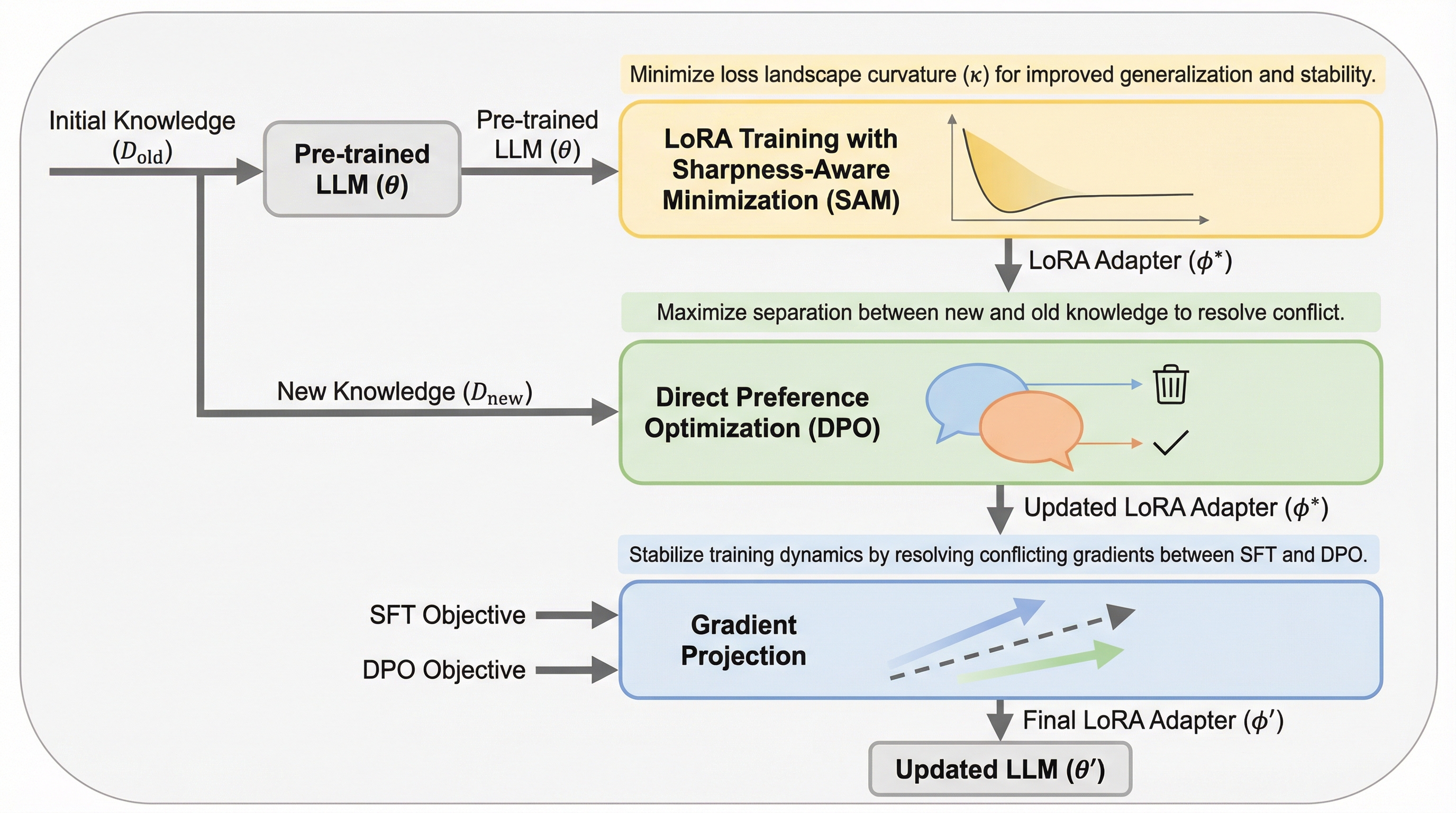
複数回の更新を伴う一般化された知識編集のための競合解消およびシャープネスを考慮した最小化
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。
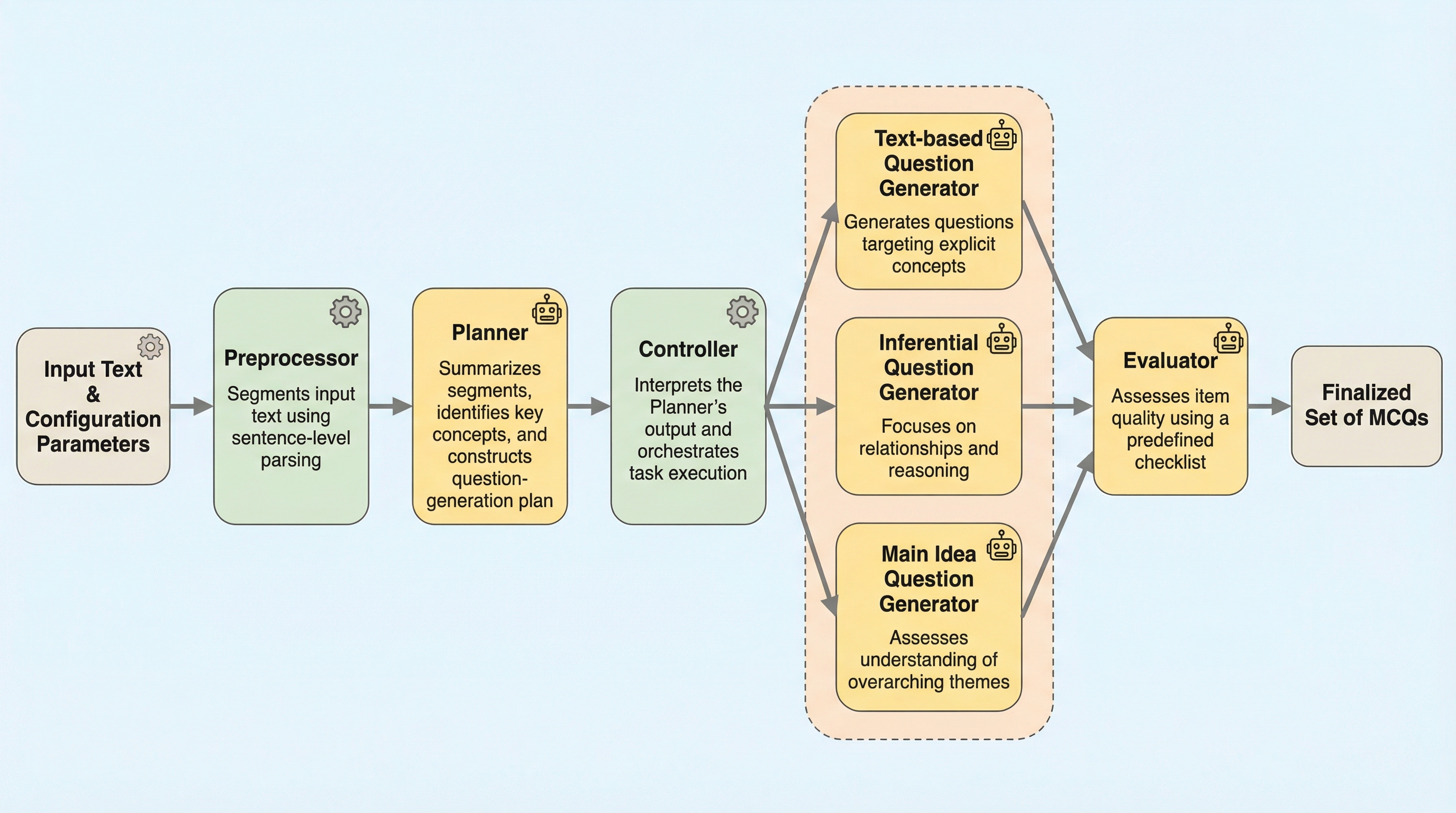
ReQUESTAは、大規模言語モデル(LLM)とルールベースの仕組みを組み合わせたハイブリッドなマルチエージェントフレームワークであり、テキスト想起、推論、主旨把握という異なる認知レベルの多肢選択式問題を系統的に生成します。
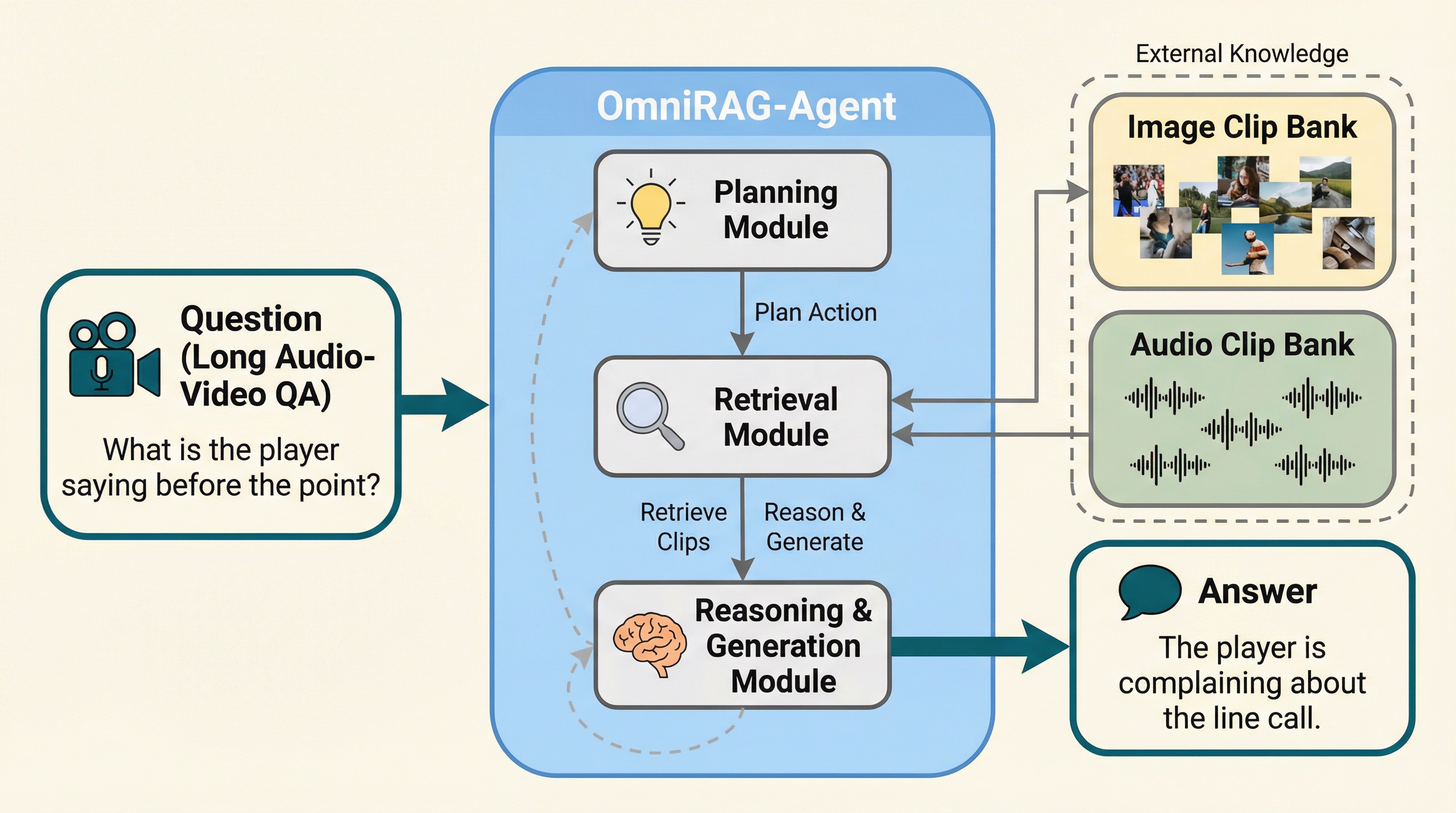
長時間の音声と動画を統合して理解するタスクにおいて、計算資源の制約を克服しながら高精度な回答を実現する「OmniRAG-Agent」が提案されました。 この手法は、動画全体を一度に処理するのではなく、外部の画像・音声バンクから必要な情報を動的に取得するRAGと、自律的に思考とツール呼び出しを繰り返すエージェント機能を組み合わせています。 強化学習手法であるGRPOを用いることで、ツールの適切な使用方法と最終的な回答の質を同時に最適化し、15GBのVRAMという低リソース環境で既存の大型モデルを凌駕する性能を達成しました。
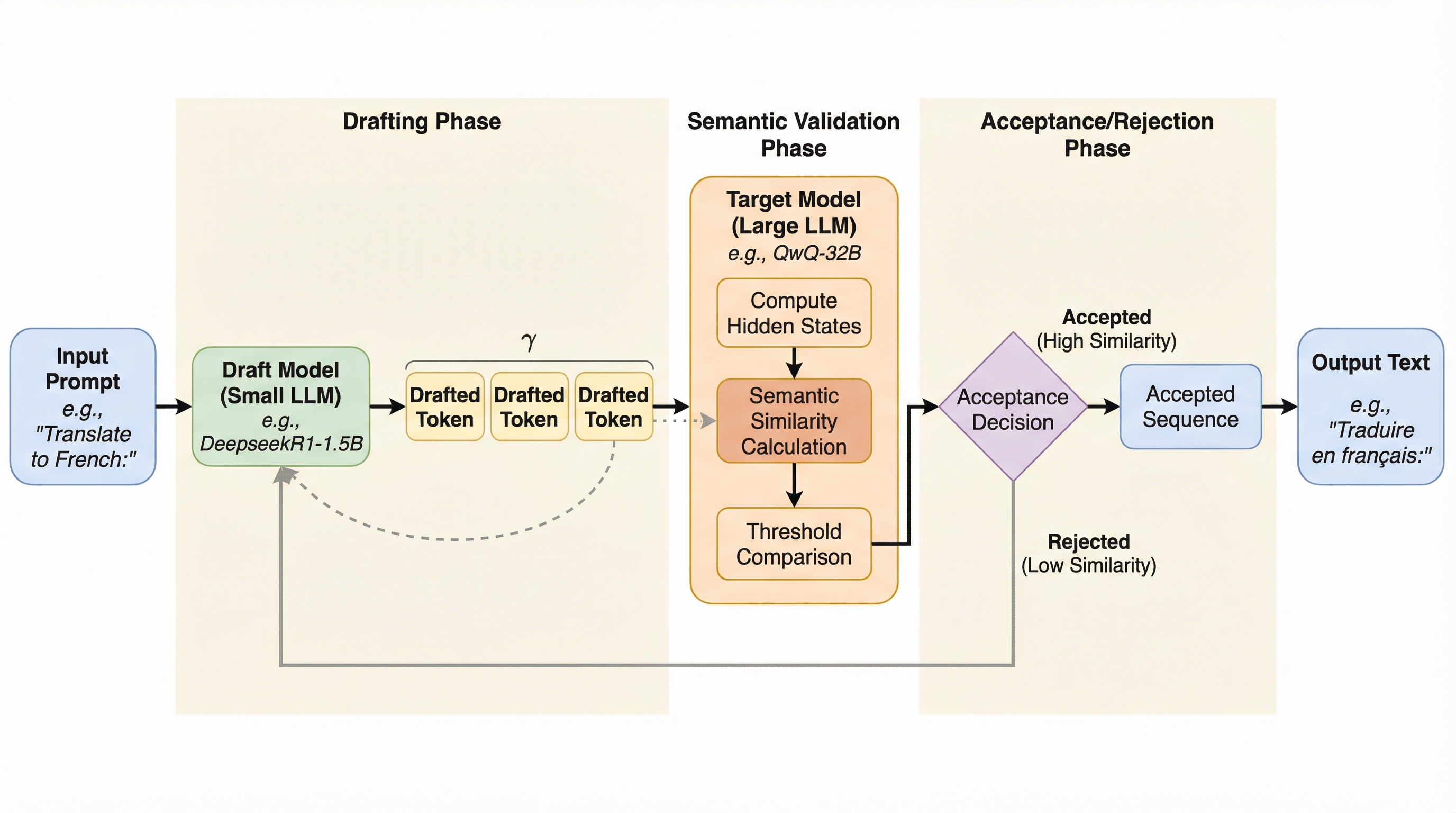
大規模言語モデルの推論を高速化する投機的デコーディングにおいて、従来のトークン単位の厳密な一致ではなく、文章全体の意味的な等価性を検証する新しいフレームワーク「SemanticSpec」が提案されました。
大規模言語モデルを用いた多段階検索エージェントの学習において、長い工程の最後にのみ与えられる報酬では、途中のどの行動が成功に寄与したかを特定できない「クレジット割り当て」の困難さが大きな課題であった。
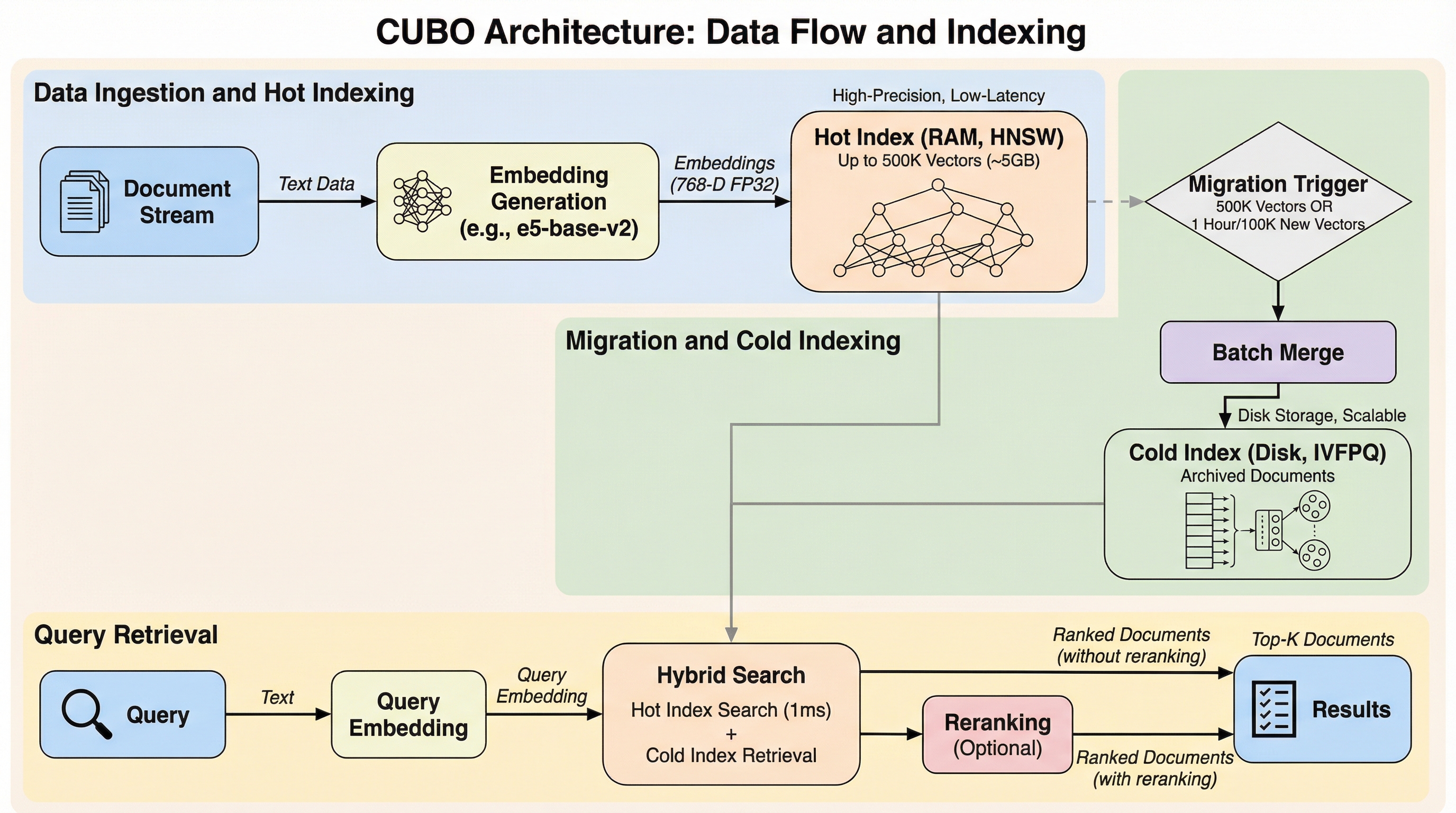
CUBOは、16GBの共有メモリを搭載した一般的なノートPCで動作するように設計された、自己完結型の検索拡張生成(RAG)プラットフォームであり、クラウドベースのAIが抱えるGDPR違反のリスクを回避しつつ、通常は18〜32GBのRAMを必要とするローカルRAGシステムを、15.
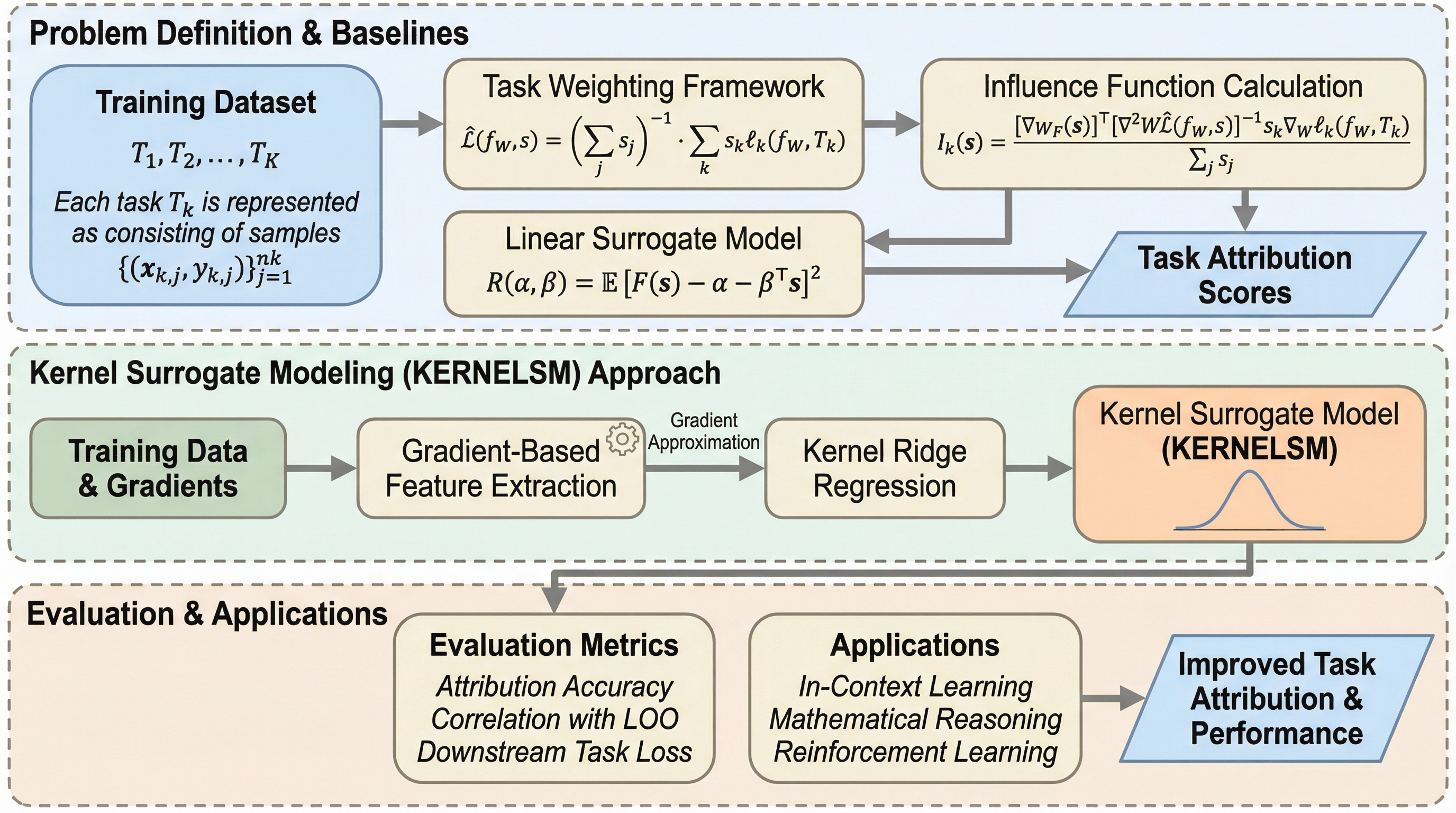
現代のAI学習において、多数の学習タスクが特定の目標タスクに与える影響を解明する「タスク属性評価」は、計算コストとタスク間の複雑な非線形相互作用(相乗効果や反作用)が障壁となっていました。本研究は、従来の線形モデルでは捉えられなかったこれらの非線形関係を、放射基底関数(RBF)カーネルを用いた「カーネル代理モデル(KERNELSM)」によってモデル化し、さらに事前学習済みモデルの勾配情報を活用した「再学習不要」の高速な推定アルゴリズムを開発しました。検証の結果、提案手法は既存の線形モデルや影響関数と比較して、真値である再学習結果との相関を25%向上させ、コンテキスト内学習や多目的強化学習におけるデモンストレーション選択の精度を40%改善することに成功しました。
大規模言語モデル(LLM)の長文処理における計算コストとメモリ消費を削減するため、情報を連続的なベクトル表現に凝縮するソフト圧縮手法「ComprExIT」が提案されました。 既存手法はLLM自体を圧縮器として再利用しますが、層を重ねるごとの情報の上書きや、トークン間での圧縮容量の不均等な割り当てという構造的な欠陥により、情報の欠落や精度の低下を招いていました。 本手法は、固定されたLLMの内部状態から「層方向」と「幅方向」に明示的に情報を伝達することで、わずか1%の追加パラメータで非圧縮モデルに匹敵する精度と、従来手法を凌駕する堅牢性を実現しました。
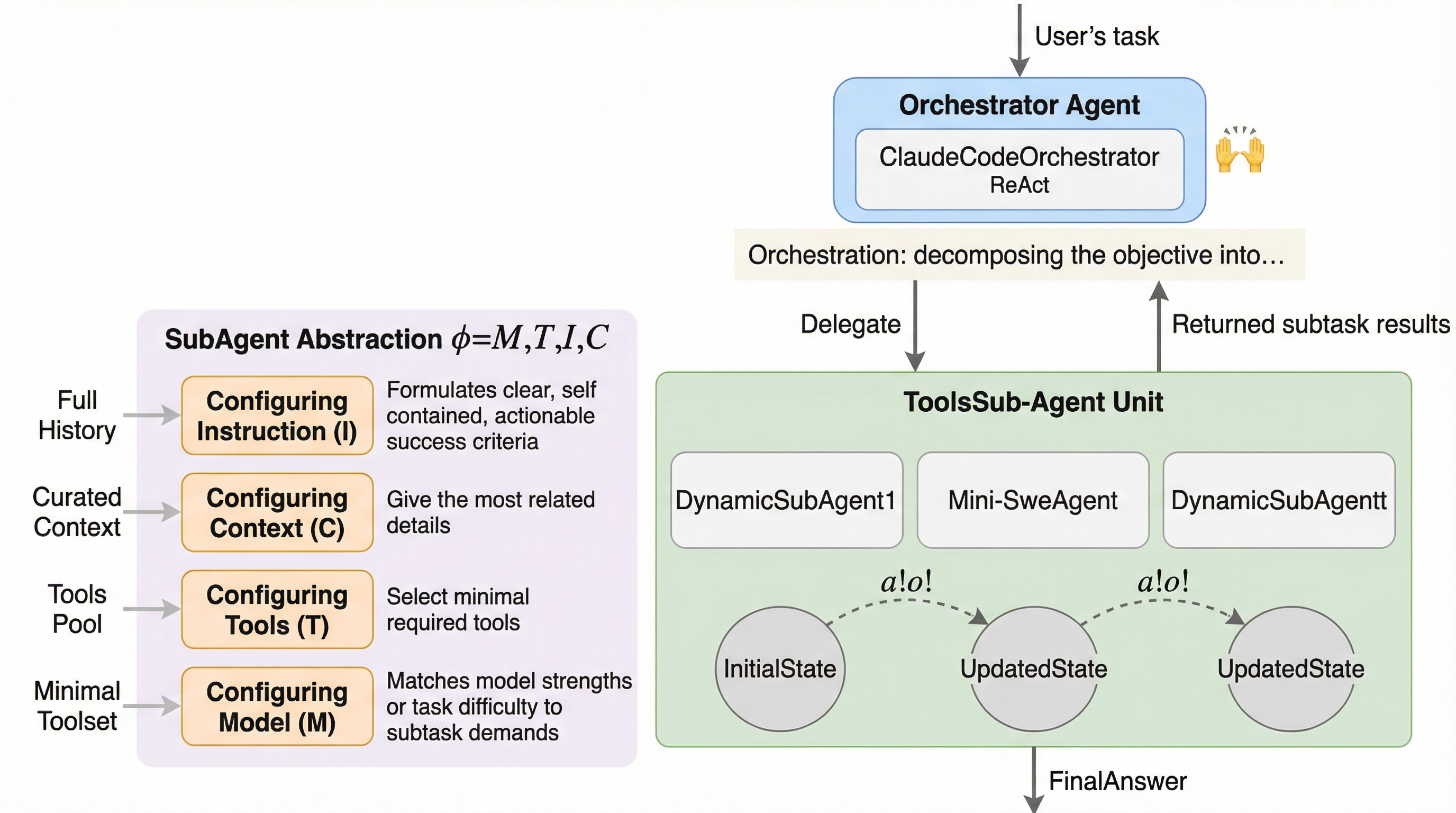
複雑で長いタスクほど、なぜエージェントは途中で失速してしまうのでしょうか? 原因はモデルの賢さだけでなく、「サブエージェントをどう扱うか」の設計にある――論文はそう示唆します。 この記事では、AOrchestraが提案する“動的に作れるサブエージェント”という発想と、何がどこまで良くなったのかを追います。
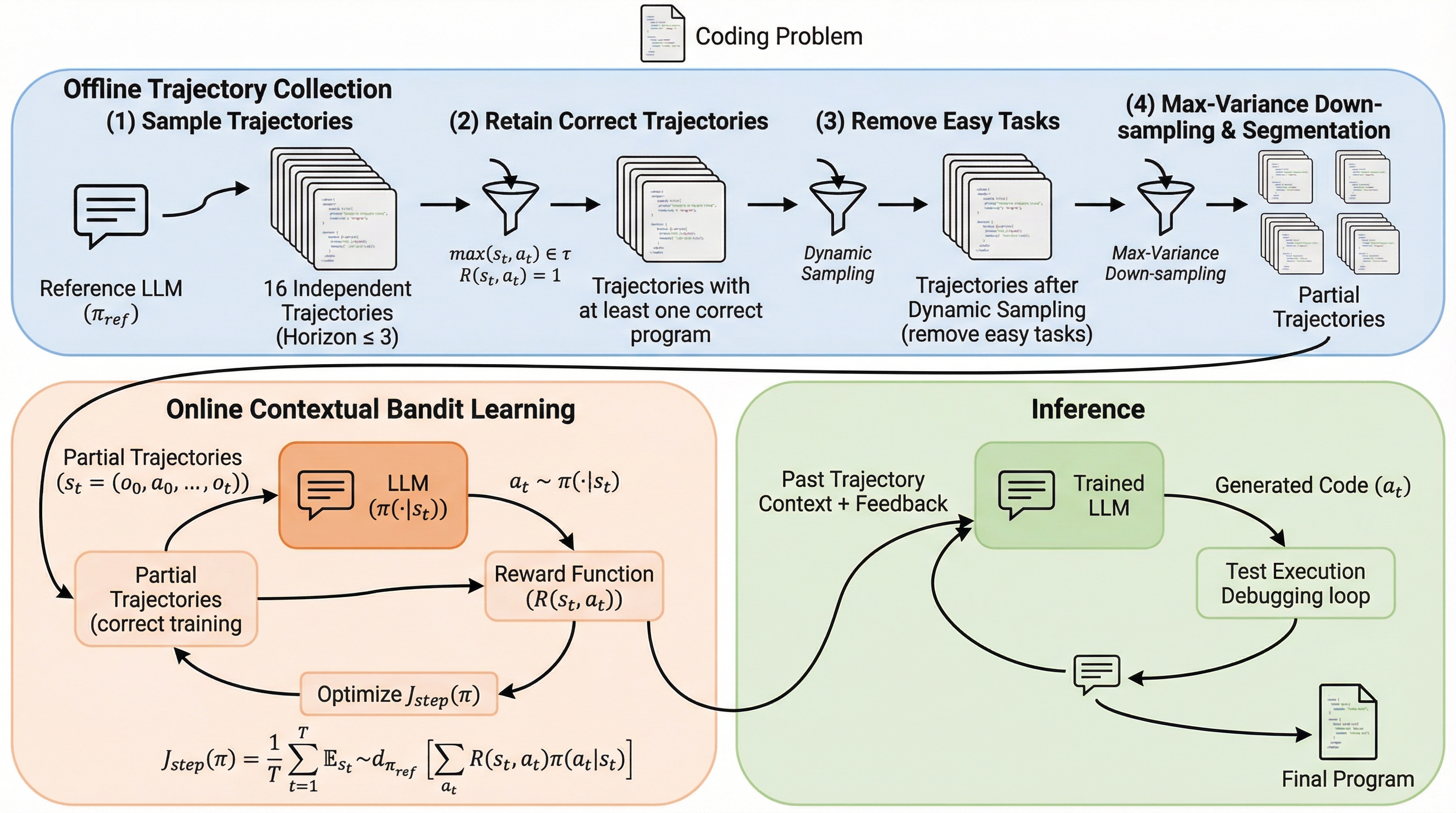
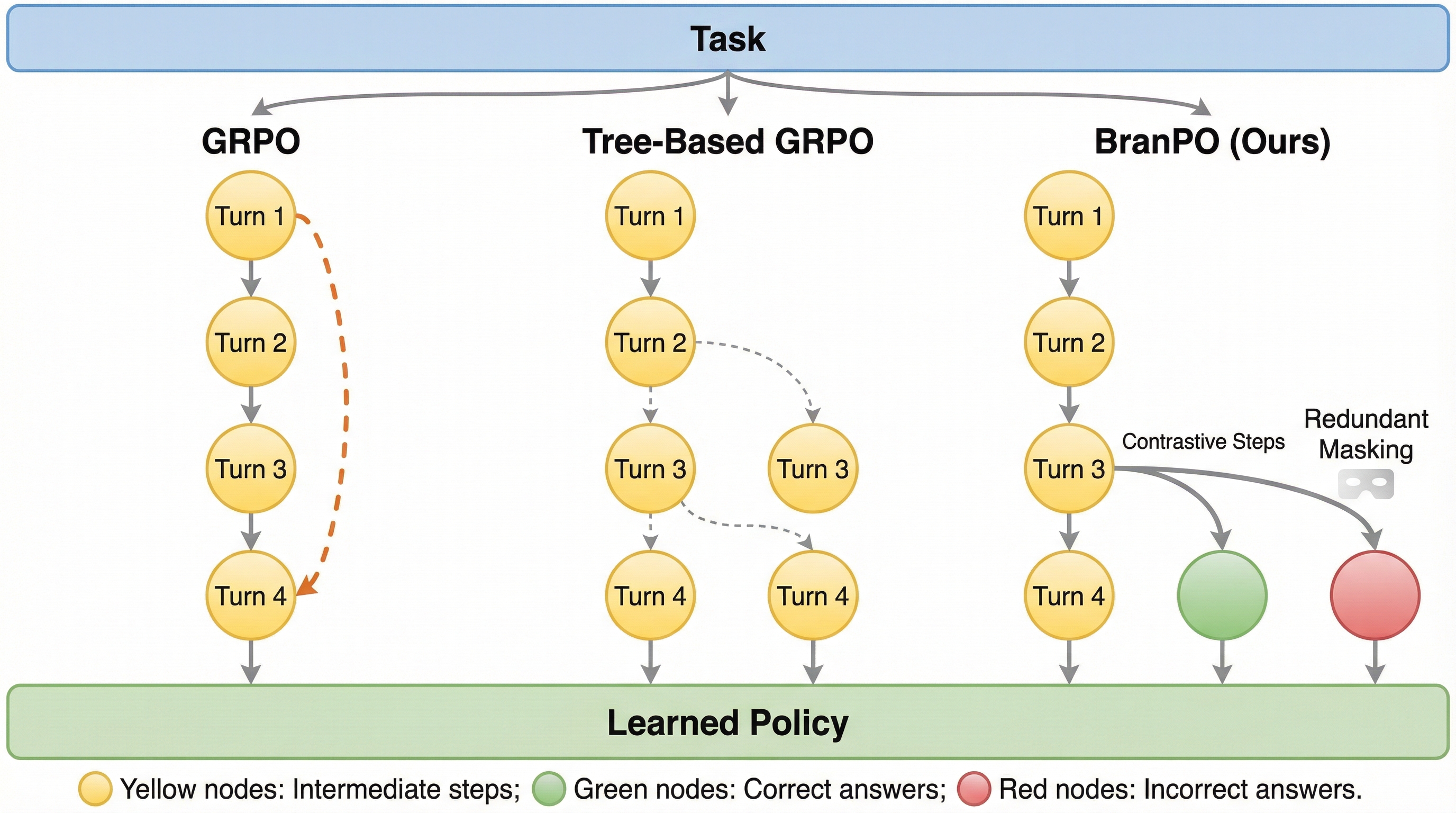
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。