大規模言語モデルにおけるヘッド間相互作用のための明示的なマルチヘッドアテンション
従来のTransformerが抱えていたアテンションヘッド間の独立性という制約を打破するため、ヘッド間の明示的な相互作用を可能にする「Multi-head Explicit Attention(MEA)」を提案し、学習の安定性と表現力を大幅に向上させた。
TL;DR(結論)
従来のTransformerが抱えていたアテンションヘッド間の独立性という制約を打破するため、ヘッド間の明示的な相互作用を可能にする「Multi-head Explicit Attention(MEA)」を提案し、学習の安定性と表現力を大幅に向上させた。 ヘッドレベル線形結合(HLC)モジュールとグループ正規化を組み合わせることで、既存手法で問題となっていた学習時の退化現象を克服し、標準的なモデルよりも高い学習率での高速な収束と低い検証損失を達成することに成功した。 MEAの構造を活用して低ランクの仮想ヘッドを再構成する戦略により、知識集約的タスクや科学的推論での性能を維持したまま、推論時のKVキャッシュメモリ使用量を50%削減するという極めて高い実用性を証明した。
なぜこの問題か
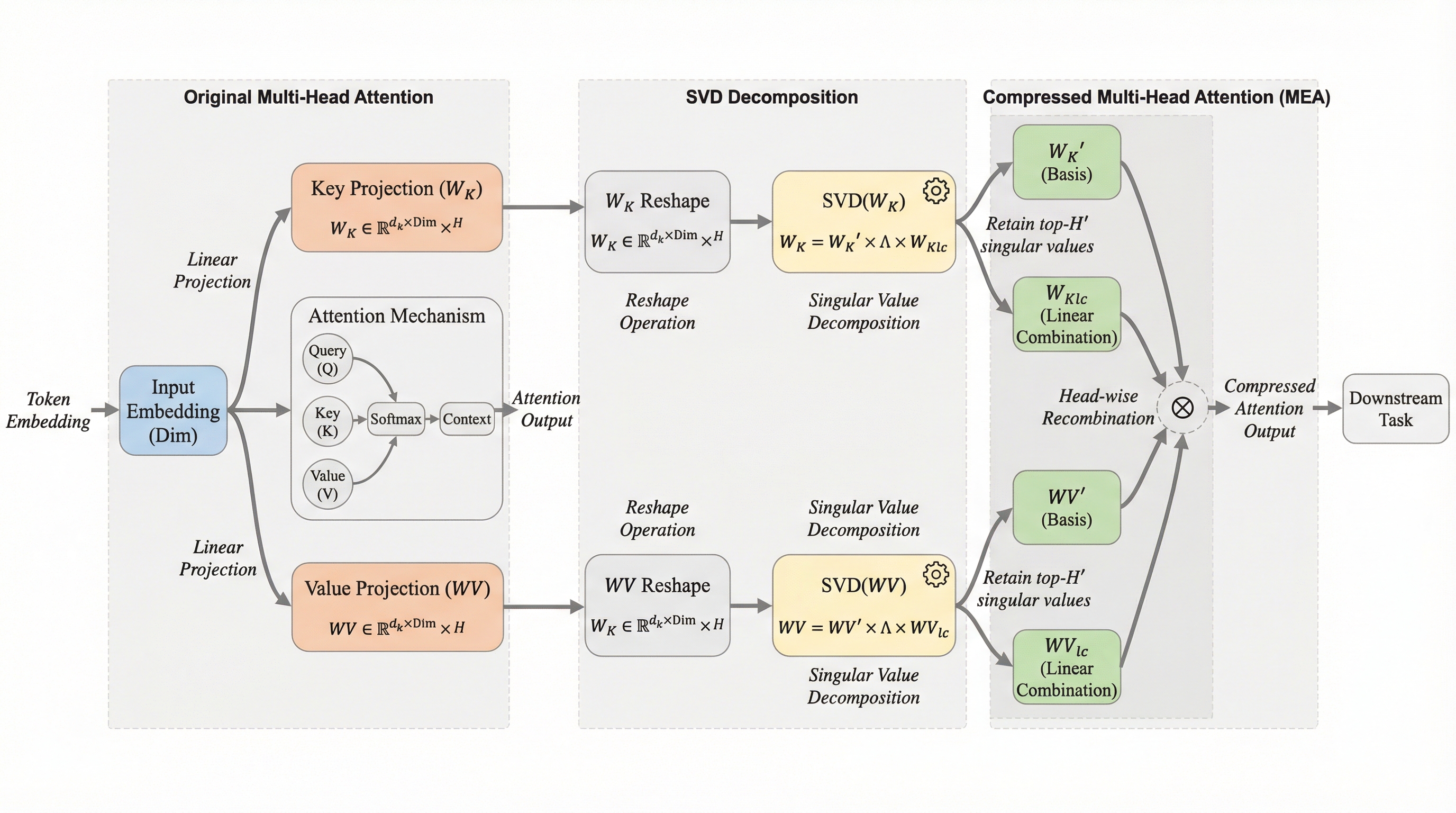
トランスフォーマーアーキテクチャに基づく大規模言語モデルにおいて、近年の研究はヘッド間の相互作用がアテンション性能を向上させることを示している。これに着想を得て、我々はヘッド間の相互作用を明示的にモデル化する、単純ながら効果的なアテンションの派生形であるマルチヘッド明示的アテンション(MEA)を提案する。MEAは2つの主要な構成要素からなる。1つは、ヘッドを横断してキーおよびバリューのベクトルに学習可能な線形結合を個別に適用し、豊かなヘッド間通信を可能にするヘッドレベル線形合成(HLC)モジュールである。もう1つは、再構成されたヘッドの統計的特性を整えるヘッドレベルのグループ正規化層である。MEAは事前学習において強力な堅牢性を示し、より大きな学習率の使用を可能にすることで収束を加速させ、最終的には検証損失の低減と幅広いタスクにおける性能向上をもたらす。さらに、アテンションヘッドの数を削減し、HLCを活用して低ランクの「仮想ヘッド」を用いてそれらを再構築することで、MEAのパラメータ効率を調査する。…
核心:何を提案したのか
本研究の最大の貢献は、ヘッド間の通信を明示的に強化する新しいアテンション機構である「Multi-head Explicit Attention(MEA)」を提案したことである。MEAの核心となるのは、ヘッドレベル線形結合(HLC)モジュールと呼ばれるコンポーネントである。これは、アテンションの計算が行われる前の段階で、キー(Key)と値(Value)のテンソルに対して、ヘッド次元にわたる学習可能な線形変換を適用するものである。これにより、複数のコンポーネントヘッドから新しい「混合ヘッド」を合成することが可能になり、パラメータを共有しながらもヘッド間の特徴を柔軟に融合させることができる。 さらに、MEAは単なる線形結合の導入にとどまらず、グループ正規化(GroupNorm)を統合することで、学習の安定性を劇的に高めている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related