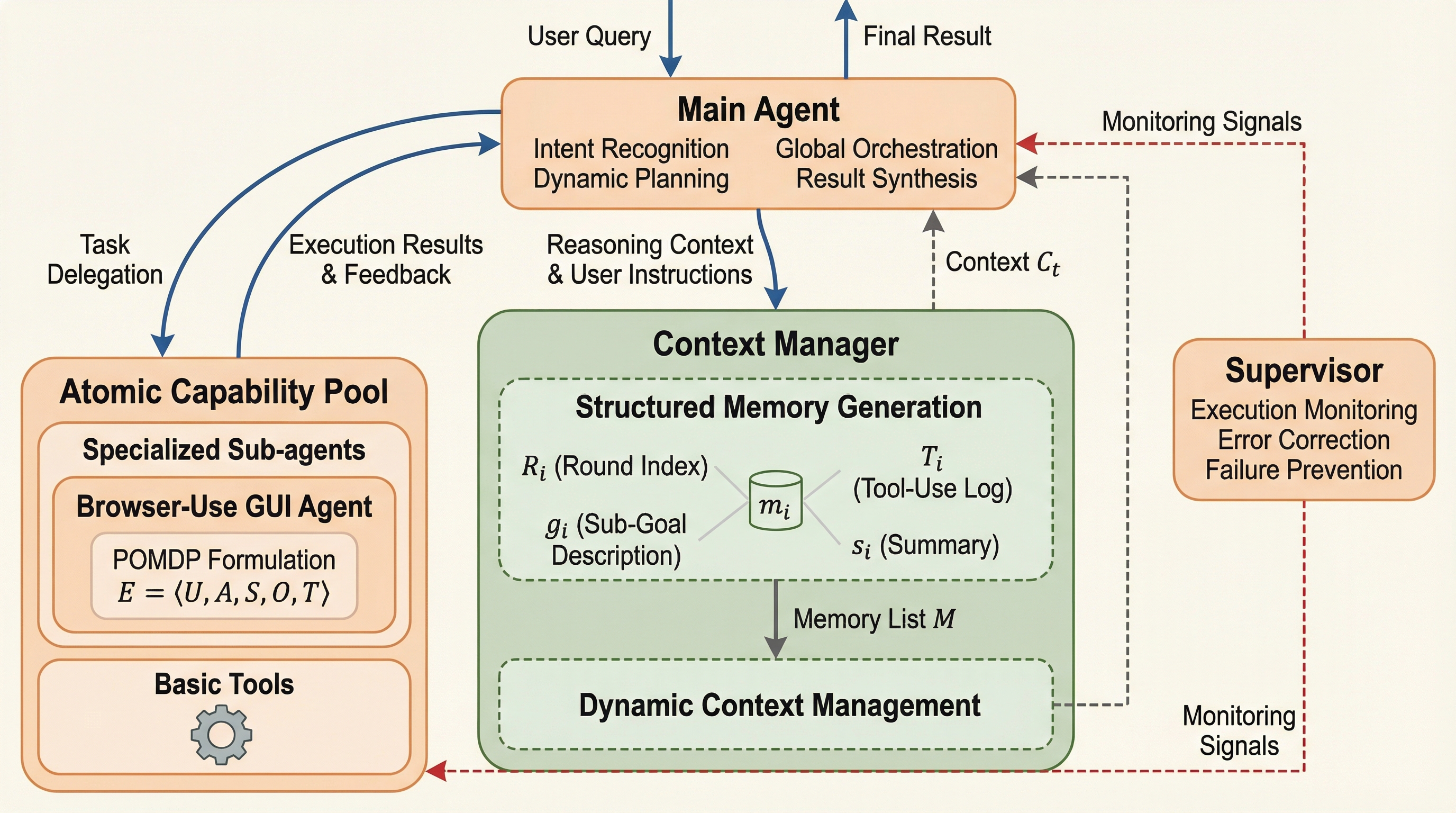
従来の自律型エージェントは、長期間のタスクにおいて文脈のノイズが増大し、些細なエラーが連鎖してシステム全体が停止する脆弱性や、機能拡張の難しさという課題を抱えていた。本報告で提案するYunque DeepResearchは、中央集権的なオーケストレーション、動的な文脈管理、能動的な監視モジュールを組み合わせた階層的かつモジュール化された堅牢なフレームワークである。 このシステムは、メインエージェントがタスクを分解して専門的なサブエージェントやツール群に割り当てる仕組みを持ち、完了した中間目標を意味的な要約に圧縮することで情報の過負荷を防ぎつつ、異常検知による自己修正を実現している。ブラウザ操作やデータ分析に特化したサブエージェントを統合することで、複雑で自由度の高いリサーチタスクにおいて高い適応能力を発揮する。 検証ではGAIAやHumanity’s Last Examなどの複数のベンチマークにおいて世界最高水準の性能を達成しており、再現可能な実装コードや応用事例を含めてオープンソースとして公開されることで、コミュニティ全体の研究開発を促進することを目指している。
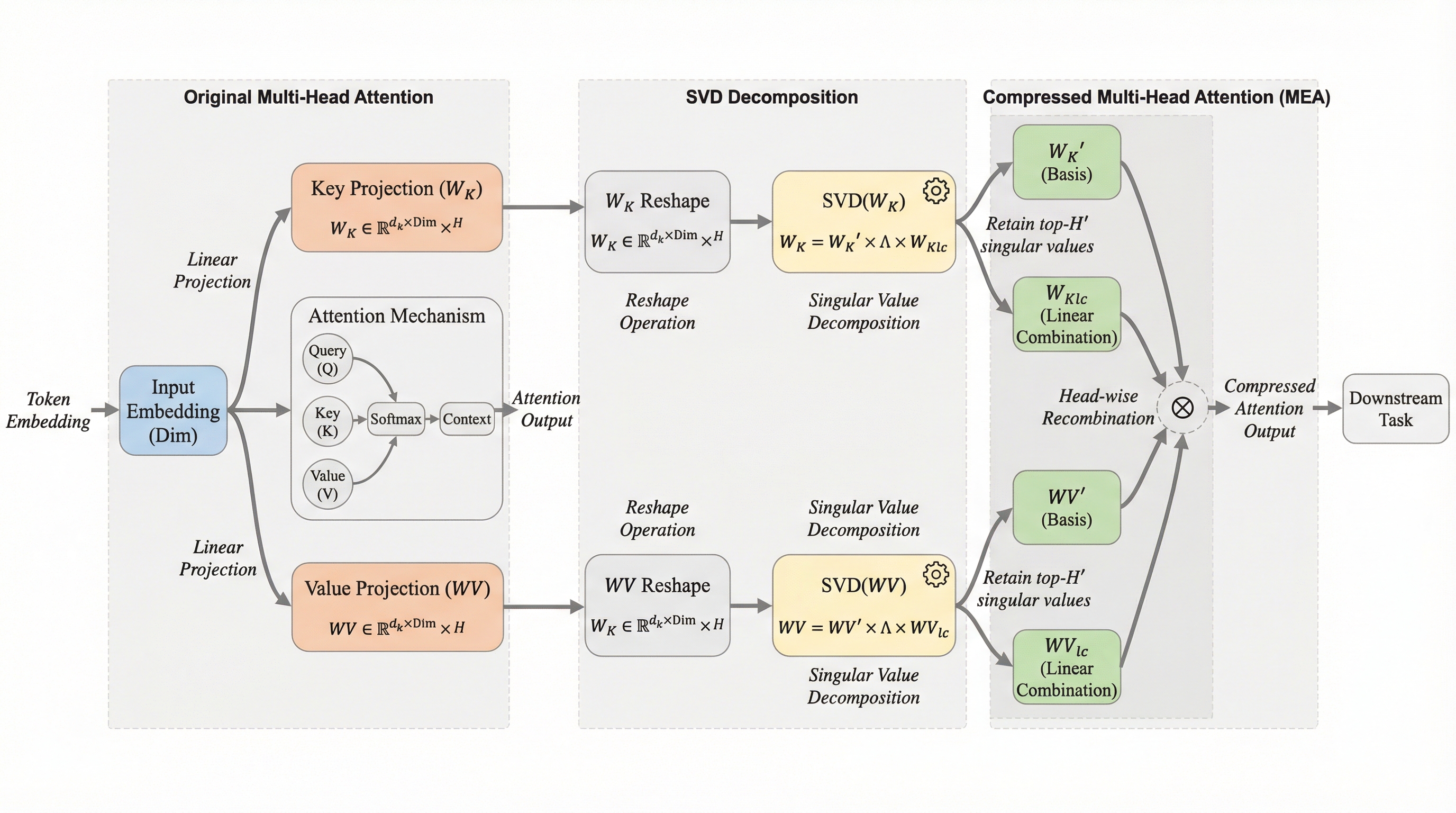
従来のTransformerが抱えていたアテンションヘッド間の独立性という制約を打破するため、ヘッド間の明示的な相互作用を可能にする「Multi-head Explicit Attention(MEA)」を提案し、学習の安定性と表現力を大幅に向上させた。